
一种从自然语言文本到本体模型的转换方法
2011-02-24 07:25彭静罗伟
电大理工 2011年2期
彭 静 罗 伟
辽宁装备制造职业技术学院(沈阳 110161)
一种从自然语言文本到本体模型的转换方法
彭 静 罗 伟
辽宁装备制造职业技术学院(沈阳 110161)
如何利用本体将内容所蕴涵的语义进行形式化与规范化描述是一项艰巨的任务。本体通常用来描述内容的语义,以实现基于语义的内容共享和集成。然而,手工构建本体通常耗费巨大,因此,有必要研究基于非结构化数据的本体学习技术。提出了从自然语言文本中学习本体的方法,定义了自然语言数据源到本体的映射规则并与现有方法进行了详细的比较,同时给出了应用实例及原型实现。分析表明,本文提出的方法在映射的完整性及正确性方面有较大提高。
本体 自然语言
本体学习(ontology learning)方法主要可以归为三类:手工的、半自动化、全自动化的方法。目前存在的本体构造方法多是手工的,需要领域专家的参与,在面对海量的内容时,手工方法费时、费力,而完全自动化的方法也不现实,因此,如何利用机器学习或统计等知识获取技术自动半自动化的从已有的数据资源中获取期望的本体,以降低本体构建的开销是一个迫切需要解决的问题。本文主要研究如何从非结构化(主要指自然语言文本)数据源获取期望的本体。
1 概述
自然语言文本是Web中大量存在的一类非结构化数据,因此,有必要从该类数据源中学习本体。依据文献,本体概念的获取方法主要有3类:基于语言学方法,基于统计学方法和混合方法。对于概念关系的获取,有基于模板的方法、基于概念聚类的方法、基于关联规则的方法、基于词典的方法和以上方法的混合。本文提出的方法是半自动化的,需要人工的参与。首先,借助于特定领域的核心本体与WordNet词典,挖掘出文本中包含的与该本体概念在语义上相近的概念以及频繁项集作为侯选概念,在人工参与下将侯选概念补充到核心本体中;然后挖掘与全部概念相关的关联规则,利用该关联规则形成概念间的侯选关系与实例,最终判定由用户来决定。
2 自然语言文本到本体模型的转换
借助特定领域的核心本体与WordNet,挖掘文本包含的与该本体概念在语义上相近的概念及频繁项集作为侯选概念,在人工参与下将侯选概念补充到核心本体中,步骤如图1所示。

图1 相关概念的获取流程
“拆词”:从核心本体概念的标识,获取与概念相关的词或词组。
“去频繁项”:将频繁出现并含有较少语义信息并的词从“拆词”获得的词集中去除。
“切词与标词”:获得输入词的词根及词性。本文采用Porter Stemming 算法完成“切词”步骤,采用QTAG算法完成“标词”步骤。
“同义词集”:借助WordNet,获得单词的同义词集合,继而获得单词的语义链(Semantic Chain),然后将语义链转化为向量表示。
“矢量化”:借助WordNet,用向量表示获得输入文本中单词的语义链,将向量进行标准化,即为每个分量计算权重。权重的计算采用TF*IDF规则产生,TF(term frequency)表示词频,IDF(inverse document frequency)表示逆文档频率,权重计算公式如下:
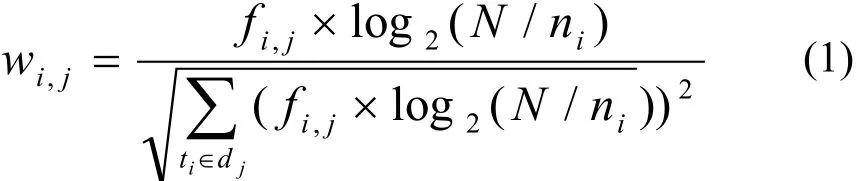
wi,j表示词ti在向量dj中的权重,fi,j为词ti在向量dj中的词频,N为向量总数,ni为包含词ti的向量数目,分母为归一化因子。
“匹配”:利用VSM方法,通过向量间的夹角余弦衡量单词的相似程度,计算公式如下:

根据结果选出与核心本体中概念相关的单词和句子。
用户从上述步骤得出的相关单词和句子中选择新的概念标识充实到核心本体,得到与特定文本相关的本体。采用关联规则挖掘算法,形成概念间的侯选关系与实例并添加到本体中。
给出从文本数据源生成本体的例子。采用清华大学的travelontology.owl作为旅游领域的核心本体,导入一篇桂林旅游的自然语言文本。图2显示了导入系统后的本体,可以进行概念及概念间关系、属性、实例的编辑添加,以充实核心本体,生成与导入内容相关的本体。
3 本体编辑及一致性检验
本文研发的管理系统支持由数据库、XML内容、自然语言文本到本体的转换,及现有本体的导入,形成基于本体的知识库。另外,内容管理系统提供本体的编辑及一致性检验功能,以消解可能的语义冲突。

图2 自然语言文本到本体的导入
4 结语
讨论了自然语言数据源到本体的转换,并与现有工作进行了详细的比较,在此基础之上开发了内容管理系统,实现了本体编辑和数据一致性检验,为实现面向语义的内容搜索奠定了基础。
[1]杜小勇等.本体学习研究综述.软件学报,2006(9).
[2]Lawrence S, Giles CL. Searching the World Wide Web. Science, 1998,280(5360):98−100.
[3]Alexander Maedche, Steffen Staab.Mining Ontologies from Text. In:Proc. Of th EKAW2000,LNAI1937.pp:18 9-202.2000.
[4]Felbaum.WordNet:an Electronic Lexical Database.MIT Press,Cambridge,Massachusetts,1998
[5]张剑,李春平.基于Word Net概念向量空间模型的文本分类.计算机工程与应用,2006(14).
齐婷婷)
猜你喜欢
开放教育研究(2020年2期)2020-03-31
计算机与生活(2018年3期)2018-03-12
中国科技期刊研究(2017年2期)2017-05-14
制造业自动化(2017年2期)2017-03-20
现代语文(2016年21期)2016-05-25
浙江大学学报(工学版)(2015年2期)2015-05-30
大连民族大学学报(2015年2期)2015-02-27
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
土木建筑工程信息技术(2013年4期)2013-10-17
