
一种基于关键词的网页搜索结果多样化方法*
2011-01-24 02:51林古立彭宏马千里韦佳覃姜维
华南理工大学学报(自然科学版) 2011年5期
林古立 彭宏 马千里 韦佳 覃姜维
(华南理工大学计算机科学与工程学院,广东广州510006)
现在的互联网已经成为全球最大的信息库,用户要在浩瀚的信息海洋中检索需要的信息,搜索引擎扮演着非常关键的角色.但现有大多数搜索引擎在根据相关度对结果文档进行排序时,都是独立考虑每个结果文档与用户查询的相关性,并没有考虑文档与文档之间的相似性,这样的排序结果容易造成冗余[1].另一方面,用户使用的查询词通常都比较短,搜索引擎很难分辨用户所表达的查询意图.例如,用户使用查询词“苹果”时,他有可能想查询一种水果,也可能是想查询苹果电脑.只返回与某一种意图相关的结果,无法满足想搜索其它信息的用户.另外,用户往往期望能在搜索引擎所返回的较靠前的结果文档(例如第一页)中获得他们所需要的信息.在这种情况下,在结果列表较靠前的位置为用户提供多样化的文档不失为一种提高搜索效率和用户满意的方案.
网页搜索结果的多样化问题在近几年开始得到学者们的重视[2-3].Carbonell等[4]提出的 MMR 方法在保持文档与用户查询相关性的同时,减少了结果文档的冗余.Zhai等[5]提出在语言模型的框架下对结果文档的多样性和相关性进行平衡.Gollapudi等[6]采用公理化的方法对多样化问题进行描述和分析,提出了3个优化目标,并把其中2个目标还原为离散问题,用2种优化算法MMD和MSD进行求解.Zhu等[7]提出的 Grasshopper算法把集中性、多样性和优先性统一在吸收马尔可夫随机游走的框架下进行优化.Swaminathan等[8]提出的EP方法通过最大化所选择的结果文档子集的联合信息覆盖值进行搜索结果的多样化.Yue等[9]提出了一种监督式的结构学习方法SVMdiv,通过学习得到单个词的重要性,然后选择最优的结果文档子集覆盖最多的重要的词,让排序结果多样化.Agrawal等[10]试图在已知查询和文档的类别信息的情况下,通过最大化在列表前k个文档中找到至少一个相关文档的可能性来达到多样化的效果.Santos等[11-12]提出的多样化框架xQuad,显式地对查询词所蕴含的子查询进行建模,然后通过估计结果文档与子查询的相关度进行结果多样化.
文中用信息面[13]来表示蕴含在结果文档中与用户查询相关的信息集合,把结果多样化问题形式化为信息面覆盖率的最大化问题,提出了一种新的网页搜索结果多样化方法KDM,使重排序后的结果列表中较靠前的文档可以包含尽量多的信息面,以达到多样化的目的.KDM既不需要直接对结果文档蕴含的信息面进行建模,也不是直接对文档进行相似度比较.KDM从结果文档中提取出关键词,利用关键词在信息面级别的距离,估计文档的信息面新颖度(以下简称新颖度),并结合文档与查询的相关度对文档进行重排序.最后,在一个公开数据集AMBIENT上进行实验以验证KDM的性能.
1 多样化网页搜索结果
1.1 信息面覆盖率的最大化问题
为了满足用户的各种信息需求,提高搜索效率和用户满意度,结果列表前端的文档要尽可能包含多个方面的信息.假设用户只浏览结果列表中最靠前的k个文档,文中将多样化问题形式化为信息面覆盖率的最大化问题.
