
冒泡排序算法及其改进算法的实验分析
2011-01-04 08:03:14淦艳杨有余平
重庆三峡学院学报 2011年3期
淦 艳 杨 有 余 平
(重庆师范大学计算机与信息科学学院,重庆沙坪坝 400047)
排序是计算机程序设计中的一种重要操作,它的功能是将任意序列的数据元素或记录,重新排列成一个按关键字有序的序列.在计算机系统中,元素或记录排序的时间占系统整个运行时间的比例很大;并且有序序列为记录的查找、插入和删除提供了方便,可以有效提高搜索效率;因此研究各类有效的排序算法一直是人们感兴趣的问题,也是计算机研究中的重要课题之一.
根据排序过程中数据记录是否被存储在内存中,可将排序方法分为两大类.[1]一类是内部排序,指的是待排序记录存放在计算机内部存储器中进行排序;另一类是外部排序,指的是待排序记录的数量很大,以致于内存一次不能容纳全部记录,在排序过程中尚需对外存进行访问的排序过程.而内部排序又包含插入排序、交换排序、选择排序、归并排序和计数排序等五类.在交换排序中,冒泡排序是其典型代表,本文将通过编程实验,验证和分析冒泡排序及其三种改进算法在不同随机程度输入序列下的性能.
为便于后续讨论,做如下假设:由于链式存储比数组存储多一倍的存储空间,因此算法中记录均默认为按数组方式存储,没有特殊说明时,均认为按升序排序.
1 相关的冒泡排序算法
1.1 传统冒泡排序算法
冒泡排序的基本思想是:[1]首先将第一个记录的关键字和第二个记录的关键字进行比较,若为逆序,则将两个记录交换,然后比较第二个和第三个记录的关键字.依次类推,直至n-1个记录和第n个记录的关键字进行过比较为止.上述过程称为第一次排序,其结果是让最大的记录被安置到最后一个记录的位置上.然后再进行下一次排序,直至整个序列有序为止.冒泡排序算法用C语言描述如下:
template<class Type>

