
基于模糊分类的炭素制品X射线图像的缺陷识别研究*
2010-10-18 14:32叶邦彦刘晓楠
制造技术与机床 2010年12期
叶邦彦 刘晓楠
(华南理工大学大学机械与汽车工程学院,广东广州510640)
随着生产技术的发展,现代工业对于产品的自动检测与识别技术的需求越来越迫切.炭素制品如石墨电极、电刷等,往往需要进行X射线检测,而要实现X射线图像的自动检测与识别,关键在于如何将所获图像中反映缺陷性质的信息(特征)从图像中提取出来,并给予正确的分类[1-2]。由于炭素制品具有局部疏松、孔隙较多、密度不均等结构特点,并且在X射线成像过程中受到随机噪声的干扰,造成成像质量相对较低,给材料内部缺陷检测的识别带来了一定的困难。在炭素制品X射线图像中包含大量与缺陷性质相关的特征,因此根据提取到的特征参数进行分类目前尚属探索阶段[1-2]。有学者使用神经网络对缺陷进行分类[4],但分类效果不是十分理想。
本文以炭素制品内部缺陷为对象,根据从其X射线图像中优化提取的3个特征量[5],通过引入模糊数学,建立一个模糊的数学模型,对缺陷使用模糊算法进行分类。实验和仿真结果表明,这一方法可获得比较理想的效果。
1 炭素制品X图像缺陷类型
不同的原材料种类和生产工艺产生的炭素制品,其缺陷类型往往不同。通过对不同炭素制品在压型、焙烧和石墨化等生产工艺中产生的缺陷进行分析,归纳出三种常见的缺陷类型[4-5],分别为气孔、裂纹、夹渣,其典型的X图像如图1所示。

