
普通话儿童词汇相邻性测试词表总体信度评估
2011-01-25 10:26:24王素菊冯洁芬刘海红李淑静杨宜林
首都医科大学学报 2011年6期
王素菊 孔 颖 冯洁芬 刘海红 李淑静 杨宜林 刘 莎
(首都医科大学附属北京同仁医院耳鼻咽喉头颈外科,北京市耳鼻咽喉科研究所,教育部耳鼻咽喉头颈外科重点实验室,北京100730)
言语测试对评估和监测听力损失对交流能力的影响、评估助听装置的效果起到了重要作用。一个理想的言语测试材料要求测试结果准确可信,对不同的测试条件有较高的敏感性,并与真实世界的言语感知能力很好相关[1]。近年来,我国的许多学者[2-3]相继开发了适合汉语语言特点的言语测听材料,但未能在临床中得到普遍使用,在词表的验证过程中,还需要在词表信度、效度和敏感度等标准化方面作进一步研究。随着我国听力学理论体系的逐步完善,发展规范化的言语测听材料越来越为我国听力学家所重视。
在上个世纪80年代末Lucy[4]提出了基于心理语言学言语听辨邻域的邻域激活模型理论,提出了单词的出现频率和相似邻居词数目的多少影响儿童口语识别的感知过程。Kirk等人依据NAM理论开发了英文版的词汇相邻性测试词表(lexical neighborhood test,LNT;注:这是单音节词表)和词汇相邻性多音节词表(multisyllabic lexical neighborhood test,MLNT;注:这是双音节和三音节词表,因此称多音节词表)来研究人工耳蜗植入儿童言语听辨发展过程[5]。随后各国相继建立了适合自己母语特征的词汇相邻性测试材料。张宁、刘莎等[6-8]也依据汉语语言的特点开发了普通话版的词汇相邻性测试词表并已经过初步的等价性验证。本文旨在对普通话儿童词汇相邻性测试词表的数字录音版本进行总体信度评估,以使测试材料符合临床实践的可靠性和有效性要求。
1 材料和方法
1.1 测试材料
普通话儿童词汇相邻性测试词表(mandarin lexical neighborhood test,M-LNT),其中包括单音节词表和双音节词表,全称为普通话儿童词汇相邻性单音节词表(mandarin monosyllable lexical neighborhood test,MLNT-M)和普通话儿童词汇相邻性双音节词表(mandarin disyllable lexical neighborhood test,M-LNT-D)。其中M-LNT-M有6张词表,包括易词表3张和难词表3张,每表20个字,练习表1张,每表10个字;M-LNT-D有6张词表,包括3张易词表和3张难词表,每表20个词,练习表1张,每表10个字。测试材料经过数字化录制,采用电脑随机播放。
1.2 测试对象
受试者为随机从北京高校中选取的听力正常者52名,以汉语普通话为日常交流方式,无听力障碍及耳科疾病史。其中男 23例,女 29例,平均年龄(22.9±1.8)岁。双耳平均听阈(500,1 000,2 000,4 000 Hz)为(4.1±3.2)dB HL,声导抗测试正常(双耳鼓室图A型,声反射阈均可引出)。