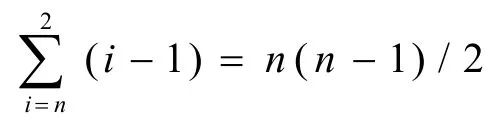
1.2 带标记的冒泡排序
带标记的冒泡排序算法基本思想是:[2]在冒泡排序过程中,只要在某一次排序过程中发现没有进行记录的交换,则说明该组记录已经有序,此时应该退出循环,即排序完成.带标记的冒泡排序算法用C语言描述如下:

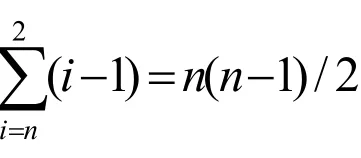
1.3 双向冒泡排序
双向冒泡排序算法基本思想是:[2,3]在传统的冒泡排序排序方法中,每次只能确定一个位置上的记录,如果一次能够确定两个位置上的记录,则会使排序所需次数减少,即在一端冒泡的同时在另一端也进行反向冒泡.用C语言描述如下:

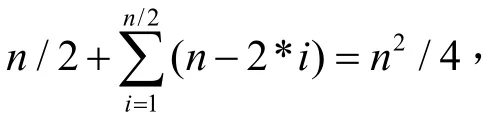
1.4 交替排序法
交替排序法是冒泡排序的变异.其基本思想是:[4]假设记录序列为R[ i](0 i n 1)≤ ≤ - ,首先将数据交换标志p置0,将R[1]与R[2]、R[3]与R[4]等两两相比较,如果逆序,则交换,同时将p置1;再将R[2]与R[3]、R[4]与R[5]两两相比较,如果逆序,则交换,同时将p置1;然后看p是否为0,若为0,就退出,即完成排序,否则继续循环.用C语言描述如下:

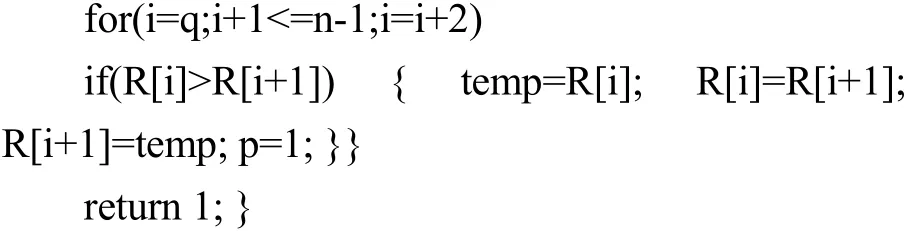
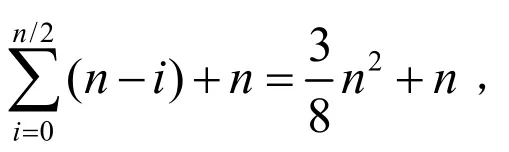
2 实验与分析
为了比较各个排序算法的性能,我们使用一台桌面电脑(AMD Sempron Dual Core Processer 2100, 1.81GHz,2.87GB的内存,Windows XP系统),在vs6.0环境下,用C语言编写程序,调用随机函数、时间函数来统计输入规模不同、传统冒泡排序算法及三种改进算法的耗时情况.该程序的主要功能为:产生的序列为1到100之间的随机序列;采用数组的方式存贮随机序列;根据不同的输入规模,得到传统冒泡排序算法及三种改进排序算法的时间耗.
