
基于相关向量机的高光谱影像分类研究
2010-09-07 03:39杨国鹏余旭初张鹏强
测绘学报 2010年6期
杨国鹏,余旭初,周 欣,张鹏强
1.信息工程大学测绘学院,河南郑州450052;2;空军装备研究院,北京100850;3.信息工程大学信息工程学院,河南郑州450052
基于相关向量机的高光谱影像分类研究
杨国鹏1,2,余旭初1,周 欣3,张鹏强1
1.信息工程大学测绘学院,河南郑州450052;2;空军装备研究院,北京100850;3.信息工程大学信息工程学院,河南郑州450052
从分析支持向量机用于高光谱影像分类时存在的不足出发,提出一种基于相关向量机的高光谱影像分类方法。在介绍稀疏贝叶斯分类模型的基础上,将相关向量机学习转化为最大化边缘似然函数参数估计问题,并采用快速序列稀疏贝叶斯学习算法。通过PHI和OMIS影像分类试验分析表明基于相关向量机的高光谱影像分类方法的优势。
高光谱影像;稀疏贝叶斯模型;相关向量机;支持向量机
1 引 言
高光谱影像具有丰富的地物光谱信息,较之全色、多光谱影像在地物识别方面具有巨大的优势。它记录的波长范围更宽,从可见光延伸到短波红外,甚至到中红外和热红外。它的光谱分辨率高、能够获取地物精细的光谱曲线,可以根据需要选择或提取特定的波段来突出目标特征。利用高光谱遥感技术,还能够很好地提取目标的辐射特性参量,使地表目标的定量分析成为可能。高光谱遥感已经成为植被调查、海洋遥感、农业遥感、环境监测、军事情报获取等领域新的重要技术手段[1]。
高光谱遥感成像机理复杂,成像光谱仪定标、大气辐射校正、地物光谱重建等预处理技术尚未完善。地物光谱曲线的近乎连续,也导致高光谱影像数据量大、波段相关性强、数据冗余严重。在不同季节、不同时刻、不同环境下,同类地物的光谱曲线也会有所不同。高光谱影像分类识别要解决是高维特征空间海量数据的非线性可分问题。因此,高光谱影像给地物精细分类识别带来了巨大机遇,也给传统影像分类方法带来了挑战。
高光谱影像地物识别有一类研究方法是基于对光谱曲线的分析。基于地物光谱库的光谱匹配分类方法原理直观、计算简单,但前提是必须对高光谱影像进行准确的地物光谱重建,否则将会严重影响地物分类的精度。由于高光谱影像的空间分辨率较低,混合像元大量存在,混合像元分解中端元光谱的选择、解混模型的建立和求解都是有待解决的问题。
高光谱影像地物识别另一类研究方法是进行模式分类。传统统计模式识别方法,例如贝叶斯分类、神经网络等,大多是基于经典统计理论的大数定理,泛化能力需要以样本数量趋近无穷大来描述,对于有限训练样本集的高光谱影像分类时,会遇到“维数灾难”现象。目前,高光谱影像降维通常采用线性特征提取方法,这也可能会降低样本的可分性。
目前,许多学者对基于支持向量机(support vector machine,SVM)的高光谱影像分类进行了研究。Gualtieri在1998年首次将SVM用于高光谱影像分类试验后指出,这种方法能有效地避免Hughes现象。夏建涛[2]对SVM的高光谱影像分类性能做了详细试验,指出核函数参数和样本数量对SVM的分类性能影响较大。
SVM基于统计学习理论的结构风险最小化原则,通过最小化经验风险和置信范围提高算法的泛化能力[3]。SVM的数学模型表示为

核函数 K(x,xi)是定义在训练样本点的基函数。
SVM能够有效避免过学习现象,具有良好的泛化能力,但它存在着明显的不足,主要表现在:①基函数个数基本上随训练样本集规模成线性增长,模型稀疏性有限;②预测结果不具有统计意义,无法获取预测结果的不确定性;③核函数参数和规则化系数需要通过交叉验证等方法确定,增加了模型训练的计算量;④核函数必须满足Mercer条件。
核方法在SVM中得到成功应用以后,人们开始利用核函数将经典的线性分析方法推广到一般情况的研究,成为继经典统计线性分析、神经网络与决策树非线性分析之后的第三次模式分析方法的变革[4]。支持向量机、稀疏核主成份分析等也引起了人们研究“稀疏”学习模型的兴趣。
稀疏学习模型具有的一般形式为

