
联结主义与语言习得研究
2010-11-14 06:24:56邓劲雷
黄冈师范学院学报 2010年2期
邓劲雷
(福建师范大学外国语学院,福建福州 350007)
联结主义与语言习得研究
邓劲雷
(福建师范大学外国语学院,福建福州 350007)
联结主义理论通过模拟大脑神经结构的运作来研究认知行为。该理论采用平行分布加工的方式来处理信息,这一信息处理方式具有许多与大脑相似的特性,如容错抗噪、内容寻址、自动生成原型和图式等。语言习得研究是认知科学的一个重要组成部分,联结主义理论对语言习得过程进行了大量的研究,深化了我们对语言习得过程的认识。
联结主义;语言习得;平行分布加工;神经网络
联结主义理论通过模拟大脑神经系统的运作来研究认知行为。这一范式下的研究始于 20个世纪 50年代,Hebb等学者对联结主义研究做出了开创性贡献[1],但是直到 1980年后,联结主义研究才得到全面发展。1986年《平行分布加工》两卷本的出版掀起了一场认知科学革命,它对传统的符号主义理论提出挑战,为认识认知行为提供了全新视角[2]。该书出版后,联结主义框架下的研究迅猛发展,并取得丰硕的研究成果[3-5]。本文拟使用语言习得研究的具体例子对联结主义的运作机制、功能、特性等进行介绍。
一、联结主义原型:大脑神经网络
联结主义理论的灵感来源于神经科学。神经科学发现大脑中神经元的数量极其庞大[6]。神经元作为大脑的基本组成单位,由树突、胞体和轴突组成,其功能类似于一个简单的计算器。树突负责接受其它神经元的轴突传递过来的神经信号;胞体主要负责对所接收的信号进行计算并确定要输出的信号值;轴突再将这些信号传递给其它的神经元。轴突与树突之间的通信结点称为突触,它的联结权重决定神经元相互作用的强度。
神经元不仅数量庞大,而且神经元之间的联结数也非常庞大。每个神经元可以与其它的神经元形成 1,000到 100,000左右的联结。科学家认为知识存储于这些联结当中 (而不是单个神经元当中),即知识在大脑中是分布表征的。大脑学习的过程是调节突触联结权重的过程[6]。神经元虽然数量庞大、联结众多,但是运算速度比较缓慢,每运算一次大约需 10毫秒的时间,即每秒钟大约只能进行 100次左右的运算。由于这一运算速度的限制,人脑无法采用图灵机式的串行运算方法。人脑在 1秒钟的时间内需进行一些非常复杂的运算,如人脸的识别,危险的判断等,这使得大脑中比较切合实际的运算模式是大规模的平行运算[6]。
二、联结主义架构和运作机制
联结主义网络是大脑神经网络的简化,它由大量与神经元功能相类似的节点组成,其结构如图1所示,节点结构如图2所示。
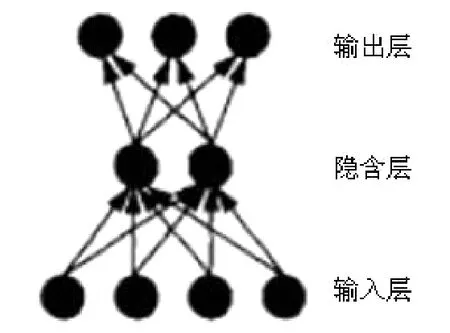
图1 三层前馈式网络[7]
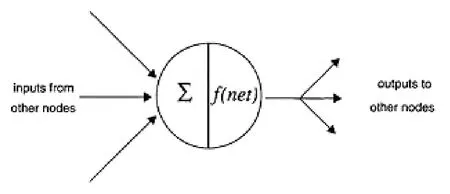
图2 联结主义神经网络节点示意[7]
联结主义网络中,节点与节点相互联结,以传递和表征信息。节点与节点之间的信息传递通过传播规则①进行计算:
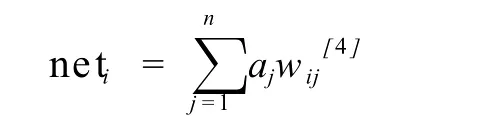
上述公式中,neti为节点 i的总输入值;n为节点 i的输入节点数量;aj指与节点 i相联的 j节点的激活值 (输出值);wij指节点 i与节点 j的联结权重。该公式表示单个节点的输入信息值等于与它相联结的输入节点的激活值与联结权重乘积的总和。该过程是节点对输入信息的汇总过程。
节点对信息汇总后,便对这些信息进行计算以确定输出信息,该过程通过激活规则进行计算:
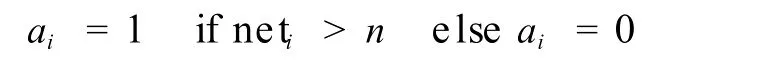