首先,我们将考察四种算法随输入规模变化时的时间消耗.假设输入序列在以下三种情况下产生:(1)前25%由随机函数产生,后75%为升序序列;(2)前50%由随机函数产生,后50%为升序序列;(3)前75%由随机函数产生,后25%为升序序列.在这三种情况下,当输入规模分别为1 000、2 000、4 000、8 000、10 000、20 000、40 000、80 000时,四种排序算法的时间消耗分别如表1和图1所示.
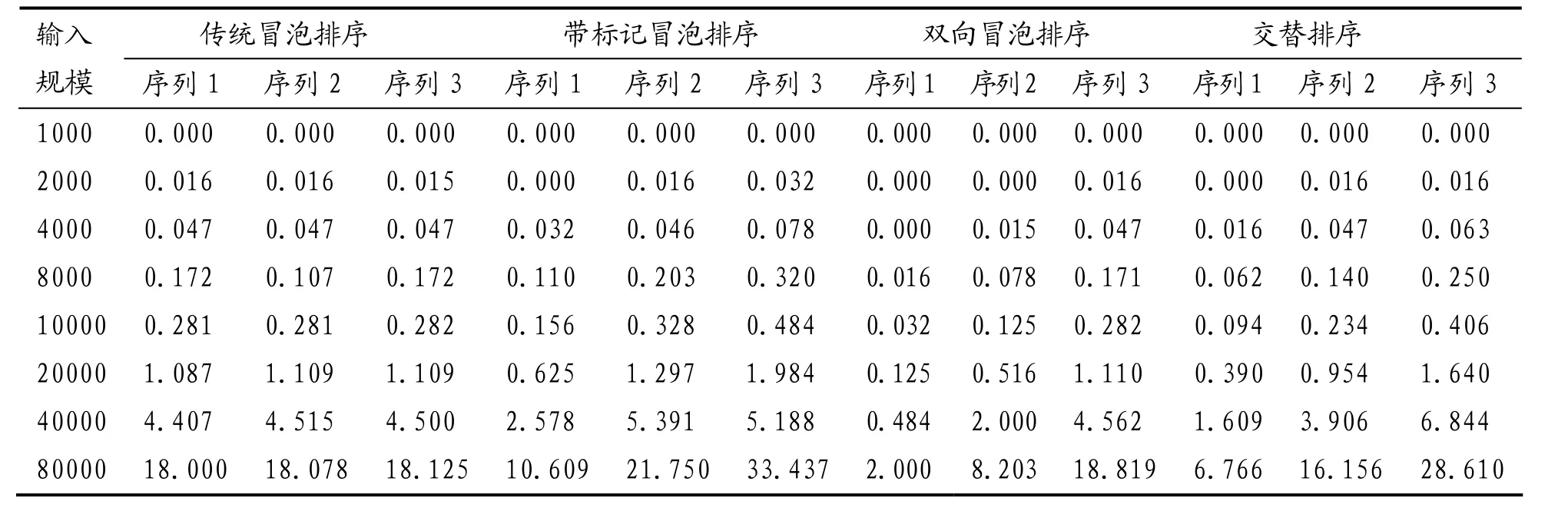
表1 四种冒泡排序算法针对输入规模的耗时
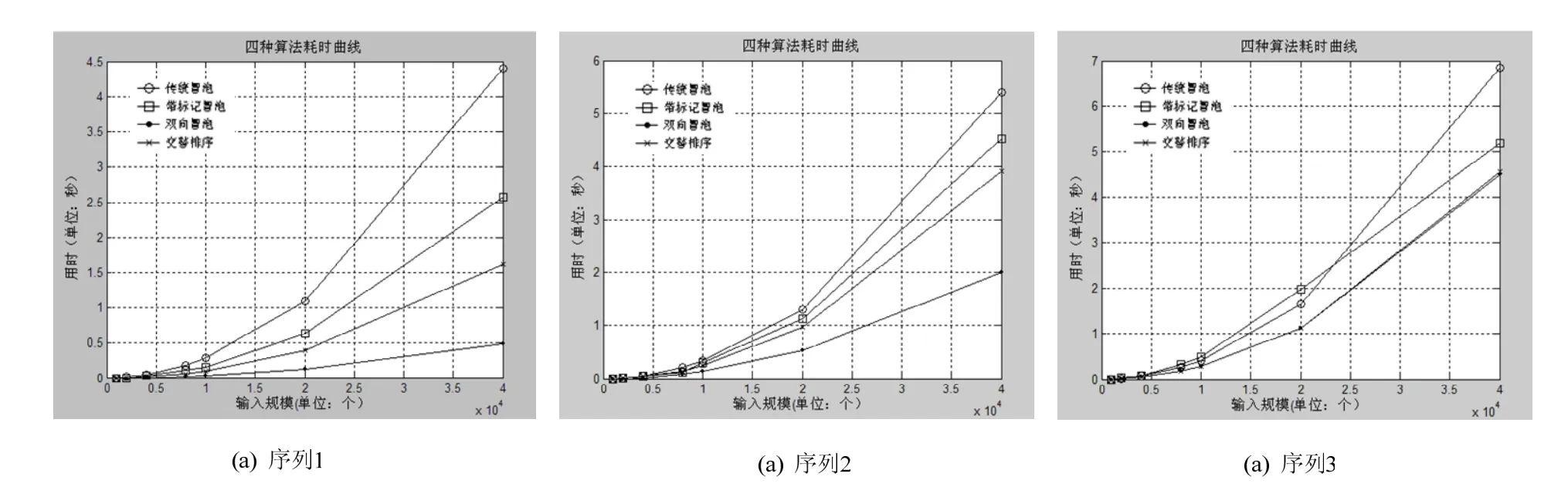
图1 四种排序算法随输入规模的耗时曲线
由表1和图1可知:在序列1情况下,传统的冒泡排序算法不及改进的三种算法优越,其中双向冒泡排序为最佳,其次是交替排序,最后是带标记冒泡.在序列2情况下,如果输入规模小于4000,带标记冒泡算法高于传统冒泡算法,但随输入规模的增加,带标记冒泡效率不及传统冒泡算法;忽略个别误差值,从整体来看双向冒泡、交替排序算法效率高于传统冒泡算法.在序列3情况下,传统冒泡排序算法效率高于改进的三种排序算法,此时的改进算法已经无优势可言.因此,在输入序列的随机程度比较大的情况下,三种改进的冒泡排序算法其性能较佳;相反,随着输入序列随机程度的降低,三种改进的冒泡排序算法其性能优势越来越弱.
其次,考虑在指定输入规模情况下,四种算法在输入序列随机度变化时的时间消耗.假设输入规模指定为10 000,四种排序算法的时间消耗如表2和图2所示.表2中,随机度为x,表示序列前x%是随机序列,后(100-x)%为升序序列.当x=0时,表示序列为正序序列,当x=100时,表示序列完全随机.
