
加入调型信息的汉语孤立词识别研究
2010-07-18 03:12:02王鹏胡郁戴礼荣刘庆峰
中文信息学报 2010年4期
王鹏,胡郁,戴礼荣,刘庆峰
(中国科技大学电子工程与信息科学系科大讯飞语音实验室,安徽合肥230027)
1 引言
众所周知,汉语是一种有调语言,汉语中的每一个字都是以一个音节作为基本的发音单位,音节和调决定了这个字的发音。正确的调型对区别不同字或词起到了很关键的作用[1-4]。因此,调的信息在汉语语音识别中起着很重要的作用。尤其在同字不同调的情况下,调的正确识别显得就更为重要。
调的信息如何更好的与现有的隐马尔可夫模型(H idden M arkov M odel)进行结合,还没有得到很好的解决。主要有以下困难:第一,调的类型实际上由基频曲线的形状所决定,而基频的一个特点是非连续性,基频仅存于语音的浊音段,在静音段以及清音段的基频是不存在的,因此不便直接将调型信息融入于传统的连续HMM;第二,调型特征相比较于声学段的特征,是一种超音段特征(supra-segmental feature)。这使得在进行上下文相关的声学建模时,将调的上下文信息加入到原有的Tri-phone建模单元中需要特殊考虑。原因在于,加入调的上下文信息后,模型的复杂度将极大地增加,以 Tritone为例,模型单元中韵母(调的载体单元)为150个,经过扩展后将比原来增大25倍,而在现有的系统中很难采用这么大的phone集合来建立可靠模型。
为了解决以上两个困难,近些年来研究者进行了一系列的尝试[1-2]。针对第一个问题,目前有两种解决方案,第一种是采用对非浊音段进行内插的方法来保证基频连续性[3],再将基频特征与原来的频谱特征拼接起来,重新组成一个增大的特征向量来训练模型,这就是Em bedded Tone M odel[4]。第二种是Tokuda提出的基于多空间概率分布的HMM模型(MSD-HMM)[5-7],也就是对于基频和声学谱特征,建立两个概率分布空间,离散的和连续的,分别对应于清音段和浊音段,此方法可以避免由于人工内插基频所带来的对模型参数估计的影响。而对于第二个问题,可采用Exp licit Tone M odel的建模方式。也就是对调单独建模。由于将调分离出来建模,我们可以采用更为复杂的建模方式,如上下文相关的建模方案以及考虑超音段特性等[8,12-13]。再利用此模型,对已有的解码网络进行重新打分,从而获得识别率的上升。
这两个问题处于调的信息在自动语音识别中运用的两个不同层面:第一个问题在于如何在传统的连续HMM模型框架下使用基频特征;第二个问题在于如何挖掘调的更为精细,更为深层的信息。本文从这两个层面出发,提出了一套在二遍解码的框架下将 Embedded Tone M odel和Explicit Tone M odel的优势相结合的方法,充分利用了调的有效信息,从而使识别性能较大幅度提升。
本文的组织结构如下,第2节给出整个系统构成并分别介绍调型特征,双流建模[6]方法和Explicit Tone M odel的建模方法,以及二遍解码的两模型得分融合方法及原理;第3节给出实验结果及分析;第4节给出结论并展望今后工作的趋势和方向。
