
广告段落分割系统中的字幕检测
2010-08-10 07:47谢志扬
电视技术 2010年2期
葛 菲,史 萍,姚 彬,谢志扬
(中国传媒大学 信息工程学院,北京 100024)
1 引言
在广告视频分析和广告段落分割的研究中,一个重要问题就是将整段电视节目按段落进行分割,从而使整段电视节目分解为正片、广告等场景,以便于组织和检索。一般的电视节目大致由一系列正片、片头、片尾、广告简单连接而成,而且部分广告段落是与片头和片尾紧密相连的,片头片尾部分包含大量的字幕信息,因此可以利用字幕特性确定片头和片尾片段。此外,在电视剧、新闻、综艺等节目播出时,在屏幕的左下角或右下角都会出现标志该节目名称的字幕区域。因此,字幕段落的出现往往表示一个广告段落的结束和新的电视节目的开始,或者一个电视节目的结束和新的广告段落的开始,它可以作为广告段落分割的边界。可见,判断出字幕段落对广告段落的检测是十分有意义的。
近年来,国内外对于从静态图像、运动视频中提取文字有大量的研究。Ohya等[1]使用灰度门限法对西文字符进行分割;Lopresti等[2]使用图像分析法对互联网上的静态图像进行了文字分割;黄祥林等[3]提出了在压缩域内利用纹理进行检测文字的算法;Lienhart等[4]基于分裂/合并算法对视频帧中的文字进行分割;胡宏斌[5]利用边缘检测对数字视频中固定区域(屏幕下方四分之一区域)的中文字符进行了检测和分割。
笔者在分析了整段视频节目字幕特征的基础上,针对片头片尾字幕片段提出了一种综合字幕边缘、字幕区域像素密度及字幕帧连续度的算法进行字幕段落的提取。在此基础上,针对特定区域节目标志的字幕,提出了在指定检测范围内进行字幕检测、以镜头为单位提取出字幕镜头的方法。
2 算法基本原理
通过对视频分析发现,在视频流中如果有字幕则一般出现在一段连续的帧内,不会只出现在一帧或几帧内,因为这样人眼将无法识别字幕,这样就形成了字幕段。字幕通常由汉字组成,而汉字在水平和垂直方向出现的笔画较多,根据汉字的这一结构特点,在电视节目的字幕片段检测中,主要利用Sobel算子[6]的水平和垂直模板对从电视节目视频中解码出来的每一帧图像进行字幕检测。图1所示为Sobel算子的水平和垂直模板。
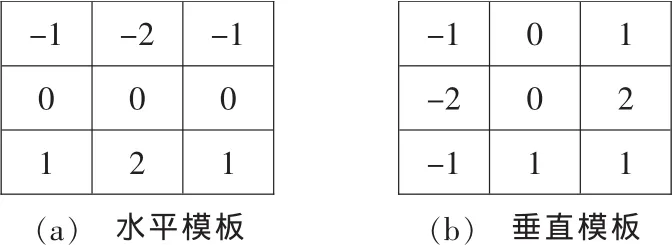
图1 Sobel算子的水平和垂直模板
2.1 字幕特征提取
视频字幕的检测是通过利用图像边缘检测技术,进而得到图像的边缘像素点来实现的,这里将图像的边缘像素点作为字幕检测的特征值。
对视频中的每一帧图像进行分析,将图中的每个点都用水平边缘Sobel算子和垂直边缘Sobel算子这2个卷积核做卷积,一个核对垂直边缘影响最大,而另一个对水平边缘影响最大。边缘检测算子的中心与中心像素相对应,进行卷积运算。运算结果是一幅边缘幅度图像。进行卷积时会遇到一些较复杂的问题,首先是图像边界问题。当在图像上逐个移动卷积核时,只要卷积核到达图像边界,就会出现计算上的问题。这时在原图像上就不能完整找到与卷积核中卷积系数相对应的9个 (对3×3卷积核)图像像素。解决这一问题的简单方法是:忽略图像边界数据,在图像的四周复制图像的边界数据。
图2显示了原始图像中3×3大小的像素邻域灰度模板,对于一帧图像中的每一个像素点来讲 (边界像素点除外),它经过Sobel算子的水平和垂直模板计算后得到的一阶偏导数为

式中:Gx及Gy分别为经横向及纵向边缘检测的图像。
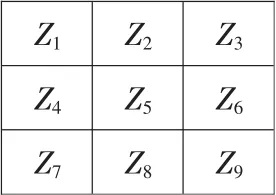
图2 3×3像素邻域灰度模板
对一阶偏导数求平方和

