
基于CUDA的快速LBP纹理背景建模算法*
2011-02-27 07:28祖仲林陈启美
武汉理工大学学报(交通科学与工程版) 2011年1期
祖仲林 李 勃 陈启美
(南京大学电子科学与工程系 南京 210093)
复杂条件下的背景建模是计算机视觉领域尤其是运动目标检测中的难点,已有的研究中,提出了大量建立背景模型的方法[1-3],如时域差分与自适应背景更新相结合的方法、高斯混合模型(mixture of Gaussian)、Codebook背景模型来进行背景学习与前景检测,以及利用区域二维特征(local binary pattern,LBP)来建立模型等.
人的视觉系统识别物体轮廓主要观测的是纹理信息,由于纹理不随光照而改变,因此从理论上对纹理的逼近是区分背景最直接的方法.Heikkila提出统计一个区域内的基本LBP纹理,利用纹理直方图完成对背景建模,但该算法复杂度仍然较高,不能很好满足实时处理的要求.文中提出了基于CUDA的快速LBP直方图背景建模算法,利用CUDA技术并发执行的优点,把传统的基于CPU的背景建模算法移植到GPU平台上,从而有效地实现实时性与可靠性的同时兼顾.
1 基于LBP纹理直方图的背景建模算法
1.1 局部纹理描述
LBP是一种有效的纹理描述算子,具有旋转不变性和灰度不变性等显著优点.在近10年的时间里,该算子已经广泛地应用于纹理分类、图像搜索、人脸图像分析、运动目标检测等领域.
基本LBP局部纹理描述法简单且非常有效.定义纹理
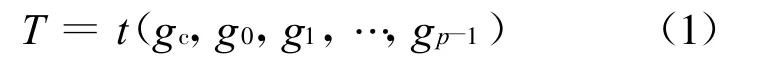
式中:gc为中心像素点,gi(i=0,1,2…,p-1)为以gc为中心的正方形框内的邻域点.以窗口中心点灰度值为阈值对窗口内其他像素做二值化处理

进一步定义阈值判决函数s(gc,gi)(i=0,1, 2,…,p-1):

通过对阈值函数采用因子为2i的加权,得到LBP的纹理描述

为了适应不同尺度的纹理特征,Ojala[5]等对基本LBP算子进行了改进,用圆形邻域代替了正方形邻域,采用双线性插值算法计算没有完全落在像素位置的点的灰度值.符号LBP(P,R)表示在半径为R的圆形邻域内有P个像素点, LBP(8,3)如图 1所示.文中选取 3×3邻域的LBP(8,1)算子.
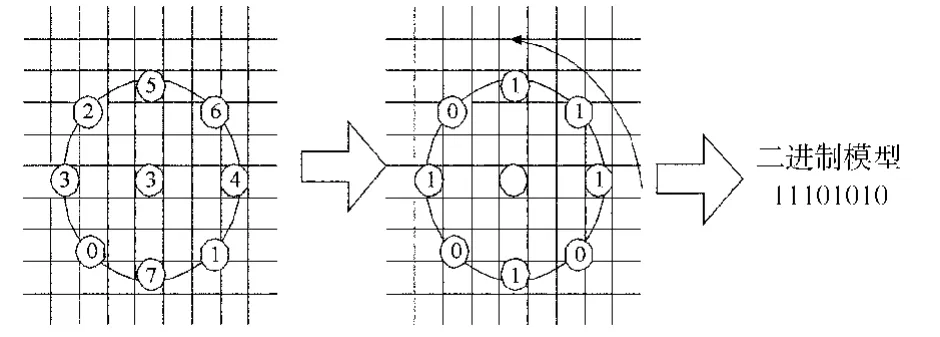
图1 扩展的LBP纹理算子(R=3,P=8)
由于文中采用的测试序列多为交通监控视频,考虑到交通视频具有自身的特殊性,即存在车道线、左右车道间栅栏等,用式(3)中差值控制法进行阈值判决,因其在单帧中阈值是固定的,不能很好地描述车道线、栅栏附近邻域的纹理.故,提出了基于比值控制的方法,可以很好地解决以上问题,选取阈值判决函数如下(其中 α,β为设定值,均接近于1).
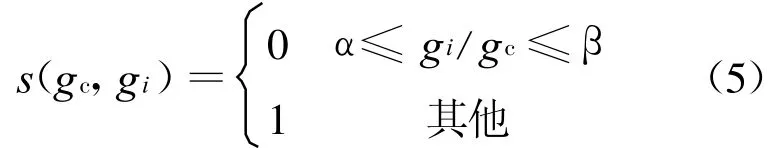
1.2 基于LBP纹理直方图的背景建模
基于纹理直方图的背景建模算法流程如图2所示.首先对当前帧图像进行LBP编码,计算以Region为半径的圆形区域内的LBP统一模式直方图,将当前帧像素的LBP统一模式直方图h与背景模型中对应像素的直方图进行匹配.h与当前背景模型的直方图进行相似性比较.参考Heikkila[4],用式(6)来衡量它们的相似性


