
Windows系统缓冲区溢出研究
2010-06-12 08:55吴雪阳樊龙陈晶波
网络安全技术与应用 2010年12期
吴雪阳 樊龙 陈晶波
中国人民解放军78046部队 四川 610011
0 引言
近二十年来,缓冲区溢出漏洞已成为计算机系统安全漏洞的主要形式之一,利用缓冲区溢出漏洞进行的攻击占了远程网络攻击的绝大多数,这种攻击可以使一个匿名网络用户有机会获得一台主机的部分或全部控制权,可以使蠕虫病毒进行迅速高效的传播,是一种极其严重的安全威胁。
缓冲区溢出攻击之所以成为一种常见的安全攻击手段,主要原因在于,存在缓冲区溢出漏洞的系统和软件非常普遍,且一旦漏洞被成功利用,被攻击者植入的攻击代码将获得与目标程序相同的系统权限,从而得到被攻击主机的控制权。
2 缓冲区溢出原理
2.1 进程在内存中的映像
各函数的栈帧大小随着函数中局部变量的不同而不等。
(2)进程对内存的动态申请发生在Heap(堆)里,随着系统动态分配给进程的内存数量的增加,Heap(堆)有可能向高址或低址延伸,取决于不同系统的实现,通常是向内存的高址方向增长。
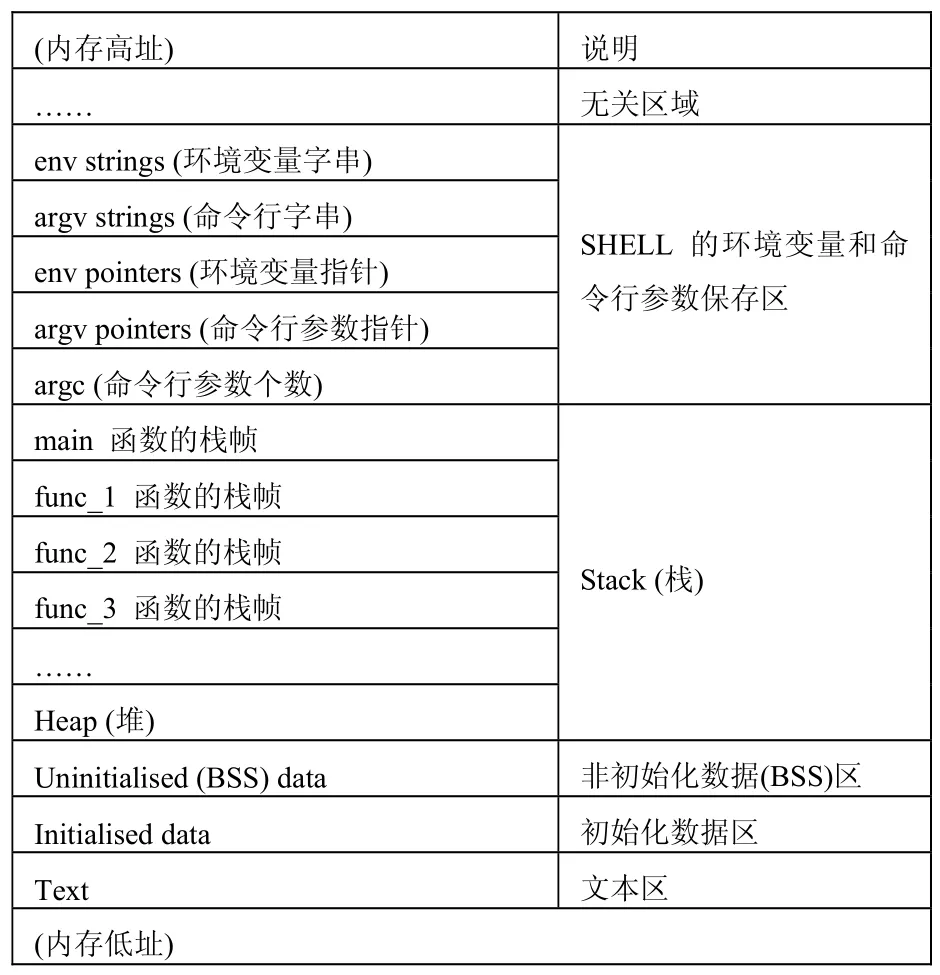
图1 进程在内存中的映像
假设有一个程序,它的函数调用顺序如下:
main(...) -> func_1(...) -> func_2(...) -> func_3(...)