2 系统构成及原理
2.1 系统构成
本文的系统是以 Embedded Tone M odel和Explicit Tone M odel结合为基础,目的在于将两者的优势充分结合,从而实现对调的信息的充分利用,以达到提高识别率的目的。此系统是在汉语孤立词识别任务上进行试验。
系统结构为图1所示,在第一遍解码中我们将不考虑调的上下文相关的信息,将频谱特征和调型特征分流建模,在决策树绑定的时候根据不同流来分别进行聚类,两个流都是通过连续HMM进行建模。在第二遍解码过程中,Explicit Tone M odel可以通过第一遍解码所得到的结果确定音节边界,从而确定浊音段的时间边界信息,再利用此信息训练出一个精细的上下文相关的调的模型。最后利用该模型对第一遍解码后得到的Nbest保留备选结果重新打分、排序,从而得到最终识别结果。

图1 系统构成图
2.2 特征处理
在Embedded Tone Model中对于第一个流选取的特征是广泛运用的M FCC(梅尔倒谱参数)特征,第二个流采用的是利用谐波求和法算出的F0特征及其一阶二阶差分,以及通过自相关法算出的浊音置信度。F0特征利用动态规划算法进行了后处理,一方面使特征具有连续性,另一方面在一定程度上减少半频,倍频误差。同时为了降低不同说话人的调域影响,我们还利用前后各1秒的窗对F0特征进行规整,也就是长时基音周期规整(LPN)[10-11]。
在Exp licit Tone M odel中我们采用了与第二个流相同的特征,只是对特征的使用有所区别,其具体方法如下:利用模型对原训练数据进行硬切分,用以确定作为带调载体的韵母所在的时间位置,从而能够消除为连接基频而加入的虚假基频的影响,以达到对调精确建模的目的。
2.3 双流建模
传统的Embedded Tone M odel是单流建模,即将频谱特征和调型特征绑定成一个流进行建模。我们知道频谱特征和调型特征是两种具有一定独立性的特征,因此在决策树绑定的时候将两种特征参数绑定在一起有两个缺陷:一是不够灵活,两种特征应该根据其不同特点进行分类,因此,单流建模很难将调的特点发挥出来,也就得不到更为充分的训练。另一是模型的复杂度过大,对于汉语来说,phone的模型单元数共69个,扩展为T ri-phone的时候大约2000状态数即可描述其特性。而调的模型单元数只有5个,只需要约500状态即可描述。如果采用单流建模,由于将两个建模单元绑定在一起,因此,调型模型的状态数必须与音的模型状态数保持一致,这样就造成模型的复杂度提高。而双流建模恰好可以解决这样的问题。在双流建模中,每一个HMM的状态单元包含两个分布,一个用以描述频谱参数,另一个用于描述调型参数。在训练过程中,输入特征向量Ot(包含频谱特征和调型特征)被当作两个独立的流,独立估计每个流的混合高斯参数。比如,给定输入特征向量Ot,在t时间j状态下的输出概率变为公式(1):
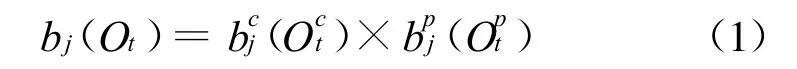