图2 基于纹理直方图的背景建模算法流程图
式中:a,b为LBP统一模式直方图;N为条目数.相似性度量的阈值 Tp是用户设定的参数,根据经验,一般在0.6~0.7之间可以得到好的结果.
对于背景模型包含的K个直方图,根据其权值进行降序排列.将当前帧中像素LBP统一模式直方图h与降序排列好的进行相似性匹配.如果与背景模型中所有直方图相似度都小于那么最低权值的直方图将被h来取代,并被赋予低的初始权值,文中用0.01,同时作比例调整权值.
如果找到了匹配的直方图,需要按下式更新背景直方图:
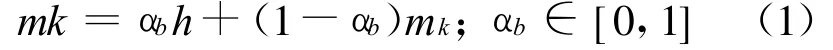

式中:Mk对于匹配的直方图值为1,其余值为0.背景模型的更新速度由学习速率参数来控制,由用户设定,其值越大,模型更新越快,但易受噪声影响.通常情况下它们取值较小时如0.01~0.05,可以得到好的结果.
1.3 运动前景检测
背景的确定方法如下:将LBP统一模式直方图按照权值进行降序排序,并在K个降序排列好的直方图中选取满足下式的最少的前B个直方图来表征背景(B<K):
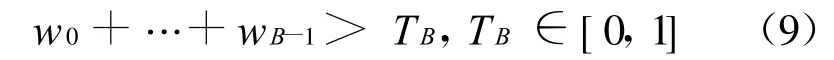
前景检测在背景模型更新前完成.当前帧某个像素的直方图h与相应位置表示背景的B个直方图用式(6)进行比较,如果对于其中一个直方图来说相似性大于所设定的阈值 Tp,那么此像素就为背景,否则即为前景.
2 GPU实现快速背景建模
2.1 CPU+GPU系统分析
基于CUDA的CPU+GPU整体架构如图3所示,在主机和设备端都有独立的存储空间,首先在主机端开辟内存空间,通过cudaMemcpy将待处理数据传递到设备,在设备上执行完Kernel函数,完成处理后,数据再传回主机.其中Kernel函数由多处理器并行执行,每个网格对应一个Block,每个多处理器可以使用16 kB共享内存,通过充分利用共享内存,可以更加有效地提高设备的使用效率.
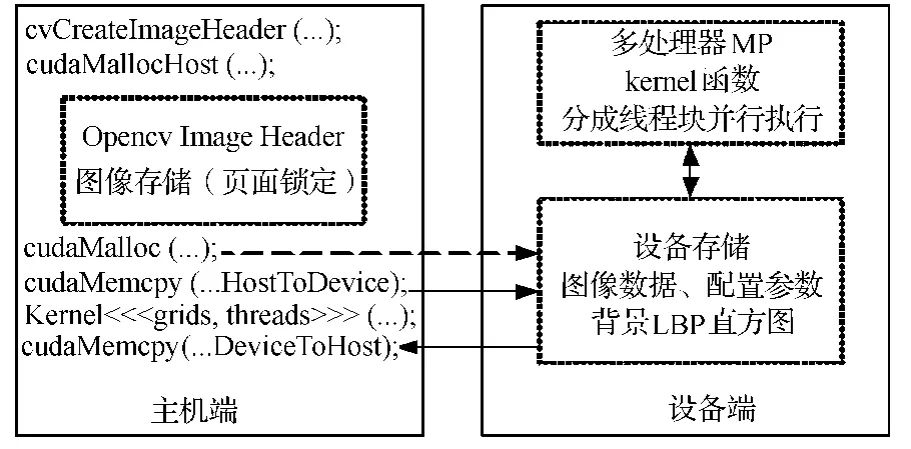
图3 CPU+GPU系统架构图
2.2 图像的存储与读取
图像在设备上的存储主要有3种方式,包括主机端的分页存储、分片存储以及纹理存储.
其中,使用cudaMallocHost开辟的分片存储空间(页面锁定)必定存在于物理内存中,而且地址固定,可以有效提高主机端与设备端的通信效率.相比cudamalloc开辟的分页存储空间,分片存储能使用CUDA API提供的异步传输功能,实现流式处理,在设备主机之间拷贝数据耗时更少,虽然分片存储有很多好处,但实际中不能分配过大,否则会降低系统整体性能.
在LBP直方图背景建模算法中,由于每个thread运算需要读取一小块数据而不是单个数据(比如LBP编码),如果每次访问都需要重新从全局存储器中访问,重复读取较多,访问效率低,同时需要考虑图像的边界问题.纹理存储为图像处理提供了优化,具有一组高速缓存,能够自动处理边界条件.在核函数中通过tex2D()函数获取像素值,非常方便,但纹理存储是只读的,不能用纹理作为输出.
设备和主机之间数据传递的时间是实时系统中需要考虑的因素,文中对多分辨率下(704×576 D1、320×240)的常见测试序列,分别使用3种不同存储方式,测试耗时表1所列(实验平台:E6300 1G ddr2内存G9600GSO).