然后对每一个像素点的G值进行累加求平均值并乘以系数4,得到该帧图像的边缘阈值

式中:m和n分别表示该帧图像像素点的行数和列数。
最后进行判决,判断该帧中哪些像素点属于边缘部分。判决条件如下

水平方向上

垂直方向上

式中:Gx′和Gx″分别为Z2和Z8在水平方向的一阶偏导,Gy′和Gy″分别为Z4和Z6在垂直方向的一阶偏导。
满足式(5)和式(6)或式(5)和式(7),则当前像素点属于水平边缘部分或者垂直边缘部分,也即该像素点属于边缘像素点。
最后对属于边缘部分的像素点进行统计累加,得到值A,即为字幕特征值。
图3为字幕特征提取中的边缘像素点检测流程图。
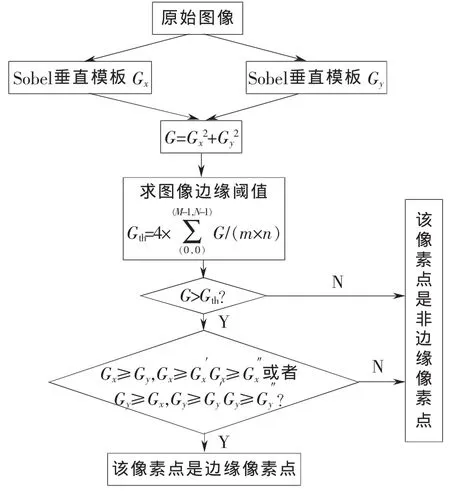
图3 边缘像素点检测流程图
2.2 片头片尾字幕片段的检测
字幕片段帧图像的A值要远大于其他帧图像的A值。经过计算观察,可以设定阈值Ath来判断当前帧是否为字幕片段帧图像。由于部分广告中也会出现字幕片段,因此在检测过程中也会将这部分内容检测出来,但是广告中字幕片段持续时间远小于电视剧中字幕片段的持续时间,也即广告中字幕片段持续帧数远小于电视剧中字幕片段的持续帧数。因此,可以设定一个持续帧数阈值Fth来判断是否为电视剧中的字幕片段。Ath和Fth共同来判决一段帧序列是否为字幕片段。
由于字幕占据的区域文字排列较紧密,根据这一特性,可用字幕的块密度[7]来判定该帧是否为字幕帧,这样可避免因不必要的纹理及条纹而造成的图像边缘点的增加,只要块中的边缘点Ba的数量大于阈值Tth,则判定其为字幕块,当字幕块的数量Bn大于阈值Bth,则判定该帧为字幕帧。
图4为片头片尾字幕片段检测算法流程图。
2.3 特定区域节目标志的字幕检测
由于一般节目一般都附带当前正在播出节目的节目标志,例如电视剧名称,新闻名称或综艺节目名称等,这些节目标志往往放置在电视节目的左下角或右下角,这里对这2个敏感区域进行研究。如图5所示,以352×288的视频图像为例,将下面的左下角和右下角区域设为敏感区域,并根据统计经验设定该区域的宽高值,单位为像素。

图4 片头片尾字幕检测算法流程图

图5 电视节目标志的敏感区域

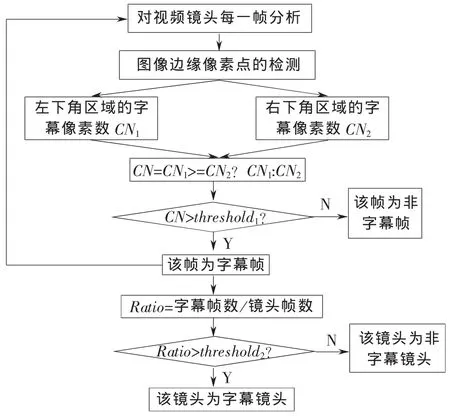
图6 左下角或右下角节目字幕标志检测流程图
3 实验结果及分析
3.1 片头片尾字幕检测实验结果
为了突出字幕检测的效果,将帧图像经过Sobel算子计算后得出的边缘图像进行二值化,得到几组图像如图7所示。