其中bc和bp分别对应着频谱和调型的分布,特征向量Ot也是由频谱特征和调型特征组成。而连续HMM的高斯混合模型也分别由独立参数描述,其表示如公式(2)和公式(3)所示:
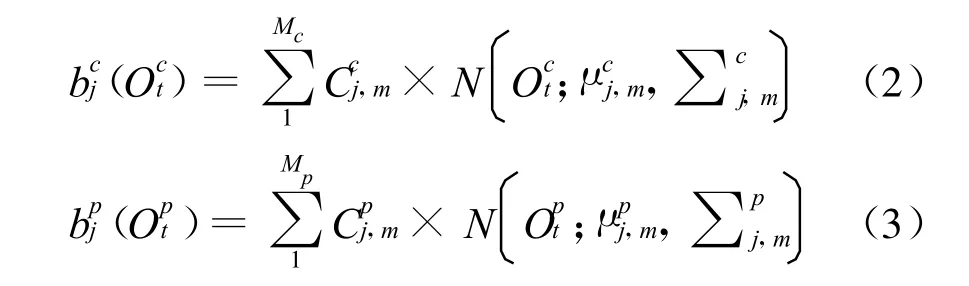
对于每一个状态,频谱分布和调型特征分布是用不同的高斯数来描述的,这样就可以通过不同复杂度的模型实现最优建模。
当作为调载体的韵母模型单元进行T ri-phone绑定的时候,我们假设频谱和调的特征是独立分布的。因此,对于处在同一状态相同中心phone单元,我们可以将其第一个流绑定在一起,同理,对于同一状态的相同调单元,我们可以将其第二个流绑定在一起。具体原理如图2所示。

图2 韵母双流绑定训练的示意图
2.4 Exp licit Tone Model的训练方法
在Embedded Tone Model中,我们已经在一定程度上使用了调的相关信息。但是由于调的特性和HMM建模自身的限制,并未能够对调进行精细建模,比如并未考虑上下文相关信息以及消除在非发音段中的人为添加的基频所造成的影响。因此,在Explicit Tone M odel中我们必须考虑到这些因素,从而在二遍解码中增加有用的信息量以进一步提高识别率。具体建模过程如下:第一步,通过训练好的模型对原训练数据进行硬切分,从而获得带调韵母的特征边界;第二步,进行上下文相关的调的模型训练。在本文的实验中,我们采用的是左相关调的建模,因为有实验表明,在连续语流中,左相关调的建模比右相关的性能要好。
2.5 二遍解码中两模型得分的融合方法
建立 Em plicit Tone M odel后,便可对用Embedded Tone Model解码出来的Nbest备选结果进行重新打分,并根据得分对识别备选条目重新排序,最终得到识别结果。在这里,我们可以将最终后验概率计算公式写为(4),因为是孤立词识别任务,所以不考虑语言模型:
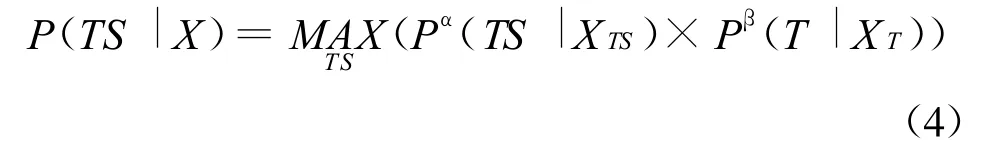
其中P(TS|XTS)为第一遍解码中利用Embedded Tone M odel所计算出的后验概率,α为其所占的权重。而P(T|XT)为Explicit M odel中的利用了左相关调信息的后验概率得分,β为其所占的权重。其中为了得到最优结果,α和β将在开发集上进行调整。由于识别任务是孤立词识别任务,因此其解码网络也是受限网络,所以我们可以认为在Lattice上进行重新打分与在Nbest出来的每一个备选条目上进行重新打分是效果一致的。在实验中,我们发现对于命令词识别任务来说,一般3Best的覆盖率已经很高,足以作为识别上界。因此我们的试验都是保留3Best作为备选结果,整个融合过程以及重新打分的具体方案如下:
第一步利用Embedded Tone M odel进行一遍解码,解码后保留3Best结果,并且对每一个备选条目进行Phone一级的硬切分,从而得到其带调韵母的边界,为利用Explicit Tone M odel进行重新打分作准备。