表1 不同存储方式下传输耗时比较
2.3 多点访问技术以及共享内存的使用

图4 多点访问技术
对于单个网格内部,由于计算单个像素点以Region为半径的LBP统一直方图时,相邻点有较多重叠部分,针对这一特性,充分使用每个多处理器(MP)对应的16 kB共享内存,可以节省大量全局存储器带宽,大大提高单次全局读取平均对应的运算次数.
2.4 核函数的设计
设备端存储主要包含背景图像的LBP直方图、一些配置参数(如背景更新速率、背景判决阈值等).实验中选取每个block对应为128个thread(16×8),通过2.3中多点访问技术,可以看出每次计算对应4个点的输出,综合考虑每个MP的寄存器数量与最大并发线程数,选取每个thread对应4×3个像素点.设备端主要的kernel函数包含:
1)LBP编码 LBP_code<<<blocks, threads>>>()
通过纹理获取主机端传递的当前帧图像,完成对图像的LBP纹理编码,选用LBP(8,1)算子
2)前景提取 Forg_Get<<<blocks, threads,SharedMem>>>()
先计算当前帧图像的LBP纹理直方图,通过与背景纹理直方图相似性比较,区分前景点,将前景二值化图像传回主机端,注意这里用到了共享内存
3)背景 LBP直方图更新 Update_back<<<blocks,threads>>>()
根据已提取的前景图像更新设备端储存的背景LBP直方图
3 实验结果与分析
3.1 实验平台及数据来源
硬件平台:CPU为Intel Core E6300;内存为ddr2 533 1.0 GB;显卡为 Nvidia G9600GSO (384MB,192bit).软件平台:Linux Suse 10.3;编译环境gcc,g++;支持Intel opencv libarary,整体实现基于CUDA SDK 2.1.
实验使用的数据包括2组测试视频
1)http://cvrr.ucsd.edu/aton/shadow提供的标准测试序列,选用其中高速公路上的场景——highwayII测试序列(32×240)
2)项目组选用的来自江苏省宁连高速公路的路况监控视频,D1格式(704×576)
3.2 实验分析
3.2.1 检测效果对比 利用文中算法对两组视频进行测试,图5为highwayII上的测试结果,图6为宁连高速路段视频测试结果,其中后一组视频中运动车辆有不同程度的阴影,为突出显示抑制阴影的效果,作了适当截图(图中所有检测结果均未经过形态学滤波等后续处理).

