
基于DSP的四路H.264视频编码器的实现与优化
2010-11-13 07:45:00张新安
湖南科技学院学报 2010年4期
张新安
(湖南科技学院 电子工程系,湖南 永州 425100)
0. 言
H.264是ITU-T的视频编码专家组(VCEG)和ISO/IEC的活动图像专家组(MPEG)联合制定的新一代视频编码国际标准[1]。H.264以实现视频的高压缩比、高图像质量和良好的网络适应性等优点,被广大视频应用产业接纳。相对于传统视频标准MPEG-2,H.264的压缩比提高了2~3倍,极大地节省了视频存储容量和网络带宽,因此,一直有许多学者致力于H.264视频编码器的设计与优化研究[2-5]。
H.264编码系统被广泛应用于当今数字视频监控领域,如银行和证券集中监控、市内交通和高速公路集中监控、小区和楼宇安防等。目前市场上大部分商用化的视频编码系统产品都采用 ASIC芯片设计,通常只能完成一路视频的实时压缩,在许多实际应用中,常常需要对多路场景进行实时监控和存储,使用一片 DSP实现多路视频监控,能充分利用DSP的运算能力,可以降低成本,减少设备的功耗和体积。
本文设计的基于TMS320DM642(以下简称DM642)的H.264视频编码器,在硬件设计上,充分利用了DM642可以输入多路不同格式音视频信号的特点,实现了 DSP处理与EDMA传输并行工作,在编码器的软件实现中,对运动估计、整数反变换、去块滤波等关键模块的算法进行了改进,并对资源使用和软件代码进行了全面优化,能对四路分辨率为CIF352×288的视频信号实现H.264视频格式的实时编码,具有功能强、可靠性高、体积小、功耗低和易于升级等特点。
1..264视频编码器的硬件实现与优化
1.1..264视频编码器的硬件系统设计
本系统以DM642DSP为核心,实现四路CIF352×288视频格式的H.264标准的实时编码,硬件系统结构如图1所示。
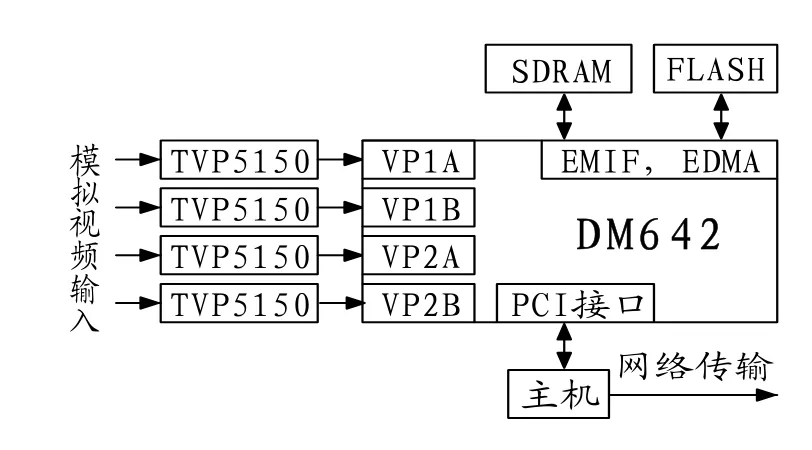
图1.路视频编码器硬件系统结构图
TMS320DM642[6]是TI公司开发研制的一款专门面向多媒体应用的专用DSP芯片,548脚BGA封装,芯片内核时钟高达600MHz,处理能力最高可达4800MIPS,采用VLIW和L1/L2两级缓存结构,并且支持EDMA,有专门为多媒体应用设计的三路视频输入、输出端口(VP口),每个VP口又分成A和B 两个通道,可与两路10bit或一路20bit视频A/D转换器直接相连,通过复用三路VP口最多允许6路视频输入。
主机首先通过PCI初始化DSP并对其加载程序,DSP开始运行H.264编码程序;输入的模拟视频信号经TVP515(0支持PAL和NTSC两种制式)被数字化为YUV4∶2∶2的数字视频格式,DM642的VP口对输入的数字信号进行格式转换,将采集的YUV分离并按照YUV分量各自连续存放的格式存放在SDRAM中,DSP通过EDMA完成4∶2∶2到4∶2∶0的视频格式转换,以适应H.264编码的要求;视频从VP口采集进来之后,采用EDMA方式进行数据搬移,搬移到缓存(cache)中之后,DM642便对数据进行压缩处理;DSP完成一帧图像的编码,通过PCI向主机发出中断,主机响应中断,从DSP的存储空间读取原始图像数据和压缩后的码流。主机程序在 VC++环境下编写,提供与用户交互的界面,可进行原始视频的实时播放、压缩编码、保存、网络传输;压缩码流的实时解压播放、保存、回放;从网络接收压缩码流实时解压回放等各种处理。