给定一个查询q和与它相关的结果文档集合D={d1,d2,…,dn},每个文档 di(i∈[1,n])都覆盖了一个与q相关的信息面集合Fi.多样化的目标就是选择一个大小为k(k≤n)的文档子集,满足:
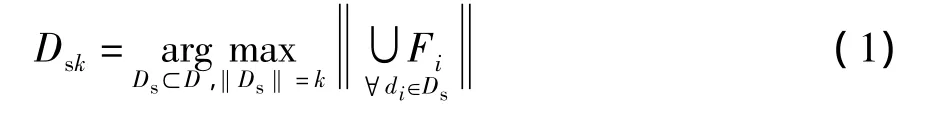
如果每个文档所覆盖的信息面集合Fi是已知的,那么式(1)是一个NP难问题[14],一个好的解决方案是直接用子集选择的贪心算法进行计算,并得到一个接近于(1-1/e)OPT的下界,OPT为最优值.但当这些信息面集合和结果文档集包含的总的信息面集合都是未知时,就会给解决多样化问题带来困难.
1.2 KDM
为解决多样化问题,文中提出了一种新的多样化方法KDM.该方法没有直接对结果文档所蕴含的信息面进行建模,也不是简单地根据文档间的相似度或距离进行多样化.具体步骤如下:首先,从结果文档集中抽取出一批关键词,这些关键词可以进行组合,从而表示蕴含的信息面;然后,根据关键词的同现性以及关键词对文档的描述能力,计算结果文档的新颖度值,并对结果文档进行重排序,以最大化前面k个文档的信息面覆盖率.
1.2.1 关键词抽取
关键词抽取是KDM的重要组成部分,期望抽取出的关键词能够通过组合来表示结果文档所蕴含的各个信息面.KDM的关键词抽取采用了已成功应用到网页搜索结果聚类系统的基于后缀数组的高频词及词组抽取技术[15],它不仅能够抽取在文档中频繁出现的单词,还可以抽取频繁出现的词组,这使得聚类结果更加准确,聚类标签更有意义.KDM的关键词抽取分为两个步骤:
(1)预处理.预处理包括对结果文档进行词根还原、停用词标记和文本分割.在这个阶段中,文中方法没有去除停用词,因为停用词可能是词组的一部分.文本分割则是把结果文档分割成单词和句子,这对于词组抽取来说非常重要,因为如果一个词组横跨了不止一个句子,那么这个词组对用户来说没有什么意义[16].
(2)关键词抽取.文中采用一种基于变形的后缀数组的词组发现算法[15],从结果文档中抽取出高频单词和高频词组,先根据规则从中选出关键词,然后去掉那些属于停用词的高频单词和以停用词开头或结尾的高频词组,最后将出现频率超过关键词频率阈值θ的高频单词和词组作为关键词.与单词相比,词组拥有更强的描述能力,因为它们可以保持单词间的亲近度和相对顺序,从语义角度上说比单纯的单词集合具有更强的表达能力.而且,相比高频单词和词组,低频单词和词组与用户查询的相关度可能较低,去掉这些低频单词和词组可以降低噪声的影响,并提高计算效率.
1.2.2 新颖度值定义
由于一个信息面可能包含许多关键词,如果排序时选择的结果文档所包含的关键词属于同一个信息面,那么排序结果并不能体现多样性.要提高结果的多样性,必须选择那些包含新颖的信息面的文档,使得结果文档集所包含的信息面的冗余尽可能地少.为了衡量文档的新颖度,文中根据关键词的同现性定义了关键词在信息面级别中的距离,并根据该距离和关键词对文档的描述能力来定义结果文档的新颖度值.
首先,假设抽取出的关键词集合W有m个关键词,对于整数 j,l∈[1,m],i∈[1,n],f(wj,di)表示关键词wj在文档di中出现的频率:
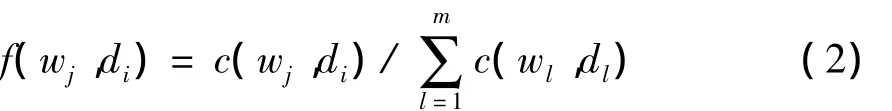
式中:c(wj,di)表示关键词wj在文档di中出现的次数.