图5 highwayII序列的检测结果图

图6 宁连监控视频检测效果图(有阴影)
对比文献[1-4]的实验结果,由图5,6可以看出,基于LBP纹理直方图的背景建模算法可以很好地检出运动目标,特别是对于有伴随阴影的运动目标,可以较好地抑制阴影点.
3.2.2 检测速度对比 利用文中算法对选用的两组视频进行测试,设备端图像读取时采用纹理存储方式,前景图像回传主机时采用分片存储方式,block大小选取为16×8.表2,3列出了在GPU和CPU上执行的实验结果.
由表 2,3可以看出,采用GPU方式,相比CPU平台有明显加速效果,不同分辨率下加速比达到20~40x,LBP纹理直方图背景建模算法的帧处理速率能够达到40 f/s以上.主要原因一方面是由于GPU并发执行的架构,能够同时处理多组数据;另一方面是由于针对该算法的特殊性和对称性,文中在CUDA架构上充分利用了共享内存和多点访问技术,更好地提高了系统性能.
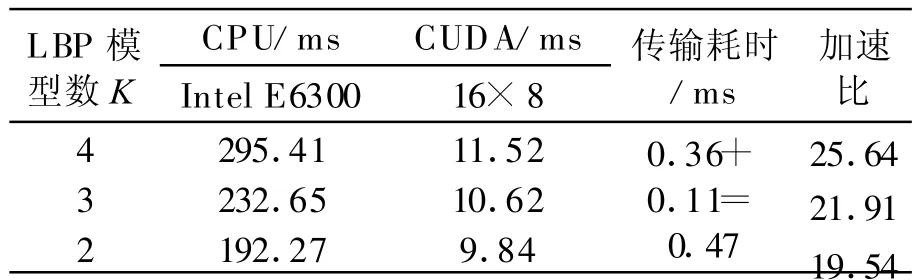
表2 序列highwayII CPU与GPU检测对比(320×240)

表3 宁连高速视频CPU与GPU检测对比(704×576)
4 结束语
针对复杂条件下背景建模这一视频检测领域的难点,文中提出了CUDA架构下的快速LBP直方图纹理背景建模算法,同时针对具体应用场景改进了基本LBP算子.实验结果表明,相比传统的CPU实现,GPU方式在实时性上有明显改善效果,不同分辨率下加速比在30x左右,帧处理速度达到40 f/s以上,很好兼顾地了实时性与可靠性.文中算法的GPU实现时采用的技术具有较强的通用性,可以应用于其他常见的背景建模算法,同时对于图像处理领域类似算法的GPU实现也有一定借鉴作用.
[1] Wang H,Suter D.A revaluation of mixture of gaussian background modeling[C]//IEEE International Conference on Acoustics,Speech,and Signal Processing(ICASSP).Pennsylvania,USA,2005:1 017-1 020.
[2]Lee D.Effective gaussian mixture learning for video background subtraction[J].IEEE T ransactions on Pattern Analysis and M achine Intelligence,2005, 27(5):827-832.
[3]Kim K,Chalidabhongse T H,Harwood D,et al. Real-time foreground-background segmentation using codebook model[J].Real-Time Imaging,2005, 11(3):172-185.
[4]Heikkila M,Pietikainen M.A texture-based method for modeling the background and detecting moving objects[J].IEEE Transactions Pattern Analysis and Machine Intelligence,2006,28(4):657-662.
[5]Ojala T,Pietikainen M,Maenpaa T.Multiresolution gray-scale and rotation invariant texture classification with local binary patterns[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2002, 24(7):971-987.
猜你喜欢
湘潭大学自然科学学报(2022年2期)2022-07-28
小哥白尼(军事科学)(2022年2期)2022-05-25
软件(2020年3期)2020-04-20
红领巾·萌芽(2019年8期)2019-08-27
摄影之友(影像视觉)(2018年12期)2019-01-28
摄影之友(影像视觉)(2018年12期)2019-01-28
中国与非洲(法文版)(2017年10期)2017-11-23
Coco薇(2017年8期)2017-08-03
初中生世界·八年级(2017年3期)2017-03-24
潍坊学院学报(2016年6期)2016-04-18