1.2..264编码算法的DSP实现与优化
将H.264编码算法在DSP上实现与优化,需要经过PC机端算法实现及优化、PC机代码的DSP化和DSP代码优化等几个步骤。
1.2.1.PC机上实现H.264算法并进行优化
选取 ITU-T的 JM6.1e参考软件作为优化对象,但是JM6.1e代码复杂,冗余度很大,需要在PC机端对其进行较大调整,涉及工作有:去除冗余代码、规范程序结构、全局和局部变量的调整和重新定义、结构体的调整等。
1.2.2.C机H.264代码的DSP化
ITU-T官方提供的H.264核心算法代码是用C语言编写、在PC机上实现的。C6000开发工具Code Composer Studio有自己的 ANSIC编译器和优化器,并有自己的语法规则和定义,所以在DSP上实现H.264的算法,要把PC机上C语言编写的H.264代码进行改动,使其完全符合DSP中C的规则。
这些改动包括:去除所有的文件操作;去除可视化界面的操作;合理安排内存空间的预留和分配;规范数据类型,把浮点数的运算部分近似用定点表示,或用定点实现浮点运算;根据内存的分配定义远近程常量和变量;把常用的数据在数据结构中提取出来,以near型数据定义在DSP内部存储空间,以减少对EMIF端口的读取,从而提高速度。
1.2.3.SP代码的优化
通过把PC机H.264代码DSP化,可以在DSP上实现H.264的编解码算法,但是,这样实现的算法运行效率很低,所以必须结合DSP本身的特点,对其进一步优化,才能实现H.264视频编码器算法对视频图像的实时处理。
对DSP代码的优化分为项目级优化、C程序级优化和汇编程序级优化三个层次。
(1)项目级优化:主要是通过选择CCS提供的编译优化参数,根据H.264系统的要求进行优化,通过不断地对各个参数(-mw -pm -o3 -mt等)的选择、搭配、调整,改善循环、多重循环体的性能,进行软件流水,从而提高软件的并行性。
(2)C程序级优化:主要是针对采用的DSP的具体特点进行代码的功能精简、数据结构的优化、循环的优化、代码的并行化处理。主要工作包括以下部分:去除掉SNR计算、帧率及其他辅助信息的程序模块;函数及数据映射区域的调整,把经常用的数据存储在片内存储器中,频繁调用的程序尽可能映射在相邻或相近的存储区域;针对并行化效果差的函数,尤其是多重循环体,要进行循环拆解,将多重循环拆解为单重循环;减少存储区数据的读取和存储,尤其是片外存储区域数据的调用,以减少时间;数据结构的重新定义和调整。
(3)汇编程序级优化。汇编级的优化包括两部分:采用线性汇编语言进行优化和直接用汇编语言进行优化。由于系统编译器的局限性,并不能将全部的函数都很好地优化,这样就需要统计比较耗时的C语言函数,用汇编语言重新编写。对耗时函数进行汇编语言改写,涉及的函数有DCT变换,反DCT变换,整象素运动估计,亚象素搜索,帧内编码函数,插值函数等。
2..264视频编码器的软件设计与优化
2.1..264视频编码器软件设计
软件设计分为视频采集、多路视频处理和视频压缩三个部分。
视频采集采用并行设计,即通过DM642的VP口同时处理四路视频源,将数据存放到对应 VP口的缓存区。在SDRAM 中,为每一路视频开辟三个缓存区,通过中断信号改变缓存区的指针,将VP口中的数据通过EDMA搬移到缓存区中周期存放。在采集部分,充分使用DM642的VP口资源和片外SDRAM,无须消耗DSP的资源,提高了系统的运行效率。