2 炭素制品X图像缺陷特征提取、参数提取和优化
炭素制品的X图像缺陷识别的流程如图2所示。
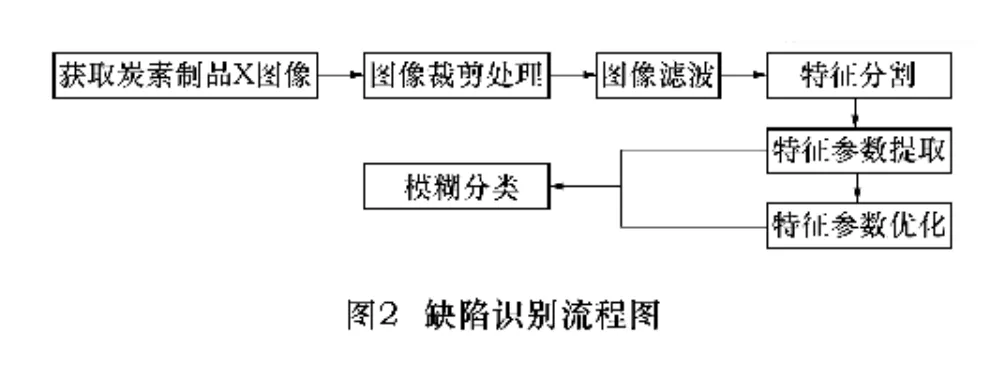
拍摄到炭素制品的X图像后,往往因为拍摄条件和环境的影响,使图像质量下降,经过图像裁剪和滤波后,图像中的有价值部分得到保留,进而从图像中提取缺陷特征[3]和对缺陷特征进行参数提取。
由于提取到的参数很多,目前有学者使用遗传算法对特征参数进行优化[4],将庞大的原始特征缩减为3个,分别为收缩率Compactness、扁度E和最小灰度值ROImin。本文将它们作为模糊分类器的输入。
3 模糊分类
3.1 建立数学模型
分类是一种多元分析方法。由于事物本身在很多情况下都带有模糊(Fuzzy)性,因此把模糊数学引入聚类分析,就会使分类更加切合实际。炭素制品X图像缺陷分类中,一般把样本的缺陷分为裂纹、气孔、夹渣三类[4],基于此,若要确定样本的类别,按照聚类基本法则,只要分析计算样本同各类别的相似程度,取最亲近的一类作为结果即可。基于此建立分类数学模型如下:
(1)设待分类的样本为:
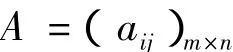
aij代表第i个样本中第j个参数的值,其中0≤aij≤1,m为样本数,n为缺陷类型。要求相似的样本分为一类,根据经验,把所有样本分为三类即可。