它是相对于权值向量w=(w1,…,wM)T的线性模型,y(x)能够逼近实变量函数或判别函数。假定存在训练样本集{xn,tn},稀疏模型是通过将权值向量w的多数元素设置为零,来控制模型复杂度,从而避免过学习现象,减小模型预测的计算量。
2000年,Tipping提出一种与 SVM相似的稀疏概率模型来弥补SVM的不足,被称为相关向量机(relevance vector machines,RVM)[5]。 2003年,Tipping设计了快速序列稀疏贝叶斯学习算法,提高了模型训练速度[6];2005年,Thayananthan将该模型推广,解决了多元输出回归和多类分类的训练问题[7]。RVM最初用以处理回归问题,通过Laplace逼近可以将分类问题转化为回归问题。目前,已经开展了RVM在文本识别、影像分类、时序分析等应用领域的研究[8-10]。
本文在介绍稀疏贝叶斯分类模型的基础上,通过参数推断将RVM学习可以转化为最大化边缘似然函数估计问题,并选用快速序列稀疏贝叶斯学习算法实现。本文通过一系列的两类RVM分类器组合解决多类RVM分类问题,将其应用于高光谱影像分类。通过PHI和OMIS影像分类试验,表明了基于RVM的高光谱影像分类方法的优势。
2 稀疏贝叶斯分类模型
2.1 模型描述
对于两类稀疏贝叶斯分类问题[11],假定训练样本集为{xn,tn}Nn=1,其中 xn∈d为训练样本向量,tn∈{0,1}为训练样本标号,分类预测模型要将非线性基函数的线性组合通过 S形函数映射到区间(0,1)内进行类别判定,即

其中,φ(x)=[φ(x1),φ(x2),…,φ(xΜ)]T为样本基函数映射组成的列向量;φi(x)(i=1,…,N)是定义在训练样本点上的核函数,即φi(x)=K(x, xi)。由于这里不要求 φi(x)为正定的,因此没有必要满足 Mercer条件。这里的 w=(w0,…, wN)T为所有基函数的权值组成的列向量,采用 S形函数的数学表达式为

对于两类分类问题,如果假设样本独立同分布的,那么训练样本集的似然函数可以表示为[5]

这里,t=(t1,…,tN)T为训练样本的目标向量。
根据概率统计原理,假设参数wi服从均值为0、方差为的高斯条件概率分布,因此

其中,α是决定权值w的先验分布的超参数。
这样为每一个权值(或基函数)配置独立的超参数是稀疏贝叶斯模型的最显著的特点,这也是导致模型具有稀疏性的根本原因[12]。由于这种先验概率分布是一种自动相关判定先验分布,模型训练结束后,非零权值的基函数所对应的样本向量被称为相关向量,因此称这种学习机为相关向量机。
根据贝叶斯理论,如果已知模型参数的先验概率分布 p(w,α),那么模型参数的后验概率为

若获取了模型参数的后验分布 p(w,α|t),那么对于待测样本为x*,稀疏贝叶斯模型的预测值z*的分布为

因为无法直接积分获取 p(z*|t),需要通过参数推断获取预测值z*。RVM判别准则为:如果 y*=σ(z*)<0.5,则 t*=0;如果 y*=σ(z*)> 0.5,则t*=1。
2.2 参数推断
由于模型参数的后验分布 p(w,α|t)不能通过积分直接获取,故将其分解为

根据贝叶斯公式,p(α|t)∝p(t|α)p(α)。由于模型参数的后验概率分布 p(w|t,α)和边缘似然函数 p(t|α)都无法积分求解,需要采用Mac-Kay提出的Laplace逼近方法近似[13],具体步骤描述如下:首先初始化超参数向量α;对于给定的向量α,建立后验概率分布的高斯近似,从而获取边缘似然函数的近似分布;通过最大化边缘似然函数来重新估计向量α;重复这个过程直到收敛[12]。
利用高斯正态分布来逼近后验概率分布的Laplace方法,是对后验概率分布的众数位置处函数的二次逼近。对于给定的向量α,由于

那么,关于w的高斯后验分布的众数通过最大化公式(3)得到

其中,yn=σ{y(xn;w)},A=diag(ai)。
通过迭代再加权最小二乘法求解,迭代收敛后,得到以众数位置为中心的后验概率分布的近似高斯分布,其均值为wMP=A-1ΦT(t-y),方差为Σ=(ΦTBΦ+A)-1。这里B=diag(β1,β2,…, βn),βn由式(4)计算得到
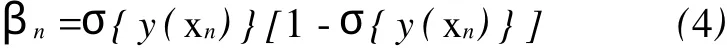
得到近似后验概率分布后,同样使用Laplace逼近方法可以将边缘似然函数 p(t|α)近似表示为

