
眼部动作实时识别系统设计
2011-01-17 01:01:55谢勤岚王西刚
中南民族大学学报(自然科学版) 2011年3期
谢勤岚,王西刚
(中南民族大学 生物医学工程学院,武汉 430074)
基于智能视频的人机交互是计算机视觉的一个重要应用领域,它主要是实时地监测视频场景中感兴趣的交互对象及其动作,如手势,面部动作等.通过对感兴趣对象的跟踪和检测,来判断对象的目的,以实现交流或控制等任务.实时识别眼部动作就是一种有效的交互方式.
本文利用摄像机和图像采集处理单元,设计了一种静态背景下眼部动作实时识别系统.它将使用者的眼部作为一个实时的特征模板,对当前采集的图像连续地进行匹配检测,找出眼部的位置并对其动作进行分析,返回一系列参数,实现对鼠标的控制.考虑到眨眼的瞬时性和眼部颜色特征的高相似性,本文没有采用当前比较流行的混合高斯背景运动检测方法和基于颜色特种匹配的连续自适应均值漂移的跟踪方法[1],而采用速度较快的帧差法来检测眼部动作,用模板匹配和轮廓查找的方式来实现眼部定位[2],并用实时模板匹配相似度的大小分析眼部的动作.
1 眼部位置的识别
在面部动作识别[3]的过程中一般对面部的静态区域不感兴趣而只是对面部某些变动的区域感兴趣.很多情况下研究者希望将感兴趣的区域分割出来,比如眼或嘴.这样就可以把图像预处理成包含感兴趣区域的图像,这些区域由有意义的超像素(super pixel)所组成.这些超像素的使用节省了大量的处理和计算时间,因为在对一幅图像做目标特征匹配时,只需要在感兴趣的区域进行搜索,而不需要搜索整个图像.目标特征检测方法最初由Paul Viola提出,并由Rainer Lienhart对这一方法进行了改进,他利用样本的haar特征进行分类器的训练,得到一个级联的boosted分类器.分类器训练完成之后,就可以用于图像中感兴趣区域的检测.若检测到目标则输出1;否则输出0.但是这种分类器的检测方法只能用于目标的检测,无法对目标后续的动作进行分析,而且用haar训练器检测眼睛时眨眼的瞬间目标会丢失.所以本文放弃了此种方法并,而是把眼睛位置的识别转化为前景运动的检测来考虑.目前主要的运动检测方法有光流法、混合高斯背景建模、帧差等.光流法计算量大而且计算复杂,不能对眨眼的瞬间做很好的实时检测,此外它对硬件有较高的要求不适用于对实时性要求较高的领域.混合高斯背景建模是对每一个像素运用混合高斯模型进行建模,并利用像素迭代进行模型的参数更新,它适用于背景图像变化并且物体运动不快的视频环境中.而对于眼部动作检测,它的实时性并没有帧差的效果好.更重要的是帧差可以较好的捕捉运动目标的边缘,这为系统后续的轮廓检测提供了极大的便利.比较以上几种方法本文选择了帧差.
1.1 帧差法原理
帧差法[4]是最为常用的运动目标检测和分割方法之一,基本原理就是在图像序列相邻2帧或3帧间采用基于像素的时间差分通过闭值化来提取出图像中的运动区域,即:
f(x,y)=fk+1(x,y-fk(x,y)
(1)
式中,f(x,y)是运动区域像素值,fk(x,y)是前帧图像像素值,fk+1(x,y)是当前帧图像像素值.首先,将相邻帧图像对应像素值相减得到差分图像,然后对差分图像二值化,在环境亮度变化不大的情况下,如果对应像素值变化小于事先确定的阈值时,可以认为此处为背景像素;如果图像区域的像素值变化很大,可以认为这是由于图像中运动物体引起的,将这些区域标记为前景像素,利用标记的像素区域可以确定运动目标在图像中的位置,即:
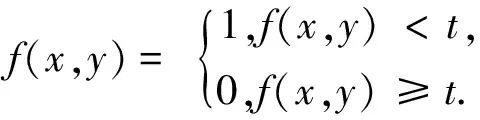
(2)
g(x,y)是经过阈值处理后的像素值,f(x,y)是帧差后的像素值,t为设定的阈值,由于相邻两帧间的时间间隔非常短,用前一帧图像作为当前帧的背景模型具有较好的实时性,其背景不积累,且更新速度快、算法简单、计算量小.算法的不足在于对环境噪声较为敏感,阈值的选择相当关键,选择过低不足以抑制图像中的噪声,过高则忽略了图像中有用的变化.图像阈值处理的结果如图1所示.