假设两个关键词经常以接近的频率出现在同一文档中,那么它们很有可能表示同一个信息面.基于这样的假设,文中定义两个关键词wj和wl在信息面级别中的距离为
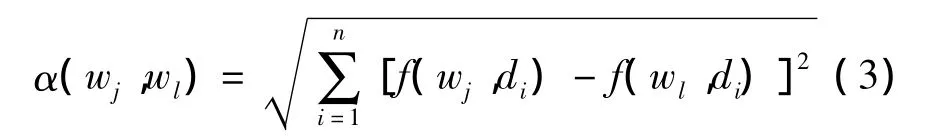
对于关键词wj来说,关键词wl跟它的距离越远,意味着wl所具有的新颖度越高.
由于文档由关键词组成,因此如果一个文档中最具代表性的关键词是新颖的,那么这个文档很可能就是新颖的.在排序过程中,关键词wj的新颖度Nw(wj)定义为该关键词与已排序文档所覆盖的关键词集Wc的距离:
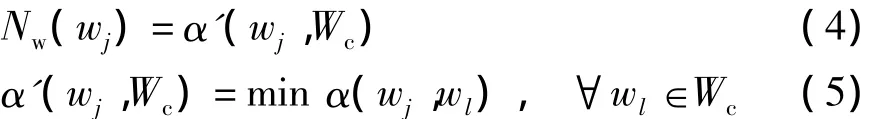
而关键词对文档的代表性则用关键词在该文档中出现的频率来刻画.因此,文档di的新颖度值定义为

1.2.3 结果重排序
在定义了文档新颖度的基础上,文中提出了一种对结果文档进行重排序的贪心算法.在选择文档时,该算法结合了文档与用户查询的相关度和文档的新颖度λR(di,q)+(1 -λ)Nd(di).其中,R(di,q)表示文档di与查询q的相关度,文中用BM25[17]进行计算;λ(λ∈[0,1])是一个平衡参数,用于调节相关度和新颖度的权重.
算法开始时,重排序子集合Ds和已覆盖关键词集合Wc为空.算法首先选择具有最大新颖度值的文档作为第一个文档.由于一开始还没有任何关键词被覆盖,关键词的新颖度值无法由式(4)计算得到,因此,关键词的新颖度根据该关键词与其它所有关键词的距离进行计算,即
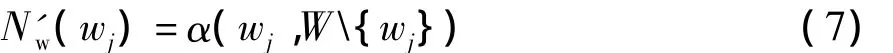
相应地,文档的新颖度为
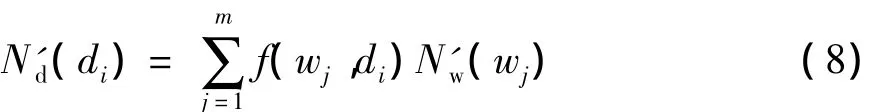
选择了第一个文档之后,它所包含的关键词集Wd*加入到Wc中.接着,计算其它文档的新颖度值Nd(di),选择相关度和新颖度结合分值最大的文档作为第二个文档,并把该文档的关键词加入到Wc中,再计算剩下其它文档的新颖度值.如此重复,直到选够k个文档或者关键词全部被覆盖为止.算法的具体描述如下:
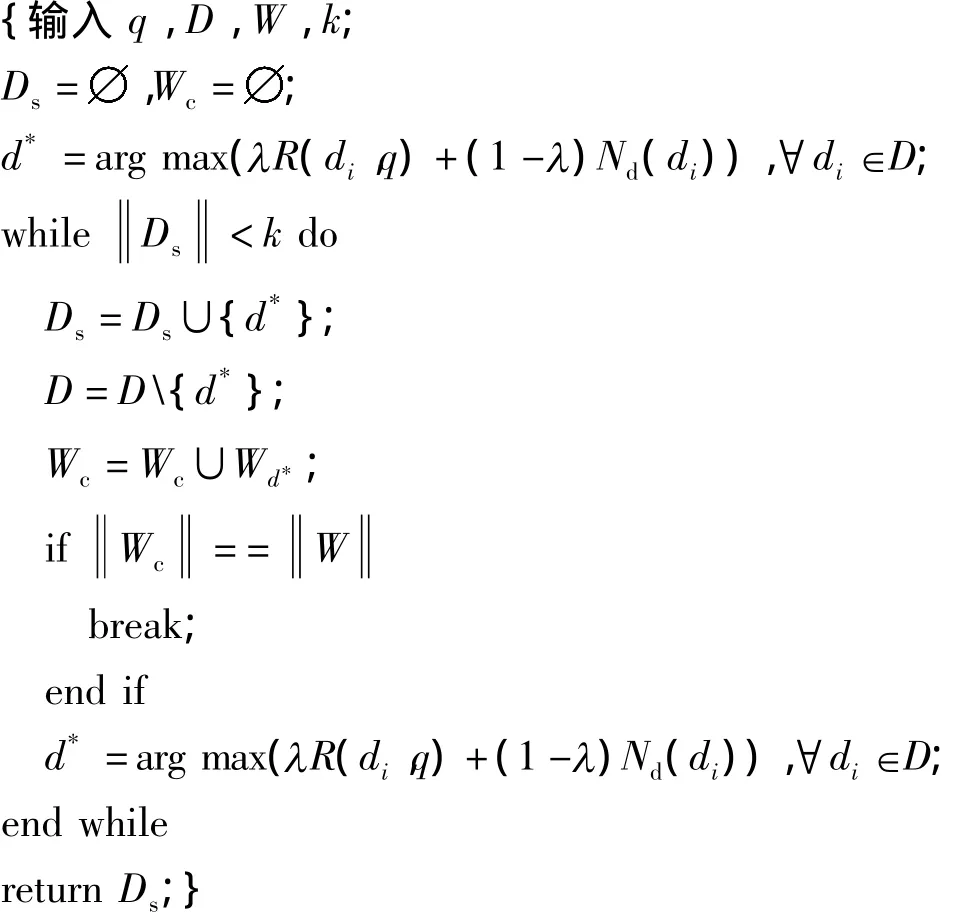
2 实验
2.1 数据集
文中采用一个为子主题检索设计的公开数据集AMBIENT(AMBIgous ENTries,http:∥credo.fub.it/ambient)来衡量KDM的多样化效果.
AMBIENT中有44个主题,每个主题包含一个子主题集合和100个排好序的文档.主题和子主题是从 Wikipedia(http:∥en.wikipedia.org/wiki/Wikipedia:Links_to_%28dis-ambiguation%29_pages)上获取的;而结果文档是以主题名作为查询词从Yahoo!搜索引擎获取的,并且根据Wikipedia上列出的每个主题对应的子主题信息,人工进行子主题相关性的标记.每个文档由搜索结果的URL、标题和文摘组成.更多的关于该数据集的信息可以参考文献[18].由于该数据集中结果的相关性只建立在Wikipedia列出的子主题的基础上,因此结果文档中所包含的与查询相关的信息很有可能没有包括在Wikipedia所列出的范围内,为了让实验更加合理,实验时去掉了那些不属于任何一个子主题的文档.
2.2 评价指标
2.2.1 子主题召回率
子主题召回率是Zhai等[5]定义的用于评价子主题检索的度量指标.给定一个主题T和一个排好序的文档列表{d1,d2,…,dn},其中 T包含了 nt个子主题 T1,T2,…,Tnt,定义 Ts(di)为与文档 di相关的子主题集合.那么在位置k上的子主题召回率定义为结果列表中前k个文档的子主题覆盖率:
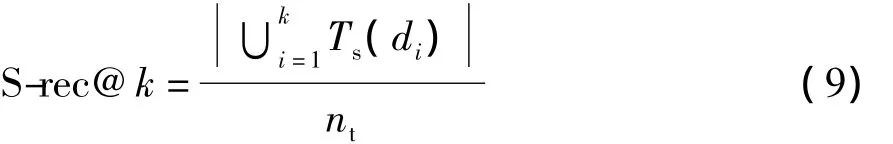
子主题召回率越大,说明被覆盖的子主题越多,当所有子主题都被覆盖时,子主题召回率为1.在实验中,考察各种方法在位置1到10的子主题召回率,以评价这些方法在搜索结果第一页中的多样化效果.