第二步利用Exp licit Tone M odel和上一步中一遍解码得到的切分结果对每一个3Best中的备选条目中的每一个带调韵母单元重新计算得分。在此处,需要注意的是,每一个调的得分计算的不再是似然值,而是当前调的后验概率。具体公式如(5):
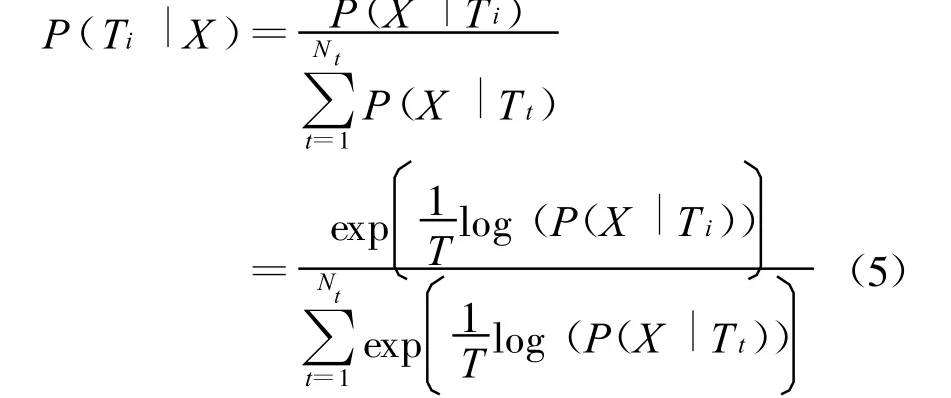
其中(5)式的X表示基频的特征向量,Ti表示当前的调的类型,如Tone1_2(当前调型为阳平,前调为阴平),Nt为调的总的模型数目,由于是左相关的调的模型,因此 Nt的值为20。T表示当前韵母的时间段长度,用以进行帧级别的归一化。进行帧级别归一化的原因在于与原来一遍解码的结果相比,我们所计算的后验概率只利用韵母段的特征进行计算,这样就造成了一遍解码和二遍解码所采用的特征段不一致,所以必须进行帧一级别的归一化。当完成此步骤后,即可计算每一个备选的调后验概率得分,公式如(6):
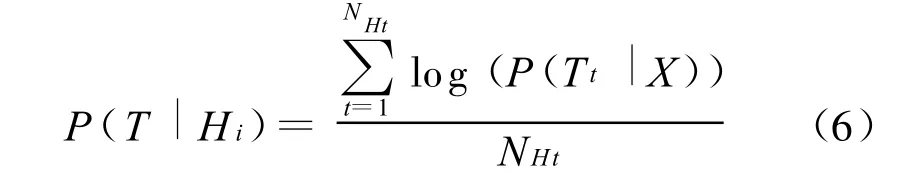
(6)式是由于Nbest中每一个备选的调的数目不同而进行的归一化,NHt为当前备选中韵母的总数目。
第三步,融合由Embedded Tone M odel得到的每一个备选的后验概率和由 Exp licit Tone Model得到的每一个备选的后验概率,并计算出最终的得分,公式如(7),(8),(9)所示。
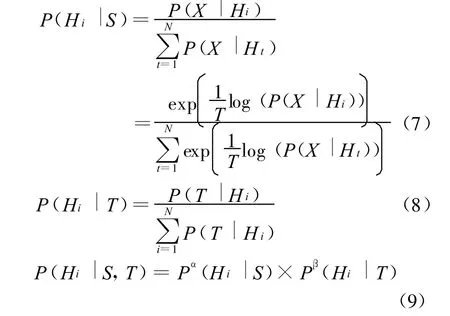
其中(7)式为Em bedded Tone M odel的每一个备选在Nbest备选中的后验概率的得分,(8)式为Explicit Tone M odel中的每一个备选在Nbest中的后验概率的得分,(9)式为最后重新进行得分计算的公式。
注:(9)式中的 α,β分别为 Embedded Tone M odel和Exp licit Tone M odel中的后验概率所占的权重。
第四步,对备选得分按从大到小排序,输出识别结果。
3 实验结果及分析
3.1 数据库介绍
为了验证本文中的方法的有效性,我们采用的训练数据库是一个电话数据库,该数据库为电话信道采集的真实语音数据,内容包括短语、数字串、字母或短句等,覆盖全国大部分省份,男女各半,总时长为360小时。其中我们使用的是该数据集的一个子集,共 17万句。此子集用来训练 Em bedded Tone M odel。Explicit Tone M odel的训练数据是从该训练库中另抽取的5万句组成。
测试库共有6个,是在不同环境下录制的真实数据,分别是:
(1)干净环境下录制的电话数据库,共有1 300个条目,后面的报告中统称为测试集一。
(2)一定噪声环境下录制的电话数据库,并从中挑选信噪比低于20dB的语音数据组成测试集,共1 600个条目,后面的报告称为测试集二。
(3)在会场嘈杂环境下录制的数据库,共1 600个条目,后面的总结报告中对整理后的数据定义为测试集三。
(4)车载环境下录制的数据库,存在开窗或开空调等背景噪声,共4 800个条目,但信噪比较高,后面的总结报告中定义为测试集四。
