
基于评价指标体系的客运专线客流节点聚类分析
2010-07-13 08:57邓延伟
铁道运输与经济 2010年5期
邓延伟
(北京交通大学 经济管理学院,北京 100044)
我国客铁流路节客点运间专的线关规联模关大系,复路杂网。和因客此流,密在度制分定布旅不客均列衡车,开行方案时需要考虑客流节点的重要性,分析节点间的差异性,并对客流节点进行聚类研究。
聚类分析法是对所研究的事物按照一定标准进行分类的数学方法。其根据事物特征,定义能度量样本间关联程度的统计量,按照关联程度对样本进行分类,将关系密切的聚集到一起,成为一个分类单位。聚类分析对样品进行分类的效果,关键是统计指标的选择。在对客流节点进行聚类分析之前,首先建立综合评价指标体系,运用层次分析法进行指标权重计算,将半定性、半定量的问题转化为定量指标问题,得出样本的综合评价结果。在此基础上,通过K-均值聚类分析得到客流节点分类标准,为制定客运专线的旅客列车开行方案提供科学依据。
1 客流节点聚类原理
节点的形成和功能定位是政治、经济、市场需求等多种因素综合作用的结果。因此,客流节点的聚类应保持客运专线网络的完整性,注重节点间的相关性和联络性,遵循与客运专线网络功能、客流量、客运站技术作业能力、人口数量、经济发展水平和旅客出行需求等相适应的原则。
1.1 聚类指标体系的建立
综合考虑与客流节点相关的运输组织、网络衔接、地方经济等因素,将节点的客运需求、路网属性、客运能力和社会属性 4 项要素作为聚类研究的依据,并在此基础上,将节点聚类指标层次化,得到 9 项二级指标,建立客流节点聚类综合评价指标体系,如图1 所示。
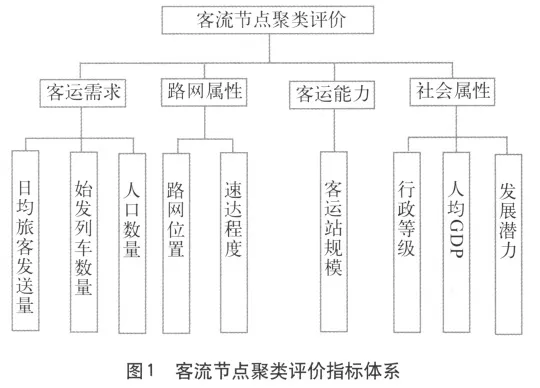
1.2 聚类指标体系的评价
应用层次分析法对客流节点聚类评价指标体系进行综合评价。
1.2.1 构造判断矩阵
采用 1~9 比例标度进行同层次两两要素之间的比较,构造判断矩阵。比例标度的含义如下。标度 1 表示两个元素相比,具有同等重要性。标度 2 表示两元素重要性介于标度 1 和标度 3之间。
标度 3 表示两个元素相比,一个元素比另一个元素稍微重要。
标度 4 表示两元素重要性介于标度 3 和标度 5之间。
标度 5 表示两个元素相比,一个元素比另一个元素明显重要。
标度 6 表示两元素重要性介于标度 5 和标度 7之间。
标度 7 表示两个元素相比,一个元素比另一个元素强烈重要。
标度 8 表示两元素重要性介于标度 7 和标度 9之间。