上述公式中,ai为节点 i的激活值 (输出值),neti为节点 i的信息总输入值,n为节点 i的激活阈值。该规则表示当输入值大于阈值时,节点输出1,否则输出 0。
大脑的学习通过调节突触的联结权重来完成,与之相对应,联结主义网络的学习则通过调节联结点的联结权重来完成。联结权重的调节通过学习规则进行计算:
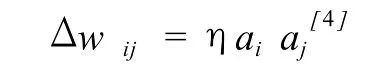
上述公式中,Δwij为节点 i和节点 j的联结权重的调节量;η为学习速度常数;ai为节点 i的激活值;aj为节点 j的激活值。该公式是著名的学习规则 Hebb规则的公式化表述。Hebb认为“如果细胞 A的轴突与细胞 B足够接近,并能使之兴奋,当 A重复或持续的激活 B,那么这两个细胞,或其中一个会发生生长或代谢变化,使得 A细胞激活 B细胞的效率提高[1]。”
联结主义网络的功能和特性主要由上述三个规则和节点的联结模式 (架构)决定。不同架构的联结主义模型的学习能力存在一些差异。如,双层前馈式网络虽然可以成功模拟许多联结式的学习,却无法进行 XOR计算。XOR计算需要三层前馈式网络(在双层前馈式网络的基础上加入隐含层,如图1所示)。Hornik等更是指出三层前馈式网络是通用的模拟器,可以进行任何形式的计算和学习[8]。
三、语言学习模拟
识字是语言学习的一个重要环节。识字过程是音、形、义的联结过程。本文主要探讨音和形的联结模拟。以单词“dog”为例。假定“dog”在大脑中的拼写表征为(1,0,1,0,1),语音表征为 (1,1,0,0,1)。学习这一组表征需要 5个代表语音表征的神经元,这 5个神经元各有 5个树突,并分别与代表视觉表征的神经元的轴突相联。整个模型如图3所示。图中 Pattern 1代表语音神经元的激活模型,Pattern 2代表视觉表征。假定该模型中各联结点的初始联结权重为 0,那么图3的信息可用图4的矩阵表示。
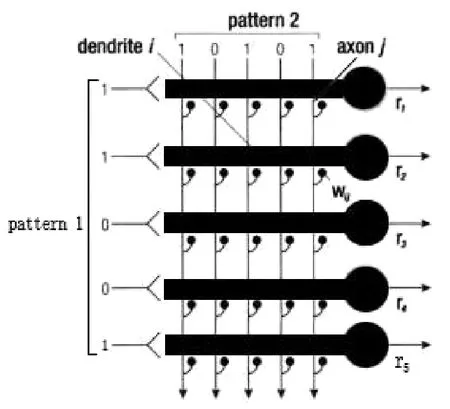
图3 学习网络示意图[9有改动]

图4 学习前的联结权重矩阵图
联结视觉与语音表征需使用 Hebb学习规则。假定该规则中的学习速度常数η为 1②,那么一次学习后,节点 (1×1)的联结权重变化值为:
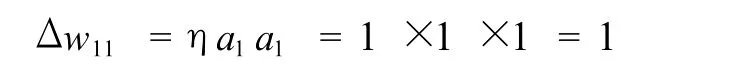
由于节点 (1×1)的初始值为零,因而调节后的联结权重为 1。学习过后的各联结点的数值如图5所示。
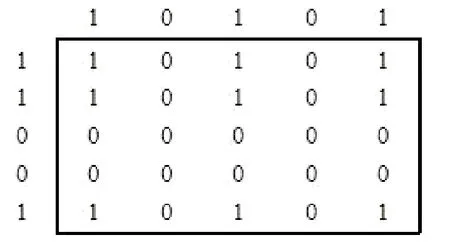
图5 一次学习后的联结权重矩阵图
联结权重调节后,也即学习后,我们将“dog”的拼写表征 (1,0,1,0,1)输入网络,检验网络能否正确输出语音表征。表征输入网络后,需在网络中传播。根据传播规则,神经元 1的总输入值net1为:
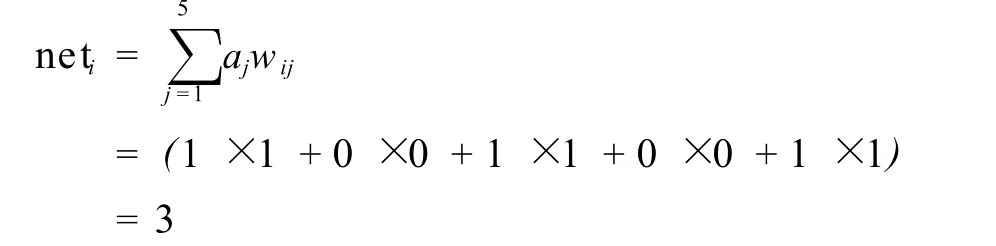
其它神经元的输入值可依此类推,其结果如图6所示:

图6 各神经元总输入值示意图
神经元接受输入信息后,便会对输入信息进行计算以确定输出信息,假定该网络的神经元为阈值型神经元且激活阈值为 3,输入值达到激活阈值后输出 1,否则输出 0。那么该网络的输出值为 (1,1,0,0,1),即学习过后,该模型能通过单词的拼写正确输出单词的语音表征。
上述网络不仅可以表征“dog”的音、形联结,还可以同时表征其它单词的音、形联结,如“dig”。假定“dig”的拼写表征为 (1,0,0,1,1),语音表征为 (1,0,0,0,1),学习常数仍为 1,学习过后的各联结点的联结强度如图7所示。