3.2 前端处理
对于语音信号先去直流,预加重(因子为0.97),汉明窗加窗,帧长 25m s,帧移 10m s的。在抽取MFCC特征参数的同时,采用一种基于能量的VAD算法,对每一段语音滤除掉大约25%~30%的无声段。抽取0~12维MFCCs,总计为13维。特征参数通过倒谱均值相减(CMS)去除信道卷积噪声;计算一阶差分、二阶差分总计构成39维;对于调型相关特征,采用利用谐波加权法和长时基音周期规整算法所得到的经过归一化的基频(F0)特征和其一阶,二阶差分以及一维浊音置信度。
3.3 Embedded ToneM odel和Exp licit ToneM odel的训练
两个模型的训练都是基于HTK工具,Embedded Tone M odel中采用的是声韵母建模单元,并进行T ri-phone扩展。该模型采用双流建模,第一个流状态数控制为2000状态,第二个流为500状态,每状态高斯数为12;此外,一个3状态的silence模型及一个单状态的shortPause(sp)模型也被引人系统中以吸收静寂段及各数字之间的短停顿。在Triphone扩展的过程中对于两个流设计了不同问题集以及不同决策树进行聚类。Exp licit Tone M odel我们采用的是左相关的调型建模单元,每个模型单元为5状态,高斯数为8高斯。
3.4 实验结果以及分析
实验一,调识别率实验。为了验证 Explicit Tone M odel中的左相关调建模的有效性,我们进行了下列实验。利用M onoTone作为基线系统,分别进行左相关以及右相关的调的建模进行对照,实验结果如表1所示:

表1 M onoTone,左相关,右相关建模调的识别率
如表1所示,左相关(Left_BiTone)或右相关(Right_BiTone)的建模相比于原M onoTone建模,其识别率能大大提高,并且左调相关的识别率高于右调相关的识别率。这是在于对于M onoTone而言,没有考虑到调的左右相关信息,因此不能更好的突出汉语连续语流中左右调对于当前调的的影响,所以识别性能不如采用考虑左右相关性的调的建模方式。并且由于汉语自身的发声特点,左相关的建模能够更好的描述在连续语流中变调现象。因此,我们相信采用左相关的Exp licit Tone Model将会带来更为准确的信息。
实验二,覆盖率实验。为了验证 Em bedded Tone Model中得到的3best备选结果是否能达到充分覆盖正确结果的目的,我们分别测定了10best,5best,3best和1best下的识别结果,以确定其有效性,其结果如表2所示:
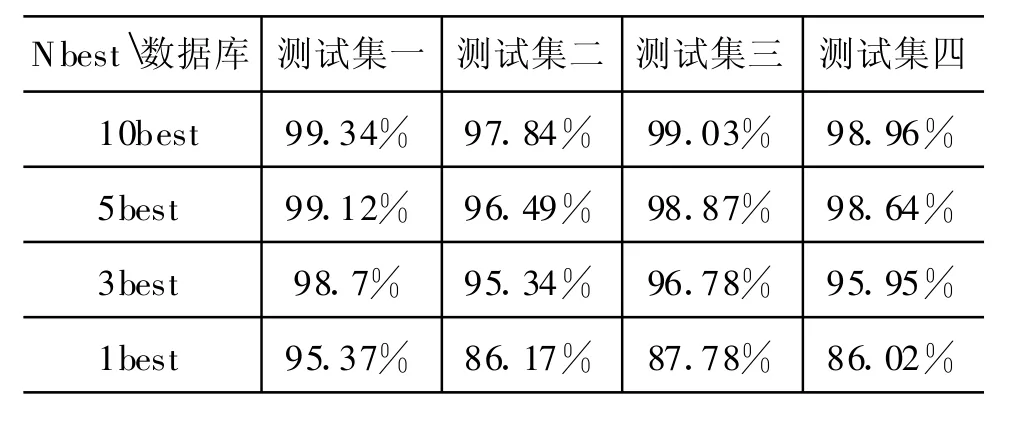
表2 覆盖率实验
如表2所示,随着备选的增多,正确词的覆盖率可以得到极大的提高。其原因在于对于汉语孤立词识别任务,由于解码空间是受限空间,因此解码后的得到的NBest备选将会覆盖绝大部份正确答案,从而具有很高的正确词覆盖率。Explicit Tone Model的作用就在于如何将这些在备选中混淆的词利用更加准确的调信息加以区别以获得更高的识别率。由实验结果可得,3best的准确词覆盖率已远高于1best,因此,从效率因素考虑本文中进行两遍解码所保留Nbest的备选数目为3个。