即:主函数main调用函数func_1;func_1调用func_2;func_2调用func_3。当程序被操作系统调入内存运行,其对应的进程在内存中的映像如图1所示。
需要说明的是:
(1)随着进程中函数调用层数的增加,函数栈帧是逐块向内存低址方向延伸的;随着函数调用层数的减少,各函数调用的返回,栈帧会逐块被释放而向内存的高址方向回缩,
(3)当BSS数据或Stack(栈)的增长耗尽了系统分配给进程的自由内存时,进程将会被阻塞,重新被操作系统使用更大的内存模块来调度运行。
(4)非初始化数据(BSS)区用于存放程序的静态变量,这部分内存都被初始化为零;初始化数据区用于存放可执行文件里的初始化数据。这两个区统称为数据区。
(5)Text(文本区)是个只读区,任何尝试对该区的写操作都将导致段违法出错,文本区被多个运行该可执行文件的进程所共享,用于存放程序的代码。
2.2 函数的栈帧
函数调用时建立的栈帧包含了下面的信息:
(1)函数的返回地址:返回地址是存放在父函数的栈帧还是子函数的栈帧里,取决于不同系统的实现,Windows系统是放在父函数的栈帧里;
(2)调用函数的栈帧信息,即栈顶和栈底;
(3)为函数的局部变量分配的空间;
(4)为被调用函数的参数分配的空间。
2.3 缓冲区溢出
从函数的栈帧结构可以看出:函数局部变量的内存分配发生在栈帧里,如果在某个函数里定义了缓冲区变量,则这个缓冲区变量所占用的内存空间就在该函数被调用时所建立的栈帧里。由于对缓冲区的潜在操作(如字串的复制)都是从内存低址到高址,而内存中函数调用的返回地址就在该缓冲区的上方(高地址)——这是由栈的特性决定的,这就为覆盖函数的返回地址提供了条件。当有机会用大于目标缓冲区的内容来向缓冲区进行填充时,就有可能改写保存在函数栈帧中的返回地址,使程序的执行流程发生转移,进而执行预先准备好的代码。下面是缓冲区溢出的示例:
(1)函数对字符串缓冲区的操作,方向一般都是从内存低址向高址的,如:strcpy(s,"AAA.....")。

(2)函数返回地址的复盖。


注:字符A的十六进制ASCII码值为0x41。
(3)从上图可以看出:如果用进程可以访问的某个地址,而不是 0x41414141来改写调用函数的返回地址,且该地址正好是准备好的代码的入口,则进程就会执行这些代码。在Windows操作系统中,由于有地址冲突检测机制,出错时能调试查看寄存器映像和堆栈映像,使得对缓冲区溢出漏洞可以进行精确的分析,确定溢出偏移地址,也便于攻击者寻找缓冲区溢出漏洞。
3 Windows系统缓冲区溢出的利用
假设已经准备好了溢出后执行的基本shellcode代码,针对Windows系统缓冲区溢出的特殊性,还须解决如下问题:
(1)正确构造溢出字符串
前面已指出,随着进程中函数调用层数的减少,栈帧会逐块被释放而向内存的高址方向回缩。在Windows系统中,系统会用随机数据填充废弃不用的堆栈空间,因此必须用下面的方式精确构造溢出字符串,确保溢出后的shellcode不会被随机数据覆盖:
…NNNNNNNNNNNASSSSSSSSS…
其中,N为NOP指令,用于溢出占位;A为跳转指令,使执行流程跳转到shellcode,后面会分析确定A的具体内容;S为shellcode代码。在缓冲区溢出发生之后,堆栈的布局如下:
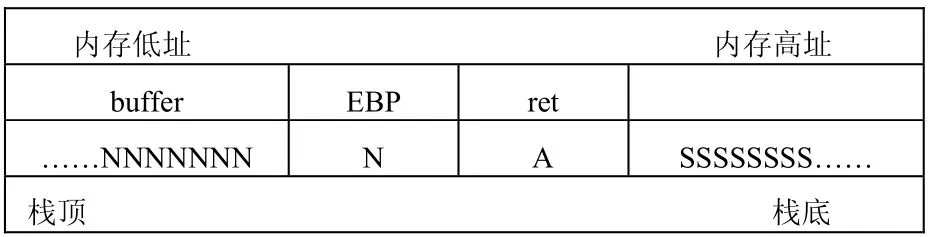
即A覆盖了返回地址,S位于父函数栈帧的顶部,A的内容,就是指向S的调用。后面会分析如何准确设置A的具体内容。