图7 学习“dig”后的联结权重矩阵图
当我们将“dog”的拼写表征 (1,0,1,0,1)输入网络,各神经元的总输入值为 (5,3,0,0,5),由于各神经元的激活阈值为 3,因而网络的输出信息为 (1,1,0,0,1),即仍为“dog”的语音表征。如果将“dig”的拼写表征 (1,0,0,1,1)输入网络,各神经元的总输入值为 (5,2,0,0,5),整个网络的输出信息为 (1,0,0,0,1),即“dig”的语音表征。这表明同一个网络可以表征不同单词的音、形联结。
四、联结主义网络特性
联结主义网络由于采用了与大脑神经网络相似的结构,因而相应的具备了一些与大脑类似的特性,如:容错抗噪,自动生成原型和结构,内容寻址等特性。
(一)容错抗噪功能 人脑具有很强的容错性。大脑细胞的自然死亡并不影响我们的认知能力,有时甚至大脑的局部损伤对其总体功能也没有影响。这一功能其实是平行分布加工的自然结果。假定在上述网络中联结点 (1×3)和 (5×4)受损,如图8所示:

图8 受损节点示意图
我们将“dog”和“dig”的视觉表征 (1,0,1,0,1)和(1,0,0,1,1)分别输入网络,通过计算得出各神经元总输入值分别为 (4,3,0,0,5)和 (5,2,0,0,4),整个网络的输出值为 (1,1,0,0,1)和 (1,0,0,0,1),即虽然网络中部分联结点损伤,网络仍能正常运作。
人脑还具有很强的抗噪功能。每个人的音质,音色均有差异,但这并不影响人们之间的交流。即便是在马路边、行驶的汽车上这样吵杂的环境中,人们仍能比较顺畅的沟通,这表明人脑有较强的抗噪功能。仍以“dog”为例。在上文中,我们假定“dog”的表征是 (1,0,1,0,1),但由于“噪音”的存在,使得输入信息被改变为 (1,1,1,0,1),这一信息虽然与原先的信息有一定的差异,但通过计算,可以发现得到的结果仍是 (1,1,0,0,1),也即联结主义网络与大脑一样具有抗噪功能。
联结主义网络的容错抗噪性,或者大脑的容错抗噪功能,是平行加工和分布表征的自然结果[9]。在联结主义网络或大脑中,信息是由大量神经元或节点组成的激活模式(activation pattern)决定,在大脑中,一个信息的表征可能需要成千上万的神经元,如果少量神经元损伤或者提取信息中存在少量“噪音”,并不会改变总的激活模式。这也是大脑或联结主义网络具有容错抗噪能力的原因所在。
(二)自动生成结构和图式 上文中的“dog”和“dig”有一致的结构“D*G”。由于采用分布表征的方式,这两个单词中的“D*G”结构在网络中的表征也是类似的,当网络多次存储或提取这两个信息是,代表“D*G”结构的联结模式不断被激活,代表这一激活模式的联结权重不断被加强,使得的“D*G”结构在网络中被突显出来 (如图7所示)。这一结构的产生是信息表征在网络中层叠的结果。由于采用分布表征的信息存储方式,多个信息可以共存于同一网络中。各信息中相同部分比起信息中不同的部分,被存取的机会要多,因而激活的次数也较多,相应的联结权重也较高,于是这些相同的信息就被突显出来。这些被突显出来的信息 (也就是输入信息中相似或相同的部分)就是结构,根据应用场合的不同,它们有时也被称作框架或图式。