笔者对中央电视台播放的部分节目进行了实验,经过计算统计,字幕片段被正确地检测出来,检测结果如表1所示。
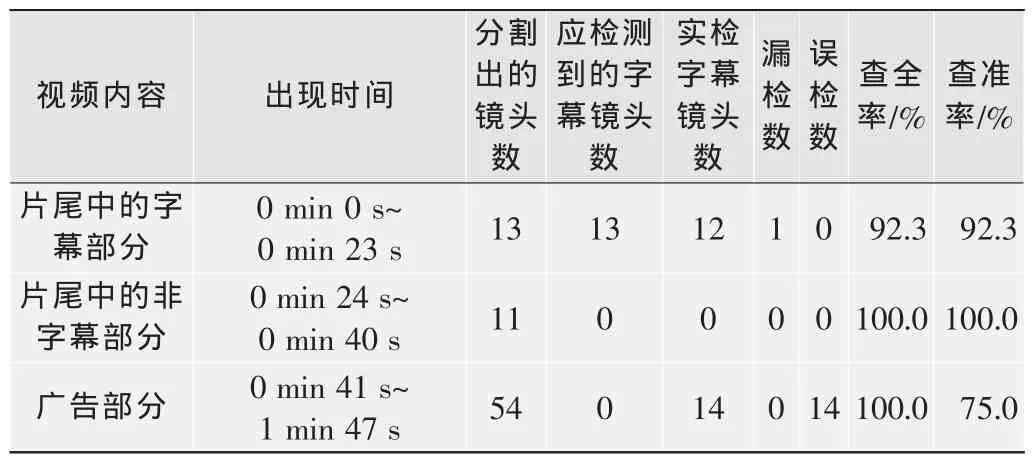
表1 中央电视台某播出视频片头片尾字幕检测结果
3.2 节目标志字幕检测实验结果
本文选取中央电视台播出的视频作为实验对象,这里以黄金时段播出的一段电视剧加广告的视频为例,将threshold1选为125,threshold2选为0.7,分析本系统对节目标志字幕检测的实验结果。节目共计时长6 min 16 s,共9 402帧,其中包含广告内容及广告前后的电视剧部分,实验结果见表2。
3.3 实验结果分析
从实验数据可以看出节目标志的字幕检测存在漏检和误检的情况,分析原因如下:
1)由于广告视频内容丰富多样,图像内采取多种线条纹理,在广告中敏感区内垂直水平线条丰富的情况下会造成广告片段内节目标志的误检,如图8所示。
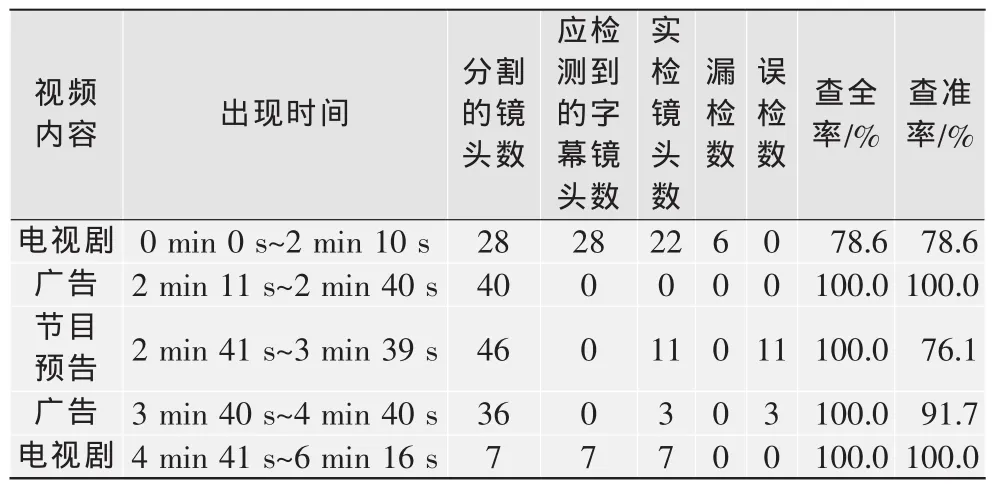
表2 中央电视台某播出视频节目标志字幕检测结果

2)采集视频有较多雪花,造成误检,如图9所示。

3)字幕帧阈值threshold1和字幕镜头阈值threshold2是字幕片段检测的关键。如果阈值选得太低,则某些广告片段就会被误检出来;如果阈值选得过高,则某些字幕片段就会出现漏检。本文选取的阈值是经过对大量带有字幕标志的片段和广告片段的敏感区域进行统计得到的值,虽然在大部分情况下能够正确检测,但仍会出现漏检和误检的情况,因此对阈值的选择还需要进一步优化。
4 小结
笔者提出了广告段落分割中的字幕检测算法,利用Sobel算子进行图像边缘检测,对边缘点进行统计分析,进而判断字幕帧,字幕镜头以及字幕段落。后续要对阈值的选取及模板的选择等方面进行优化,以达到更好的实用效果。
[1]OHYA J,SHIO A,AKAMATSU S.Recognizing characters in scene images[J].IEEE Transactions on Pattern Analysis and Machine In⁃telligence, 1994, 16(7): 214-224.
[2]LOPRESTI D,ZHOU J.Document analysis and the world wide web[C]//Proceedings of International Workshop on Document Analysis Systems.Malvern:[s.n.],1996:651-669.
[3]黄祥林,沈兰荪.基于DCT压缩域的图象字符定位[J].中国图象图形学报,2002,1,7A(1):22-26.
[4]LIENHART R,STUBER F.Automatic text recognition in digital videos[R].Mannheim Germany: University of Mannheim,1995.
[5]胡宏斌.基于语义信息提取的视频索引技术研究[D].武汉:武汉大学,2001.
[6]杨淑莹.VC++处理程序设计[M].北京:清华大学出版社,2005.
[7]蔡波,周洞汝,胡宏斌.数字视频中字幕检测及提取的研究和实现[D].武汉:武汉大学,2003.
猜你喜欢
现代电子技术(2021年1期)2021-01-17
小学阅读指南·低年级版(2020年9期)2020-10-12
阅读(快乐英语高年级)(2020年9期)2020-01-08
上海大学学报(自然科学版)(2018年5期)2018-11-02
电脑知识与技术(2018年35期)2018-02-27
散文诗(2017年17期)2018-01-31
自动化学报(2017年11期)2017-04-04
电子制作(2016年15期)2017-01-15
读写算(下)(2016年11期)2016-05-04
唐山文学(2016年11期)2016-03-20
