
中文网络资源备份保存的调查与思考
2010-06-14 08:28朱天慧曲阜师范大学图书馆山东曲阜273165
图书馆理论与实践 2010年7期
●朱天慧(曲阜师范大学 图书馆,山东 曲阜 273165)
随着信息技术的飞速发展,网络资源正逐渐成为使用最多最频繁的信息资源。在这浩瀚的信息海洋中,有95%的Web信息是可以公开获取的,其容量比美国国会图书馆的馆藏量还多出50倍。然而,Web信息的存在又是短暂的,美国数字信息基础架构和保存项目的报告中指出网络信息的平均寿命为44天。中国互联网中心2009年1月的调查数据表明,中文网页的更新周期在6个月以内者占80%,[1]可见网络信息资源更新频率相当高。因此,网络信息资源的长期保存已经成为一个刻不容缓的问题。近10年来,国内有关网络资源备份保存方面的研究论文呈逐年递增趋势,从研究的内容看,主要侧重于介绍国外网络资源备份保存项目以及元数据、技术、管理策略、法律法规等方面的研究,但从用户消费利用的角度对网络资源备份保存进行的研究尚不多见。本文基于国内网站被InternetArchive和WebInfomall备份保存的情况进行调查研究,揭示网络资源保存面临的几个主要问题,并提出了相关建议。
1 网络资源备份保存概述
1.1 何谓网络资源备份保存
网络资源备份保存(Web Preservation或Web Archiving)就是将网络资源定期存档备份并整理编目,以供使用者查询过去的网站或网页信息。从20世纪90年代开始,许多国家就开始积极探索网络资源的保存问题,并提出了多种解决方案,如澳大利亚国家图书馆启动的PANDORA项目、挪威的Paradigma项目、瑞典的Kulturarw项目、欧洲的NEDLIB计划、美国的互联网档案馆、美国国会图书馆的NDIIP项目等。[2]进入21世纪后,我国也启动几个保存网络信息资源的项目,如国家图书馆“网络信息资源保存”实验项目(WICP)和“中国Web信息博物馆(Web Infomall),其中后者已经初具规模。
1.2 Internet Archive的功能与特点
互联网档案(Internet Archive)是美国旧金山的一个非赢利组织,创立于1996年,其创立的目的是为收集所有可以公开检索到的网络信息并构建一个网络图书馆。该网站的数据来源多由该网站自行搜寻保存,也有来自于其他典藏机构寄存的信息。2003年,InternetArchive将所备份保存的资料全部寄存一份给埃及的亚历山大图书馆(LibraryofAlexandria),建立了一个镜像站点。InternetArchive的搜集备份保存政策是限定edu、gov、org等域名为搜集范围,并选择性地收集一些com网站信息,另外该网站还收费性地接受个人网站的备份申请。InternetArchive保存的网络资源类型除了网页档案外,还包括文字数据、影音数据、动画、软件等。Internet Archive通过WayBack Machine提供对历史网页的记录存储,向研究者和普通公众提供免费访问,允许人们通过网页地址进行查询,[3]网址是 http://www.archive.org/index.php。
1.3 WebInfomall的功能与特点