1.3 测试地点和设备
测试地点为标准隔声室,背景噪声小于20 dB (A);GSI-61纯音听力计的channel 1的Ext B通道作为言语输出通道;用1 000 Hz纯音作为校准音,使用B&K Type1613声级计、Type4144电容传声器、Type4152仿真耳,参照国际标准进行校准,校准耳机为TDH-50P,将言语听力级(0 dB HL)校准为20dB的言语声压级(dB SPL)。所用测试设备均已由北京市计量研究院校准。
1.4 实验设计和方法
预实验以小步距多强度设点的原则,获得覆盖强度—识别函数曲线的20%~80%言语识别率强度的最小位点。采用随机区组设计方法,每人随机分到奇数位或偶数位强度组,每人每张表按照最小位点强度数进行测试。
测试在双室隔声室中进行。根据受试者的平均听阈选取听力较好的耳朵单侧聆听词表。测试前对受试者进行指导,告知测试目的,要求集中注意力聆听后复述测试项,鼓励猜测。测试词表按照由易到难的顺序依次播放词表。测试前播放练习表让受试者熟悉过程,避免出现情绪紧张。测试先选择识别率为40%~60%的强度给声,避免低强度给声时造成受试者缺乏信心以及高强度给声时造成的学习记忆效应。测试时间约60 min,测试中注意受试者的状态,中途适时安排两次休息时间,以克服疲劳而造成的非随机误差。
测试者以耳机监听方式判断正误,标准为每一音节的声母、韵母和声调都正确时才得分,计算正确率,作为该测试词表的言语识别率。计算公式为:
正确率=复述正确词的得分×100%=复述正确词数/总词数×100%
1.5 统计学方法
采用SPSS 13.0统计软件和Matlab7.1对4种词表的数据进行分析。
1.5.1 词表的等价性分析
本词表根据词汇测试项评价的二项分布理论,Thornton A R和Raffin M J等提出[9]对于测试结果仅以测试项的正误来表示的开放测试材料可用二项分布来评估。由二项分布理论公式可知不同得分对应不同的随机误差,以n个测试项的识别率的标准差(standard deviation,SD)来表示:

其中n是测试项的数目,p是得分。为了稳定数据之间的变异,Thornton和Raffin又对数据进行了反正弦变换处理。Studerbaker G A[10]进一步提出对得分进行合理化的反正弦变换的方法可以使随机误差不再与具体得分相关,所有得分的随机误差都大体一致;除去两端得分,其他所有得分在均数周围呈正态分布;平均得分和方差彼此不相关;在大部分得分区域内,得分增长或减少的可能性一致。将原始得分数值进行合理化的反正弦变换(rationalized arcsine units,RAU)

其中X为正确回答数目,N为表内测试项数目,R为变换后得分。使用Matlab 7.1进行数据变换。将数据进行变换后,4类词表的数据均满足正态分布。由于数据满足随机区组设计,因此对于满足正态分布的数据采用随机区组设计方差分析。
1.5.2 词表的P-I曲线
根据词表言语识别率特性表述方式即强度-识别函数曲线,采用Matlab 7.1软件进行数据处理。使用Logistic回归函数拟合获得函数曲线、斜率和阈值:

