
一种新的K均值挖掘的隐私保护算法
2011-02-28 01:45王思勃白素平
长春大学学报 2011年10期
王思勃,白素平
(长春理工大学 光电工程学院,长春 130012)
0 引言
近年来,人们对隐私问题以及数据挖掘应用越来越关注,于是很多研究人员开始研究隐私保护的数据挖掘技术,简称PPDM。PPDM技术被广泛应用于医疗、商业、社会学等多种领域。前期的工作主要有两类:数据修改和数据加密[1]。数据加密技术没有数据修改技术应用的广泛,因为它的计算和通信代价太高。隐私保护的数据挖掘有两个目标:隐私和精度[2]。这两个目标往往是一种平衡关系:隐私要求方面,在挖掘者挖掘数据之前,要对隐私数据进行足够的干扰;精度要求方面,尽管隐私数据被干扰,蕴藏在隐私数据中的数据模式仍然可以被挖掘者挖掘出来。本文提出了一个新的噪音添加算法来干扰原始数据,实验表明,这个算法在同等条件下比其它的算法挖掘精度更高。
1 背景介绍
对于数据加密的隐私保护方法,主要实现分布式数据挖掘隐私保护方法。由于公钥密码机制保证了第三方对原始数据的不可见性以及数据的无损失性,能够实现与原始挖掘相同精度的挖掘结果。但是与数据干扰方法相比,其计算和通信代价很昂贵。
数据修改技术主要有:加法噪音,乘法噪音,矩阵乘法,数据交换和K匿名[3],本文着眼于加法噪音技术。对于加法噪音技术,2000年,Agrawal and Srikant公布了他们关于隐私保护数据挖掘的早期工作,他们提出了一个在客户/服务器场景下,构建决策树的加法干扰技术,通过重构原数据的数据分布得到与原数据相似的数据,然后再挖掘重构数据,缺点是重构比较麻烦。为了能够直接通过挖掘干扰数据,而不需要修改挖掘算法,就能得到很好的挖掘效果,刘丽[4]提出了一个门限法,计算每条数据记录的概率值,通过门限将数据记录进行分类,这样就跳过了重构过程,减少了程序的计算。刘丽方法的缺点是合适的门限的选取比较困难,没有规律,要依靠经验,不同的数据集也不同。
2 RD算法
以前的加法噪音算法都是要对干扰后的数据进行处理,然后再进行挖掘。本文提出的RD(random distance)算法是在数据干扰之前,对原始数据进行一次K均值的预挖掘,根据挖掘后的结果再进行干扰,而数据分析者只需要直接对干扰后的数据进行挖掘,就能够得到与挖掘原数据相似的结果.RD算法中,数据提供者使用下面公式替代原始数据X:

其中,R是独立同分布的噪音数据。
我们假设D是原始数据集,C(C1,C2...Ck)是使用k均值聚类算法挖掘原始数据的聚类结果。我们的目的就是要把D修改成D',当数据分析者挖掘D'时,得到一个新的聚类结果,这个聚类结果与C具有较高的相似度,从而保证了挖掘精度。如图1所示。

图1 RD算法示意图
在RD算法中,首先遍历数据集中的所有记录,在使用K均值聚类之后,每一条记录都将会被归类,此时,数据提供者对记录添加噪音数据。为了保证干扰后的数据模式保持不变,RD算法尽可能得去保证每条记录在干扰前后类别不变,方法是在添加噪音数据后,调整聚类中心和干扰后记录点之间的距离,使得数据干扰前后始终在此类别域内,如图1所示,Ci是聚类中心,R is记录点.噪音数据RxandRy被添加到属性X和Y中,然后回得到点P(X+Rx,Y+Ry).此时,有三种情况需要考虑,P分别在Din(i),D(i)和out(i)域内:
在计算Ci和P'之间的距离之后,就能计算出将要发布给数据分析者的数据点P'的坐标。RD算法伪代码