实验三,利用Explicit Tone M odel对 Embedded Tone Model所得到的识别结果进行两遍解码,从而得到最终的识别结果。其中我们从电话数据库中找出一部分作为开发集,以确定了α,β权重的参数范围。α,β的参数设置为(1,0.05)。实验的基线系统为不带调特征的单流模型,其他配置与Embedded Tone Model系统保持一致。实验结果如表3所示。
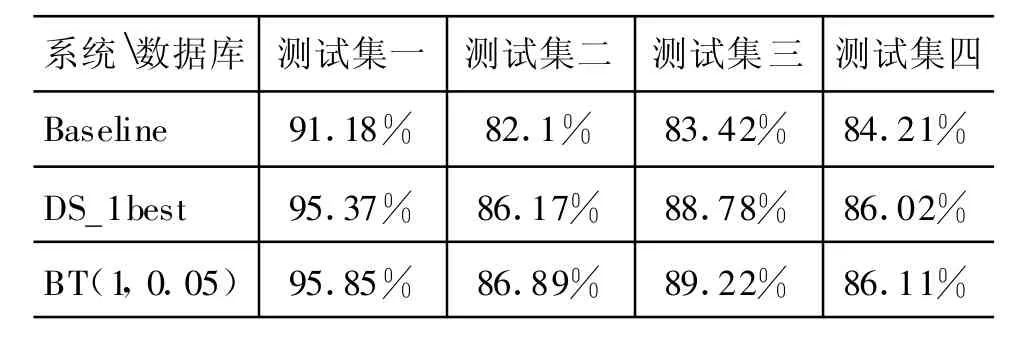
表3 二遍解码的识别结果
表3中,可以看到Embedded Tone M odel中的双流建模(DS_1best)对识别率提高非常明显,平均能提高3%左右,在测试集三上能提高5.36%。其原因在于双流建模能更好的将音的特性和调的特性分流去进行绑定、建模,从而极大程度上提高了调的信息的在汉语语音识别中的作用。结合Explicit Tone M odel的二遍解码(BT)方法,也看到了其对识别性能的提升所起到的作用,由于Explicit Tone Model在建模过程中避免了基频内插所带来的影响和在Embedded Tone M odel中由于超音段限制而无法考虑的调的上下文相关性的影响。因此,在更为精细的Explicit Tone M odel的帮助下,还能在一定程度上提高识别率。
4 结论及展望
在本文中,主要讨论了如何在汉语孤立词识别任务上更好的利用调的信息,采用的方法是在两遍解码的框架下,将 Embedded Tone M odel和 Exp licit Tone M odel相结合的方式。在 Embedded Tone M odel中我们用的M onoTone进行建模,并且利用双流建模两方面的优势:一方面在 Triphone绑定的时候,将频谱信息和调型信息分开,从而能够利用两者不同的特点进行绑定;另一方面,降低了模型复杂度。但是由于Embedded Tone Model没有充分利用调的上下文相关信息,因此我们利用Explicit Tone M odel中进行更为精细的建模。在融合过程中,由于不同备选的时间切分信息不一致,造成两者的得分范围不一致。为解决此问题,我们进行了帧一级的归一化,然后再进行后验概率的得分融合。本文中的两种方法的结合较大幅度提高了识别率,并且在一定程度上降低了模型复杂度。本文工作主要运用于汉语孤立词识别,但是没有充分利用语流中词调和句调信息,因此如何将这些高层次信息运用到孤立词识别任务中,以及将相关方法推广到汉语大词汇量连续语流识别中将是下一步工作中所要考虑的问题。
[1] Y.W.Wong and E.Chang.The effect of pitch and tone on different Mandarin speech recognition tasks[C]//Proc.Eurospeech,2001:1517-1521.