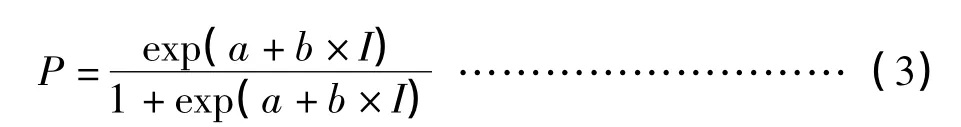
其中P为识别率,I为强度,a是回归曲线截距,b是曲线斜率[11]。
根据言语识别阈的定义将50%识别率所对应的强度视为该测试表的阈值,由公式2推导出阈值强度为-a/b,在20%~80%的线性增长区域内求出其斜率b。
2 结果
2.1 M-LNT词表的等价性
M-LNT的4类词表获得20%~80%的识别率范围所需的强度,分别为6个强度点,双音节易词表为16、20、22、24、26、30dB(SPL),双音节难词表为18、22、26、29、33、37 dB(SPL),单音节易词表为16、21、26、31、36、41 dB(SPL),单音节难词表为19、25、31、37、43、49 dB(SPL)。每人每张表可按照最小位点强度数共测试3个强度。
本实验中采用随机区组设计方法,根据统计分析得出双音节易词表、双音节难词表、单音节易词表和单音节难词表在各强度下获得的识别率数据总体均呈正态分布和方差齐性,采用随机区组方差分析,结果显示双音节易词表间、双音节难词表间和单音节易词表间、单音节难词表间,4类的各词表间差异均无统计学意义,详见表1、2。

表1 单音节词表统计学分析结果Tab.1 Statistical analysis of monosyllable word lists

表2 双音节词表统计学分析结果Tab.2 Statistical analysis of disyllable word lists
2.2 M-LNT词表的得分—强度曲线(P-I function)
使用Matlab 7.1软件以Logistic回归函数进行非线性拟合,得出4类词表的P-I曲线(图1-4)。通过对合理化反正弦变换后的得分进行计算,得出每张词表的言语识别阈值、20%~80%斜率和50%斜率(表3)。
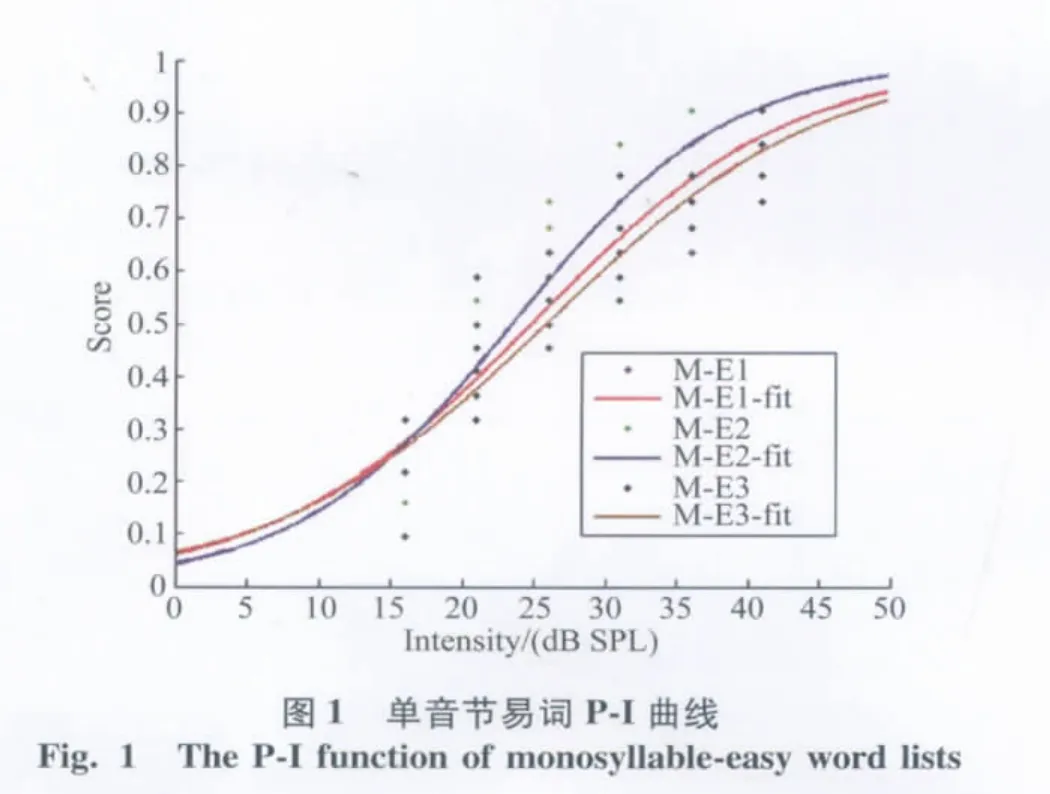
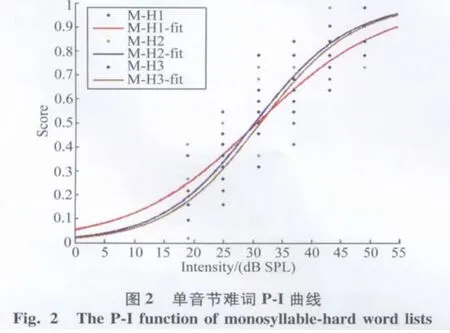
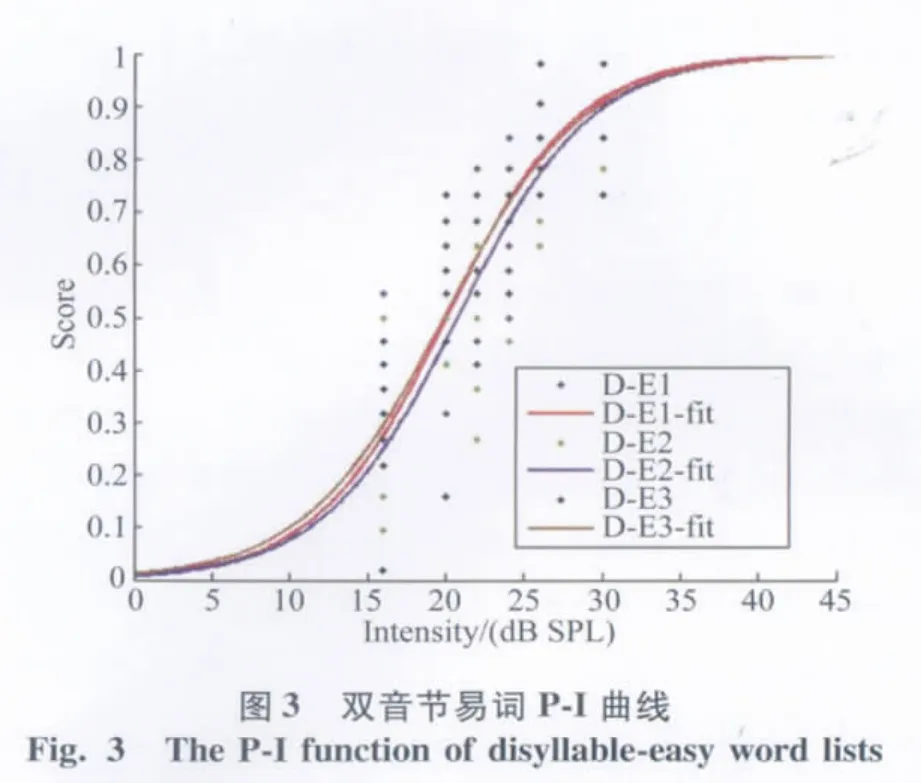
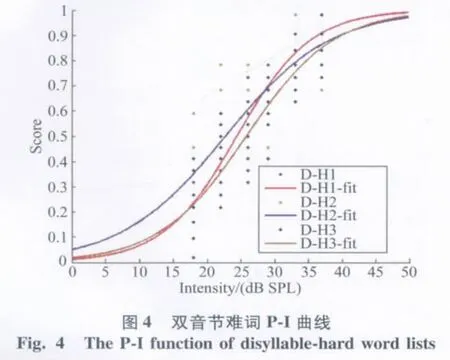
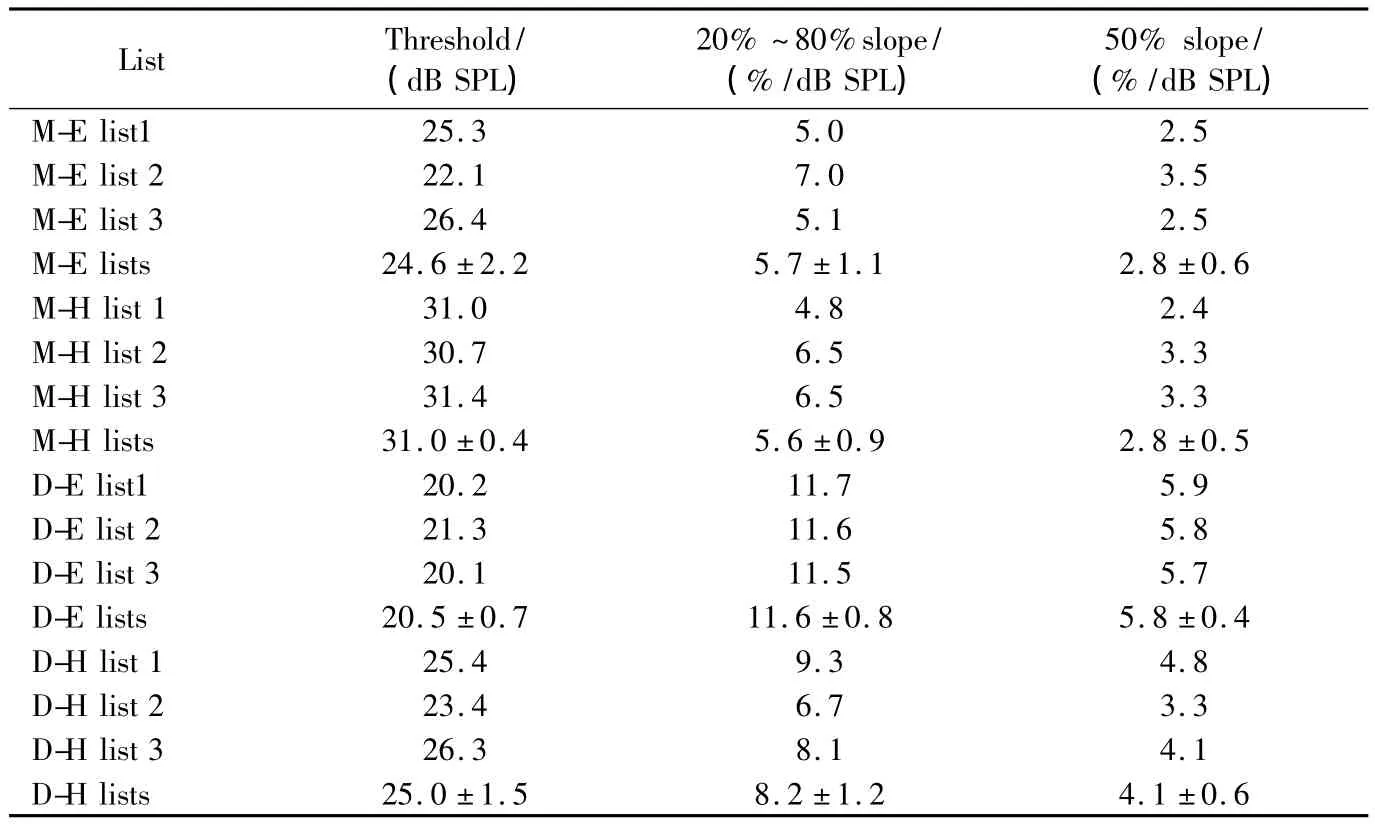
表3 各词表的阈值和斜率Tab.3 Threshold and slope of 4 kinds of word list
其中双音节易词、双音节难词、单音节易词、单音节难词词表的平均言语识别阈分别为(20.5±0.7)、(24.8±2.1)、(24.6±2.2)、(31.0±0.4)dB SPL。双音节词表的阈值低于单音节词表,易词词表的阈值低于难词词表。20%~80%线性范围斜率代表词表整体走向,双音节易词、双音节难词、单音节易词、单音节难词词表分别为11.6、8.2、5.7、5.6%/dB SPL,其中双音节易词斜率最大,P-I函数曲线走形最陡峭,接下来依次为双音节难词、单音节易词、单音节难词,代表阈值附近的50%正确率时的P-I曲线斜率与20%~80%斜率变化趋势一致。