图1 原始和阈值处理图
由于图像总会受到噪声和波动的影响所以目标的二值化图像存在一定的噪声干扰,本文还使用了形态学方法来进一步去除噪声,使感兴趣的区域轮廓更加清晰.
1.2 形态学处理
因为运动目标表面纹理不够,所以二值化图像中目标内部会出现空洞,同时也存在着噪声的干扰.为了能更好地实现目标定位,需填补物体内部区域的空洞,并去除一些噪声干扰.本文采用数学形态学中开运算对图像中感兴趣区域进行处理,去除噪声.使用结构元素B集合A进行的开运算定义为[5]:
A∘B=(A⊖B)⊕B.
(3)
用B对A进行开操作就是先用B对A腐蚀,再用B对结果进行膨胀.这样可以使A的轮廓平滑,抑制A物体边界的小离散点或尖峰,可以在消除小物体、在纤细点处分离物体、平滑较大物体边界的同时并不改变其面积.
在实现本文算法的程序中,我们自定义一个IplConvkernel结构实现该算法[6](即(3)式中的“核B”).该结构对象由cvCreateStructuringElementEx()函数创建,由cvReleaseStructuringElement()函数释放.
IplConvKernel*cvCreateStructuringElementEx (
int cols,
int rows,
int anchor_x,
int anchor_y,
int shape,
int*values=NULL
);
shape
结构元素的形状,可以是下列值:
CV_SHAPE_RECT,长方形元素;
CV_SHAPE_CROSS,交错元素;
CV_SHAPE_ELLIPSE,椭圆元素;
CV_SHAPE_CUSTOM,用户自定义元素.这种情况下参数 values 定义了 mask即像素的那个邻域必须考虑.
对于核的形状选择,本文并没有拘泥于传统的方形核,而是选择了3×3的星形开运算核,这样可以使它最大限度的消除噪声和波动的影响.形态学处理的结果如图2所示.

图2 形态学处理
对比图2(a)和图2(b)可以看出,未进行开运算时脸的大概轮廓和周围的点噪声,开运算后则只有眼部区域较清晰同时噪声较少.
2 跟踪和眼部动作识别
2.1 跟踪
本系统中使用的跟踪方法是模板匹配法,具有速度快、计算简单的特点.该方法利用由Grauman等人提出的归一化系数完成跟踪,它对图像序列中的每一帧进行如下计算:
(4)

程序中使用cvMatchTemplate()函数对搜索区域匹配,函数原型如下:
cvMatchTemplate(
const CvArr* image;
const CvArr* templ;
CvArr* result;
int method;
);
在匹配方法的选择上共有3种方法,即平方差匹配法:
R(x,y)∑x′,y′[T(x′,y′)-I(x+x′,y+y′)]2,
(5)
和相关匹配法:
R(x,y)∑x′,y′[T(x′,y′)I(x+x′,y+y′)]2,
(6)
以及本程序采用的第3种匹配方案,它是在兼顾速度和精度的情况下作出的选择,其表达为:

(7)
其中:令Z(x,y)=


图3 实时模板图
利用实时产生的匹配模板,我们只需要在图像中感兴趣的区域(眼部周围)进行匹配,它将是一个很小的部分,这样大大的减小了计算时间.将匹配的最佳点标记出来,就是期望的眼部区域.在匹配后还实现了一个有效区域框定的处理,试验表明这种处理可以极大地减小匹配的误差.