(2)通过样本的部分数据在模糊空间的分布规律,根据已经人工分好类的样本得到分类的标准参数(聚类中心点)B=(b1,b2,b3)T。
若样本 a1,a2,…,ak属于裂纹,ak+1,ak+2,…,ak+l,属于气孔,剩下的 ak+l+1,ak+l+2,…,am属于夹渣,则应使B满足各聚类样本到各聚类中心加权距离之和最小,即:
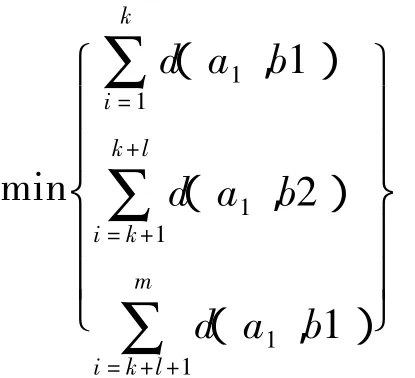
其中 d(a,b)为 a 和 b的欧式距离
(3)分别计算A中各样本同三个类型的相似度R=(rij)m×3(i,j=1,2,…,n,rij为样本i同样本j的相似关系)。计算相似度R的方法很多,如欧式距离法、夹角余弦法,公式如下:
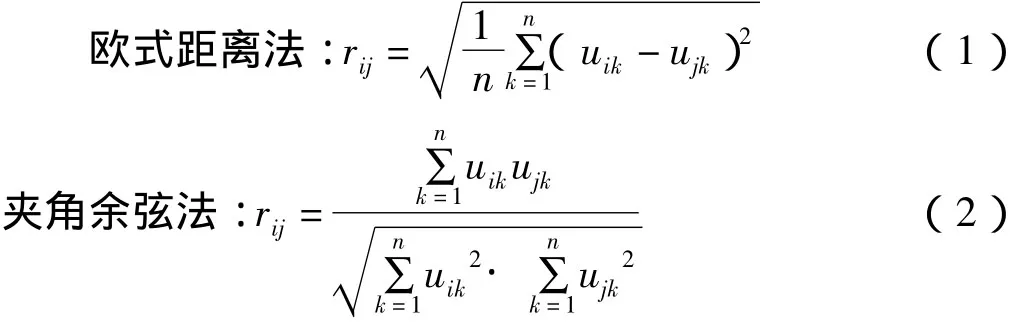
式中:uik为第i个点的第k个因子(参数)的值;ujk为第j个点第k个因子(参数)的值。
(4)根据距离标定、夹角标定的数据,计算出A中各样本中属于三种缺陷类型的隶属度U(其中0≤uij≤1)。隶属度函数选取正态分布型:
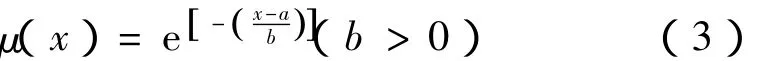
(5)根据分类决策原则对隶属度U进行分类,得到分类结果。一般按照隶属度最大的进行分类,即样本对哪类的隶属度大,样本就属于哪一类。
3.2 算法设计
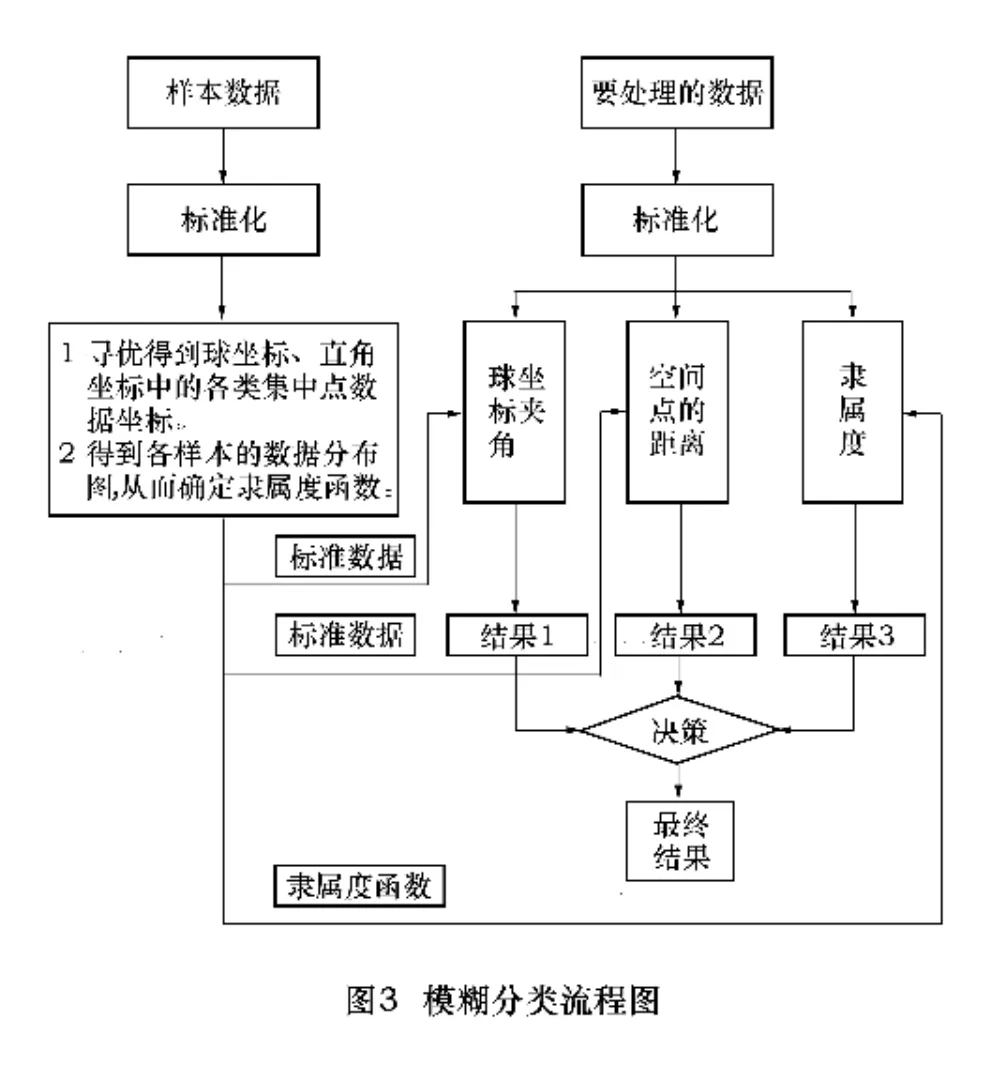