我们知道,Windows系统的用户进程空间是0—2G,操作系统所占的是 2—4G,用户进程的加载位置为:0x00400000。用户进程的所有指令地址、数据地址和堆栈指针都会含有�x0字符,因此不管A中的跳转地址如何设定,也必然含有�x0字符,而�x0字符恰好也是字符串结束的标志。这样就会导致前面的溢出字符串在A处就被�x0阻断了,根本无法将shellcode植入进程。此外,shellcode中本身也可能存在�x0字符,也会影响其植入。这就需要对溢出字符串进行编码处理,处理掉所有不能在shellcode中出现的“�x0”字符,然后在基本的shellcode代码执行前,再由一个子程序对其解码。一种可行的编码方式是对溢出字符串进行 xor 0x99处理,用同样的程序即可完成解码过程。编解码程序如下:
0xb1,0xc6,/* mov cl, C6*/
0x8b,0xc7,/* mov eax, edi*/
/*Xorshellcode */
0x48,/* dec eax*/
0x80,0x30,0x99,/* xor byte ptr [eax],99*/
0xe2,0xfa,/* loop Xorshellcode*/
(2)正确设置跳转指令地址
根据前面的分析可以知道,函数返回的时候,esp(栈顶寄存器)指向的地址,就是缓冲区溢出后 shellcode的开始位置。因此函数返回后如果立即执行jmp esp指令就可以使程序执行流程跳转到shellcode上来。要实现这一点,可以把上述溢出字符串中A的内容设为内存中一个已存在的jmp esp指令地址即可。一个Windows程序运行时,内存中很多动态链接库(dll)都会有jmp esp指令,出于通用性的考虑,可以选择kernel32.dll里面的指令,因为kernel32.dll是系统核心的dll,这些 dll一直位于内存中,而且对应于固定版本的Windows其加载的位置是固定的。不同的 Windows系统版本,kernel32.dll中jmp esp指令地址不同:
win98第二版下(4.00.2222a),地址为:0xbff795a3
winnt4下(4.00.1381),地址为:0x77f0eac3
win2000下(5.00.2195),地址为:0x77e2e32a
等等。
以这种方式设置跳转指令地址,需要预先知道目标操作系统版本,否则jmp esp地址如果不对,目标程序就会跳出“无效页错误”对话框并退出运行。
(3)正确加载shellcode中的系统函数
实现具备一定功能的shellcode,通常会调用一些基本的win32系统函数,如 ReadFile、CreateProcess等,但这些函数必须加载到目标程序的进程空间后才能被使用。如何才能实现这一点呢?可以考虑使用 win32系统函数 LoadLibrary来加载相应的动态链接库,用GetProcAddress来获得所需函数的地址。在shellcode里面可以包含一个函数名表,保存每一个需调用函数的函数名,并在shellcode执行前,使用上述两个函数逐个获得这些函数的地址即可。
这个办法还必须解决一个问题,即 LoadLibrary和GetProcAddress本身如何加载并获得调用地址?研究一下这两个函数的作用可以知道,每一个win32程序都需要用它们来取得所有其他函数的地址。因此可以断定,目标程序肯定会加载这两个函数。接下来需要解决的是如何找到这两个函数在目标程序里面的加载地址,它们是否会根据操作系统的不同而变化的呢?答案是否定的,这些动态加载的函数在目标程序里设置了一个入口表,由目标程序自己加载,且该入口表地址是固定的,不会因操作系统不同而变化。这样,就可以使用 wdasm32之类的工具来搜索目标程序中的LoadLibrary和GetProcAddress,得到它们对应的入口表地址,假设为AAAA。在shellcode里面,就可以直接用call [AAAA]指令来调用了。
4 缓冲区溢出的保护方法
有四种基本的方法可保护程序免受缓冲区溢出攻击:
(1)编写正确的代码