[2] C.J.Chen,R.A.Gopinath,M.D.M onkow ski,M.A.Picheny,and K.Shen.New methods in continuous Mandarin speech recognition[C]//Proc.Eurospeech,1997:1543-1546.
[3] M odeling of fundamental frequency using a quad ratic sp line function[C]//'IYavaux de I'Institut-de Phonetique d'Aix 15,1993:71-85.
[4] Qian Y.Use of Tone information in cantonese LVCSR based on generalized character posterior p robability decoding[D].PhD.Thesis,CUHK,2005.
[5] Tokuda K,Masuko T,M iyazaki N,Kobayashi T.M ultispace p robability distribution HMM[C]//IEICE Trans.Inf.&Syst.,2002;E85-D(3):455-464.
[6] Frank Seide and N.Wang,Two-Stream Modeling of Mandarin Tones[C]//Proc.ICSLP 2000,October,2000.
[7] Wang H L,Q ian Y,Soong F K,Zhou JL,H an JQ.A Multi-Space Distribution(M SD)approach to speech recognition of tonal languages[C]//Proc.of ICSLP,2006:1047-1050.
[8] Jin-song Zhang and Keikichi H irose,Anchoring H ypothesis and its App lication to Tone Recognition of Chinese Continuous Speech[C]//Proc.ICASSP 2000,2000.
[9] C.H.H uang and F.Seide.Pitch tracking and tone features for mandarin speech recognition[C]// Proceedings of ICASSP,2000:1523-1526.
[10] 朱小燕,王昱,刘俊,汉语声调识别中的基音平滑新方法[J].中文信息学报,2001,20(2):45-50.
[11] 潘逸倩,魏思,王仁华,基于韵律信息的连续语流调型评测研究[J].中文信息学报,2008,20(4):88-93.
[12] 林茂灿.普通话语句的韵律结构和基频(F0)高低线构建[J].当代语言学,2002,(4):254-265.
[13] 勇强,初敏,贺琳,吕士海.汉语话音节时长统计分析[C]//第五届全国现代语音学学术会议论文集,2001:66-69.
猜你喜欢
中国人民公安大学学报(自然科学版)(2022年1期)2022-07-20 02:51:14
新疆大学学报(自然科学版)(中英文)(2022年2期)2022-03-27 02:08:08
山东交通科技(2020年2期)2020-08-13 09:24:06
工程数学学报(2020年3期)2020-07-06 07:38:40
计算机工程(2020年3期)2020-03-19 12:24:50
长治学院学报(2019年2期)2019-07-24 07:14:04
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
中国交通信息化(2018年3期)2018-06-13 03:27:58
电子制作(2017年20期)2017-04-26 06:57:35
雷达学报(2017年6期)2017-03-26 07:53:04