标度 9 表示两个元素相比,一个元素比另一个元素极端重要。
1.2.2 计算各级指标权重
通过合积法求解判断矩阵的特征根,其解即为同一层次各指标的权重系数,并对其进行一致性检验,其检验步骤如下。
(1)计算一致性指标:CI=(λmax-n)/(n-1)。式中:n 为判断矩阵 A 的阶数;λmax为判断矩阵 A 的最大特征根。
(2)计算一致性比例:CR =CI/RI。式中:RI 为平均随机一致性指标,是CI 的修正系数。当 CR<0.1时,一般认为判断矩阵的一致性是可以接受的。
1.2.3 二级指标的量纲处理
在进行指标比较之前,需要定性描述指标转化为定量指标问题,并统一数据量纲,以使评价结果更加科学、准确。建立定性指标评语集合{好:0.90~1.00;较好:0.75~0.90;一般:0.55~0.75;差:0.55 以下},根据指标特点采用相应的评价标准,如表1 所示。定量指标将指标项数据划分为 4 个评价区段,分别为好、较好、一般、差,再对各区段内的节点进行评分。各项定量指标评价区段的划分标准如表2 所示。
1.2.4 计算各项指标得分和综合得分
确定客流节点因素集U,按聚类因素分为 4 个子集:客运需求U1、路网属性U2、客运能力U3、社会属性U4。各子集Ui={ Ui1,Ui2,…,Uin}。
对每个子集 Ui进行二级评价,Ui的单要素测评矩阵为Ri=(rij)mm,其中,rij为 Ui子集中指标 j 的评价得分。构造二级判断矩阵得到评价指标权重 Wi,二级评价结果为:

表1 定性指标评价标准
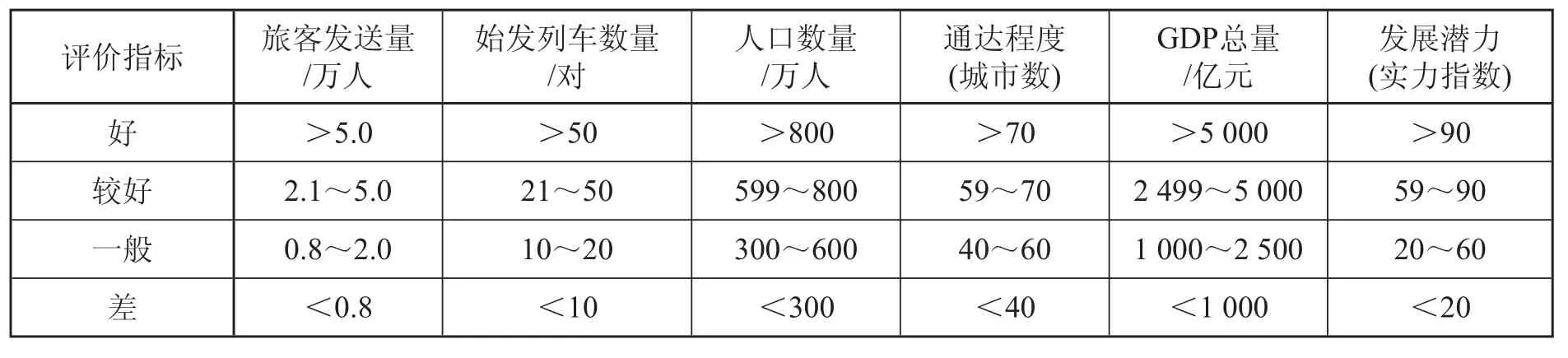
表2 定量指标评价标准
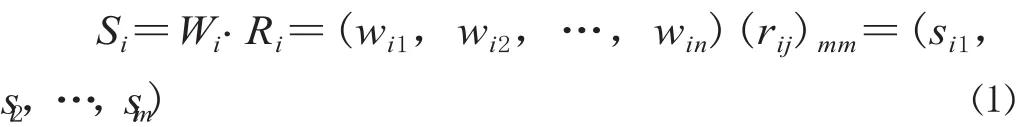
再将每个子集Ui当作一个指标,用 Si作为单因素矩阵,进行一级综合评价。构造一级判断矩阵的各因素子集权重W,一级综合评价结果为:
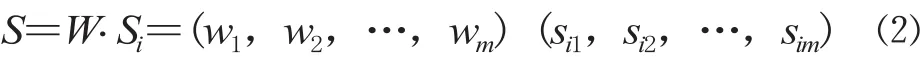
1.3 客流节点K-均值聚类统计
K-均值聚类算法是一种在无类标号数据中发现簇和簇中心的方法。以综合评价得分为依据,对 N 个数据对象给出 K 个划分,通过迭代把数据对象划分到不同的簇中,使簇内部之间对象的相似性很大,而簇之间对象的相似性很小,相似的计算根据一个簇中对象的平均值进行。给定一个含有N个数据对象的数据库,以及要生成的簇的数目K,随即选取 K 个对象作为初始的 K 个聚类中心,然后计算剩余各个样本到每一个聚类中心的距离,把该样本归到离其最近的那个聚类中心所在的类,对调整后的新类使用平均值的方法计算新的聚类中心,如果相邻两次的聚类中心没有任何变化,说明样本调整结束且聚类平均误差准则函数 E 已经收敛。
