
基于C4.5决策树的嵌入型恶意代码检测方法*
2011-01-24 02:51张福勇齐德昱胡镜林
华南理工大学学报(自然科学版) 2011年5期
张福勇 齐德昱 胡镜林
(华南理工大学计算机系统研究所,广东广州510006)
嵌入型恶意代码指利用文档漏洞将恶意代码嵌入到正常文档中,以实现其传播和攻击的恶意代码.这种嵌入文档中的恶意代码不易被察觉,而且即使在这些恶意代码的特征码已知的情况下,商业反病毒软件也不能对其进行有效的检测[1-3].对于利用零日漏洞嵌入的恶意代码而言,基于特征扫描的反病毒软件对其更是无能为力[4-6].
研究人员普遍采用统计分析的方法进行嵌入型恶意代码检测,该方法将文档看成一个字节序列,提取其n-gram(连续的n个字节)作为分析特征[7],通过计算n-gram的马氏距离[1]、n-gram在模型中出现的比例[2]、n-gram熵率等方式实现恶意代码检测[3].文献[3]的结果表明,马氏距离不能得到较好的检测结果,n-gram 熵率对 JPG、MP3、PDF、ZIP等格式的文件检测结果较好,但对DOC(Word)文档不能进行有效检测.Li等[2]采用 high-order n-gram建立normal和abnormal两个模型,计算测试文档中n-gram在两个模型中出现的比例,赋予相应的分值,测试文档的类型即为得分高的模板类型;此方法在对Word文档的检测中取得了较好的结果,但其对训练和检测数据较为敏感.
为此,文中提出一个采用C4.5决策树的嵌入型恶意代码检测方法.首先,提取文档的n-gram,计算所有n-gram的信息增益,选择具有最大增益的500个n-gram作为特征值,如果文档中存在某个n-gram特征,将此特征值标为1,否则标为0,然后采用C4.5决策树进行分类.
1 Boosting C4.5决策树方法
1.1 特征选择
文中选用n-gram信息增益进行特征选择.信息增益被广泛用于信息检索[8]、文本分类和病毒检测等领域[9-10].信息增益通过衡量特征为分类系统带来的信息量来判断特征的重要性,带来的信息量越多,该特征越重要.
文中以n-gram作为特征T,其信息增益为

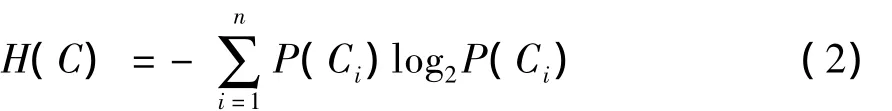
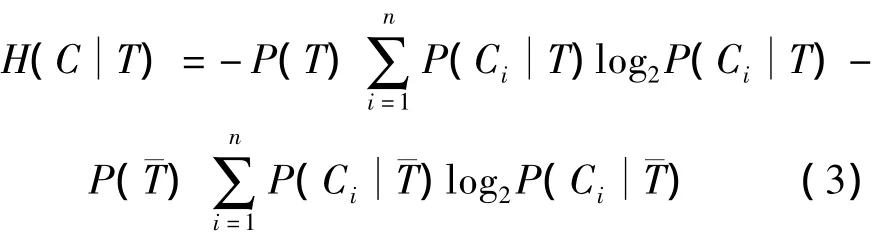
式中:P(Ci)为Ci出现的概率;P(T)为T出现的概率为T出现时Ci出现的概率为T不出现的概率;为T不出现时Ci出现的概率.
1.2 C4.5 决策树
文中选用目前广泛应用于分类、检索的C4.5决策树算法进行分类[11-14],该算法根据信息增益率来选择属性,从一个无次序、无规则的实例集合中归纳出一组采用树形结构表示的分类规则[15].以文中选择的最大信息增益n-gram属性为例:已知样本集D{X1,X2,…,Xn},假定类别属性具有 m 个不同的值,根据类别属性取值的不同可以将D划分为m个子集{D1,D2,…,Dm}.由此可以得出样本集 D 对分类的平均信息量为