如果令^t=ΦwMP+B-1(t-y),则近似高斯后验分布的均值wMP=Σ ΦTB^t、方差Σ=(ΦTBΦ+ A)-1。近似的边缘似然函数对数为

其中,C=B+ΦA-1ΦT。
通过比较稀疏贝叶斯的分类和回归模型的参数推断过程可知,利用Laplace逼近方法可以将分类问题转化为回归问题[6],相应回归问题的目标向量^t=ΦwMP+B-1(t-y)。稀疏贝叶斯分类模型学习,最终都归结为第Ⅱ类型最大似然参数估计问题。
2.3 多类分类器
上面研究的是二值分类问题的稀疏贝叶斯分类模型。在多类别分类情况下,假设共存在 K个类别(K>2),随机样本服从独立同分布的多项式分布,此时最大似然函数可以表示为[14]

这里采用 K目标编码方法,分类器共有 K个输出yk(xn;w),每个输出都有独自的参数向量wk和超参数αk。
由于这种多类问题整体求解时,计算量非常大。与SVM多类分类相似,可以将多类分类问题分解成一系列二类问题进行求解,例如一对余法 (one against rest,OAR)、一对一法 (one against one,OAO)等多类分类器构造方式[1]。
3 相关向量机学习算法
通过以上分析,RVM学习最终归结为第Ⅱ类型最大似然参数估计问题。通过最大化边缘似然函数 p(t|α)来估计α,通常采用以下三种方法[7]:MacKay迭代估计、期望最大化迭代估计、自下而上的基函数选择算法。
最大边缘似然估计超参数过程中,超参数更新需要计算后验权值的协方差矩阵,矩阵求逆需要计算复杂度为O(M3)和存储空间为O(M2)[11],M为基函数的个数。本论文采用自下而上的基函数选择方法中,基函数个数从1开始不断增加直至获取相关向量,而且Φ与Σ只包含当前模型中存在的基函数。
2.4 算法原理
自下而上的基函数选择是 Tipping于2003年提出的快速序列稀疏贝叶斯学习算法[6]。由于边缘似然函数的对数L(α)与单个超参数αi的相关性,i∈{1,…,M},将式(5)中的C分解为
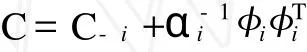
其中,C-i是C去除第i个基函数影响后的矩阵,满足