中国Web信息博物馆是在国家973和985项目支持下,由北京大学网络实验室开发建设的中国网页历史信息存储与展示系统,是目前全国最大、最完整的互联网内容信息收集与仓储中心。WebInfomall的基本使命是以一种集中的形式,全面展现中国互联网上信息的历史;为社会提供多种海量网络信息产品,供相关科研人员进行研究。作为一项服务社会的公益事业,可以查找网页存档情况以及网页链入和链出等信息。借助“天网中英文网页和文件搜索引擎”,该系统目前已经维护有2002年1月以来30亿个以中文为主的网页,而且以每天100—200万网页的速度不断增加,并以平均每月4500万个网页的速度扩大规模。这些网页不仅来源于不同的URL,而且还包含同一个URL的不同内容版本,其中许多内容目前在中国互联网上已经不复存在。人们通过HisTrace实验性系统框架从WebInfomall中尽量准确、完整地提取与重要历史事件相关的网络新闻报道,并按照报道发生的时间顺序将它们不重复地展示出来,[4]其网址是http://www.infomall.cn/。
2 国内网站备份保存情况的调查
为了解国内网站的备份保存情况,笔者选择了104个国内网站(域名为 .edu的有75个、.gov的有17个、.org的有7个以及.com的有5个),分别在InternetArchive和WebInfomall两个系统中检索了各类网站主页的保存情况,检索日期为2008年12月13日—14日),记录各网页保存的起止日期,存档次数以及网站的自我更新次数,并对结果进行统计分析,见下表。
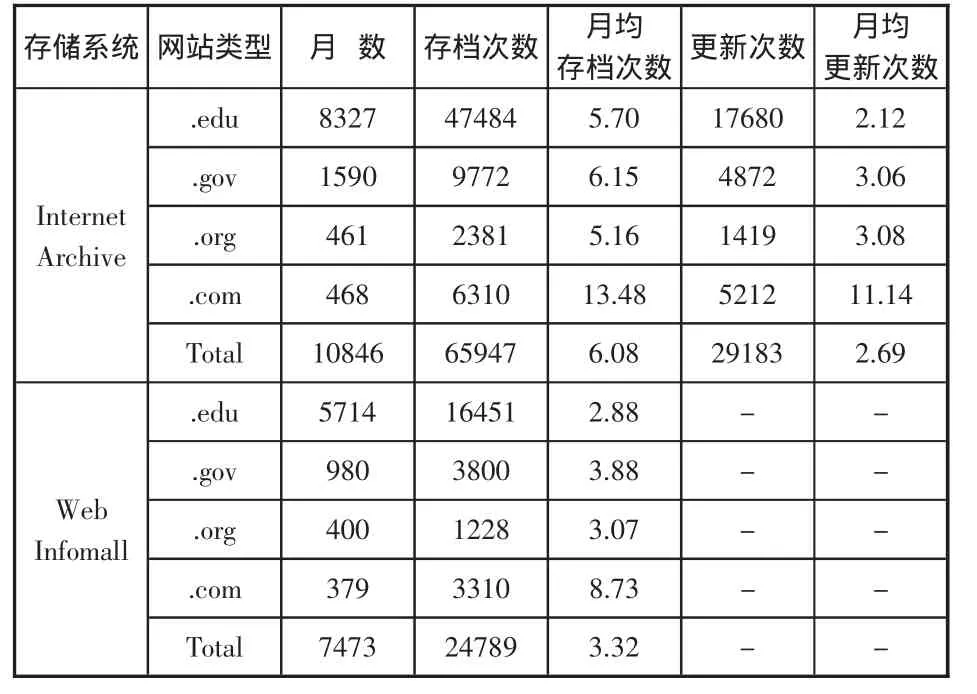
表 部分国内网站的备份保存情况统计
由上表可见,104个国内中文网站分别被存档65947次和24789次,平均每个网站每个月的被存档次数分别是6.98次和3.32次,显示出两个系统在保存数量上存在较大的差异。此外,不同域名类型网站被存盘备份的频率以.com类为最高,其余类型网站则相差不多。
除了在收录网页数量上的差异外,Internet Archive和Web Infomall之间还存在一些明显的差别,比如两个系统分别自不同时期开始进行备份保存,前者备份保存时间范围从1996年12月至2008年2月,而后者的时间范围为2002年1月到2008年12月。显示出InternetArchive备份网页的历史早于WebInfomall,但在从存盘后到可提供检索旧网页之间,至少有10个月的滞后期;而WebInfomall中没有显示出这种滞后性。另外,在InternetArchive的查询结果中,可以显示网页备份起止日期、起止日期之间的备份存档次数及更新次数等;而在Web Infomall中没有显示出更新次数。
3 结论与建议
3.1 构建分工协作的保存体系是网络资源备份保存的必然要求
网络信息资源的保存是一项系统工程,涉及政府、新闻出版、教育、科技、文献收藏等部门和单位,因此,充分运用现代信息技术,采取分工协作的机制是构建适合我国国情的网络资源备份保存体系的必由之路。笔者认为,以国家宏观管理层面为指导,构建以国家图书馆为核心,联合其他组织和机构建立分布式保存体系是目前较理想的选择。该体系的建立有助于资金的统筹及人员的协调,有利于全面、经济、合法、有效地实施对网络资源的长期保存。InternetArchive虽然不是由美国国会图书馆牵头实施的,但它与众多学术机构与纪念馆建立了合作关系,比如,其网络档案主管MicheleKimpton致力于国际互联网备份保存协会筹备,并提出了Internet Archive联盟的构想,即由国家图书馆负责网络资源备份保存的选择标准制定、收集和提供检索,Internet Archive负责技术上的支持以及研发新的工具。[5]因此,借鉴其做法,加强与各个部门之间的分工协作,也应该是今后WebInfomall发展的主要方向。
3.2 完善基于用户需求的采集策略是网络资源备份保存的前提条件
资源收集与保存的最终目的是为当前与未来用户群体提供服务。对InternetArchive资源的选择性评价结果表明,网络资源保存应该以特定用户群体为中心来进行。[6]因此,掌握和了解当前用户的需求,预测未来用户的需求与信息行为,是完善网络资源备份保存的必要前提。