综合分析建立的数学模型,分类算法流程如图3所示。
其中分类算法主要包括4个过程[6]:(1)数据标准化;(2)标定;(3)确定隶属度;(4)决策分类。
3.3 使用MATLAB设计分类器
(1)数据的标准化
经过遗传算法优化后的参数同前文的数学模型还有些差距,其在空间分布的尺度大,且同类参数在不同样本间的数量级相差很大,为把优化的参数划归到区间[0,1],对样本数据进行标准化处理,其方法如下:

式中:ui为原始样本;xi为标准化后样本,同时为保证标准化后数据分布到[0,1],c1取 min(ui),c2取 max(ui)-min( ui)。
将原始数据标准化后的数据如表1。
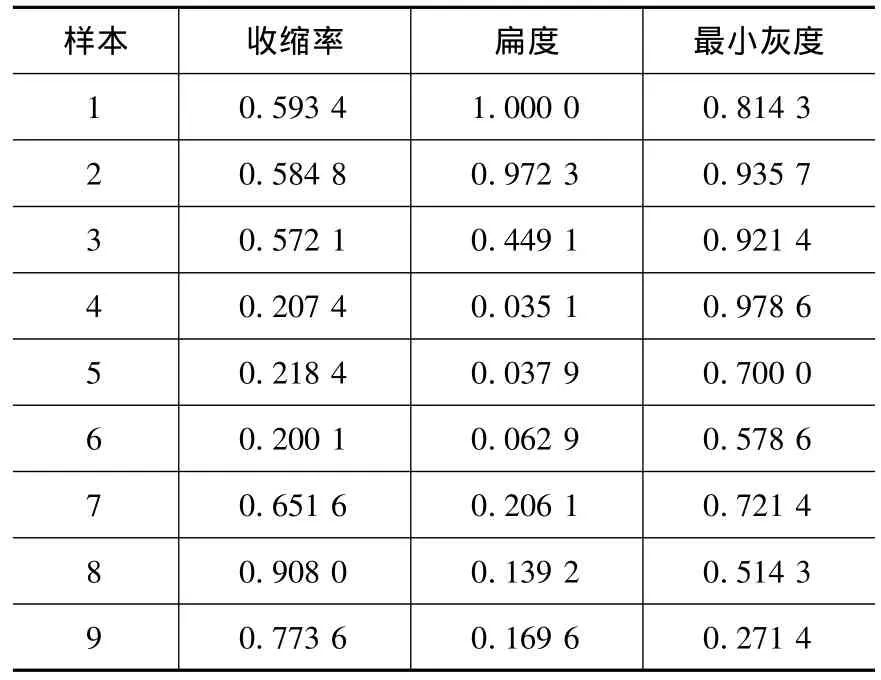
表1 标准化后的数据
(2)标定数据
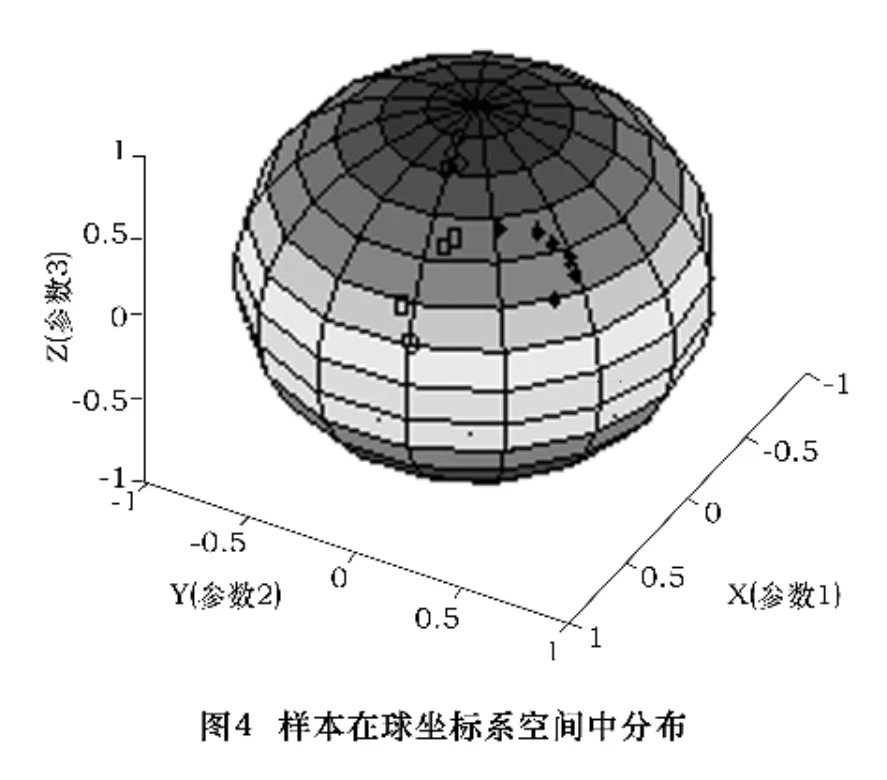
优化后的3个参数可以作为模糊空间的一个点进行处理,把标准化的数据在球坐标系中表示,如图4所示。
可以看出,同类样本基本聚集在一个特定区域。所以可以通过寻找各类样本在空间区域的聚类中心点(标准点),根据各样本点到各个标准点的距离远近或夹角大小确定各样本对三个缺陷类别的隶属度,作为分类的依据。以距离法为例,待求标准点满足以下原则:要求标准点到同类样本各点的距离之和最小。
求标准点的流程图如图5,其中PD代表的是距离远近。