(三)原型效应 Rosch的一系列实验使原型效应成为认知科学中广为人知的概念[10,11]。在实验中,她发现人们总是认为范畴中一些成员比其它的成员更典型;在列举范畴成员时,一些成员总是更早且更频繁的被列举出来③。Rosch和Mervis指出典型成员是与同一范畴中其它成员具有最多家族相似性的成员。Rosch和Mervis的这一论断在联结主义的模拟实验中得到了很好的证明。McClelland和 Rumelhart(1985)利用联结主义网络对原型效应进行模拟研究。在实验中,他们使用一个 24节点的网络。网络的后 16个结点用于存储视觉表征。假定训练中使用的表征代表狗的视觉信息,且每次训练所使用的表征之间有轻微的差异,用于代表不同的狗。网络的前 8个结点用于存储名字表征。如果训练过程中采用同一表征 (如“dog”)对前 8个节点进行训练。多次训练过后,对前 8个节点输入“dog”表征,后 16个节点激活的视觉表征值与先前训练表征的平均值比较接近,即与各训练表征具有最多家族相似性。
(四)内容寻址 内容寻址指通过部分信息提取全部信息的一种信息检索方式。它是人脑区别于图灵机的一个重要标志。图灵机通常采用地址寻址方式检索信息。提取信息时,先查找地址,再通过地址通达内容。这种寻址方式类似于字典的信息检索方式。查字典时,需先查找词条,再通过词条查找解释。因而即便是最好的字典,要查到“面积为 960万平方公里,人口为 13亿的国家是哪个?”也相当困难。而任何一个对中国有所了解的人都能很快说出答案。人脑或联结主义网络与图灵机或字典的信息检索的重要差别就在于此。在联结主义网络中,信息存储通过内容与内容的相互联结实现。信息提取是神经元的模式激活过程。这种信息存储和提取方式类似于 Collins和 Loftus(1975)所提出的激活扩散模型。所不同的是在激活扩散模型中,被激活和扩散的是一个个节点,而在联结主义网络中,被激活扩散的是由许多节点组成的激活模式。提取信息输入网络后,会激活代表该信息模式的一些节点。这些节点随之向与它紧密相联的节点传递信息,使相邻节点也处于激活状态,直到所需的信息模式被激活。这种信息扩散激活的能力使联结主义网络具备了内容寻址的能力。
五、联结主义框架下的语言习得研究
联结主义理论对语言习得进行了大量的模拟研究。其中最广为人知的是英语过去式的习得模拟[5,15]。这些模拟不仅能正确生成过去式,而且学习过程也与儿童的学习过程相似。如呈 U型状发展。除对英语过去式的习得进行研究外,联结主义网络还对语言习得过程的模拟还包括:语音习得关键期现象[16],言语切分[17-19],句法范畴习得[20,21],语言结构习得[3,22]等。这些研究大大深化了我们对语言习得过程的认识,但是限于篇幅,在此不做详细介绍。
联结主义理论对语言习得的研究取得了丰硕的成果。但联结主义理论毕竟才刚刚起步,许多领域还有待进一步研究。如在句法习得上虽然取得了一些成果,但总得说来还不尽如人意。句法结构的习得不仅需要形式结构上的相似性,还需意义和功能上的相似性,但目前却还没有恰当的方法在网络中表征功能或意义。虽然联结主义研究还面临着许多类似挑战,语言和其它认知活动归根到底都需由大脑来完成,它必然受到大脑架构和运作机制的影响。联结主义通过模拟大脑的神经网络来研究人类的认知行为无疑能使我们对大脑和认知行为的奥秘有更深刻的认识。
注释:
①以下对传播规则、激活规则和学习规则的介绍,仅限本文例子中需用到的规则,如需对网络的三个规则深入了解 ,请参阅 McLeod等 (1998)或 Rumelhart和 McClelland(1986)的著作。
②学习速度常数决定联结权重变化的速度。该数值较大时,联结权重变化较快,相应的学习速度也较快。但是,如果该数值过大,则可能导致无法达到理想的学习效果。
③关于原型研究的详细回顾可参看Lakoff(1987)。
[1]Hebb,D.O.,The Organization of Behavior:A Neurophysiological Theory.New York:John W iley&Sons Inc,1949.
