
改进的粒子群算法
2011-02-28 01:45:48宋继红
长春大学学报 2011年10期
宋继红
(长春大学 电子信息工程学院,长春 130022)
1 粒子群算法概述
粒子群优化算法(PSO)中是,Kennedy和Eberhait提出的一种基于群体智能的演化计算技术,它初始化为一群随机粒子(随机解),然后通过迭代找到最优解,在每一次迭代中,粒子通过跟踪两个“极值”来更新自己。第一个就是粒子本身所找到的最优解,这个解叫做个体极值pbest,另一个极值是整个种群目前找到的最优解,这个极值是全局极值gbest。它没有遗传算法用的交叉(crossover)以及变异(mutation),而是粒子在解空间追随最优的粒子进行搜索。
在找到这两个最优值时,粒子根据如下的公式来更新自己的速度和新的位置:

V是粒子的速度,pbest和gbest如前定义,rand是介于(0,1)之间的随机数,c1,c2是学习因子,通常c1=c2=2。每一位粒子的速度都会被限制为不高于一个最大速度Vmax,如果某一位更新后的速度超过用户设定的Vmax,那么这一位的速度就被限定为Vmax。
在标准PSO算法中,惯性权重是控制历史速度对当前速度的影响程度,平衡PSO算法的全局搜素和局部搜索能力。当w较大时,算法具有较强的全局搜索能力;当w较小时,算法的局部搜索能力强,而且PSO算法后期粒子容易在全局最优解附近出现震荡现象,我们通常需要反复试验才能确定w最大值wmax,Wmin和最大迭代次数。而且找到适应每个问题的最佳值也比较困难,所以有必要对更新的位置作一定的限制,限制的思路多种多样,既可以采用速度限制的方法,也可以采用模拟退火思想的方法,本文将模拟退火思想运用到粒子群算法中去,以解决局部最优和速度收敛缓慢的问题。
2 模拟火退算法概述
模拟退火算法的基本思想是从一给定解开始的,从邻域中随机产生另一个解,接受准则允许目标函数在有限范围内变坏,以一定概率接受新的解。
退火温度是跳出局部极值的关键参数,退火温度直接影响接受准则,因此退火温度一定要选好初值。当算法接近收敛时,局部最大适应值和个体适应值之比逐渐减少并趋向于1,退火温度t随之逐渐接近0。这样,在全局最优解附近的温度下降速率足够慢,接受恶化解概率也逐渐减少,所以粒子群定会形成最低能量的基态。
3 粒子群算法的优化策略
基于这种思想进行了两种方法的改进:
方法1:按(2)式计算新的位置,计算两个位置所引起的适应值的变化量△E;若△E≤0,接受新值,否则若exp(-△E/T)>rand(0,1),也接受新值,否则就拒绝,xk+1仍为xk具体步骤如下:
1)对每个粒子初始化,设定粒子数n,随机产生n个初始解或给出n个初始解,随机产生n个初始速度,给定起止“温度”T、T0和退火速度α;
2)根据当前位置和速度产生这个粒子的新位置;
While(迭代次数<规定迭代次数)do
3)计算每个粒子新位置的适应值;若粒子的适应值优于原来的个体极值pbest,设置当前适应值为pbest;
4)根据各个粒子的个体极值pbest找出全局极值gbest;
5)按(1)式,更新自己的速度,并把它限制在Vmax内;
6)按(2)式,更新当前的位置;
7)计算两个位置所引起的适应值的变化量△E;△E≤0,接受新值,否则若exp(-△E/T)>rand(0,1),也接受新值,否则就拒绝,xk+1仍为xk;
8)若接受新值,降温T←αT,否则不降温。
End
方法2:接受准则允许目标函数有限范围内变坏,并不按概率取舍,直接按△E<e,e为按允许目标函数变坏范围,具体算法如下:
1)对每个粒子初始化,设定粒子数n,随机产生n个初始解或给出n个初始解,随机产生n个初始速度;
2)根据当前位置和速度产生这个粒子的新位置;
While(迭代次数<规定迭代次数)do
3)计算每个粒子新位置的适应值;
4)对某个粒子,若粒子的适应值优于原来的个体极值pbest,设置当前适应值为pbest;
5)根据各个粒子的个体极值pbest找出全局极值gbest;
6)按(1)式,更新自己的速度,并把它限制在Vmax内;
7)按(2)式,更新当前的位置;
8)计算两个位置所引起的适应值的变化量△E;若△E <e,接受新值,否则就拒绝,xk+1仍为xk。End
4 数值模拟
分别选用上文中的方法1,方法2和原始PSO算法对下面两个标准测试函数进行计算,并对其结果进行分析。

