
基于改进Q-学习的导航知识获取算法研究
2011-01-23 09:25郑炳文
科学之友 2011年4期
郑炳文
(胜利油田海洋采油厂,山东 东营 257000)
基于改进Q-学习的导航知识获取算法研究
郑炳文
(胜利油田海洋采油厂,山东 东营 257000)
基本Q-学习算法总是利用当前最优策略进行动作的选取,这样容易陷入局部最优。文章在模拟退火强化学习基础上提出了基于探索区域扩张的Q-学习,加入原地探索策略,提高了找到目标的效率;引入了探索区域扩张策略,避免了初始时在整个环境中加入探索的盲目性,提高了学习效率;加入算法的自主学习结束条件,避免了找到最优路径后的重复学习,节省了学习时间。仿真实验验证了算法的有效性。
强化学习;Q-学习;探索区域扩张;模拟退火;神经网络
1 机器学习背景
移动机器人要在未知环境中安全、可靠地完成指定任务,除了应具有建模、定位、规划、运动等基本能力外,还应能够处理各种突发情况,逐渐适应环境,提高工作效率,这就要求其导航控制系统具有灵活性和适应性。近年来,机器学习已成为人工智能和机器人学的一个研究热点,并且取得了不少突破性进展,其中包括神经网络算法研究、模糊逻辑算法研究、进化学习算法应用研究、统计学习特别是支持向量机(Support Vector Machine,SVM)理论和算法研究、强化学习理论和算法研究等。上述机器学习理论和方法为复杂和未知环境中的信息提取、环境理解、任务规划和行为决策提供了有效的解决途径,应用机器学习方法来实现未知环境中移动机器人导航控制器的设计和优化,已成为近年来移动机器人导航控制技术的研究热点。
2 机器学习在导航中的研究概况
随着模糊逻辑方法和技术研究的进展,应用模糊逻辑方法实现移动机器人的导航成为一个研究热点。在基于模糊逻辑的移动机器人导航方法中存在的另一个关键问题是参数的优化和对环境的自适应。虽然模糊规则的建立可以利用人类的语言知识,但仍然有许多参数需要调整和优化,才能获得满意的效果,而且一旦环境发生改变,模糊控制器往往缺乏自适应和自学习的能力。
神经网络作为人工智能和机器学习研究的一个热点,已成功地应用于模式识别、自适应控制、系统辨识等领域。神经网络具有良好的非线性函数逼近能力和容错能力,且能够实现自适应和学习。基于神经网络的导航方法采用了神经网络的无监督学习或监督学习方法,其中无监督学习方法仅能够实现对环境特征的自组织分类和识别,难以实现行为选择的优化,而监督学习方法则要求构造各种条件下的教师信号,因此缺乏对未知和快速变化环境的自适应能力。
进化计算是模拟自然界生物进化过程的一种计算智能方法,目前已在算法和理论上取得了大量的研究成果,并成功地应用于组合优化、自适应控制、规划设计、机器学习和人工生命等领域。利用进化计算方法虽然可以实现移动机器人导航控制器对环境的自适应和优化,但存在计算时间长、学习效率不高的缺点。
2.1 ε-greedy 策略
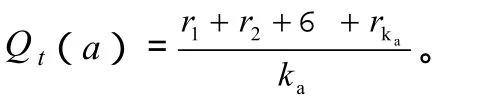
如果ka=0,就定义Qt(a)为默认值,如Q0(a)=0,当ka→∞时,Qt(a)一定收敛于Q*(a)。因为每次估计是相关回报抽样的简单的平均,因此称此估计动作值的方法为抽样平均法。这只是估计动作值的一种方法,不一定是最好的,下面讨论怎样用此估计来选择动作。
2.2 Boltzmann分布

这里T为温度参数。温度高时,所有动作概率接近相等。温度低时,动作选择概率由于它们的估计值的不同而存在很大不同。当温度趋近于0时,软最大化动作选择变为贪婪动作选择。
2.3 基于Metropolis规则的Q-学习算法
模拟退火算法是求解组合优化问题的有效近似算法,它是对固体退火过程的模拟。该算法是局部搜索算法的一种扩展,解决优化解陷入局部最小的情形,其核心是Metropolis准则。模拟退火算法不是完全拒绝恶化解,因此,能够跳出局部最优,避免陷入局部搜索。
3 实验及结果分析
3.1 实验环境描述
实验环境为一个20×20的栅格世界,每个栅格代表智能体的一种状态。S为智能体的初始点,T为目标点,黑色区域为障碍物。环境中的障碍物和目标都是静态的,对于智能体而言,环境(即障碍物、边界以及目标的位置)是未知的。以智能体为中心的二维空间内平均分布8个运动方向,代表它的8个可选动作。立即回报 r为{-100,100,0},对应条件为{碰到障碍物,到达目标,其他}。
3.2 实验结果分析
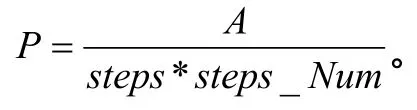
比较了3种算法的综合指标,可以看出,环境越复杂,ERE-Q-learning算法的优势越明显。

表1 搜索路径总长度的降低率比较
4 结束语
通过讨论 Q-学习算法中探索与利用之间的平衡问题,首先介绍了平衡探索和利用的各种算法,然后分析了这些算法的不足之处,最后在基于Metropolis准则的Q-学习的基础上,提出了基于探索区域扩张的 Q-学习算法。此算法加入原地探索策略,提高了找到目标的效率;引入了探索区域扩张策略,避免了初始时在整个环境中加入探索的盲目性,提高了学习效率;加入算法的自主学习结束条件,避免了找到最优路径后的重复学习,节省了学习时间,而且环境越复杂,越能体现该算法的优越性。该算法的折算率、降温率和最大限制步数还有必要进一步优化,以使算法具有更好的适应性。
Based on Improves the Q-study the Guidance Knowledge Gain Algorithm Research
Zheng Bingwen
The basic Q-learning algorithm always uses the current most superior strategy to carry on the movement the selection, such easy to fall into is partially most superior.Article proposed in the simulation annealing strengthening study foundation based on explores the Q-study which the region expands, joins in-situ exploration strategy, enhanced has found the goal the efficiency; Introduced has explored the region expansion strategy, has avoided initial when joined the exploration in the entire environment blindness, enhanced the study efficiency;Joined the algorithm the independent study termination condition, after having avoided found the optimal choice the redundant study, has saved study time.The simulation experiment has confirmed the algorithm validity.
strengthened study; Q-study; explores the region expansion; simulation annealing; neural network
TP242
A
1000-8136(2011)06-0141-02
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
环球时报(2022-07-13)2022-07-13
北京航空航天大学学报(2022年6期)2022-07-02
环球时报(2022-03-14)2022-03-14
现代仪器与医疗(2021年1期)2021-06-09
中国金属通报(2020年2期)2020-06-30
电子技术与软件工程(2019年20期)2019-11-30
电影(2018年8期)2018-09-21
计算机测量与控制(2018年9期)2018-09-19
软件(2017年7期)2018-01-24
