
维吾尔语、哈萨克语、柯尔克孜语在图书馆编目系统的应用
2010-07-18 03:12:04吾守尔斯拉木曹锦梅朱雪莲陈少鸿
中文信息学报 2010年4期
吾守尔◦斯拉木,曹锦梅,朱雪莲,陈少鸿
(1.新疆大学信息科学与工程学院,新疆乌鲁木齐830046;2.新疆医科大学高等职业技术学院,新疆乌鲁木齐830054;3.新疆艺术学院基础部,新疆乌鲁木齐830049;4.新疆会计干部培训中心,新疆乌鲁木齐830002)
1 操作系统和数据库的UNICODE的发展历程
尽管中国的维、哈、柯文字已经在 UNICODE 3.1以后得到批准,目前操作系统中,W INDOWS VISTA支持中国少数民族语言藏语、蒙古语、维吾尔语、彝语,但数据库系统中,却并不是完全支持,如微软的SQL SERVER2008。虽然增加了维、哈、柯文字数据库的排序,但不是本语,而是维吾尔语的拉丁字母的排序,这样不能完全满足少数民族语种的网络信息检索需求[1]。
2 多语种图书馆编目系统整体解决方案
2.1 统一存储各种语言数据
操作系统:数据库服务器端是WINDOWSVISTA,JAVA应用服务器端是比较普及的W INDOWS XP。数据库采用支持UNICODE5.0的Oracle10,支持UNICODE5.0的J2EE开发环境。数据库的安装按照全球化语言设置,定制为NLS-LANG=SIMPLIFIED CHINESE_CH INA.AL32UTF8,字符集编号为873,相应的文件是lx20369.nlb,是所有语言的超集,无论什么语言,只要是UNICODE中定义的就包含。完全支持藏语、维吾尔语、哈萨克语、柯尔克孜语、蒙古语、彝语,这样就可以正常存储一些少数民族文字了。表1是维、哈、柯文字在ORACLE数据库中的对照编码转换实验测试情况。

?
以上可以看出,图书馆编目软件要面对长度不一样的语言文字的编码:
占一个字节的英文字母和阿拉伯数字;
占二个或三个字节的阿拉伯字符(维吾尔语、哈萨克语、柯尔克孜语);
占三个字符的汉语、藏语、蒙古语、彝语等。
(占四个字符的中国古文字,因为没有安装输入法,没有测试。由于32除以 8等于4,正好目前UNICODE支持的最长四个字节,所以理论上也是没问题的。)
2.2 统一逻辑存储
数据库中字段存储的维吾尔语(阿拉伯语字符)是按逻辑顺序存储的[2],机读目录的格式也是按照逻辑顺序存储,子字段顺序也是按字母大小写顺序从左到右逻辑存储。这样无论是什么语种,无论显示的方向是从左到右,还是从右到左(维吾尔语、哈萨克语、柯尔克孜语),从上到下(蒙古语、察合台语),都是逻辑顺序,这样机读目录在多语种图书馆内部的业务规则各语种是统一的[3]。
逻辑顺序的统一意味着检索顺序的统一。检索的一致性使我们不再为各个语种设计单独的检索策略,使多语种图书馆编目系统的设计简单。
2.3 统一显示字符
不再像过去采用微软的WEFT软件将字库嵌入到网页文件上,这样非常麻烦,也是过时的做法。针对XP操作系统的只需下载符合UNICODE的各少数民族文字的输入法和字库(XP补丁不能太旧,要支持UPS10.DLL以上),在VISTA中本身就可以支持蒙、藏、维、彝。我们安装了新疆大学维、哈、柯语输入法,除维吾尔语和微软的输入法完全一样,哈萨克语、柯尔克孜语都正常使用显示。
2.4 统一字符编码的转换
采用通用的网络服务器和客户端浏览器的方式,客户端输入的维、哈、柯文字是UTF-8格式[4],通过浏览器传到J2EE应用服务器,不进行转换,仍然以UTF-8的格式通过JDBC接口传入数据库,不存在转换问题,避免了乱码等问题。例如:多语种机读目录表”MARC”为例,下列对应的SQL数据类型对应表如表2、表3所示。
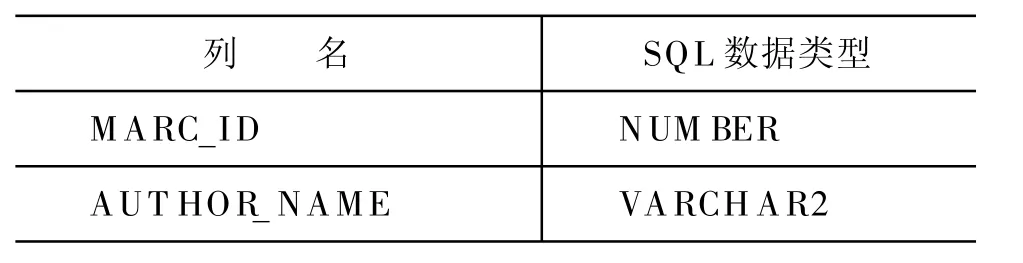
表2 机读目录表列与SQL数据类型对应表