2.2 眼部动作识别
在完成眼部在图像序列中的定位和跟踪以后,为了使程序的执行更高效,需要进一步限定模板只在每一帧的有效区域内实现匹配.有效区域由满足:
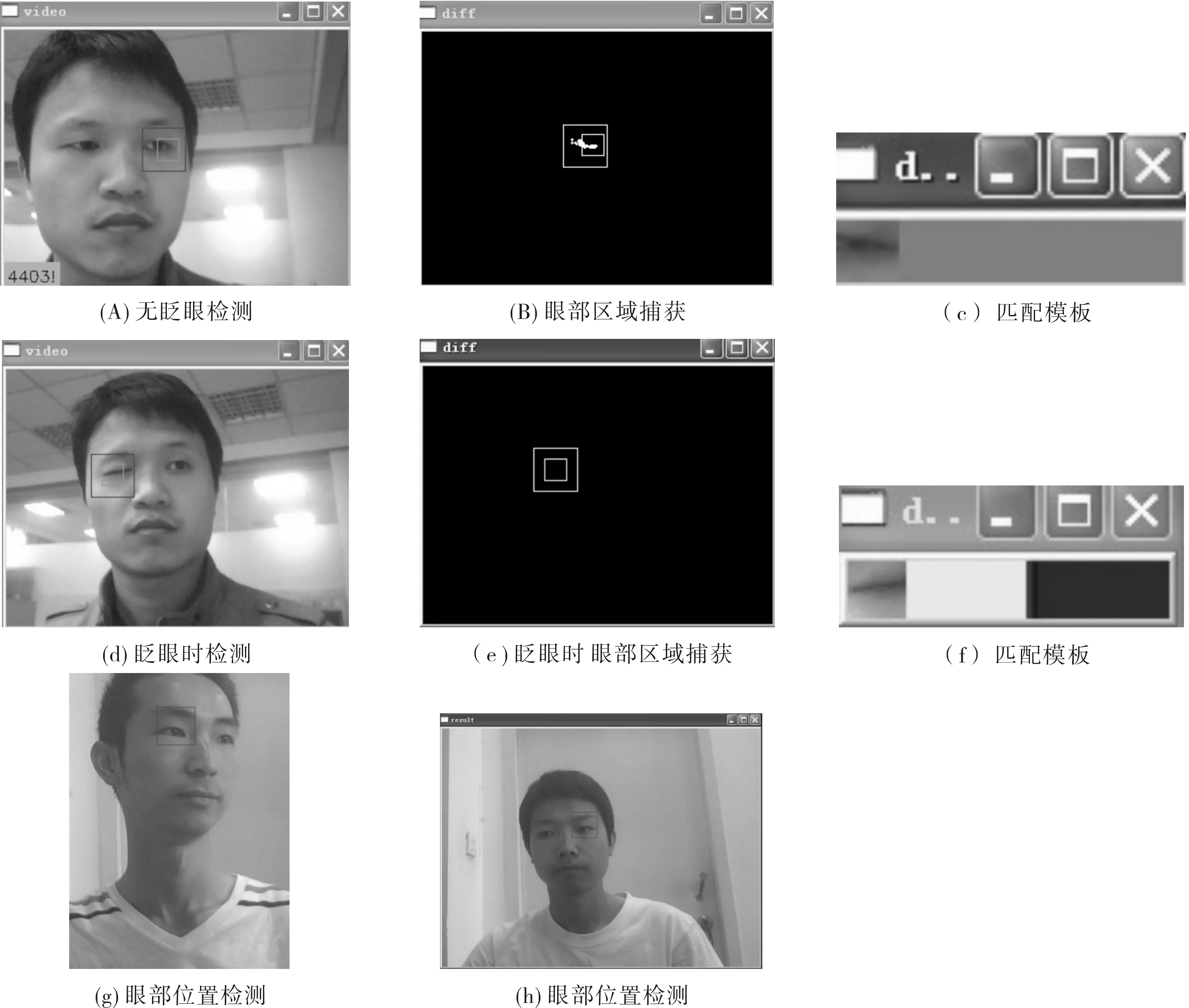
x1 (8) 的像素(x,y)构成,其中(x1,y1)和(x1+w,y1+h)为边界点. 对于眨眼动作的识别,本文将它转化为相关性的返回值判别.其原理是使用当前用户的眼部作为模板,当使用者闭上眼睛时,眼部和匹配模板的相似程度就下降,当使用者再次睁开眼时眼部和匹配模板的相似度就会上升.这种上升和下降的变化,同样使匹配返回值有了变化,而返回值的变化使眼部动作得到有效地检测. 该系统是在Pentium IV 2.7 GHz处理器、512MB RAM的XP硬件平台上使用Opencv图像库函数结合Visual Studio 2005软件开发并测试.图像采集设备为每秒可采30帧图像的USB摄像头,所捕捉视频大小为300×200的像素. 由于系统采用的是模板匹配的方法,在对视场区域匹配时并没有遍历整个视场区域,而是根据前一帧的匹配点来确定下一次要匹配的区域,所以有很好的实时性.考虑硬件负荷的关系,实验测试都是在每秒25帧图像的情况下完成.实验过程中面部大约距摄像头有1m的距离时识别效果最佳. 为了测量该系统的准确性,我们进行了100次的眼睛定位实验.在实验中有6次没有正确捕捉到眼部位置.同时为验证眨眼动作的捕捉情况,我们还进行了100次的眨眼捕捉试验,其中有18次没有正确的检测到眨眼动作.从实验中可知该系统对眼睛的正确捕获率约为94%,眨眼动作正确检测率约为82%,可以准确的找出眼部位置,并始终将眼部作为处理的有效区域,较好地捕捉眨眼动作,即使在闭眼的时候,也能准确地捕获和跟踪目标.实验结果如图4所示. 图4 实验结果图 经测试,系统可以完成如下任务:(1)采集输入的视频图像,并在抓取时实现对图像的压缩;(2)检测视频中眼部位置,并较好定位;(3)在头部有较大动作使眼部抓取范围丢失时,只需调整头部再眨眼即可重新获得目标;(4)可以识别眼部动作并返回参数值同时对眼部跟踪. 本文结合帧差法、模板匹配、轮廓检测、形态学处理利用摄像头设计了一种可以实时跟踪和分析人眼部动作的图像采集与处理系统,通过对目标的检测,能够完全的识别眼部位置和较准确的分析眼部动作.在检测初期,该系统利用运动分析来定位视场中眼睛的位置.