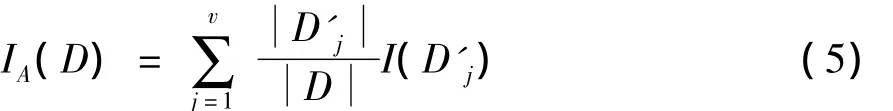
则利用属性A对D进行划分的信息增益等于使用A对D进行划分前后不确定性下降的程度,即信息增益

由于信息增益倾向于选择具有大量值的属性,但某些属性(例如充当唯一标识的属性)虽具有最高的信息增益,却对分类没有用.为了克服这种偏奇,C4.5决策树采用信息增益率作为属性选择的依据.信息增益率的计算公式为

1.3 Boosting技术
决策树是一种不够稳定的分类方法,训练集的小范围变动就可能造成分类模型的显著变化.为了提高决策树分类的稳定性,可以利用不同的训练集构造多个分类模型,先由每个模型独立做出决策,再通过综合打分的方法得到最终结果.
Boosting的思想是对每个样本赋予一个相同的初始权重,在此后的迭代过程中不断调整权重.整个过程进行k次迭代,每次迭代首先根据样本的权重构造训练集,权重越大的样本出现在训练集中的概率越高.然后,利用训练集构造决策树,找出不符合决策树模型的例外样本,加大它们的权重,使得下一次的迭代更加关注这些样本.同时对每个模型赋予一个权重,表示模型对决策的影响因子,该值与模型的错误率成反比,也就是说,模型对训练集的错误率越低,它的权重就越大,对决策的结果就越重要.Boosting的过程描述如下.
(1)训练过程.
{输入:训练数据T,样本数n,迭代次数k.
输出:决策树序列 α1,α2,…,αk.
根据样本权重,从T中抽取样本集Ti;
根据样本集得到模型αi;
计算模型αi的错误率ε(i);

(2)决策过程.
{输入:测试数据 γ,决策树序列 α1,α2,…,αk.
输出:预测类别 α(γ).

根据αi判断γ的类别,结果为αi(γ);
end for
根据模型的权值统计每个类别的得票,得票最高的就是α(γ)}
2 数据集
为了验证方法的有效性,文中采用真实的嵌入型恶意代码作为实验数据.从VX Heavens[16]上收集了Word、Excel和PPT 3种类型的恶意文档共3173个,收集了正常文档760个,所有正常文档均为本研究所日常交流所用文档.实验数据的详细信息见表1.
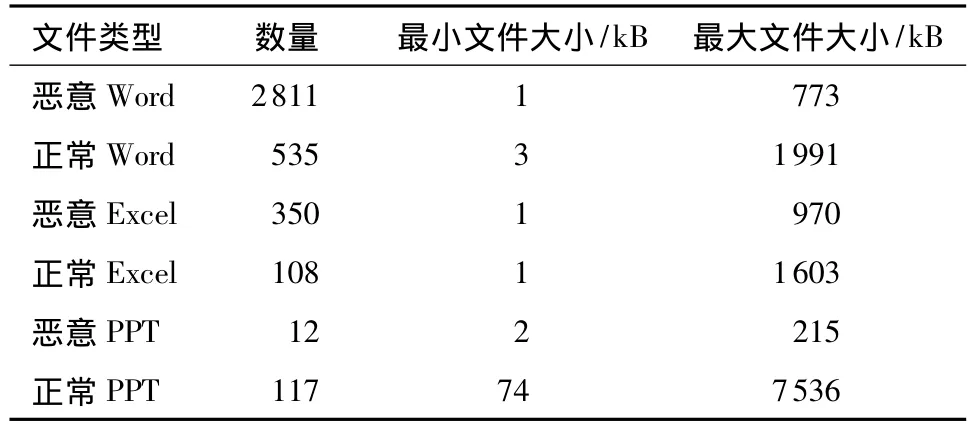
表1 实验数据Table 1 Experimental data


图1 3-gram属性分布图Fig.1 Distribution of 3-gram attributes
3 实验分析
3.1 评估策略
在恶意代码检测中,通常采用检测率(TP)即正确分类的恶意代码数与恶意代码总数的比值和误检率(FP)即正常文件被认定为恶意代码数与正常文件总数的比值来评价检测方法的优劣.分类准确率(ACC)也被应用到检测算法优劣的评估中,其为正确分类的样本数与所有测试样本数的比值.
3.2 有效性验证
为验证文中提出的方法的有效性,首先选择了恶意文档274个(其中Word 131个,Excel 131个,PPT 12个),正常文档236个(其中Word 123个,Excel 95个,PPT 18个),进行特征提取和分类测试.3种类型文档测试均采用10次迭代,建立10棵决策树,采用10折交叉验证,测试结果见表2.