表3 机读目录表列与Java类型对应表
2.5 统一的多语种编目规则
由于系统要处理多种语言,中文的机读目录实际上是脱胎于美国的机读目录,对中国少数民族文字编目涉及较少,国内各少数民族地区如内蒙古也研制本语种的机读目录格式(推广的不充分),这样容易混乱,所以我们完全采用中文机读目录的格式,增加了880字段(可以不增加,系统完全支持民文,为了响应国家版权图书馆的在版编目数据CIP,国内所有的图书都有规范的汉语的目录),进行过渡,系统嵌入民文拉丁字母转换程序,在正文和880字段著录原文和拉丁罗马化的民文。
2.6 统一的检索策略
由于存储了多语种,所以采用什么检索方式是非常重要的。因为英文存在大小写问题,维吾尔语、哈萨克语、柯尔克孜语存在语中、语首、语尾、独立形式,蒙古语也存在变形字母连接问题。这些问题如果单独处理,要在程序上增加分支,实际上我们采用了一个非常简单的办法,只要在检索的SQL语句上增加个函数UPPER()函数[5],就解决了上述问题,至于汉字的简体、繁体的联连问题,以后再考虑(香港地区、新加坡用的多,国内很少使用,特点是简体、繁体一并检索)。这样就可以达到字段中的任意检索,不管形式。另一方面,在SQL语句中增加入口,比如书名字段和880书名替换拉丁罗马化民文,可同时进行检索。
条件格式:

2.7 统一页面流程
由于基于统一策略,多语种编目程序流程不设立分支,一套程序流程,即在应用服务器端运行的程序都是一样的,各语种在一套程序中运行,将各个语种的差别全部不考虑,让程序简单化。浏览器首选语言设置,表4给出了维、哈、柯文字语种代码。

表 4 中国维、哈、柯文字语种代码表
系统根据客户端浏览器的首选语言从服务器发送相应的语言标记的页面[6]。
2.8 统一用户界面
针对不同文字流方向的问题,统一原则采用表格页面的方式,将各个控件都限制在类似单元格中,在一套英文界面中以提示的英文为核心,建立多语种的名称数据库。
2.9 统一多语言排序
采用 UNICODE编码,数据库排序只能按照UNICODE的排序方式,即:按照UNICODE编码的码位顺序排序(按字符代码的二进制排序(汉字的UNICODE是按部首排序的))。虽然可以按照ORACLE的本地化设置进行维、哈、柯语种字符自选设计排序顺序,但意义不大,而且本研究是以实现统一的原则,缩小了个性化的问题。针对各个语种字符特有的排序方式(比如英语的单词语音排序、维吾尔语字符集特有的排序方式等)都暂时不能直接使用了。准备以后在查询语句中添加各民文语种规范排序文件名。
2.10 统一定义数据库的名称
由于ORACLE支持维、哈、柯文字的字段名,这就存在选择什么语言来定义字段,由于涉及计算机数据库字段名,编目员看到的规范字段名与读者看到的供显示的字段名都是不一样的,如表5所示。