边缘似然函数的对数L(α)可以表示为

其中,

目标函数L(α)可分解为去除基函数φi后的边缘似然函数L(α-i)与关于αi的独立表达式l(αi)。这里的 si=Cφi,qi=Ct。稀疏因子si用于度量基函数φi与模型中剩余所有基函数的重叠程度;质量因子qi用于度量去除基函数φi后对模型误差的校正。
通过分析l(αi)表明,L(α)关于αi存在唯一最大值。当>si时,αi=/(-si);当 如果假设 Si=C-1φi和Qi=C-1t,则有si=αiSi/(αi-Si),qi=αiQi/(αi-Si)。当αi=∞时,si=Si且qi=Qi。 实际学习过程中,利用Woodbury恒等式获取 Si和Qi非常方便[6],有 针对稀疏贝叶斯分类,B=diag(β1,β2,…, βn),^t=ΦwMP+B-1(t-y)。 序列稀疏贝叶斯学习算法流程可以描述为[12] 1.初始化选择1个基函数φ1,并估计相应权值w1。 2.设置基函数φ1的超参数α1为合理数值,使其他所有超参数αj为无穷大,即模型中只有基函数φ1。 3.利用式(4)计算B。 4.计算均值μ和方差Σ,同时计算出所有基函数对应的qi和si。 5.选择候选的基函数φi。 9.如果收敛,算法结束;否则,执行步骤3—9。 已有文献表明,基于SVM的高光谱影像分类具有良好的泛化能力,其分类精度较高。论文进行了基于RVM和SVM的高光谱影像分类试验,并对分类结果进行了比较分析。 由于SVM要求核函数满足Mercer条件,为便于比较,RVM与SVM都采用高斯径向基核函数,其表达式为 k(x,x′)=exp(-‖x-x′‖2/ σ2),其中σ2为核函数参数,它控制了核函数宽度。为了便于设置σ2数值,试验中将高光谱影像的每个波段特征DN值规范化到[0,1]范围内。 由于SVM模型含有规则化系数,在分类时需要设置,在试验中通过交叉验证网格搜索法来获取[1]。SVM学习过程采用序列最小优化算法,利用统计模式识别工具箱STPRtool实现[15]。 本试验采用的计算机硬件环境为Intel Core2 CPU 3.0 GHz、2.99 GHz内存3.25 GB,软件环境为Microsoft Windows XP、MATLAB 7.5。 试验数据:由中科院上海技术物理研究所研制的PHI成像光谱仪1999年9月获取的江苏省常州市影像,光谱覆盖范围为0.42~0.85μm,共80波段,图像大小为346×512,数据经过反射率转换。训练样本分布如图1所示,样本信息情况如表1所示。 图1 试验区PHI影像样本分布Fig.1 Samples distribution of PHI imagery 表1 试验区PHI影像样本信息Tab.1 Samples information of the PHI imagery 将各类样本按数量随机等分成两部分作为训练样本和测试样本。选择不同 Gauss核函数参数σ,该PHI影像RVM分类结果比较如表2所示,基函数数量为该多类分类器中所有二值分类器使用基函数个数之和。 表2 试验区PHI影像RVM分类比较T ab.2 RVM classification comparison of the PHI imagery 通过SVM进行分类时,规则化系数C需要通过交叉验证获取,该影像OAO-SVM分类的交叉验证精度如图2所示,选取规则化系数 C= 2.0。不同Gauss核函数参数σ时,该影像SVM分类结果比较如表3所示。 图2 试验区PHI影像OAO-SVM分类交叉验证精度/(%)Fig.2 Cross-validation error rate of the PHI imagery OAO-SVM classification/(%) 表3 试验区PHI影像SVM分类比较T ab.3 SVM classification comparison of the PHI imagery 试验数据,采用中科院上海技术物理研究所研制的OMIS成像光谱仪获取的江苏太湖沿岸的影像,光谱覆盖范围0.46~12.85μm共128波段,影像大小347×513,试验中使用受噪声影响比较小的6~64、113~128共75个波段。通过对影像目视判读,训练样本分布如图3所示,样本信息情况如表4所示。 表4 试验区OMIS数据样本信息Tab.4 Samples information of the OMIS imagery 将各类样本按数量随机等分成两部分作为训练样本和测试样本。选择不同Gauss核函数参数σ,该OMIS影像RVM分类结果比较如表5所示。 图3 试验区OMIS影像样本分布Fig.3 Samples distribution of the PHI imagery 表5 试验区OMIS影像RVM分类比较T ab.5 RVM classification comparison of the OMIS imagery 通过SVM进行分类时,通过交叉验证获取选择规则化系数C=2.0时。选择不同 Gauss核函数参数σ,该OMIS影像SVM分类结果比较如表6所示。 表6 试验区OMIS影像SVM分类比较T ab.6 SVM classification comparison of the OMIS imagery 通过PHI和OMIS影像的RVM、SVM分类试验,论文得出以下结论: 1.在RVM模型中不存在规则化系数C,不需要交叉验证获取规则化系数的步骤,因此RVM与SVM相比受分类器参数选择的影响要小。 2.对于不同的多类分类器构造方法,包括一对一法和一对余法,RVM分类精度与SVM分类精度都相当,RVM的训练速度更快。 3.由于RVM模型更加稀疏,RVM分类器所用核函数个数是SVM所用核函数个数的1/10~1/5。因为RVM与SVM都是通过核函数的线性组合来进行分类预测的,所以RVM分类速度比SVM分类速度快得多。 4.无论是RVM,还是SVM,在训练过程中,一对一多类构造方法的训练速度都要比一对余法训练速度要更快。 RVM是按照SVM模型的形式,在贝叶斯框架下提出的具有稀疏概率模型的学习机。在RVM求解过程中,核函数不必要满足Mercer条件。在RVM模型中,不需要通过交叉验证获取规则化系数。 通过PHI和OMIS影像分类试验表明,RVM具有良好的泛化能力,受分类器参数选择的影响较小。当SVM选择合适的规则化系数时,SVM与RVM的分类精度相当。 RVM采用快速序列学习算法时,训练过程要比序列最小优化的SVM速度要快。在RVM训练完成后,只有少数基函数的权值非零,比SVM更加稀疏,分类预测过程所用时间更短。 由于RVM的核函数不必要满足Mercer条件,本文为方便与SVM进行比较,只进行了RBF核函数的试验研究。不同核函数的高光谱影像RVM分类性能将是下一步研究的重点。 [1] YANG Guopeng.Hyperspectral Image Classification and Feature Extraction Based on Kernel Methods[D].Zhengzhou: Information Engineering University.2007.(杨国鹏.基于核方法的高光谱影像分类与特征提取[D].郑州:信息工程大学,2007.) [2] XIA Jiantao.High Dimensional Multispectral Data Classification Based on Machine Learning[D].Xi’an:Northwestern Polytechnical University,2002.(夏建涛.基于机器学习的高维多光谱数据分类[D].