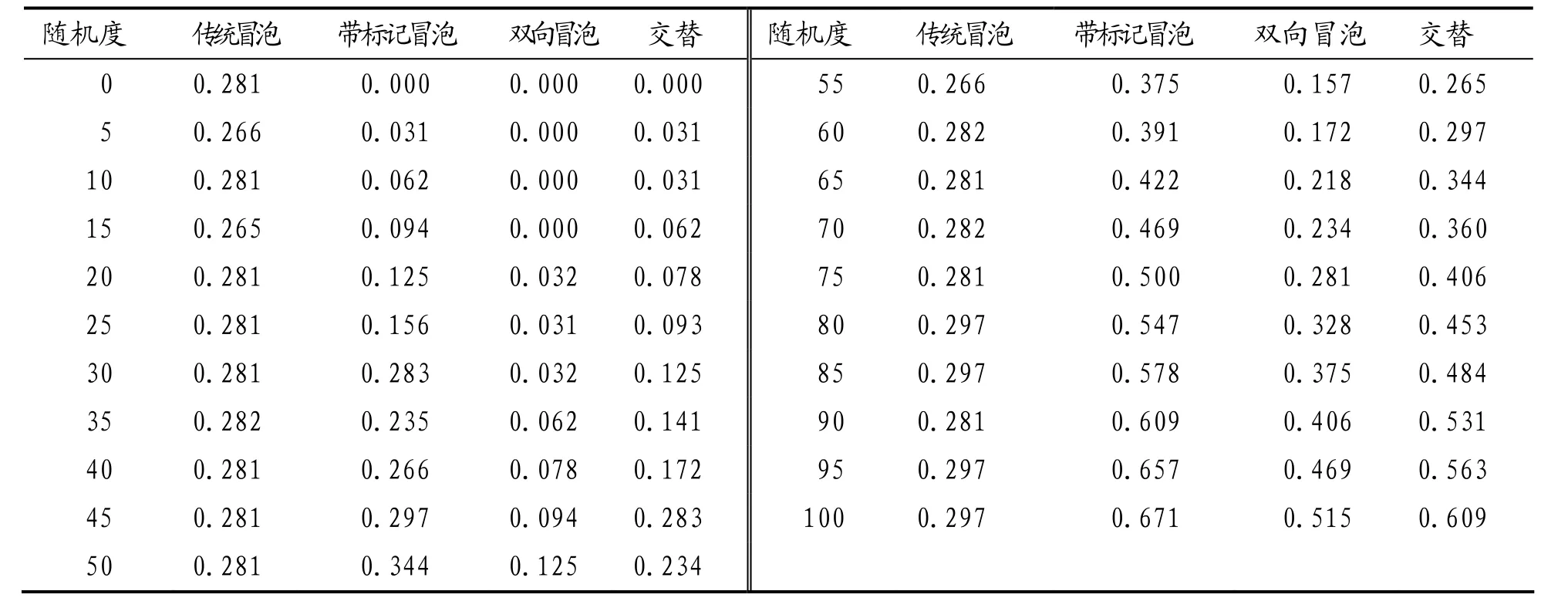
表2 四种冒泡排序算法针对随机度的耗时
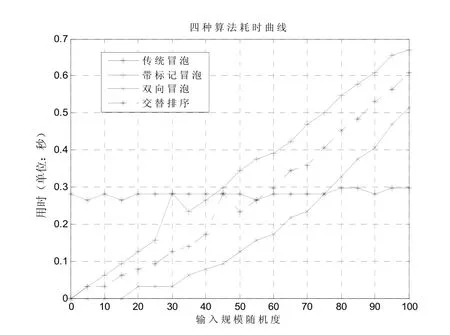
图2 四种排序算法随随机度的耗时曲线
当输入规模在10 000时,由表2和图2可知:
(1)传统冒泡排序的耗时曲线基本上呈一条水平直线,它表明输入序列的随机度对传统冒泡排序的时间消耗影响很小,或者说传统冒泡排序的时间消耗只与输入规模有关,而与输入序列的随机度无关;相反,另外三种算法的耗时曲线基本上呈相同斜率的直线,它表明这三种算法的时间消耗随输入序列随机度的增大而增加,同时这三种算法对应耗时增加的速度基本相同.