表5 数据库、实体对象、视图对象、属性对应表
例如,维吾尔语小说《阿凡提的故事》,读者看到的是“书名:阿凡提的故事”;编目员看到的是“200$a阿凡提的故事”;机读目录书名的字段名是“200$a”;J2EE定义的O racle数据库字段名是“200”;系统自动转换为:数据库字段名是“M 200”。机读目录在数据库内容上是不存储“200”,只有在组装成机读目录,进行交换时才进行组装成纯文本的字符流的。
书名实体对象(数据库内部存储)、视图对象(单一数据库的各种显示表格)、标签(显示的机读目录字段的名称)是数据库、J2EE开发环境、机读目录三方对于定义的规定是不同的,这三方在编程时是要统一协调的。
2.11 统一长度的定义
字段定义时,按照字符的长度,将一个字节的阿拉伯数字、英文;两个字节的维、哈、柯文;三个字节的维哈柯扩展区字符;三个字节的汉字;四个字节的中日韩的扩展区的汉字都统一到“1”的定义,根据ORACLE数据库字符集UTF-8属性,自动乘以字节长度,而得到实际长度。所以在编程时,全部采用符合UNICODE的函数,从根本上破解所有不规范的问题。
3 民族语言的显示特性
以上是将维、哈、柯文字统一化处理的策略。但各语言的特性不同,维吾尔语、哈萨克语、柯尔克孜语是横向,从右到左;简体中文是从上到下,从左到右。不管文字流的特性如何,只是呈现出来的显示问题,在数据库中全部按照逻辑顺序存储,数据库与应用程序和客户端都是按照逻辑顺序传送,文字显示上的语言内部的变形、逻辑关系由操作系统的程序决定,文字方向流由浏览器的参数决定,如表6所示。
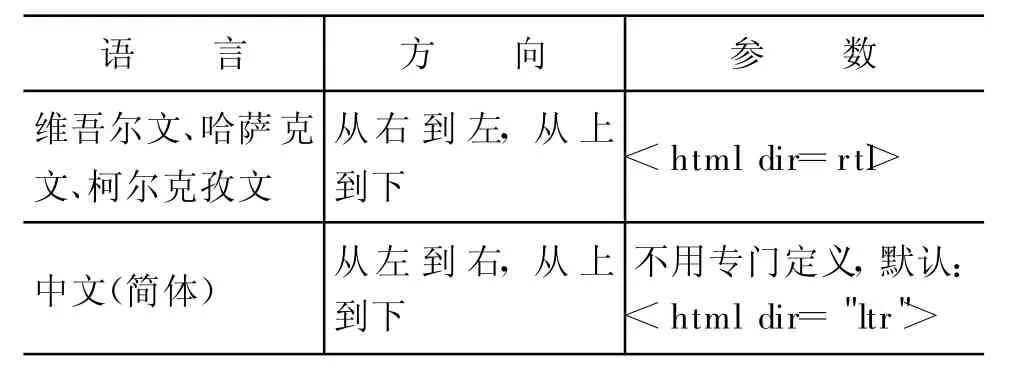
表6 各语言显示方向及语种
4 结束语
通过以上的整体规划实现了图书馆编目的分层管理,如表7所示。

表7 分层管理与分层实现
本文对我国维、哈、柯文字进入数字图书馆系统做了深入研究,通过UTF-8的统一字符编码格式,使维、哈、柯文字达到了与汉字同等的应用,为少数民族文化的数字化发展提供了具有现实意义的实施方案。同时 UNICODE也解决了汉字与维、哈、柯文字的统一处理问题,目前由我国提案,正在计划将古维吾尔文添加到UNICODE[7],这样加快了新疆灿烂悠久的历史文献的数字化进程。
[1] 吐尔地◦托合提,维尼拉◦木沙江,艾斯卡尔◦艾木都拉.维、哈、柯多文种全文搜索引擎的设计与实现[J].计算机应用与软件,2009,26(6):96-98.
[2] 吉虹.新疆少数民族图书馆自动化与数字图书馆[J].现代图书馆情报技术,2002,2:10-12.
[3] 陈少鸿.多语种图书馆编目系统分析与设计[D].新疆大学,2009.
[4] 吴俊森,吐尔根◦依不拉音.基于内容的维文文本检索系统[J].现代计算机,2006.
[5] 盖国强.循序渐进O racle数据库管理、优化与备份恢复[M].北京:人民邮电出版社,2007.
[6] 邹竹彪.JSP网络编程从入门到精通[M].北京:清华大学出版社,2007.
[7] 地里木拉提◦吐尔逊,瓦依提◦阿不力孜,吐尔根◦伊布拉音.古维吾尔文(察合台文)及转写符号的智能输入法研究[J].中文信息学报,2007,21(6):125-128.
猜你喜欢
广东教学报·教育综合(2022年69期)2022-06-23 13:50:23
时代邮刊(2021年8期)2021-07-21 07:52:44
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:05
海外华文教育(2017年6期)2017-08-07 03:10:42
自动化学报(2017年4期)2017-06-15 20:28:55
新疆大学学报(哲学社会科学版)(2015年5期)2015-10-12 01:16:14
语言与翻译(2015年4期)2015-07-18 11:07:45
语言与翻译(2014年3期)2014-07-12 10:32:09
中国边疆民族研究(2014年0期)2014-02-13 02:32:22
新东方英语(2014年1期)2014-01-07 20:03:00
