
基于优化的LMNLDA的人脸识别研究*
2011-02-28 05:10苗春玉闫德勤
网络安全与数据管理 2011年12期
苗春玉,闫德勤
(辽宁师范大学 数学学院,辽宁 大连116029)
人脸识别特指利用分析比较人脸视觉特征星系进行身份鉴别的计算机技术,是一项热门的计算机技术研究,它属于生物特征识别技术,是人工智能与模式识别领域以及计算机视觉领域最富挑战性的研究课题之一。特征提取是人脸识别中极其关键的一步。线性判别分析(LDA)也叫做 Fisher线性判别(FLD),是模式识别的经典算法,其基本思想是将高维的样本投影到低维最佳鉴别矢量空间,投影后保证样本在该空间中有最佳的可分离性。但LDA算法过度强调了边缘类与其他类的类间距离大小,导致在投影空间中近邻类样本的重叠。LDA算法在人脸识别应用中常遇到两个问题:(1)SSS小样本问题(Small Sample Size)[1];(2)边缘类的存在造成投影空间中近邻样本重叠的问题。而一种改进的LDA算法——最大边际近邻元判别分析方法(LMNLDA)可以有效地克服样本类间数据重叠,增加了样本间的相似度来描述数据之间关系,于是重新定义散度矩阵,从而得到该判别准则。
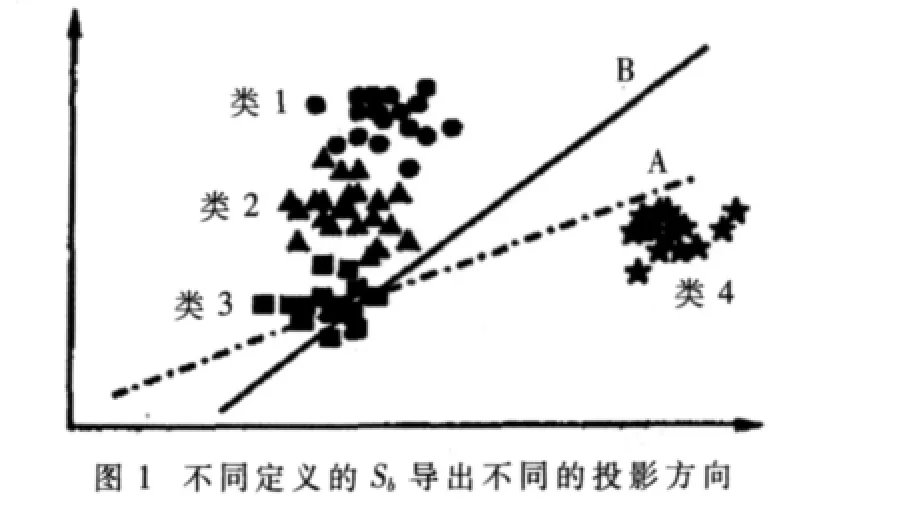
如图1所示,考虑一个M维的样本模型投影到一维空间,假定有一个边缘类4与类1、类2、类3相隔较远,则根据传统LDA算法得到的最佳投影方向A夸大了与其他3个类的类间距离较大的、可分性很好的类4,但却造成了类间距离本来就小的类1、类2、类3的彼此重叠。因此,就分类性而言,基于Fisher准则得到的鉴别方向并不是最优的,最大边际近邻元判别分析方法同样没有对这类问题进行解决。
1 传统的LDA方法及LMNLDA方法
1.1 传统的LDA方法
假设训练数据集 X={x1,x2,…,xc},其中 xk,k=1,2,…c是第k类数据集。LDA的目的是从高维特征空间里找出最有分类信息的低维特征,即寻找一个变换矩阵G,使得类内尽可能紧凑,类间尽可能分离。通常用离散度来刻画样本的分布,于是得到Fisher准则:

1.2 LMNLDA方法
最大边际近邻元判别分析方法(LMNLDA)是一种改进的LDA算法。假设{(xi,yi)}ni=1表示一个样本输入集,其中 xi∈RD,yi表示每一类的类别。 用二进制矩阵 yij∈{0,1}来表示类别yi和 yj是否匹配,并且矩阵yij是固定的,用变换L来决定样本之间的度量[3]。首先对于每一个输入样本xi∈RD,根据k近邻原则,采用欧式距离来进行距离度量,定义如下的惩罚函数:

此函数包括两部分,即在新的线性空间内,“引力”部分迫使拉近目标近邻点的距离使之尽量紧凑在一起,“斥力”部分迫使不同于输入样本类别的其他点尽量离得远一些。两部分相互对立、相互制约。最后,利用交替投影算法对式(3)进行优化取得最小值,进而求得最优变换矩阵L。
于是,在新的变换空间中,获得的新的类内、类间和总体散布矩阵为:

该方法能够克服样本类间数据重叠并且增加了一种描述数据之间关系的样本间相似度,但并未解决边缘类对选择投影方向的影响及矩阵Sneww的奇异问题。
2 优化的LMNLDA(OLMNLDA)方法
在计算等式SbG=SwG∧时的一个普遍问题是求Sw的逆,例如利用零空间方法,也就是忽略了零空间之后的列空间。但是Chen等[4].曾经验证了Sw包含了重要的判别信息,如果去掉零空间,则会丢失掉一部分有价值的信息,因此这里通过因数分解保持了信息的完整性,将等式(2)转化为:
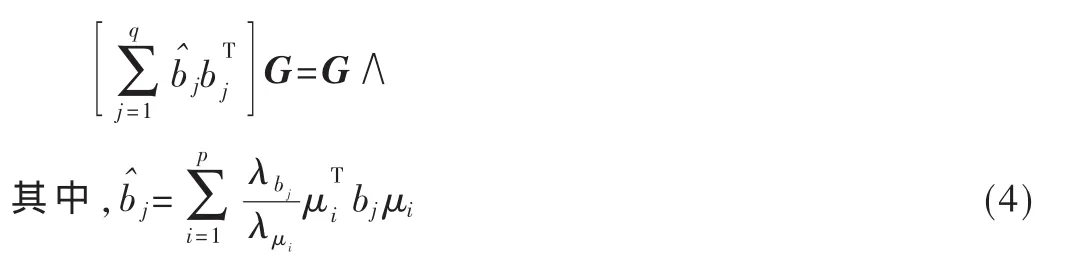



3 实验结果
为了测试优化的LMNLDA算法的识别性能,本文采用Yale人脸数据库、ORL人脸数据库和PIE人脸数据库进行了识别对比实验。
3.1 采用Yale人脸数据库的实验
采用国际通用的Yale人脸数据库,该数据库由15人,每人11幅,共165幅人脸正面256级灰度图像组成,每幅图像大小为243 mm×320 mm。其中有些图像是拍摄于不同时期的,人的脸部表情和脸部细节有着不同程度的变化,人脸姿态也有相当程度的变化。图2所示为预处理后的同一个人的人脸图像,共选择105个图像为训练集,其余的60个图像为测试集。
3.2 采用ORL人脸数据库上的实验
ORL人脸数据库由剑桥大学实验室1992年4月到1994年4月拍摄的一系列人脸图像组成,具体为40个人,每个人由不同表情或不同视点的10幅图像构成,倾斜角度不超过20°。人脸库中某一人的10幅图像如图3所示,一共选择了280个图像为训练集,其余的120个图像为测试集。
3.3 采用PIE人脸数据库的实验
PIE人脸数据库拥有68人,有不同的姿势,不同的灯光条件,以及不同的明暗表情等差别,其中包括了每个人的 13种姿态条件,43种光照条件和4种表情下的照片。如图4所示的一部分图像,一共选择340个图像为训练集,其余的11 214个图像为测试集。

3.4 实验结果分析

表1 在Yale人脸库的识别结果比较

表2 在ORL人脸库的识别结果比较

表3 在PIE人脸库的识别结果比较
如表1、表 2、表3表示5种方法在取相同特征维数的情况下的识别率比较,通过对3种人脸数据库的实验结果对比可以看出,本文所提出的优化的LMNLDA算法的识别率比其余4种方法的识别率都要高,5种算法呈现一个大体的趋势,就是在一个确定的维数即本征维数上识别率最高,维数越大,识别率越趋于平衡。从以上的实验结果可以看出,在相同特征维数的情况下OLMNLDA优于其余4种算法,克服了边缘类对选择最佳投影方向的影响,进而能得到较为满意的效果。实验结果充分证明了本文算法的有效性。
[1]BELHUMEUR P N,HESPANHA J P,KRIEGMAN D J,et al.Fisherfaces:Recognition using class specific linear projection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1997,19(7):711-720.
[2]张贤达.矩阵分析与应用[M].北京:清华大学出版社,2004.
[3]KILIAN Q,WEINBERGER L K,SAUL.Distance metric distance metric learning for large margin nearest neighbor classifiers[J].Journal of Machine Learning Research,2009(10):207-244.
[4]CHEN L,LIAO H,KO M,et al.A new lda-basedface recognition system which can solve the small sample size problem[J].Pattern Recognition,2000,33(10):1713-1726.
[5]MARTINEZ A M,ZHU M.Where are linear featureextraction methods applicable[J].IEEE Trans.On Pattern Analysis and Machine Intelligence,2005,27(1):1934-1944.
[6]LIU K,CHENG Y Q,YANG J Y,et al.An efficient algo rithm for Foley-Sammon optimal set of discriminant vectors by algebraic method[J].Int.J.Pattern Recog.Artif.Intell,1992,6(5):817-829.
猜你喜欢
数学物理学报(2022年4期)2022-08-22
无线互联科技(2020年22期)2021-01-11
弹箭与制导学报(2020年2期)2020-09-01
数学物理学报(2020年3期)2020-07-27
计算机工程(2020年3期)2020-03-19
计算机与生活(2019年8期)2019-08-12
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
自动化学报(2017年4期)2017-06-15
中国交通信息化(2016年2期)2016-06-06