3 实验结果
本文实验中,数据挖掘工具使用的是WEKA工具,噪音数据的生成使用的是Matlab 7.0实现的,使用的数据集来源于真实的数据集Iris,Yeast和 Glass,,实例数分别为150、1484、214,从加利福尼亚大学的UCI机器学习库中下载得到。
实验中,通过与Keke Chen的数据干扰进行比较来衡量算法的性能。对每一个数据集,实验测试条件为:分类数目选取2和3,加法噪音为均值为0,方差为0.2的高斯分布。我们的结果与Keke Chen的数据干扰进行比较,每一项测试选取10组噪音数据,计算平均精度作为最终精度。图2和3显示了分别挖掘Iris数据集干扰前后的结果。由此可见,干扰后隐私所属类别更明显了,从而保证了很高的挖掘精度。
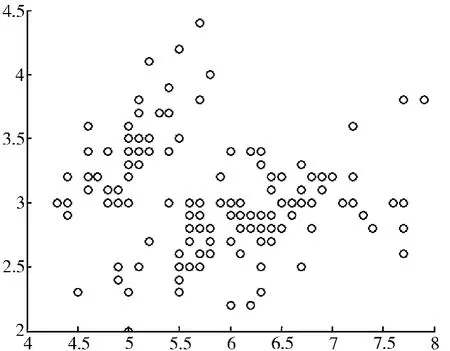
图2 隐私数据分布
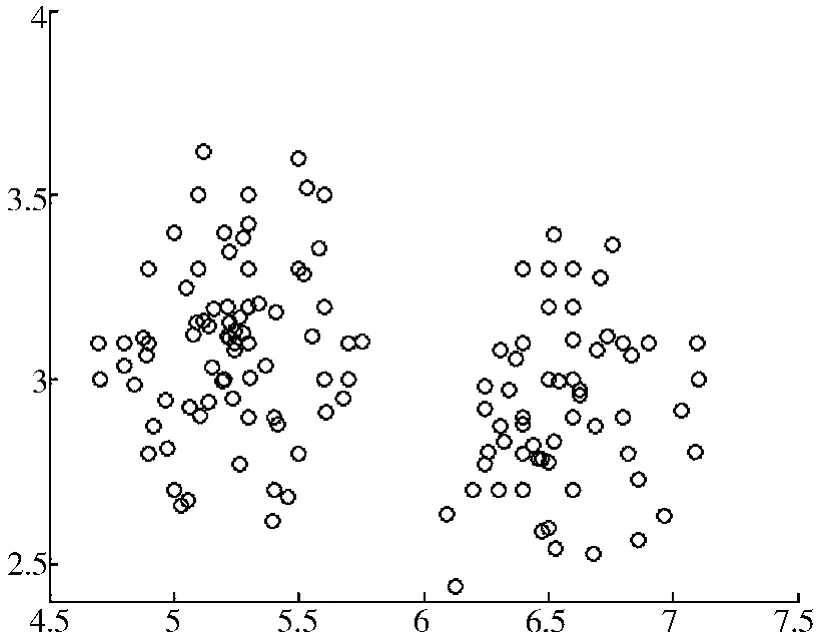
图3 干扰后数据分布
表1显示了测试的结果,实验表明,在大多数情况下,我们的算法的挖掘精度要高于Keke Chen的算法。
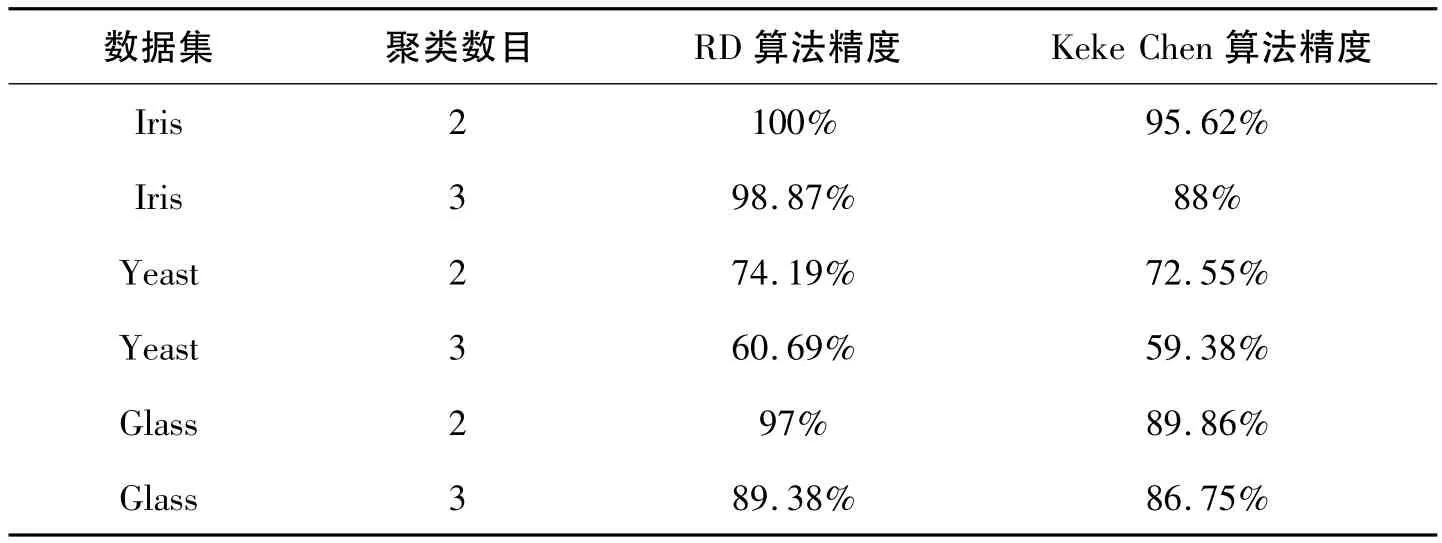
表1 挖掘精度
4 结语
本文提出了一个新的噪音添加方法,保护了数据挖掘中的隐私数据。我们的方法根据对原数据的预挖掘结果来调整干扰后数据,从而不再需要计算代价很高的重构步骤,也不需要修改数据挖掘方法,并且能够得到较高的挖掘精度,是一个有效可靠的隐私保护的数据挖掘方法。
[1]Jiawei Han,Micheline Kamber.范明,盂小峰等译.数据挖掘:概念与技术[M].北京:机械工业出版社,2001.
[2]王泳.基于隐私保护的数据挖掘[D].赣州:江西理工大学,2008.
[3]李锋,马进,李建华.分布式数据挖掘中的匿名隐私保护方法[J].浙江大学学报(工学版),2010(2):276-283
[4]Li Liu,Murat Kantarcioglu,Bhavani Thuraisingham.Privacy Preserving Decision Tree mining from Perturbed Data[J].In proceedings of 42th Hawaii International Conference on System Sciences.2009.
[5]K.Chen,G.Sun,and L.Liu.Towards attack-resilient geometric data perturbation[J].In Proceedings of the 2007 SIAM International Conference on Data Mining(SDM’07),Minneapolis,MN,April 2007:589-592.
猜你喜欢
China Report Asean(2022年8期)2022-09-02
大众投资指南(2021年35期)2021-02-16
物联网技术(2020年12期)2021-01-27
小学科学(学生版)(2020年10期)2020-10-28
疯狂英语·新悦读(2019年10期)2019-12-13
小火炬·阅读作文(2017年8期)2017-09-26
Coco薇(2017年9期)2017-09-07
汽车零部件(2017年4期)2017-07-12
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