西安:西北工业大学,2002.) [3] VAPNIK V N.The Nature of Statistical Learning Theory[M]. New York:Springer,1995. [4] SHAWE-TSYLOR J,CRISTIANINI N.Kernel Methods for Pattern Analysis[M].London:Cambridge University Press, 2004:47-82. [5] BISHOP C M,TIPPING M E.Variational Relevance Vector Machines[C]∥Proceedings of the 16th Conference on Uncertainty in Artificial Intelligence.San Francisco:Morgan Kaufmann,2000:46-53. [6] TIPPINGM E,FAUL A.Fast Marginal Likelihood Maximization for Sparse Bayesian Models[C]∥Proceedings of Ninth International Workshop on Artificial Intelligence and Statistics. Key West:[s.n.],2003. [7] THAYANANTHAN A.Template-based Pose Estimation and Tracking of 3D Hand Motion[D].Cambridge:University of Cambridge,2005. [8] SILVA C,RIBEIRO B.Scaling Text Classification with Relevance Vector Machines[C]∥IEEE International Conference on Systems,Man and Cybernetics. Taipei: IEEE,2006: 4186-4191. [9] DEMIR B,ERTURK S.Hyperspectral Image Classification Using Relevance Vector Machines[J].IEEE Geoscience and Remote Sensing Letters,2007,4(4):586-590. [10] NIKOLAEV N,TINO P.Sequential Relevance Vector Machine Learning from Time Series[C]∥Proceedings of 2005 IEEE InternationalJoint Conference on Neural Networks.[S.l.]:IEEE,2005:1308-1313. [11] TIPPING M E.Sparse Bayesian Learning and the Relevance Vector Machine[J].Journal of Machine Learning Research, 2001,1:211-244. [12] BISHOP C M.Pattern Recognition and Machine Learning [M].Singapore:Springer,2007. [13] MACKAYDJ C.The Evidence Framework Applied to Classification Networks[J].Neural Computation,1992,4(5):720-736. [14] THAYANANTHAN A.Relevance Vector Machine Based Mixture of Experts[R].Cambridge:Department of Engineering,University of Cambridge,2005. [15] FRANC V,HLAVAC V.Statistical Pattern Recognition Toolbox for Matlab User’s Guide[DB/OL].[2004]. http:∥cmp.felk.cvut.cz/cmp/cmp software.html. (责任编辑:丛树平) Research on Relevance Vector Machine for Hyperspectral Imagery Classification Y ANG Guopeng1,2,YU Xuchu1,ZHOU Xin3,ZHANG Pengqiang1 Though the support vector machine has been successfully applied in hyperspectral imagery classification, it has also several limitations.Relevance vector machine(RVM)is a sparse model in the Bayesian framework,its mathematics model doesn’t have regularization coefficient and its kernel functions don’t need to satisfy Mercer’s condition.RVM presents the good generalization performance,and its predictions are probabilistic.In this paper, we firstly analysis the disadvantages of the support vector machine for hyperspectral imagery classification,and then a hyperspectral imagery classification method based on the relevance machine is brought forward.We introduce the sparse Bayesian classification model,regard the RVM learning as the maximization of marginal likelihood, and select the fast sequential sparse Bayesian learning algorithm.Through the experiments of PHI and OMIS imageries,the advantages of the relevance machine used in hyperspectral imagery classification are given out. hyperspectral imagery;sparse Bayesian model;relevance vector machine;support vector machine YANG Guopeng(1982—),male,PhD candidate,majors in pattern reorganization and hyperspectral imagery remote sensing. E-mail:yangguopeng@hotmail.com 1001-1595(2010)06-0572-07 P237 A 国家863计划(2006AA701309) 2009-07-17 2009-09-17 杨国鹏(1982—),男,博士生,主要从事模式识别、高光谱遥感。
2.5 快速序列稀疏贝叶斯学习算法
4 高光谱影像分类试验
4.1 试验一





4.2 试验二




4.3 试验分析
5 总 结
1.Institute of Surveying and Mapping,Information Engineering University,Zhengzhou 450052,China;2.Intelligence Institute of Airforce’s Equipment Academy,Beijing 100850,China;3.Institute of Surveying and Mapping,Information Engineering University, Zhengzhou 450052,China
猜你喜欢
工程数学学报(2020年3期)2020-07-06
科技创新与应用(2020年6期)2020-02-29
长治学院学报(2019年2期)2019-07-24
雷达学报(2017年6期)2017-03-26
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
铁道通信信号(2016年6期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
电子器件(2015年5期)2015-12-29