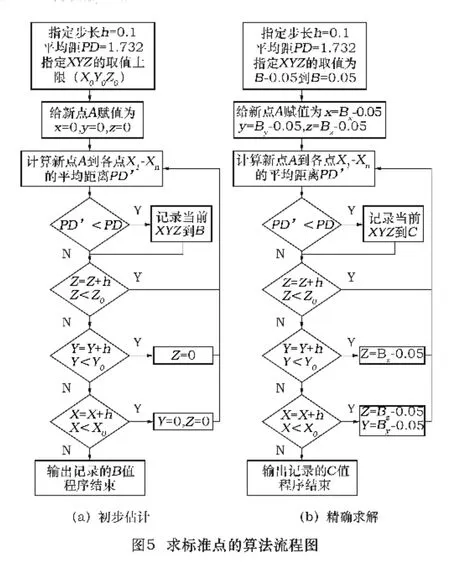
根据图5的算法,在MATLAB中近似求出各缺陷类型的标准点数据如表2。
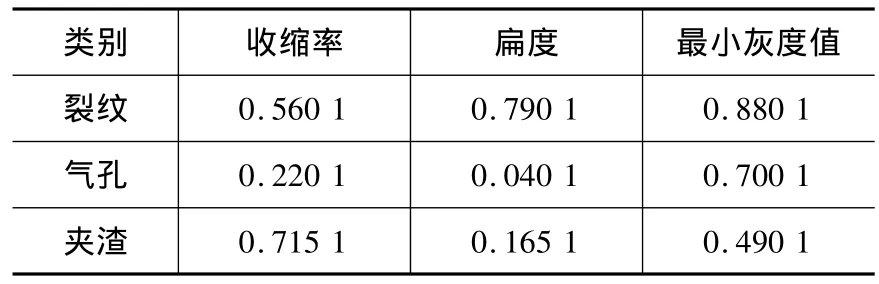
表2 直角坐标系下的各缺陷类型的标准点
根据标准化后的数据(表1)和标准点数据(表2)可以对样本进行标定,从而确定各样本属于各类别的隶属度。各样本到标准点的距离如表3。
(3)确定隶属度
使用距离法来确定隶属度,距离越近,隶属度越高;距离越远,隶属度越低。由于自然界中离散的事物大多呈正态分布,所以隶属度函数采用公式(3),其中a的取值由表2确定,b的取值由数据标准化后的统计标准差确定。确定隶属度程序流程如图6。
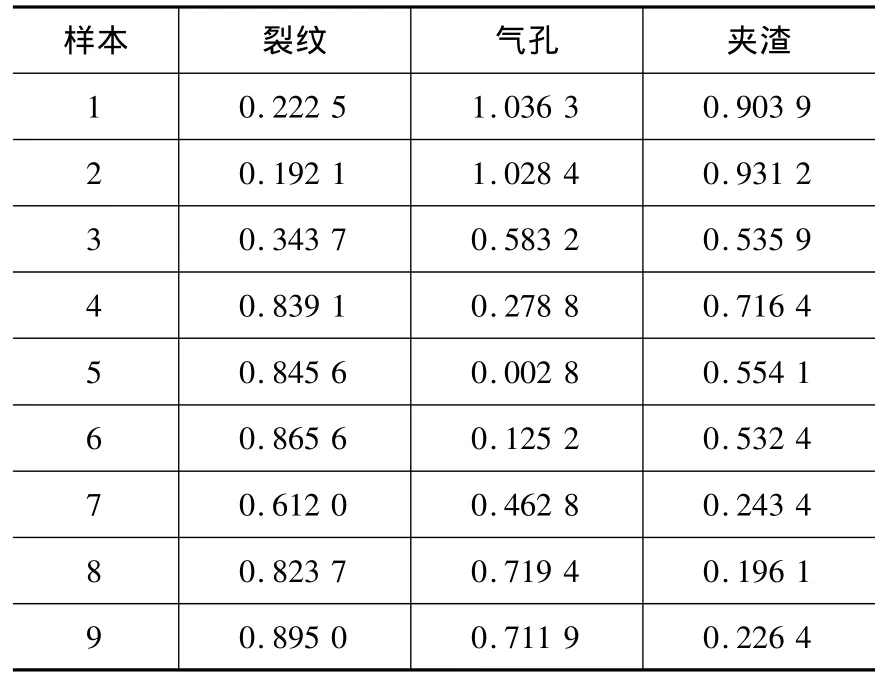
表3 各样本到各标准点的距离
根据标定的数据,代入式(3)求出各样本属于各类的隶属度,如表4。
(4)模糊决策
根据隶属度的大小判断样本的分类,一般按照隶属度最大的进行分类,即样本对哪类的隶属度大,样本就属于哪一类。由表4的隶属度可以看出,样本1-9被分开了,按照隶属最大的原则,可以确定样本1-3是裂纹,样本4-6是气孔,样本7-9是夹渣。把分类的结果同人工分类的结果进行比较,证实同人工分类的结果吻合。本文设计了一个决策规则库,用来对样本进行分类决策,最终决策的流程如图7。