2 实例分析
以客运专线站点所在城市为对象,选择北京、上海、广州、天津、武汉、大连、济南、南京、郑州、合肥、西安、重庆、洛阳、衡阳等 40 个城市,进行聚类研究。
(1)对准则层因素进行两两比较,并按照1~9 比率标度进行打分,确定准则层因素相对于目标层因素的重要度,构造一级判断矩阵。同理,可得二级指标判断矩阵。

(2)按照归一法,对判断矩阵进行计算,求出其特征向量,即得到标准层的一级指标相对于目标层的权重W=[0.55,0.24,0.16,0.55]。同理,可得二级指标相对于一级指标的权重W1=[0.58,0.31,0.11],W2=[0.67,0.33],W4=[0.64,0.26,0.1]。
对一级指标特征向量进行一致性检验,先求出特征根 λmax=4.06,n=4。
CI=(4.06-n)/(n-1)=0.06/3=0.02,CR=CI/RI=0.02<0.1,故通过一致性检验。
同理,二级指标 4 个特征向量均通过一致性检验。
(3)根据客流节点所在城市的实际情况,按照指标评价标准,计算各城市的二级指标得分,并利用式 ⑴ 和式 ⑵ 计算所选城市的一级指标评价得分和综合评价得分。评价结果如表3 所示。
(4)依据评价得分,应用 SPSS 软件对所选城市的评价得分进行K—均值聚类运算,统计结果如表4 所示。
综合 SPSS 统计软件计算结果,结合铁路客运专线生产力布局规划,根据最终得分将客流节点所在城市划分为 4 类:①综合得分在 0.91~1.00 之间;②综合得分在 0.79~0.90 之间;③综合得分在0.70~0.78 之间;④综合得分低于 0.70。
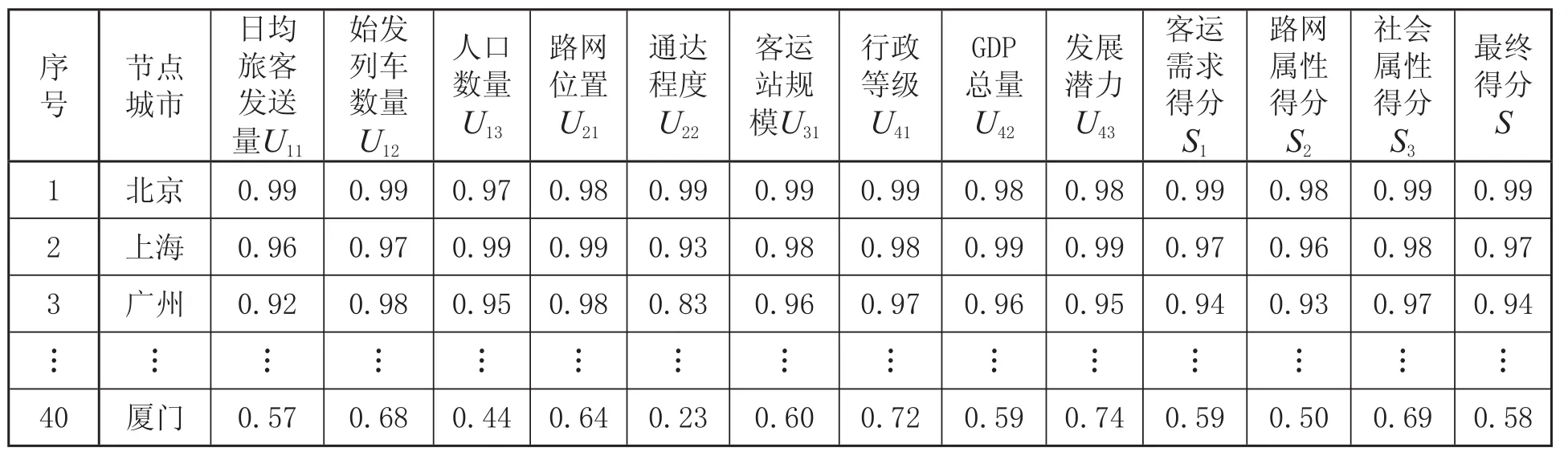
表3 客流节点指标综合评分结果

表4 客流节点得分聚类结果
3 聚类统计结果分析
由以上聚类统计结果可知,我国客运专线的客流节点所在城市的层次结构有以下 4 大类。
第一类包括北京、上海、广州、武汉等城市。这些城市一般位于铁路网中多条干线纵横交错的位置,同时担负着南北与东西通道的铁路运输任务,属于整个路网的神经中枢。同时,此类客流节点多位于人口规模较大、经济高度发达的中心城市,对全国政治、经济、文化的发展有至关重要的影响。另外,此类节点城市还是最重要的始发终到站点,其始发终到客流占有很大的比例。