多路视频的处理采用四路编码串行执行,即通过用户程序控制DSP,在编码完第一路的当前视频帧后,再编码下一路的当前视频帧,依次循环进行。
视频压缩部分采用的H.264标准是以宏块为单位的变换和预测的混合编码技术,如图2所示。编码过程主要包括变换、量化、熵编码、反量化、反变换、帧内预测、环路滤波、图像重建、运动估计及运动补偿。
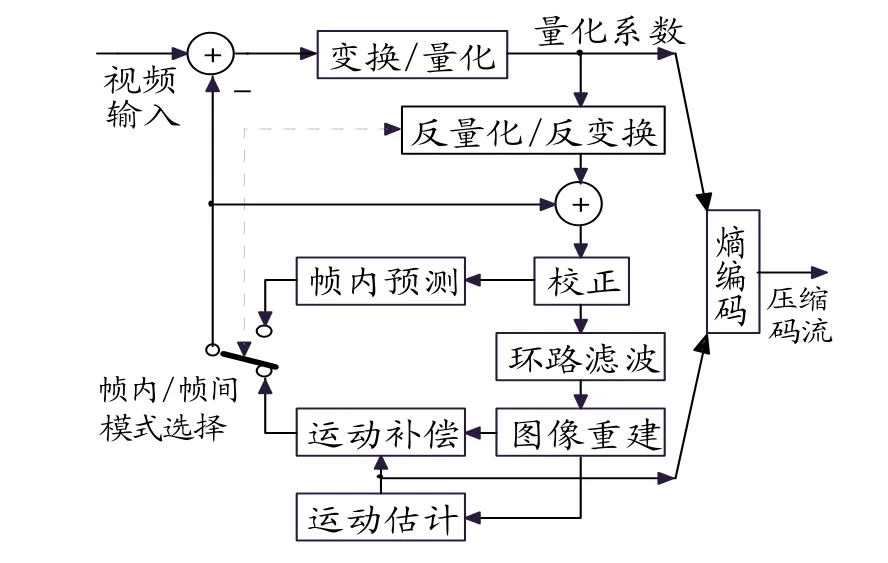
图2..264视频编码器方框图
2.2..264视频编码器的软件优化
H.264编码计算量庞大,而DSP的硬件资源有限,需要结合DSP的特点进行较好的优化,才能达到实时编码的要求。下面给出Cache性能优化和存储的配置优化的方法。
2.2.1.ACHE的性能优化
DM642的存储器系统由片内内存L1、L2和片外外存两部分组成,L1、L2和片外SDRAM构成了整个存储器系统的三级层次结构,如图3所示。片内内存采用两级缓存结构,第一级由L1P和L1D组成,L1距离DSP内核最近,数据访问速度最快,只需一个时钟周期。第二级L2是一个统一的程序/数据空间,根据L2配置为Cache或SRAM的不同选择,访问速度需 8个或 6个时钟周期。第三级是片外外存,由SDRAM 构成,片外存储器容量很大但访问速度很慢,远远大于8个时钟周期。

图3.级存储器系统结构图
对CACHE性能优化,本设计采用了下列一些方法:合理配置L2;合理布置程序代码段和数据段的内存布局,为防止有效代码、数据在缓冲存储器中相互排挤,尽量把顺序执行的代码、同时使用的数据放在相互邻接的物理空间当中;若函数模块和数据包含在一个循环中,循环体的大小应与Cache的容量相吻合,以便能把整个循环体全部放入 Cache中;为提高Cache中数据的重复利用率,把数据操作构成一条数据处理链,链中的下一级操作直接使用上一级操作留在Cache中的数据;根据Cache行数据宽度信息,调节数据在物理内存中的存放位置,从而利用数据预取增加Cache的命中率;通过合理的数据填充策略,避免同一时钟周期对相同存储体的读写操作造成存储器的存取冲突。
2.2.2.储器的配置优化
DSP的程序数据存储空间非常有限。因此,对于视频编解码这种需要处理大量数据的程序而言,必须合理安排数据和程序的存储方式,实现对存储器的优化,以便提高程序执行的效率。否则,大量数据的反复搬移会阻碍程序运行效率的提高。
原程序有很多不适应DSP系统的程序流程结构,如内存分配和释放操作频繁,没有在一开始就分配好内存,而是在一个个单独的函数中分配和释放内存,不仅程序运行效率低,还产生许多不必要的临时存储空间。为此,要对原有程序结构进行修改,调整程序运行流程,合并部分函数,使程序结构能充分利用DM642的硬件特点,尽量节省存储空间。
根据片内存储器容量小而存取速度快,片外存储器容量大但存取速度慢的特点,在分配存储器的时候对于那些经常使用的变量放在片内,如 VLC表、运动矢量、反量化、反DCT的系数以及其它中间变量等,而对于那些执行次数比较少或者比较大的变量如视频帧参考帧则放在片外。此外由于编译和分配空间是以文件为单位的,所以把频繁使用的函数放在同一文件中,再将这个文件放入片内存储器以高效地利用有限的片内资源。同时通过Profiler分析代码调用频率,合理安排代码的存放位置,提高Cache的命中率和数据访问性。为保证数据读取的高效性,在片内开辟乒乓结构的双缓存区。