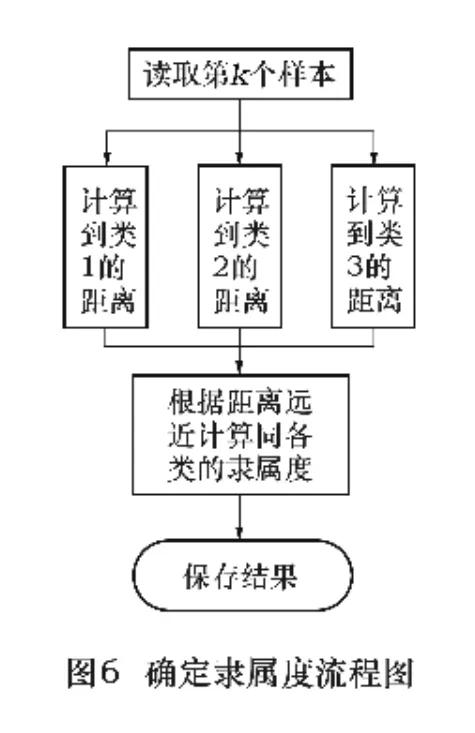
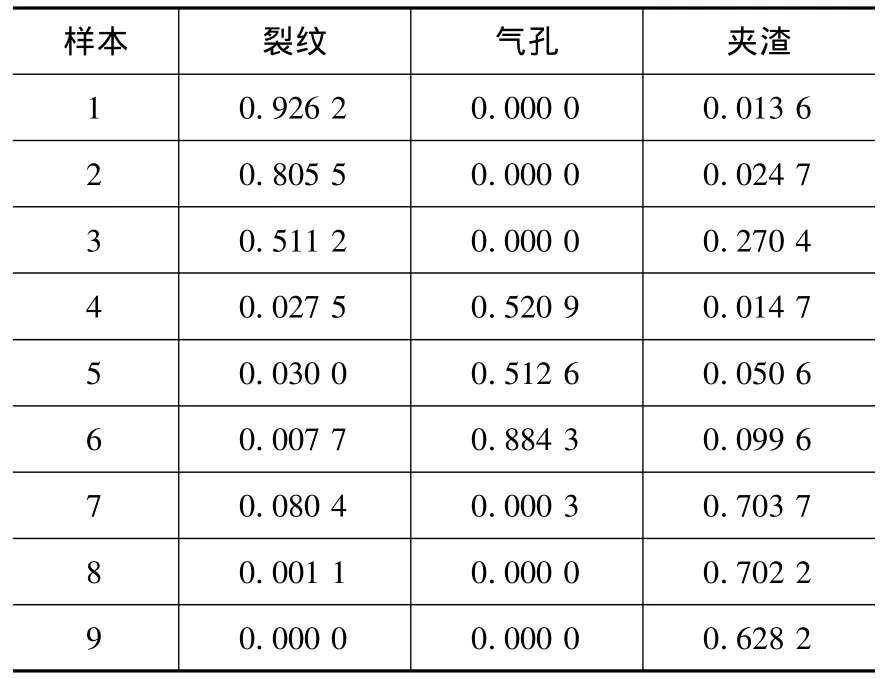
表4 使用距离法标定的隶属度
在MATLAB中编写程序进行仿真,同时使用噪声干扰,其结果准确率统计如表5所示。
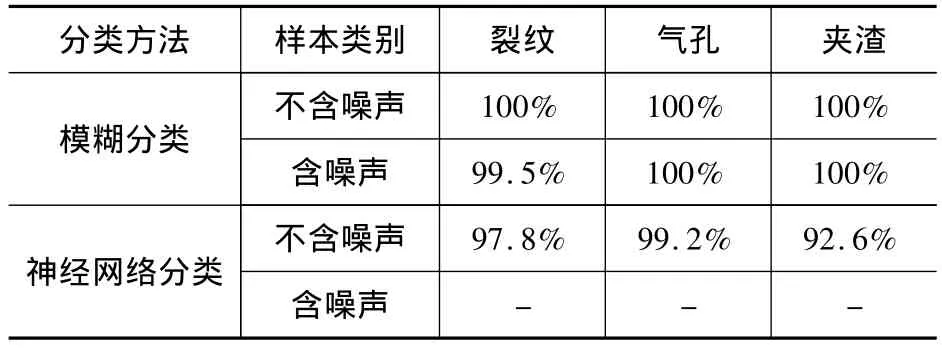
表5 MATLAB仿真准确率统计
3.4 仿真结果分析
仿真结果表明,本文探讨的模糊分类方法对缺陷识别的正确率很高,这表明本文的模糊分类算法对炭素制品X图像缺陷的适应性较好。同神经网络的分类结果相比,不仅模糊分类算法对于不含噪声的样本在识别正确率上高于神经网络分类结果,而且对于含噪声的样本的分类正确率也很高。由此可见,使用模糊分类正确识别图像缺陷效果很好,且对噪声等有很强的适应性。
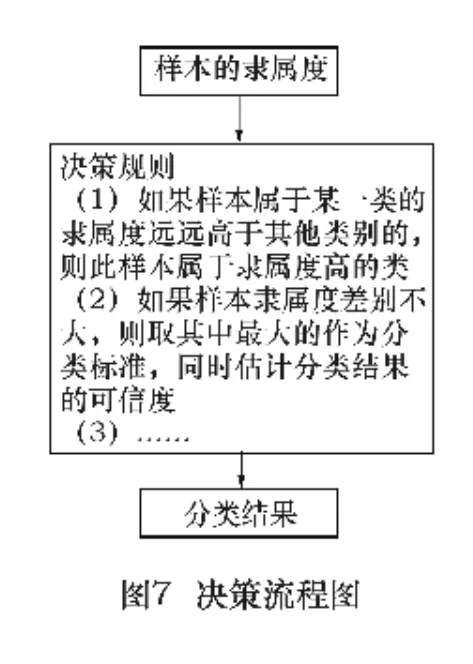
4 结语
本文讨论了使用模糊分类方法对优化后的缺陷特征参数进行分类的方法。在模糊分类中,使用自适应的标准化算法对优化后的参数进行归一化处理,然后对样本进行标定,进而求出样本同标准类型的相似程度,最后使用专家决策系统进行分类辨识。通过MATLAB进行仿真,结果表明,本文的算法具有以下几个优点:
(1)可以根据样本的增加自主学习、调整;
(2)模糊分类算法同神经网络分类比较,具有不用训练、直接使用的的优点,同时分类速度也大大地提高;