Web资源的备份保存,除了选择合适的采集方式外,还要确定合理的采集频率。由于各个网页的更新频率不同,因此必须基于中文网络信息资源的种类与特点,探索合适的采集频率,否则就可能遗漏很多重要信息。采集频率需要针对不同性质的网站、不同内容信息的网页来确定,对于一般稳定性的或内容积累性的网站,每半年采集一次较为合适,动态性较强的网站则应该进行跟踪采集。
3.3 开展国际合作是网络资源备份保存的现实需要
美国InternetArchive于1996年开始对包括我国网络信息资源在内的全球网络信息进行批量收集,他们搜集和保存了我国官方网站的大量信息,甚至包含许多我们现在已经无法找到和再现的信息。Internet Archive起步早,其备份中文网页的历史远早于Web Infomall。调查还显示:Internet Archive对中文网页的月均存档次数也远高于WebInfomall。因此,如果能够与之建立合作关系,利用其过去备份保存的国内网络资源,就可以更完整地建立我国网络资源典藏体系。另外,加强与国外同行的合作,充分借鉴其经验、管理模式和先进的技术,可促进我国网络学术信息保存工作的发展。
3.4 纳入相关教育体系是网络资源备份保存的坚强后盾
目前Web资源备份保存面临着人员和技术两大“瓶颈”。就人员方面讲,网络资源在备份保存后还需要自动和/或人工编目,尤其是后期的数据检索和开发等,这些都需要具有相关专业技能的人员广泛参与,在网络时代,只有具备网络信息技术与信息组织才能的人员,才能圆满完成这些任务。美国学者WilliamY.Arms提出网络资源备份保存是图书馆学与信息科学之间的新领域(Librarianship in a New Domain)。随着图书馆事业的迅速发展和信息技术的广泛应用,图书情报学和信息学教育应该与时俱进,不断调整和改进课程设置,对教学方式和内容进行改革,增加新兴学科和现代科技的比重,如将网络资源备份保存的策略和技术等内容列入相关课程之中,为网络资源备份保存的实施提供充分的人力资源后盾。
[1]第23次中国互联网络发展状况统计报告[EB/OL].[2009-12-20].http://www.cnnic.cn/index/0E/00/11/index.htm.
[2]李晓明.Web InfoMall:过去、现在与将来[EB/OL].[2009-12-20].http://www.hainu.edu.cn/sewm2007/20070310SEWM.pdf.
[3]Internet Archive[EB/OL].[2009-12-20].http://www.archive.org/index.php.
[4]中文 Web 信息博物馆 [EB/OL].[2009-12-20].http://www.infomall.cn/.
[5]Internet Archive:Bios[EB/OL].[2009-11-02].http://www.archive.org/about/bios.php.
[6]赵俊玲.国外关于网络信息资源保存的研究[J].中国图书馆学报,2004(5):80-83.
猜你喜欢
恋爱婚姻家庭(2023年1期)2023-02-15
海洋信息技术与应用(2022年1期)2022-06-05
成都信息工程大学学报(2021年6期)2021-02-12
网络安全和信息化(2020年1期)2020-01-15
语言与文化论坛(2019年4期)2019-03-29
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2017年2期)2017-05-17
太空探索(2016年10期)2016-07-10
中国教育技术装备(2016年15期)2016-03-01