由于不同的主题包含不同数量的子主题,固定位置的子主题召回率可能还不能非常准确地衡量多样化性能.因此,文中还采用了另外一个子主题召回率的评价指标.对于每一个主题,都可以找到一个最小的位置,使得在该位置上的子主题召回率为1,称这个位置为最小排序位置,最小排序位置的子主题召回率可以很好地对多样化效果进行评价.因此,文中用44个主题在最小排序位置的平均子主题召回率(avg_S-rec@minR)对多样化方法进行评价.
2.2.2 加权子主题损失
当不同子主题有不同的重要性时,仅仅采用2.2.1节所介绍的评价方法不能体现重要性的差别的.Yue等[9]认为在多样化任务中,越主流的子主题越重要,被覆盖的需求更大,提出了一个加权子主题损失函数来衡量多样化性能.给定一个主题及其结果文档集,每个子主题的权重跟包含该子主题的文档数成正比.在位置k的加权子主题损失定义为前k个文档所没有覆盖的子主题的加权比率.跟子主题召回率一样,文中用44个主题在最小排序位置的平均加权子主题损失(avg_WSL@minR)来评价多样化方法.
2.3 实验对比方法
为了考察KDM的多样化性能,将其与其它6种现有的多样化方法进行了对比,包括MMR[4]、Grasshopper[7]、MMD[6]、MSD[6]、EP[8]和 SVMdiv[9].由于所采用的数据集中的文档都至少与主题中的一个子主题相关,因此可把这些文档与主题的相关性看作是相等的.此外,由于数据集中最大的子主题数是15,因此在实验中只获取各种方法所产生的结果列表的前15个文档.6种方法的实验参数如下:
(1)对于MMR,抽取数据集中检索结果的标题和文摘组成结果文档,并进行了词根还原、去停用词的预处理.接着把文档表示成文档所有单词的TFIDF向量,然后计算文档间的余弦相似度.根据文献[4]进行了算法的实现.
(2)对于Grasshopper,有3个输入参数,包括表示文档间相似度的加权矩阵、表示优先性的概率分布和一个权衡参数λ(λ∈[0,1]).采用与 MMR相同的预处理和文档相似度计算,并构建相似度加权矩阵;给所有文档相等的优先概率.直接采用代码(http:∥www.cs.wisc.edu/~jerryzhu/pub/grasshopper.m)实现算法.
(3)对于离散算法MMD和MSD,在进行预处理和文档表示后,计算文档间的欧氏距离,并根据文献[6]实现这两种算法.
(4)对于EP方法,先对文档进行预处理,然后根据文献[8]中的描述实现该方法,取k=15.
(5)对于SVMdiv方法,使用文献[9]中的数据集进行模型的训练.训练时,选定参数k=15,C=0.1.测试时,把AMBIENT的数据转换成该方法所要求的格式,并取k=15.直接采用代码(http:∥projects.yisongyue.com/svmdiv/)实现算法.
2.4 结果与分析
表1给出了7种方法的多样化排序结果中,前10个排序位置(搜索结果第一页)的文档的平均子主题召回率.总体而言,KDM的多样化效果要优于其它方法.具体来看,在排序位置1和2,7种方法的性能比较接近,SVMdiv在位置1取得了最高的子主题召回率;从位置4开始,KDM和MMR的性能都明显优于其它方法;在位置10时,KDM的平均子主题召回率达到了0.800,比表现最差的Grasshopper方法高将近30%.