编码过程中要访问的大量数据都放在片外存储器, 处理时要进行频繁的数据搬移,由于CPU访问片外的速度通常要比访问片内慢10~20倍,片外数据的传输通常成为程序运行时的瓶颈,即使代码效率很高,流水线也会因为等待数据而被严重阻塞,本设计采用EDMA传送数据来有效地解决这一问题。在编码当前宏块的同时,利用EDMA将下一个宏块的数据、用到的参考帧数据由片外传送至片内,当前宏块做完运动补偿后,EDMA将重建后的宏块由片内传送至片外。这样CPU只对片内数据进行操作,流水线可以顺利进行。
3..264视频编码器关键模块的算法优化
H. 264视频编码器的计算量主要集中在运动估计、量化、反量化、DCT与IDCT和去块滤波几个模块,这些模块优化前的运算量占到全部运算量的80%以上。下面给出几个耗时较多的关键模块的优化策略。
3.1.动估计优化
视频编码中,运动估计部分是运算量最大的一块,研究显示,对于H.264,单帧参考,运动估计占总运算量的70%,5帧参考,这个比例能达到90%,因此,采用有效快速的运动估计算法非常有必要,本系统采用基于预测和早停止技术的运动估计算法,主要方法是利用周边邻块对当前块运动矢量进行预测,并设定自适应阈值,使搜索提前停止。采用该算法,在搜索窗为32时,每块平均搜索点数3~4个左右,与全搜索算法的4225余个点相比,速度提高了1000多倍。
计算 SAD是整像素运动估计中计算量最大的部分,TI库函数中提供了一些函数,对于 16×16,16×8,8×8块的搜索可以直接利用库函数。对于 8×16 的块不能直接利用,用线性汇编来实现后,软件流水一次迭代的周期数为 3,与三个汇编库函数的迭代周期数相同。
分像素运动估计中,在每个搜索位置调用Calcu_Subpixel_Residual(),计算出 1/4预测像素值,求预测残差,将预测残差保存在diff[16*16]中, 并将预测值保存。然后调用SATD_block()对diff[16*16]中的残差进行哈达码变换求 SATD,求 SATD是对每个 4×4块进行,之后求和,4×4块之间的计算可以软件流水提高速度。此外,设两个数组来保存最优的预测值,若当前考察的位置代价更小,则通过交换指针使pBestPred指向最优的预测值,避免数据拷贝。
3.2.数反变换的优化
对整数反变换模块进行运算分析,算术运算的比例达到80%,所以优化重点是减少算术操作。一次反变换需要进行128次乘法和96次加法运算。当反变换进行Hadamard变换时,则需要进行256次乘法和192次加法运算。这样即使是QCIF图像,其逆变换也需要进行 50688~101376次乘法和38016~70632次加法运算。由于乘除运算比加减法运算耗时多,所以整数反变换的优化应集中在减少乘法运算次数上。
通过观察变换矩阵可发现,该矩阵只包括±1和±1/2这4种系数,对于乘以±1的系数来说,可将其转换为简单的加减法,而对于乘以±1/2,则可以先进行移位运算然后再进行加减法运算,这样就完全避免了代价昂贵的乘法和除法运算。另外可利用蝶形变换对矩阵相乘再做进一步改进。例如对 5帧不同格式图像比较其优化前后的整数反变换过程,其所要的计算时间如表1所示。由表1可见,经统计优化后的反变换速度能提高21倍左右。

表1.数反变换优化前后时间对比
3. 3 去块滤波的优化
由于H.264中最小块的大小是4×4,所以在每个4×4块中的每个点有相同的边界门限。依据这一点,16个点可以只计算4次边界门限,其相应的滤波操作也可以4次完成。通过这种优化方法可以将去块滤波函数的调用次数降下来。