(3)模糊分类算法更加接近人的思维,而且容易得到准确的分类。
[1]刚铁,王东华.基于自适应形态学滤波的X射线图像的缺陷提取[J].机械工程学报,2001,37(5):85-89.
[2]刚铁,吴林.焊接缺陷的超声回波特征分析与模式识别[J].哈尔滨工业大学学报,1997,29(2):15-17.
[3]周贤,刘义伦,李学军.炭素材料X射线图像的缺陷的自动提取与分割[J].计算机应用,2006,26(5):1214-1216.
[4]周贤.阴极炭块内部缺陷的X射线自动检测与识别研究[D].长沙:中南大学机电工程学院,2006.
[5]周贤,唐琴,赵先琼.炭素制品X射线图像的缺陷特征分析与选择[J].无损检测,2006,28(10):505-507.
[6]李士勇.工程模糊数学及应用[M].哈尔滨:哈尔滨工业大学出版社,2007.
猜你喜欢
机电安全(2022年5期)2022-12-13
一重技术(2021年5期)2022-01-18
有色金属设计(2021年4期)2022-01-09
食品安全导刊(2021年21期)2021-08-30
科学(2020年1期)2020-01-06
人大建设(2019年6期)2019-10-08
中成药(2017年6期)2017-06-13
中国卫生(2015年12期)2015-11-10
中国卫生(2015年10期)2015-11-10
中成药(2014年7期)2014-02-28