2.3 M-LNT词表的临界差值(critical difference,CD)
利用合理化反正弦变换后的得分值公式换算出95%置信度下词表在每一种强度下的临界差值[9]:
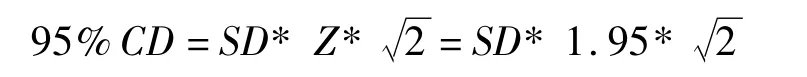
其中SD为标准差,Z是标准化的随机变量值(95%置信区间是1.96),计算得出单音节易词表、单音节难词表、双音节易词表、双音节难词表的总体临界差值分别为±22.2、±26.1、±32.7、±29.9%(表4-表7)。每一类词表在各强度下的言语识别率(均值±标准差,),详见表8~11,从中可以得出在每种词表所给出的5个强度点基本覆盖了20%~80%的言语识别得分范围。

表4 单音节易词表总体和6个强度下信度指标的比较Tab.4 The reliability parameters of monosyllable-easy word lists %

表5 单音节难词表总体和6个强度下信度指标的比较Tab.5 The reliability parameters of monosyllable-hard word lists %

表6 双音节易词表总体和6个强度下信度指标的比较Tab.6 The reliability parameters of disyllable-easy word lists %

表7 双音节难词表总体和6个强度下信度指标的比较Tab.7 The reliability parameters of disyllable-hard word lists %
表8 单音节易词表各强度下的言语识别率Tab.8 The word recognition scores of monosyllable-easy word lists(s)%

表8 单音节易词表各强度下的言语识别率Tab.8 The word recognition scores of monosyllable-easy word lists(s)%
Intensity/dB SPL M-E list1 M-E list2 M-E list3 16 20.7±7.8 21.6±13.2 19.0±9.3 21 46.3±9.2 48.3±8.8 44.3±7.8 26 54.5±4.9 57.4±8.7 51.6±6.1 31 66.1±4.9 72.5±8.0 63.6±7.0 36 74.4±8.0 83.9±7.1 72.3±4.4 41 85.8±4.0 89.6±5.8 81.2±6.4
表9 单音节难词表各强度下的言语识别率Tab.9 The word recognition scores of monosyllable-hard word lists(s) %
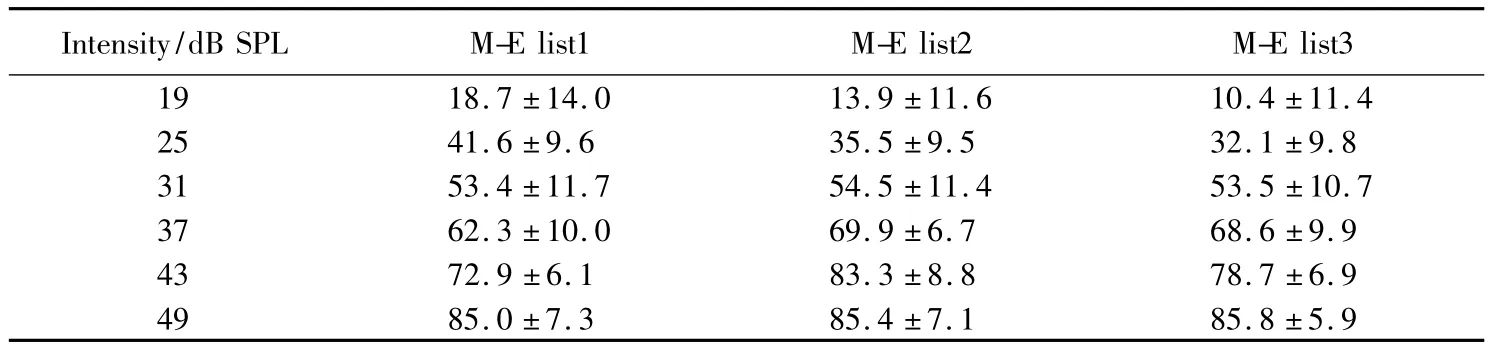