这在大大简化了眼睛定位的时间的同时也带来了初始化失败的问题.对于初始化失败问题后续研究中准备利用一个合适的睁开眼睛的模板(这个模板来自使用者本身),在初始化失败后利用此模板重新定位视场中眼睛位置,增加系统稳定性.此外,为减小强烈的光照变化对系统的影响,后续的研究中准备加入Gray World算法,它用来平衡采集图像的色彩.以减少光照条件的影响.这些算法的加入对系统稳定性和准确性的影响都要在以后的工作中进一步研究和验证. [1] 谢勤岚,李圆双,喻 该.基于高速球型摄像机的运动目标检测与实时跟踪系统[J].中南民族大学学报:自然科学版,2010,29(2):80-84. [2] 吴正平,崔文超.一种基于Face SDK的人眼宽度测量系统[J].三峡大学学报:自然科学版,2010(5):90-92. [3] Ghijsen M.Facial expression analysis for human computer interaction[D].Twente:University of Twente,2004. [4] Liu Yazhou,Yao Hongxun,Gao Wen.Nonparametric background generation[J].J Vis Commun Image R,2007(18):253-263. [5] 冈萨雷斯.数字图像处理[M].阮秋奇,阮宇智,译.2版.北京:电子工业出版社,2005. [6] 刘瑞祯,于仕琪.Opencv教程:基础篇[M].北京:北京航空航天大学出版社,2007:262-268.3 实验分析
4 结语
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
含能材料(2021年1期)2021-01-10 08:34:34
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
中国眼镜科技杂志(2017年10期)2017-07-10 09:17:56
中国眼镜科技杂志(2016年2期)2016-12-01 06:37:13
中国眼镜科技杂志(2016年2期)2016-12-01 06:37:13
工业设计(2016年8期)2016-04-16 02:43:24
CHIP新电脑(2016年3期)2016-03-10 14:22:03
家庭科学·新健康(2015年8期)2015-08-19 15:11:07