第二类包括西安、成都、济南、沈阳等城市。这些城市一般位于几条铁路主干道的交叉处,同时也是区域内多条次要通道的汇集中心,在客运专线网中起到承上启下的中转过渡功能。这些城市多为省会城市,人口集中、经济较发达,与周边地区和城市有着密切联系,对区域经济的形成和发展有举足轻重的影响。该类节点客流呈现多样性,流向较为分散,跨线客流所占比例较大。
第三类包括大连、太原、兰州、合肥等城市。这些城市一般位于客运专线各条干道尽端或通过之处,属于区域内交通的必要节点,主要完成区域内相应地方性节点间的联络,并为上层区域输送客源。此类城市的人口规模和经济水平均为中上水平,人口出行数量和方向较为稳定。这些节点的运输组织以中短途客流为主,主要开行区域列车。
第四类包括唐山、温州、新乡、信阳等城市。此类城市多属于直达列车的停站服务范围,在路网中不具有突出的地位,客流吸引和集散能力较弱。
4 结束语
采用层次分析法对客流节点进行综合评价,选取具有代表性的评价指标,合理统一量纲,对客流节点的评价得分进行K-均值聚类分析,能方便且较准确地得出聚类结果,有助于铁路客运部门准确把握客流节点的重要性,对制定列车开行方案和运输组织工作具有一定的指导意义。
[1]任若思,王惠文. 多元统计数据分析——理论、方法、实例[M]. 北京:国防工业出版社,1997.
[2]李永文. 关于铁路旅客满意度的调查分析[J]. 铁道经济研究,2002 (5):33-35.
[3]王志华,赵 冬,余永华. 基于模糊 C 均值聚类的柴油机故障诊断[J]. 船海工程,2007 (4):56-57.
[4]戴 宾. 改革开放以来四川区域发展战略的回顾与思考[J].经济体制改革,2009 (1):140-142.
[5]李永文. 关于铁路旅客满意度的调查分析[J]. 铁道经济研究,2002 (5):33-35.
猜你喜欢
环球时报(2022-12-12)2022-12-12
科学家(2021年24期)2021-04-25
中国建材科技(2020年6期)2020-03-23
铁道通信信号(2019年6期)2019-10-08
科技经济市场(2017年5期)2017-09-16
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
河北工业大学学报(2016年6期)2016-04-16
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
智能系统学报(2015年4期)2015-12-27