表2 小规模数据集实验结果Table 2 Experimental results in the small data set %
由表2可见,所提出的Boosting C4.53-gram信息增益法适用于嵌入型恶意代码检测,并具有很高的检测率和分类准确率.其中对Word文档的检测率为100%.对PPT文档的检测率稍低为91.70%,这主要是因为参与测试的样本数太少,不能很好地展现分类效果.实际上在对PPT文档的检测中,恶意文档和正常文档均只有1个被错误分类.
接下来分别采用从上述3类文档中提取的500个3-gram作为属性,计算所有3346个Word文档、458个Excel文档和129个PPT文档的属性值,采用上述的10棵决策树序列对这些文档进行测试,结果见表3.
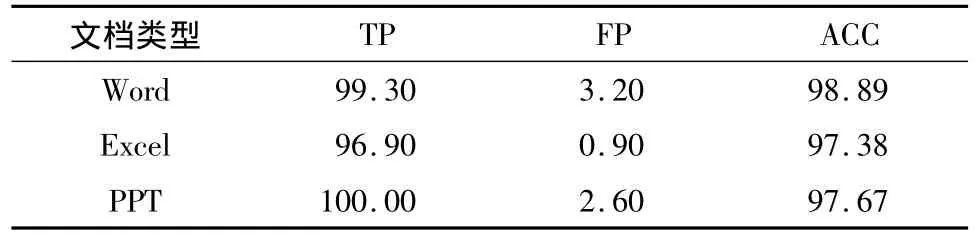
表3 大规模数据集实验结果Table 3 Experimental results in the large data set %
由表3可以看出,仅采用少量样本提取的500个属性建立的决策树,对3类文档均具有较高的检测率.由表2、3可知,Boosting C4.5 n-gram信息增益法适用于嵌入型恶意代码检测,而且通过预先提取的属性特征可以实现对未知恶意代码的准确检测.
3.3 检测结果比较
采用Markov 2-gram熵率法、High-order 5-gram模型法、C4.53-gram信息增益法以及Boosting C4.53-gram信息增益法对表1列出的数据集进行测试,比较各种方法的检测结果.对于High-order 5-gram模型法,仅采用对整篇文档建模的方法,因为分段模型的权值大小对检测结果有很大影响,对于不同的测试数据检测结果差异较大.表4示出了各种方法的检测结果,所列结果均为10折交叉验证的结果.