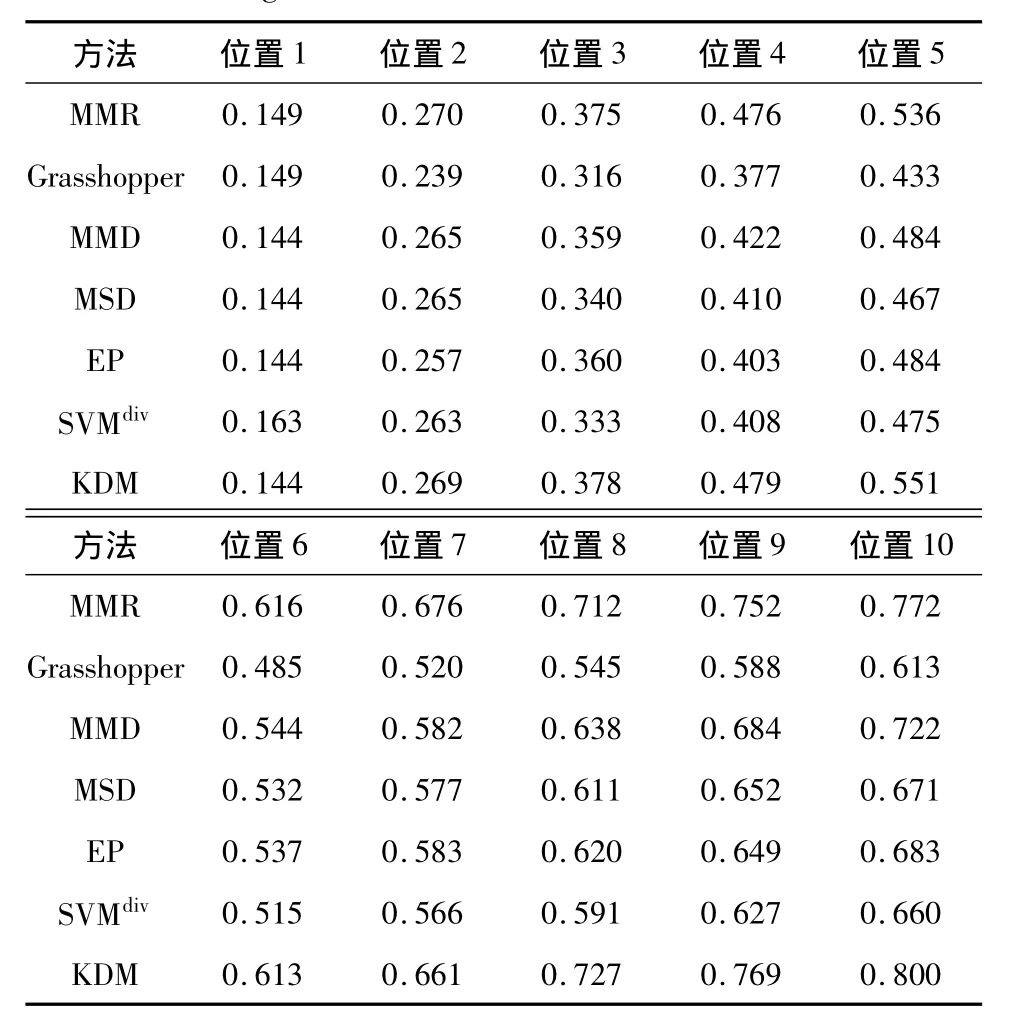
表1 7种方法前10个排序结果的平均子主题召回率Table 1 Average S-recall at rank from 1 to 10 of seven mthods
7种方法的avg_S-rec@minR和avg_WSL@minR如表2所示.从表2中可以看出,KDM依然取得了最优的效果,即把所有44个主题的性能平均起来,KDM在最小排序位置上的子主题覆盖率(avg_S-rec@minR)最高,达到了0.693;而在最小排序位置上的子主题加权损失(avg_WSL@minR)最小(为0.099).7种方法的avg_S-rec@minR与表1中的avg_S-rec@10一致,从大到小依次为:KDM>MMR>MMD>EP>MSD>SVMdiv>Grasshopper.