表9 单音节难词表各强度下的言语识别率Tab.9 The word recognition scores of monosyllable-hard word lists(s) %
Intensity/dB SPL M-E list1 M-E list2 M-E list3 19 18.7±14.0 13.9±11.6 10.4±11.4 25 41.6±9.6 35.5±9.5 32.1±9.8 31 53.4±11.7 54.5±11.4 53.5±10.7 37 62.3±10.0 69.9±6.7 68.6±9.9 43 72.9±6.1 83.3±8.8 78.7±6.9 49 85.0±7.3 85.4±7.1 85.8±5.9
表10 双音节易词表各强度下的言语识别率Tab.10 The word recognition scores of disyllable-easy word lists(±s) %
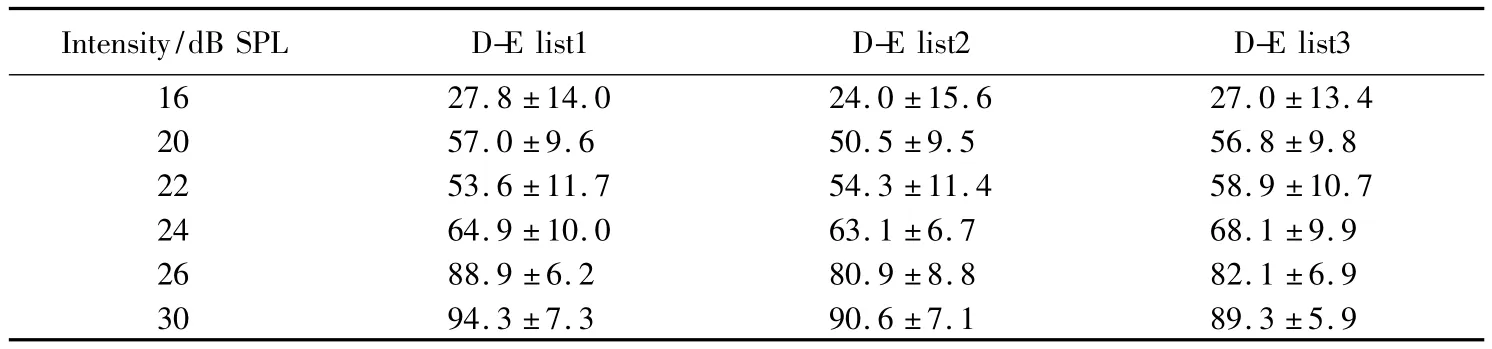
表10 双音节易词表各强度下的言语识别率Tab.10 The word recognition scores of disyllable-easy word lists(±s) %
Intensity/dB SPL D-E list1 D-E list2 D-E list3 16 27.8±14.0 24.0±15.6 27.0±13.4 20 57.0±9.6 50.5±9.5 56.8±9.8 22 53.6±11.7 54.3±11.4 58.9±10.7 24 64.9±10.0 63.1±6.7 68.1±9.9 26 88.9±6.2 80.9±8.8 82.1±6.9 30 94.3±7.3 90.6±7.1 89.3±5.9
表11 双音节难词表各强度下的言语识别率Tab.11 The word recognition scores of disyllable-hard word lists(s) %
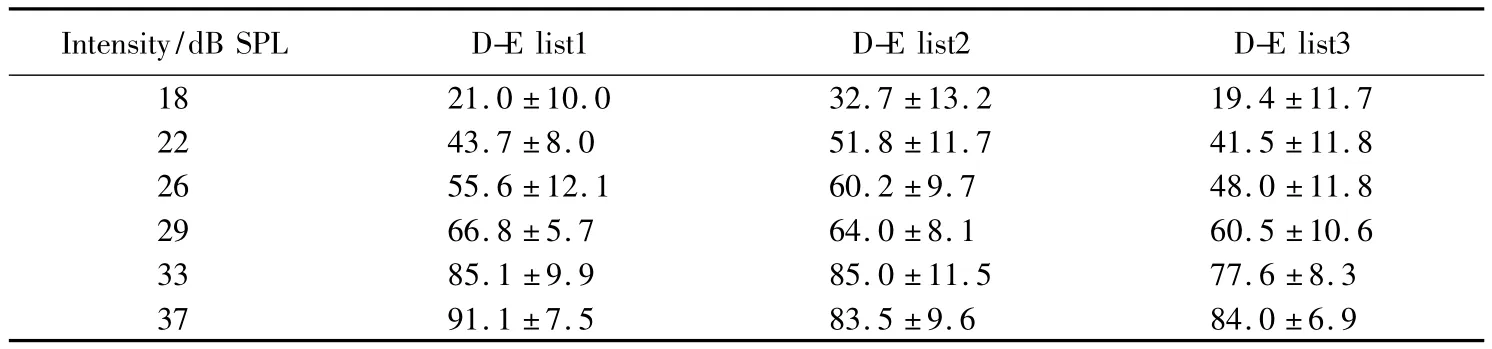
表11 双音节难词表各强度下的言语识别率Tab.11 The word recognition scores of disyllable-hard word lists(s) %
Intensity/dB SPL D-E list1 D-E list2 D-E list3 18 21.0±10.0 32.7±13.2 19.4±11.7 22 43.7±8.0 51.8±11.7 41.5±11.8 26 55.6±12.1 60.2±9.7 48.0±11.8 29 66.8±5.7 64.0±8.1 60.5±10.6 33 85.1±9.9 85.0±11.5 77.6±8.3 37 91.1±7.5 83.5±9.6 84.0±6.9
3 讨论
3.1 言语测试词表的P-I曲线特性