表4 4种方法的检测结果Table 4 Test results of the four methods %
从表4可以看出,Markov 2-gram熵率法对3种类型文档的检测率都在60%左右,而且都有很高的误检率.因此,Markov 2-gram熵率法并不适用于这3类文档的嵌入型恶意代码检测.与 High-order 5-gram模型法相比,C4.53-gram信息增益法和Boosting C4.53-gram方法对Word文档和Excel文档的检测率均有明显提升.两种决策树方法对Word文档的检测率均为99.80%,但由于Boosting技术的运用使C4.5决策树的误检率由2.20%降低到1.70%,同时分类准确率也有所提高;而对Excel文档的检测却出现了相反的结果,采用Boosting技术的决策树检测率低于未采用Boosting的决策树,误检率高于未采用Boosting的决策树.其原因为,Boosting技术虽然可以在一定程度上提高决策树分类的稳定性,但它有时也会存在过拟合的情况,导致分类准确率的降低.
由于收集的恶意PPT文档数量较少,High-order 5-gram模型法、C4.53-gram信息增益法和Boosting C4.53-gram信息增益法对PPT文档得到了同样的检测率,都有2个恶意文档被误认为正常文档.但Boosting C4.53-gram信息增益法的误检率要明显低于High-order 5-gram模型法和C4.53-gram信息增益法.更重要的是在分类准确率方面,Boosting C4.53-gram信息增益法要高于High-order 5-gram模型法和C4.53-gram信息增益法.说明 Boosting C4.53-gram信息增益法可以对未知样本进行更准确的分类.
4 结语
针对嵌入型恶意代码这种新兴的计算机安全威胁.文中在分析了以往统计分析方法不足的基础上提出采用C4.5决策树的机器学习方法进行嵌入型恶意代码检测,该方法通过从训练样本中提取的500个具有最大信息增益的3-gram作为属性特征,实现了高检测率和高分类准确率;该方法通过对少量样本的学习,即可实现对未知嵌入型恶意代码的准确检测,在检测率和分类准确率方面与以往的检测方法Markov 2-gram和High-order 5-gram相比有明显优势.
[1] Stolfo S J,Wang K,Li W J.Towards stealthy malware detection[M]∥Malware detection.Heidelberg:Springer-Verlag,2007:231-249.
[2] Li W J,Stolfo S J,Stavrou A,et al.A study of malcodebearing documents[C]∥Proceedings of the 4th International Conference on Detection of Intrusions and Malware,and Vulnerability Assessment.Heidelberg:Springer-Verlag,2007:231-250.
[3] Shafiq M Z,Khayam S A,Farooq M.Embedded malware detection using Markov n-grams[C]∥Proceedings of the 5th International Conference on Detection of Intrusions and Malware,and Vulnerability Assessment.Heidelberg:Springer-Verlag,2008:88-107.
[4] John Leyden.Trojan exploits unpatched Word vulnerability[EB/OL].(2006-05-22)[2010-05-28].http:∥www.theregister.co.uk/2006/05/22/trojan_exploit_word_vuln/.
[5] Joris Evers.Zero-day attacks continue to hit Microsoft[EB/OL].(2006-09-28)[2010-05-28].http:∥news.cnet.com/Zero-day-attacks-continue-to-hit-Microsoft/2100-7349_3-6120481.html.
[6] David Kierznowski.Backdooring PDF files [EB/OL].(2006-09-13)[2010-05-28].http:∥michaeldaw.org/md-hacks/backdooring-pdf-files.
[7] Damashek M.Gauging similarity with n-grams:languageindependent categorization of text[J].Science,1995,267(5199):843-848.
[8] Grossman D A,Frieder O.Information retrieval:algorithms and heuristics[M].2nd ed.Heidelberg:Springer-Verlag,2004.
[9] Dumais S,Platt J,Heckerman D,et al.Inductive learning algorithms and representations for text categorization[C]∥Proceedings of the 7th International Conference on Information and Knowledge Management.New York:ACM Press,1998:148-155.
[10] Kolter J Z,Maloof M A.Learning to detect malicious executables in the wild[C]∥Proceedings of the International Conference on Knowledge Discovery and Data Mining.New York:ACM Press,2004:470-478.
[11] Garcia S,Fernandez A,Herrera F.Enhancing the effectiveness and interpretability of decision tree and rule induction classifiers with evolutionary training set selection over imbalanced problems[J].Applied Soft Computing,2009,9(4):1304-1314.
[12] Conway M,Doan S,Kawazoe A,et al.Classifying disease outbreak reports using n-grams and semantic features[J].International Journal of Medical Informatics,2009,78(12):47-58.
[13] 闵华清,卢炎生,蒋晓宇.基于共同进化计算的分类规则算法[J].华南理工大学学报:自然科学版,2006,34(6):69-73.Min Hua-qing,Lu Yan-sheng,Jiang Xiao-yu.Algorithm of classification rules based on co-evolution computation[J].Journal of South China University of Technology:Natural Science Edition,2006,34(6):69-73.
[14] Tso B,Tseng J L.Multi-resolution semantic-based imagery retrieval using hidden Markov models and decision trees[J].Expert Systems with Applications,2010,37(6):4425-4434.
[15] 徐鹏,林森.基于C4.5决策树的流量分类方法[J].软件学报,2009,20(10):2692-2704.Xu Peng,Lin Sen.Internet traffic classification using C4.5 decision tree [J].Journal of Software,2009,20(10):2692-2704.
[16] VX Heavens.Computer virus collection [DB/OL].(2007-09-14)[2010-05-28].http:∥vx.netlux.org/vl.php.
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
北京航空航天大学学报(2021年6期)2021-07-20
电子制作(2019年19期)2019-11-23
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年19期)2018-11-14
电子制作(2018年16期)2018-09-26
信息安全研究(2016年4期)2016-12-01
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