(2)传统冒泡排序的耗时曲线与其它三条曲线都有相交点,在某相交点的左边,传统冒泡排序的耗时高于相比较的算法,而在相交点的右边,则相比较算法的耗时高于传统算法.比如,传统冒泡排序算法和交替冒泡排序算法在随机度为 55时相交,它表明当输入序列的随机度小于 55时,交替冒泡排序算法的耗时较小,性能优于传统排序,否则,当随机度进一步增大时,其性能还不如传统排序.
(3)在改进的三种冒泡排序算法中,如果将其对应曲线视为斜线,则对应的截距不同.双向冒泡、交替排序和带标记的冒泡排序对应的横截距从大到小变化,它表明这三种算法对输入序列随机度的敏感性从小变大.此即:在相同耗时情况下,双向冒泡排序算法可以容忍更大程度的随机度;在相同随机度的情况下,双向冒泡排序算法的耗时最少.
3 总 结
通过对传统的、带标记的、双向的和交替排序四种冒泡排序算法的概述及改进算法的实验分析可以得出:
首先,用文字和C语言描述冒泡排序及其三种改进算法的基本思想,分析和总结出它们的平均时间复杂度为O(n2),空间复杂度为O(1).
其次,验证了输入不同随机程度的序列时,四种排序算法的性能存在差异.当输入序列前25%随机后75%升序时,带标记冒泡、双向冒泡、交替排序算法效率均高于传统冒泡排序算法,且双向冒泡排序耗时最少;当输入序列前50%随机后50%升序时,双向冒泡排序和交替排序算法效率高于传统冒泡排序算法;当输入序列前75%随机后25%升序时,改进的三种算法效率不及传统冒泡排序,此时则应选择传统冒泡排序算法.然后,由实验数据表明四种算法的时间消耗与输入序列的规模近似地呈指数曲线关系.
最后,验证了输入规模均为10 000,不同随机程度下,四种算法的性能由图2观察可知:实验说明输入序列的随机度对传统冒泡排序的时间消耗影响很小,或者说传统冒泡排序的时间消耗只与输入规模有关,而与输入序列的随机度无关;双向冒泡、交替排序和带标记的冒泡排序算法的耗时曲线基本上呈相同斜率的直线,它表明这三种算法的时间消耗随输入序列随机度的增大而增加,同时这三种算法对应耗时增加的速度基本相同.另外传统冒泡排序的耗时曲线与其它三条曲线都有相交点,在某相交点的左边,传统冒泡排序的耗时高于相比较的算法,而在相交点的右边,则相比较算法的耗时高于传统算法.除此之外,如果改进三种算法对应的曲线视为直线,则对应直线的倾斜度为 40˚左右,且截距不同.这说明输入序列随机度的敏感性存在差异,即双向冒泡、交替排序和带标记的冒泡排序的敏感性从小到大.因此,将输入规模、随机程度等因素考虑到实际应用中,会提高算法效率,节省排序时间.
[1]严蔚敏,吴伟民.数据结构[M].北京:清华大学出版社,1997.
[2]周秋芬.冒泡排序算法及其改进[J].新乡教育学院学报,2009(3):160-161.
[3]杨义磊.冒泡排序的分析改进算法[EB/OL].中国科技论文在线,http://www.paper.edu.cn.
[4]王爱松,张景龙.冒泡排序法的变异——交替排序法[J].内蒙古民族大学学报,2009(2):21.
猜你喜欢
出版人(2022年11期)2022-11-15 04:30:18
出版人(2022年8期)2022-08-23 03:36:50
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12
英语文摘(2020年6期)2020-09-21 09:30:40
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:46
科普童话·学霸日记(2020年1期)2020-05-08 16:45:11
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
儿童绘本(2018年5期)2018-04-12 16:45:32
通信电源技术(2016年5期)2016-03-22 01:09:37
Coco薇(2015年10期)2015-10-19 12:42:05