[2]Rumelhart,D.E.,J.L.McClelland,and t.P.R.Group,Parallel Distributed Processing-Vol.1 Foundations.TheM IT Press,1986.
[3]Elman,J.L.,Learning and Development in NeuralNetworks: the importance of starting small. Cognition,1993.48:p.71-99.
[4]Elman,J.L.,et al.,Rethinking innateness:A connectionist perspective on development.1996:M IT Press.
[5]Plunkett,K.and V.Marchman,From rote learning to system building:acquiring verb morphology in children and connectionist nets.Cognition,1993.48(1):p.21-69.
[6]Rumelhart,D.E.and J.L.McClelland,PDP Models and General Issues in Cognitive Science,in ParallelDistributed Processing-Volume 1:Foundations,D.E.Rumelhart,J.L.McClelland,and t.P.R.Group,Editors.1986,TheM IT Press.p.110-146.
[7]Plunkett,K.and J.L.Elman,Exercises in Rethinking Innateness.1997:M IT Press.
[8]Hornik,K.,M.Stinchcombe,and H.White,Approximation Capabilities of Multilayer Feedforward Networks.NeuralNetworks,1991.4(2):p.251-257.
[9]McLeod,P.,K.Plunkett,and E.T.Rolls,Introduction to ConnectionistModeling of Cognitive ProcessesOxford University Press,1998.
[10]Rosch,E.H.,Natural Categories.Cognitive Psychology,1973.4:p.328-350.
[11]Rosch,E.H. and C.B.Mervis,Family Resemblances:Studies in the Internal Structure of Categories.cognitive Psychology,1975.7:p.573-605.
[12]Lakoff,G.,Women,Fire,and Dangerous Things:What Categories Reveal about the Mind.Chicago:The University of Chicago Press,1987.
[13]McClelland,J.L.and D.E.Rumelhart,Distributed Memory and the Representation of General and Specific Infor mation.Journal of Exper imental Psychology:General,1985.114(2):p.159-188.
[14]Collins,A.M.and E.F.Loftus,A Spreading-Activation Theory of Semantic Processing.Psychological Review,1975.82(6):p.407-428.
[15]Rumelhart,D.E.and J.L.McClelland,On Learning the Past Tense of English Verbs,in Parallel Distributed Processing-Vol.2:Psychological and BiologicalModels,J.L.McClelland,D.E.Rumelhart,and t.P.R.Group,Editors.TheM IT Press,1986.
[16]McClelland,J.L.,J.A.Fiez,and B.D.McCandliss,Teaching the vertical bar r vertical bar-vertical bar 1 vertical bar discrimination to Japanese adults:behavioral and neural aspects.Physiology&Behavior,2002.77(4-5):p.657-662.
[17]Brent,M.R.and T.A.Car twright,Distributional regularity and phonotactic constraints are useful for segmentation.Cognition,1996.61(1-2):p.93-125.
[18]Christiansen,M.H.,J.Allen,andM.S.Seidenberg,Learning to segment speech using multiple cues:A connectionist model.Language and Cognitive Processes,1998.13(2-3):p.221-268.
[19]Elman,J.L.,Finding Structure in Time.Cognitive Science,1990.14(2):p.179-211.
[20]Redington,M.,N.Chater,and S.Finch,Distributional information:A powerful cue for acquiring syntactic categories.Cognitive Science,1998.22(4):p.425-469.
[21]Mintz,T.H.,Category induction from distributional cues in an artificial language.Memory&Cognition,2002.30(5):p.678-686.
[22]Christiansen,M.H.and N.Chater,Toward a connectionist model of recursion in human linguistic performance.Cognitive Science,1999.23(2):p.157-205.
H0
A
1003-8078(2010)02-084-05
2010-03-21
邓劲雷 (1979-),男,福建莆田人,福建师范大学外国语学院讲师。
责任编辑 张吉兵
猜你喜欢
自然杂志(2021年6期)2021-12-23 08:24:46
艺术品鉴(2020年9期)2020-10-28 09:00:16
当代陕西(2020年17期)2020-10-28 08:18:18
意林·全彩Color(2018年9期)2018-10-12 01:07:04
人大建设(2018年5期)2018-08-16 07:09:00
现代装饰(2018年5期)2018-05-26 09:09:01
电信科学(2017年6期)2017-07-01 15:44:57
Coco薇(2016年7期)2016-06-28 02:13:55
Coco薇(2015年12期)2015-12-10 02:53:05
电源技术(2015年5期)2015-08-22 11:18:38