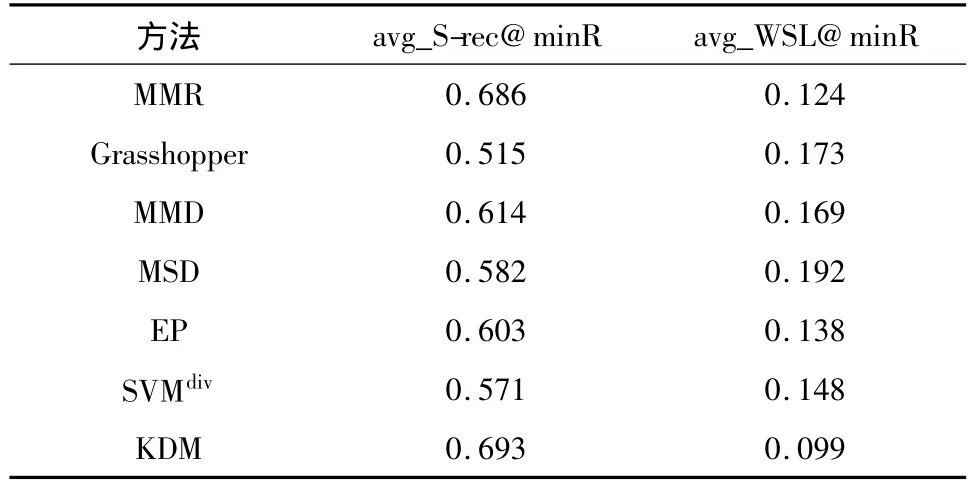
表2 7种方法的avg_S-rec@minR和avg_WSL@minRTable 2 avg_S-rec@minR and avg_WSL@minR of seven methods
为进一步分析KDM的有效性,笔者还进行了如下实验,对KDM中关键词抽取的作用进行分析.
首先,不进行1.2.1节中描述的关键词抽取,而是采用2.3节中的预处理方法对文档进行预处理,然后把所有单词作为关键词,再用KDM的重排序算法进行多样化,实验结果见表3中KDM_ST方法所对应的性能.从实验结果可以看出,以所有单词作为关键词,KDM的多样化效果比进行关键词抽取的效果差.这说明1.2.1节中描述的关键词抽取有利于提高KDM的多样化效果.对比KDM_ST和表2中的实验结果可以看出,即使以所有单词作为关键词,KDM的多样化性能还是要优于除MMR外的其它方法.
另外,由于KDM所抽取的关键词包括高频单词和高频词组,为考察它们对KDM多样化效果的影响,文中分别只使用高频单词或高频词组作为关键词进行实验,结果见表3中KDM_FT(高频单词)和KDM_FP(高频词组)方法所对应的性能.从结果可以看出,单独使用高频单词或高频词组的效果均不如把它们结合起来利用的效果好,而只用高频单词的效果要明显优于只用高频词组的效果.这与在1.2.1节中的设想一致,高频单词所包含的信息要大于高频词组,但仅仅使用高频单词是不够的,高频词组所蕴含的更为丰富的语义信息是高频单词的重要补充.
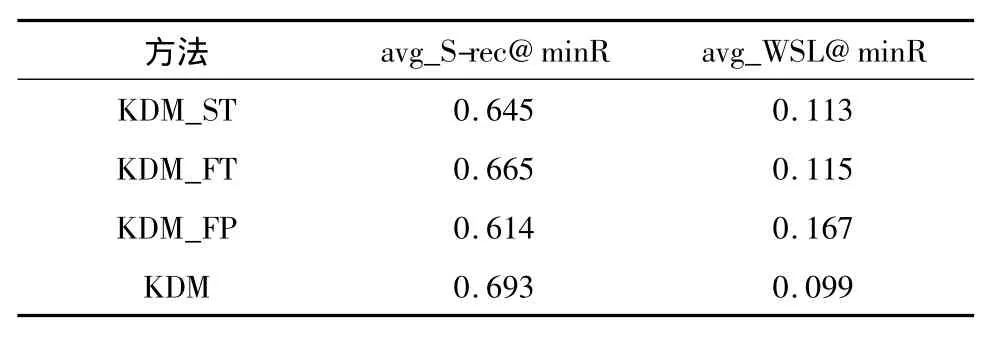
表3 采用不同形式的关键词的KDM性能Table 3 Performance of KDM with different types of keywords
3 结语
在网页搜索中,搜索结果的多样化逐渐变得重要.文中提出了一种新的网页搜索结果多样化方法,该方法通过从结果文档中抽取关键词,以关键词为基础计算文档的新颖度,并根据文档的新颖度和相关度进行重排序.实验结果说明,该方法与现有多样化方法相比,无论是子主题的召回率还是加权子主题损失的性能,都要优于其它方法.