编写正确的代码是很有意义但耗时耗力的工作,特别是使用C语言这类容易出错的编程语言,程序员往往追求性能而忽视代码的正确性和安全性。包括很多版本的C标准库都存在缓冲区溢出漏洞。尽管目前已有了很多指导性的意见和规范来指导程序员编写安全的程序,但具有安全漏洞的程序仍然不断出现。除了要求程序员尽可能编写正确的代码外,目前已出现了一些专门的工具来帮助程序员检查代码中存在的安全隐患,这些工具可以通过人为随机地产生一些缓冲区溢出来寻找代码的安全漏洞。一些静态分析工具也可以用于侦测缓冲区溢出的存在。
(2)使用非执行的缓冲区
通过使目标程序的数据段地址空间不可执行,使攻击者即使向缓冲区植入代码也不可能被执行,这种技术被称为非执行的缓冲区技术。很多老的 Unix系统都是这样设计的,但后来的Unix和MS Windows系统为了实现更好的性能和功能,往往在数据段中动态地放入可执行的代码。为了保持程序的兼容性,不大可能使所有程序的数据段不可执行,但可以设定堆栈数据段不可执行,因为任何合法的程序都不会在堆栈中存放代码,这样就可以最大限度地保证程序的安全。目前,Linux和 Solaris都发布了这方面的内核补丁,Windows Vista也增加了类似的内存保护机制。
(3)进行数组边界检查
与使用非执行的缓冲区保护不同,数组边界检查完全防止了缓冲区溢出的产生和攻击。只要数组不能被溢出,溢出攻击也就无从谈起。为了实现数组边界检查,所有对数组的读写操作都应被检查,以确保对数组的操作在正确的范围内。最直接的方法是检查所有的数组操作,但是通常可以采用一些优化的技术来减少检查的次数。常见的实现数组边界检查方法包括编译器检查、存储器存取检查、使用类型安全语言等。
(4)程序指针完整性检查
程序指针完整性检查和边界检查略微不同,程序指针完整性检查在程序指针被引用之前检测它的改变。因此,即使攻击者成功地改变了程序的指针,由于系统事先检测到了指针的改变,因此这个指针将不会被使用。实现程序指针完整性检查需要操作系统或程序编译器的支持。
5 结论
本文中,我们详细描述和分析了缓冲区溢出的原理和Windows系统中利用缓冲区溢出漏洞需要解决的技术难点,并总结了缓冲区溢出保护的基本方法。由于缓冲区溢出攻击是目前出现频繁、危害极大的攻击手段,进行这方面的研究工作对于了解系统弱点、掌握攻击手段、有针对性地进行安全防护都具有积极意义。研究结果表明,对于Windows下存在缓冲区溢出漏洞的程序,需要采用适当的技术和技巧才能加以利用,同时也使Windows系统的安全防护面临挑战。
[1]Randal E.Bryant.David O'Hallaron. Computer Systems: A Programmer’s Perspective.中国电力出版社.2004.
[2]Foster,J.C.缓冲区溢出攻击—检测、剖析与预防.清华大学出版社.2006.
[2]许治坤.网络渗透技术.电子工业出版社.2005.
[3]黑猫(virtualcat@hotmail.com).如何编写自己的缓冲区溢出利用程序.2001.
[4]ipxodi(ipxodi@263.net). Windows系统下的堆栈溢出. 绿盟月刊.2000.
[5]David A.Wheeler.安全编程:防止缓冲区溢出.IBM developer Works.2004.
猜你喜欢
中国外汇(2019年20期)2019-11-25
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
中国外汇(2019年8期)2019-07-13
沈阳工业大学学报(2018年1期)2018-01-08
中国工程机械学报(2016年5期)2016-03-07
电脑爱好者(2015年21期)2015-09-10
项目管理技术(2015年3期)2015-04-23
时代人物(2014年10期)2015-01-28
民主与科学(2014年3期)2014-02-28