言语测试中言语识别率与刺激信号的强度是相关的,P-I曲线描述了这一相关现象。正常人的P-I曲线呈侧向拉伸的S型,得分随着强度的增加而增加,并在强度上升一定程度后趋于稳定,从而达到最大言语识别率,本实验P-I曲线图与上述规律相符合。P-I曲线的形状可以由言语识别阈和斜率2个参数来描述,言语识别阈是达到50%言语识别率时的刺激信号强度;斜率是识别率受刺激信号强度影响的程度,也是言语测听材料信度和敏感度的重要参数。测试项之间难度相近的测试表P-I曲线斜率较大,包含的冗余信息较多、词语熟悉度较高,斜率也较大,即P-I曲线比较陡峭。
普通话儿童词汇相邻性测试词表是基于心理听辨领域的邻域激活模型理论(neighborhood activated model,NAM)研发的,NAM理论提出,一个有效的信号输入可以激活记忆中一套声学—音位特征相似的词汇,激活水平与刺激信号的相似度是成比例的,即竞争性词的词频以及词汇特征匹配程度,决定着提取的目标词的难易。出现频率高而相似邻居数较少的词汇(易词)比出现频率低而相似邻居数较多的词汇(难词)容易识别,同样冗余信息较多的双音节词汇比单音节词汇容易识别。Kirk K I等[5,12]在听力正常儿童和人工耳蜗儿童的研究中都证明了这一理论。Liu C等[8]在听力正常的汉语普通话儿童中也得到了同样的结果,即易词的识别得分高于难词的识别得分,双音节词的识别得分高于单音节词的识别得分。本实验M-LNT单音节易词表、单音节难词表、双音节易词表和双音节难词表平均言语识别阈分别为(24.6± 2.2)、(31.0±0.4)、(20.5±0.7)、(24.8±2.1)dB SPL,双音节词表阈值比单音节词表阈值低,易词表阈值比难词表阈值低,表明在本测试中双音节词识别易于单音节词,易词比难词容易识别,与之前研究相符。Nissen S L等[13]研究的汉语成人双音节词测试材料的P-I曲线平均斜率为6.3%/dB(男声)和7.3%/dB (女声)。Nissen S L等[14]研究粤语版的双音节词在正常成人中P-I曲线平均斜率为7.5%/dB(男声)和7.6%/dB(女声),同时Nissen S L等[15]也研究得出汉语普通话成人三音节词测试材料的P-I曲线平均斜率为11.3%/dB(男声)和12.1%/dB(女声)。本实验中双音节难易词表的斜率分别为8.2%和11.6%,单音节难易词表的斜率分别为5.6%和5.7%,双音节词的冗余度高于单音节词,斜率也大于单音节词,P-I曲线的走形趋势较陡,结果与之前相符。Dirks D D等[16]对根据邻域激活模型编制的难易词表分析比较得出易词斜率比难词斜率大,本实验中M-LNT单音节和双音节的易词斜率都大于难词斜率,表明在词汇的习得过程中易词的习得比难词容易,本实验也表明了这一规律。
3.2 言语测试词表的总体信度
信度是描述测听材料可靠性的指标,可靠性包括了得分在多次测试中的稳定性和多张表之间的一致性,也就是复测信度和复本信度,其中对于复本信度的评价包括统计学分析上的等价性以及表间的变异度。信度以变异度的大小为指征,变异度小,则信度高[3]。变异度表现在P-I曲线斜率与阈值的一致性以及两表得分的临界差值。其中临界差值也可以作为复测信度的评价指标。