4.统性能测试
测试在一台P4 3.0GHz,1G内存,操作系统为Windows XP的 PC机上进行。硬件测试平台为基于本文方案研制的DM642编码器板,主频600MHz。对各种不同的CIF格式的视频序列进行编码,统计出优化前后的编码性能如表2所示。

表2.试结果(一路视频输入)
从表2可以看出,在优化前系统不能完成一路视频的实时编码,优化后一路视频的编码帧率达到100fps以上,另从表2实验结果可知,信噪比下降很少。在实时采集和编码四路视频时,即使在视频内容比较复杂的情况下,总编码帧率仍可达到102帧/秒,因此,本文设计的H.264编码器完全能胜任四路CIF格式视频的实时编码,充分利用了DM642可以接受多路不同格式音视频信号和数据处理能力强的优点,降低了系统得成本。
5. 结
在TMS320D642 DSP上实现了四路CIF格式视频的实时H.264软件编码器。给出的程序代码的优化方法,对于所有的C64DSP都具有通用性,提出的关键模块的优化策略,对采用其它视频压缩标准的编码器的优化具有重要的参考和借鉴价值。该H.264视频编码器与网络平台相连接可以应用于多路视频监控、视频会议、可视电话、无线流媒体通信等应用领域。这种在通用DSP上全软件实现的H.264视频编码器,具有功能强、使用灵活、便于升级等特点,有广泛的应用前景。
[1]ITU-T. Recommendation H.264 Advanced video coding for generic audiovisual services[S].2004.
[2]陆璐,周维.适用于H.264的快速模式选择算法[J].通信学报,2006 , 27 (7) : 117-121.
[3]张江鑫,冯明.H. 264快速帧内预测模式选择算法[J].中国图象图形学报, 2008, 13 (10) : 2023-2036.
[4]刘佳,董金明.一种新的 H.264/AVC快速帧内预测模式选择判决算法[J].电子与信息学报,2009, 31 (5) : 1072~1076.
[5]余成伟,陆建华,郑君里.H.264 编码模式选择快速算法研究[J].清华大学学报, 2007, 47(10) : 1677-1680.
[6]Texas Instruments Incorporated. TMS320DM642 Hardware Designer’s Resource Guide[R]. Texas Incorporated 2004.
猜你喜欢
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26 14:09:30
数学小灵通(1-2年级)(2020年6期)2020-06-24 05:57:54
动漫星空(2018年11期)2018-10-26 02:24:02
动漫星空(2018年2期)2018-10-26 02:11:00
动漫星空(2018年9期)2018-10-26 01:16:48
动漫星空(2018年5期)2018-10-26 01:15:02
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
中学生数理化·八年级数学人教版(2017年2期)2017-03-25 16:12:51
电子设计工程(2017年20期)2017-02-10 03:39:29
中学生数理化·七年级数学人教版(2016年9期)2016-12-07 08:18:09