参数设置如下:在基本的粒子群算法中,粒子数n=40,Vmax=1,Vmin=-1,初始速度都为0。
方法1的参数与基本粒子群算法相同,起始温度T=100,退火温度α=0.99。
方法2的参数与基本粒子群算法相同,xmax=10,xmin=-10;e=1。
由于此函数较复杂,因此将循环次数设为30次,测试结果如表1所示。

表1 三种策略对F2的测试结果

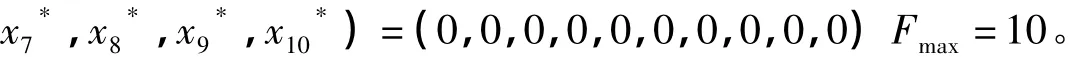
由于这个函数的特殊性参数设置如下:Vmax=0.3,Vmin=-0.3;xmax=2,xmin=-2;允许的最大适应值为9.999;初始温度T=100,退火温度α=0.99,e=1;一个循环内最大迭代次数为5000,各种策略循环1000次的结果如表2所示。

表2 三种策略对F3的测试结果
仍然针对函数F3,现在我们想比较一下各种方法的收敛快慢,我们跟踪粒子的每次迭代的位置,每隔5ms纪录一次粒子的位置,三种算法都只运行一次的详细跟踪图如图1所示。

图1 三种算法的收敛图
从表1中我们可以看出,方法1和方法2的总运行时间和总迭代次数都少于原始的粒子群算法。但在表2中方法2的总运行时间却比原始粒子群算法的总运行时间长。原始的粒子群算法迭代了不到60次最先停止,方法2迭代了接近100次最后停止。出现这种情况的原因在于方法1和方法2在一定程度上接受了恶化解,而基本粒子群算法不接受恶化解,因此基本粒子群算法的运行时间快。但是这种快是有一定的前提的,那就是算法一定收敛到最优解,而不是局部最优。
对于表2中的粒子群算法,我们为了让其收敛也把X限定了范围这种思想正是本文方法1算法的思想,现在我们把粒子群算法中的X范围扩大到,我们把循环次数降低到20次得到表3。

表3 不同的x范围的粒子群算法运行结果

续表
再把表3细化,当xmax=5,xmin=-5时基本粒子群算法程序运行详细结果,我们可以看出第三次和第四次循环程序迭代次数为5000次,而5000正是我们程序所规定的最大迭代次数,最优值分别为9.311330和9.102719,这说明第三次和第四次循环基本粒子群算法陷入了局部最优。当xmax=10,xmin=-10时,程序的20次循环中的18次都陷入了局部最优。经过上述的测试和分析,本文的两种改进策略都能在一定程度上避免陷入局部最优,并且在大多数情况下其运行时间和迭代次数比原始粒子群算法少。
5 结语
通过本文的测试结果,并加以分析,我们可以得出如下结论:
方法1算法和方法2算法都能在一定程度上有效的避免了陷入局部最优,这也是本文最重要的结论;当三种算法都收敛时,用他们来计算同一函数并循环n次(n很大),绝大多数情况下方法2算法的迭代次数最少,然后是方法2算法,最后是基本粒子群算法;而总运行时间则是方法2算法最少,然后是方法21算法,最后是基本粒子群算法;方法2算法的总运行时间和迭代次数随x范围的增大而增大并且这种增大的趋势越来越迅速。
[1]Kennedy J,Eberhart R.Particle Swarm Optimization[J].In:IEEE Int1 Conf on Neural Network,Perth,Australia,1995:1942 -1948.
[2]白莉媛,胡声艳,刘素华.一种基于模拟退火和遗传算法的模糊聚类方法[J].计算机工程与应用,2005(9):56-58.
[3]谢晓峰,张文俊,杨之廉.微粒子群算法综述[J].控制与决策,2003(2):129-134.
[4]Clerc M,The Swarm and the Queen:Towards a Deterministic and Adaptive Particle Swarm Optimization,In:Proc of the C t R,A modified particle swarm optimizer[J].In:IEEE World Congress on Computational Intelligence,1999:1951 - 1957.
猜你喜欢
智能建筑电气技术(2022年2期)2022-02-06 02:30:46
新世纪智能(数学备考)(2021年10期)2021-12-21 06:20:38
商用汽车(2021年4期)2021-10-13 07:16:02
数学物理学报(2020年6期)2021-01-14 01:00:14
河北理科教学研究(2020年3期)2021-01-04 01:49:40
高考·上(2019年5期)2019-09-10 03:48:06
科技与创新(2019年11期)2019-09-05 13:40:34
中学数学杂志(2019年1期)2019-04-03 00:35:46
中学生数理化·中考版(2017年12期)2017-04-18 12:55:03
当代旅游(2016年5期)2016-10-19 14:03:45