为评估患者在治疗和干预的不同阶段的疗效,需要在不同时间对同一患者进行相同条件下的多次言语识别能力测试,为了避免受试者对单一测听材料多次测试产生记忆影响测试结果的比较,就需要每套测试材料具有多张等价的词表,因此在词表的开发过程中等价性验证是必不可少的步骤。本实验经随机区组设计的方差分析表明4类不同性质的词表间差异无统计学意义,即每类词表表间等价。其结果与Liu C等[8]在正常儿童中的研究结果一致。测听材料的等价性与P-I曲线的斜率也有相关性,曾有报道[17]测试项之间的同质性越好,P-I曲线的斜率越陡峭。本实验结果得出双音节难易词表的斜率分别为8.2%和11.6%,单音节难易词表的斜率分别为 5.6%和5.7%,也表明了词表同质性较好,可靠性较高。
临界差值也是对于复本信度评价的一个重要指标,它描述了表间的变异度。临界差值也可以作为复测信度的评价指标,对于同一患者前后2次测试得分的差异必须高于随机误差即临界差值[18],来评价其复测信度。同样的,临界差值也是复本信度的重要评价指标,也就是对于同一患者同一条件下先后分别测试2张内容不同的表,两表得分的差异高于随机误差时表明有差异性[19]。从本实验得出M-LNT单音节易词表、单音节难词表、双音节易词表、双音节难词表的总体临界差值分别为±22.2%、±26.1%、±32.7%、±29.9%,也可以看出单音节词比双音节词的临界差值要小,而双音节词冗余信息比单音节词多,比单音节词简单,表明词表越简单临界差值越小。
3.3 言语测试词表的敏感度
敏感度也称区分度,是指某测试所能区分的不同受试者或不同测试条件下言语识别率的最小差异[20]。测试词表的敏感度可用P-I曲线的斜率来描述,斜率越大,得分对强度越敏感。言语识别率接近50%时斜率最大,敏感度最高,但同时变异度会较大,信度较差;而高敏感度的材料在言语声压级上的细微的增加就会使识别率变化水平超出随机误差波动范围,易于得出可靠结论[3]。因此测听材料要在高敏感度与信度之间取得平衡。本实验结果M-LNT单音节易词表、单音节难词表、双音节易词表和双音节难词表20%~80%斜率分别为6.1、5.9、11.6、8.0%/dB SPL,双音节词表斜率比单音节词表要大,敏感度更高,也表明词表容易程度越高,敏感度越高,符合词表建立的基本原则。
本实验通过对普通话儿童词汇相邻词表的分析,表明其总体信度可靠,并且获得了该测试材料的P-I曲线,建立了M-LNT词表言语识别率的基准曲线。此外McArdle R A等[21]指出对于正常年轻人等价性测试的词表,可能对有听力损失的人来说是不等价的,因此要得到一套完善有效的专业化测听材料,并最终应用于临床助听装置使用者,还需要进一步在人工耳蜗使用者中进行一系列的临床验证,这也是我们下一步要进行的工作。
[1] Mackersie C L.Test of speech perception abilities[J].Curr Opin Otolaryngol&Head and Neck Surg,2002,10:392-397.