目前KDM只采用了简单的词袋模型对关键词和文档以及关键词和关键词之间的关系进行刻画,还可以用其它模型,如语言模型等.另外,在关键词的抽取方面,也可以采用其它方法进行抽取.
[1] Goffman W.On relevance as a measure[J].Information Storage and Retrieval,1964,2(3):201-203.
[2] Bennett P N,Carterette B,Chapelle O,et al.Beyond binary relevance:preferences,diversity,and set-level judgments[J].ACM SIGIR Forum,2008,42(2):53-58.
[3] Radlinski F,Carterette B,Bennett P N,et al.Redundancy,diversity and interdependent document relevance[J].ACM SIGIR Forum,2009,43(2):46-52.
[4] Carbonell J,Goldstein J.The use of mmr,diversity-based reranking for reordering documents and producing summaries[C]∥Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.New York:ACM,1998:335-336.
[5] Zhai Chenxiang,Cohen W W,Lafferty J.Beyond independent relevance:methods and evaluation metrics for subtopic retrieval[C]∥Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.New York:ACM,2003:10-17.
[6] Gollapudi S,Sharma A.An axiomatic approach for result diversification[C]∥Proceedings of the 18th International Conference on World Wide Web.New York:ACM,2009:381-390.
[7] Zhu Xiaojin,Goldberg A B,Van Gael J,et al.Improving diversity in ranking using absorbing random walks[C]∥Proceedings of Human Language Technologies:the Annual Conference of the North American Chapter of the Association for Computational Linguistics.Rochester:NAACL,2007:97-104.
[8] Swaminathan A,Mathew C,Kirovski D.Essential pages[R].Redmond:Microsoft Research,2008.
[9] Yue Y,Joachims T.Predicting diverse subsets using structural svms[C]∥Proceedings of the 25th International Conference on Machine Learning.New York:ACM,2008:1224-1231.
[10] Agrawal R,Gollapudi S,Halverson A,et al.Diversifying search results[C]∥Proceedings of the Second ACM International Conference on Web Search and Data Mining.New York:ACM,2009:5-14.
[11] Santos R L T,Peng J,Macdonald C,et al.Explicit search result diversification through sub-queries[C]∥Proceedings of the 32nd European Conference on Information Retrieval.Berlin/Heidelberg:Springer-Verlag,2010:87-99.
[12] Santos R L T,Macdonald C,Ounis I.Exploiting query reformulations for Web search result diversification[C]∥Proceedings of the 19th International Conference on World Wide Web.New York:ACM,2010:881-890.
[13] Carterette B,Chandar P.Probabilistic models of ranking novel documents for faceted topic retrieval[C]∥Proceedings of the 18th ACM Conference on Information and Knowledge Management.New York:ACM,2009:1287-1296.
[14] Khuller S,Moss A,Naor J.The budgeted maximum coverage problem [J].Information Processing Letters,1997,70(1):39-45.
[15] Osinski S,Weiss D.A concept-driven algorithm for clustering search results [J].IEEE Intelligent Systems,2005,20(3):48-54.
[16] Zhang D,Dong Y.Semantic,hierarchical,online clustering of web search results[C]∥Proceedings of 6th Asia Pacific Web Conference.Berlin/Heidelberg:Springer-Verlag,2004:69-78.
[17] Robertson S,Jones K S.Simple proven approaches to text retrieval[R].Cambridge:Computer Laboratory of University of Cambridge,1997.
[18] Carpineto C,Mizzaro S,Romano G,et al.Mobile information retrieval with search results clustering:prototypes and evaluations[J].Journal of American Society for Information Science and Technology,2009,60(5):877-895.
猜你喜欢
客联(2022年3期)2022-05-31
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
中国新闻周刊(2021年26期)2021-07-27
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
信息安全研究(2016年4期)2016-12-01
高中生学习·高三版(2014年3期)2014-04-29
