
基于概念的视频检索中概念语义匹配算法研究
2011-01-29 09:38:58张皓翔尚麟宇
泰山学院学报 2011年6期
张皓翔,尚麟宇
(北京交通大学轨道交通控制与安全国家重点实验室,北京 100044)
为了实现基于概念视频检索中从底层内容到查询的语义贯通,应用基于WordNet词典的语义相似度算法,通过对三种不同原理的算法对比应用,得出基于信息量算法在本应用中更有优势,语义匹配可以提高检索精度,最优映射数目为2至3个,以及在目前发展水平下,映射到合适的概念比检测器精度更合适四个重要结论.
语义视频检索;相似度算法;查询预处理;概念检测器过滤;映射数目
1 引言
统计显示,著名的视频共享网站YouTube每天新增6.5万部视频,网络视频量在以惊人的速度增加.基于概念的视频检索技术不用人工标注,直接根据视频内容建立中间语义概念进行索引,满足了应用需求[1-3].但是基于概念的视频在底层特征到上层用户查询之间存在着语义鸿沟,如何跨越语义鸿沟,实现语义上的贯通,成为人们的研究热点[1-2].
在目前的发展水平上看,基于语义概念的视频检索包括概念检测、查询到概念的匹配和结果融合三个核心内容[3],其中概念检测模块实现了从视频内容到语义概念的语义鸿沟跨越,但查询到概念的匹配通常采用布尔方法,即使是相似度计算也没有涉及语义.这样就导致了从查询到底层特征的语义中断.为了实现从查询到底层内容的语义贯通,引入基于WordNet词典的语义相似度算法[4],结合理论分析,对语义匹配进行研究,得到了语义贯通会提高检索精度,基于信息量的算法有优势,最优匹配数目以及现有条件下,匹配概念数目比较重要的结论.
2 相关工作
在查询到概念的映射模块,根据使用的特征不同可以分为:基于文本特征的映射;基于视觉内容的映射[5]等.在本文的实验中没有用到样例查询,只是对查询主题的文本描述,所以本文研究是基于文本特征的映射.基于文本的映射主要包括两步:
第一步是查询和概念的预先处理,如词根化,去除停用词,高频词,并进行相应的格式变换.第二步是映射.可以通过判断查询中是否包含概念描述中的词,来确定查询是否匹配到该概念,完成布尔匹配.或者通过一些相似度计算方法实现软匹配[6],如基于向量空间模型的相似度计算[3]语言模型[4]等.但是这些研究都没有涉及语义的层面,如“person”和“car”从词形或者词义上看都没有关系,语义上却有相关性,因为日常生活中,人经常是需要车作为代步工具的,这用布尔匹配或者向量空间模型是无法表示的.
WordNet语义词典是由Princeton大学研制出的联机英语词汇检索系统,根据词义而不是词形来组织单词.基于这种词典结构有很多种算法,文献[5,7,8]计算两个单词之间的相似度,[9]根据上下文建立向量计算形似度,[11]根据词典的路径长度计算相似度,[6]根据信息量计算相似度.另外在查询到概念映射模块,[9]只选择最优的一个概念,[10-11]的概念检测器集合比较小,都没有涉及检测器精度过滤这样的问题.
在本论文中,第3部分介绍用到的语义相似度算法,以及概念检测器过滤方法.第4部分介绍对概念视频检索实现语义贯通的实验,包括要解决最优映射数目和概念检测器过滤问题,最后是结论和进一步的工作.
3 语义匹配方法
WordNet核心组织原则是由同义词集合组成上下位关系,将单词由词形组织转化为语义组织.基于WordNet的语义相似度算法有三种原理.
3.1 基于路径长度的算法
针对WordNet的词典结构,很直观的计算相似度的方法是计算两个单词之间的路径长度.比如说要计算nickel和credit card的相似度,从结构树的分支nickel往上寻找到第一个同时包含这两个单词的概念,Medium of Exchange,从这个单词向下找到另外一个分支Credit Card,共有七步,可以据此得到两个单词的相似度.WUP和LCH是基于路径长度的算法.
3.2 基于信息量的算法
基于信息量的算法RES,JCN是根据单词在训练语料中的出现频率计算熵值得到相似度.
RES算法公式如下:

JCN算法公式如下:
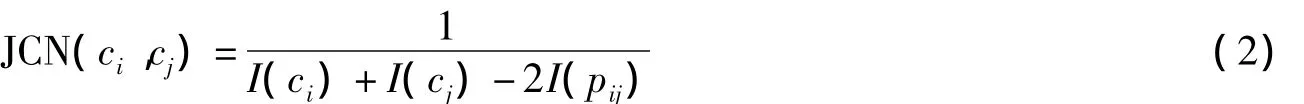
公式中的I表示熵值,即信息量.词典中单词的出现频率是从Brown Corpus of American English(100万个单词,涵盖新闻、自然科学领域等)语料库训练得到的.
3.3 基于二次共现信息的算法
基于二次共现信息的算法VECTORE和LESK是根据Harris的分布假设理论提出,分布假设理论指语义相似的词在同一语言文本中共同出现的概率相比于没有语义关系的词更大.因此根据词典中单词的注释信息建立二次共现上下文向量,计算两个单词向量空间的夹角余弦得到相似度.
这三种原理的方法都是基于WordNet语义词典,因此计算得到的是语义相似度.将其应用到基于内容的视频检索中,可以实现查询到中间概念的语义匹配.
3.4 概念检测器过滤方法
对每个概念检测器计算其可信度,公式如下,SHLF_i表示镜头S在第i个概念检测器中的产生概率,系统中我们设η=0.1,那么概念检测器K的可信度计算公式如下:
为了最大化这些概念检测器的精度,从TRECVID2007HLF任务中选择最优的6个结果进行融合.取列表中的前500个镜头,根据每个镜头在提交列表中的位置信息按如下公式计算:

其中Contains(Sij)表示列表j中是否包含镜头Si.maxPos表示列表里最大的排序数,这里为500. Pos(Sij)表示镜头Si在列表j中的排序.公式的前半部分表示有多少个列表中包含镜头Si,后半部分进一步描述镜头Si在这些列表中的重要程度.
4 实验
基于语义概念的视频检索包括概念检测、查询到概念的匹配和结果融合三个核心内容,如下图1所示.

图1 基于概念的视频检索框架图
在底层内容到中间语义概念模块,采用香港城市大学训练的374个LSCOM基于局部描述子的概念检测器,用SVM支持向量机方法训练得到.在结果融合模块,工作是把多个排序结果融合为一个,即最终的视频检索结果.可以采用1∶1的系数进行融合[5],在本实验中,采用有权重的融合方法.
实现语义的贯通,需要跨越查询和中间概念的语义鸿沟.在这个模块,采用国际检索会议TRECVID2007年的24个查询主题,应用语义相似度算法后,应该得到如表1所示的结果.
其中“0197”到“0220”是TRECVID2007年的24个查询主题编号,“Actor”到“Yasser_Arafat”是香港城市大学训练的374个概念.
将三种原理的六种语义相似度算法分别进行计算得到如表所示的结果,来验证信息量算法在基于内容视频检索上的优势.

表1 相似度比较结果示意图
根据不同的语义相似度算法得到24个主题的检索结果,用Trecvid评测工具对结果进行评测.
4.1 最优映射数目实验
同布尔映射不同的是,语义匹配的结果经过归一化和排序之后,需要选择一定数目的概念,数目不同对结果的影响也不同.如果选择的概念数目少,会丢失查询主题信息的可能;如果选择的概念数目多,会造成混入噪声的可能.
对每个算法的每个主题选择2~5个概念进行实验,如对WUP算法计算出来的查询和概念的相似度,选择前2个概念融合结果,计算24个查询主题的平均MAP值,再选择三个概念和四个概念,分别计算平均MAP值,将三个值进行比较,得到的最好结果对应的映射概念数目视为最优.

图2 最优映射概念数目实验结果
图2中的横轴代表六种算法,每种算法的直方图从左到右依次代表映射2到5个概念,纵轴代表映射精度,即平均MAP值.从实验结果来看,除了JCN算法的最优映射数目为3个,其它的算法映射两个概念得到最好的结果,随着映射概念数目的增多,融合效果会变差,所以最优的映射个数是2~3个.
4.2 算法应用结果比较
将语义相似度算法应用到基于概念的视频检索中,根据实验数据,对不同原理的语义匹配效果进行分析.
表2是各个算法的MAP值:(映射概念数目2个到3个的结果算术平均)

表2 语义匹配效果
在视频检索中采用布尔匹配的映射方法,得到的检索结果平均MAP值为0.0156,所以可以从表3中看出,上述六种语义算法的应用相比于布尔匹配都可以提高检索精度.
从图2中可以看到,基于路径长度的算法LCH要优于WUP,基于二次共现信息向量的算法VECTOR要优于LESK,基于信息量的算法RES和JCN结果相当.将查询主题映射到2个概念时,RES的应用效果最好,将查询主题映射到3个概念时,JCN的应用效果最好.这两种算法都是基于信息量的语义算法,所以基于信息量的算法在视频检索的语义匹配占有优势.
而基于二次共现信息向量方法,由于对词性没有限制,应该体现应用优势,在这里可能是数据中的名词居多,因此这两种算法特有的优势没有发挥出来.
相比于前两种原理的算法,基于信息量的相似度算法减少了词典结构不合理性对结果的影响,融入了人类语言中不同单词出现的频率对语义的作用,所以会更有优势.
4.3 语义概念过滤
从查询到中间概念的匹配采用语义匹配方法之后可以提高检索的精度,并且用基于信息量的相似度算法为最好.但就目前的研究情况,关于语义匹配的一个问题是概念训练数目不够多并且精度不够高.
美国CMU Alex G.Hauptmann领导的研究组得出人工语义概念研究的理论基础:(1)关于语义概念集的大小:用几千个(<5000)概念就能达到很高的检索精度,并且每个概念的检测精度不用太高(也不能低于MAP=10%),可以达到和文本检索相当的效果(MAP=65%).
从这个理论出发,目前比较成熟的概念检测器如香港城市大学的374个LSCOM基于局部描述子的概念检测器,相对于5000个概念,数目显然很少,并且训练的概念精度也都不是很高,需要过滤.因此在语义匹配问题上出现了选择题:(1)映射到合适的概念,但有些概念检测器的精度比较低;(2)映射到较少的概念,但是概念检测器的精度较高.这两种情况下的语义匹配结果是不同的.下面的实验验证了在目前的条件下,第一种情况的语义匹配结果更好.
结果按照精度从高到低的顺序排序,选择域值为1,得到187个概念进行语义匹配实验,依次是六种算法映射到2~4个概念,得到最后的视频检索精度(平均MAP值)如表3所示:

表3 概念检测器过滤实验结果
从表中可以看到,匹配概念数目为2的时候,只有三种方法的平均检测精度上升,WUP、LCH和RES算法的检测精度值甚至下降.主题映射到3个概念时,应用效果有了明显的下降.
所以在目前的研究水平上,映射到合适数目的概念比过滤检测器精度效果更好.
5 结论和进一步工作
通过以上的实验,我们得到如下的结论:
(1)在查询到概念的匹配模块,采用语义匹配方法会实现语义贯通,提高检索精度,使得结果从平均MAP0.0156提高到0.02235(RES),0.02145(JCN);
(2)基于WordNet的相似度算法中,基于信息量的算法减少了词典结构不合理性对结果的影响,融入了单词频率对语义的作用,因此更有优势;
(3)语义匹配最优映射概念数目为2~3个.从实验分析,映射到一个概念的时候,会丢失查询主题信息,映射到4个以上概念的时候,会引入误匹配噪声,对结果产生消极影响;
(4)在概念检测器目前的发展水平上,将查询主题匹配到合适数目的概念比映射精度较高的概念效果要好.结合4.3节理论分析,如果有5000个概念,即使精度比较低,也能得到满意的结果,但是实验中用到的374个概念相对于5000概念,显然比较少,所以单纯提高检测器精度并不能改善结果,大规模的训练语义概念应该是今后发展的重点.
本论文在基于概念的视频检索中实现了语义匹配,从查询到底层内容的语义实现了贯通,提高了检索精度.下一步的工作是针对查询和概念的零概率问题,提出统计和规则相结合的查询扩展方法,用扩展后的查询进行概念匹配,以期提高检索精度.
[1]Han J,Ngan K N,LiMingjing,etal.Amemory learning framework for effective image retrieval[J].IEEE Transactionson Image Processing,2005,14(4):511-524.
[2]魏维,游静,刘凤玉,许满武.语义视频检索综述[J].计算机科学,2006,2(10).
[3]Pedersen T.,Patwardhan S.,Michelizzi J.Wordnet::similarity-measuring the relatedness of concepts[J].In AAAI,2004,(9).
[4]D.Wang,X.Li,J.Li,B.Zhang.The importance ofquery-concept-mapping for automatic video retrieval[J].In ACM Multimedia,2007,(11).
[5]刘群,李素建.基于《知网》的词汇语义相似度计算[J].中文计算语言学,2002,(7):59-76.
[6]X.Li,D.Wang,J.Li,B.Zhang.Video search in concept subspace:A text-like paradigm[J].In Proc.of CIVR,2007,(8).
[7]Z.Wu,M.Palmer.Verb semantic and lexical selection[J].In Annual Meeting of the ACL,1994,(12).
[8]Resnik P.Using information content to evaluate semantic similarity in a taxonomy[J].In IJCAL,1995,(6).
[9]C.G.Snoek,B.Huurnink,L.Hollink,M.de Rijke,G.Schreiber,M.Working.Adding semantics to detectors for video retrieval[J].IEEE transactions on Multimedia,2007,(11).
[10]A.Haubold,A.P.Natsev,M.R.Naphade.Semantic multimedia retrieval using lexical query expansion and model-based reranking[J].In Proc.of ICME,2006,(5).
[11]M.G.Christel,A.G.Hauptmann.The use and utility of highlevel semantic feature extraction[J].In Proc.of CIVR,2005,(7).
猜你喜欢
中学化学(2024年4期)2024-04-29 22:54:35
西南交通大学学报(2018年5期)2018-11-08 10:59:16
中国交通信息化(2017年9期)2017-06-06 07:14:57
新闻传播(2016年11期)2016-07-10 12:04:01
中国民族医药杂志(2016年5期)2016-05-09 07:43:50
工业设计(2016年11期)2016-04-16 02:49:43
作文大王·低年级(2016年3期)2016-03-11 00:48:53
计算机工程(2015年4期)2015-07-05 08:29:20
武夷学院学报(2014年5期)2014-07-19 10:08:27
河南科技(2014年22期)2014-02-27 14:18:12