[2] 卜行宽,倪道凤.推进中文言语测听材料的标准化和临床应用[J].中华耳科学杂志,2008,6(1):9-10.
[3] 郗昕.言语测听工具的效度、信度和敏感度[J].中华耳科学杂志,2008,6(1):1-6.
[4] Lucy P A,Pisoni D B,Goldinger S D.Similarity neighborhood of spoken word.In Altmann G T M(Ed.).Cognitive model of speech processing:psycholinguisti and computational perspectives[M].Cambrige,MA:MIT Press.1990.
[5] Kirk K I,Pisoni D B,Osberger M J.Lexical effects on spoken word recognition by pediatric cochlear implant users[J].Ear Hear,1995,16(5):470-481.
[6] 张宁,刘莎,盛玉麒,等.普通话儿童词汇相邻性单音节词表的编制[J].听力学及言语疾病杂志,2009,17(4):313-317.
[7] 张宁,刘莎,盛玉麒,等.普通话儿童词汇相邻性多音节词表编制研究[J].中华耳科学杂志,2008,6(1):30-34.
[8] Liu C,Liu S,Zhang N,et al.Standard-Chinese Lexical Neighborhood Test in normal-hearing young children[J].Int J Pediatr Otorhinolaryngol,2011,75(6):774-781.
[9] Thornton A R,Raffin M J.Speech discrimination scores modeled as a binomial variable[J].J Speech Hear Res,1978,21(3):507-518.
[10]Studebaker G A.A“rationalized”arcsine transform[J].J Speech Hear Res,1985,28(3):455-462.
[11]冀飞,郗昕,陈艾婷,等.汉语普通话单音节测听字表的等价性研究[J].中华耳科学杂志,2008,6(1):17-20.
[12]Kirk K I,Miyamoto R T,Lento C L,et al.Effects of age at implantation in young children[J].Ann Otol Rhinol Laryngol Suppl,2002,189:69-73.
[13]Nissen S L,Harris R W,Jennings L J,et al.Psychometrically equivalent mandarin bisyllabic speech discrimination materials spoken by male and female talkers[J].Int J Audiol,2005,44(7):379-390.
[14]Nissen S L,Harris R W,Channell R W,et al.The development of psychometrically equivalent Cantonese speech audiometry materials[J].Int J Audiol,2011,50(3):191-201.
[15]Nissen S L,Harris R W,Jennings L J,et al.Psychometrically equivalent trisyllabic words for speech reception threshold testing in Mandarin[J].Int J Audiol,2005,44 (7):391-399.
[16]Dirks D D,Takayana S,Mashfegh A.Effects of lexical factors on word recognition among normal-hearing and hearingimpaired listeners[J].J Am Acad Audiol,2001,12(5):233-244.
[17]Wilson R H,Carter A S.Relation between slopes of word recognition psychometric functions and homogeneity of the stimulus materials[J].J Am Acad Audiol,2001,12(1):7-14.
[18]郗昕,冀飞,赵阳,等.一组等价的普通话音位平衡单音节短表的总体信度[J].中华耳科学杂志,2008,6(1):21-25.
[19]Gelfand S A.Optimizing the reliability of speech recognition scores[J].J Speech Lang Hear Res,1998,41(5):1088-1102.
[20]冀飞.汉语单音节测听词表的开发和等价性验证[D].北京:第四军医大学生物医学工程系,2007.
[21]McArdle R A,Wilson R H.Homogeneity of the 18 quick SIN lists[J].J Am Acad Audiol,2006,17(3):157-167.
猜你喜欢
英语世界(2021年13期)2021-01-12 05:47:51
小学生作文辅导(2020年16期)2020-11-25 17:06:10
快乐作文(1.2年级)(2019年9期)2019-09-10 02:48:13
考试周刊(2019年9期)2019-01-26 10:24:24
西藏大学学报(自然科学版)(2016年1期)2016-11-15 05:23:31
国家图书馆学刊(2016年2期)2016-10-09 06:19:31
小天使·一年级语数英综合(2015年6期)2015-05-14 05:50:08
声学技术(2014年2期)2014-06-21 06:59:08
中国音乐教育(2014年11期)2014-05-18 09:58:28
图书馆建设(2012年3期)2012-10-23 05:16:30
