
陪护机器人口语对话系统设计与实现
2010-06-12 08:55郭书杰黄明梁旭
网络安全技术与应用 2010年12期
郭书杰 黄明 梁旭
1大连交通大学机械工程学院 辽宁 116028 2 91550部队 辽宁 116023 3大连交通大学软件学院 辽宁 116028
0 引言
口语对话系统是一种通过自然语言同人进行交流的智能人机交互系统,它的目标是让用户能和机器进行自然和智能的对话。根据系统/用户在对话中的主动程度,口语对话系统基本上可以分为以下三类:①系统主导:系统完全控制对话流程,通常由系统主动向用户询问,要求用户回答给定的问题。系统主导方式只允许用户在非常有限的时候主控对话流程,如重新开始对话,求助等。由于严格限制了用户的动作,任务完成率通常比较高,但对话过程不够自然和人性化。②用户主导:在用户主导的系统中,用户可以随意对系统发问,而系统则只在必要的时候要求用户澄清。这样,用户具有很大的自由度。但是,从另一个方面来讲,用户往往不清楚系统的能力,因此容易造成“离题万里”的情况,使得任务完成率往往比较低下。③ 混和主导:混合主导模式则是对前两种方式的折衷:用户和系统都能控制对话流。通常用户可以主动提供查询所需要的信息、否定或纠正前面的话语等,而系统也可以主动发问,如要求确认信息、询问更详细的信息等。
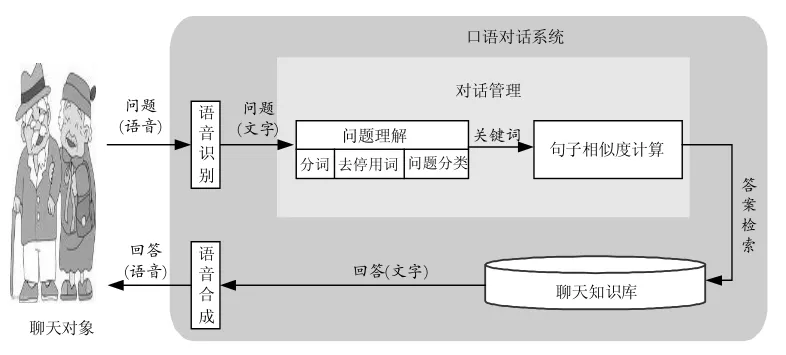
图1 典型的口语对话系统
通常,口语对话系统都含有一个对话知识库以及一个对话管理模块,对话知识库就像口语对话系统的大脑,它存储着用于回答用户问题的对话知识;而对话管理模块则用于控制对话进程。一般来说,一个典型的口语对话系统由语音识别、对话管理、语音合成等三个模块组成,如图1所示。
1 设计与实现
陪护机器人口语对话系统的难点有两个。首先,口语对话系统希望人机交互的过程尽量模拟真实的聊天过程,从而使得对话过程更加自然和更具人性化,这就要求机器人和陪护对象之间能够就一些话题展开多个回合的交流,而不是像一般的问答系统一样,只是单纯的“一问一答”。其次,口语对话系统要求必须在较短的时间内对用户的问话做出反应,然而由于受到成本的限制,陪护机器人核心控制器的各种硬件性能又不太好,这就要求系统具有较高的效率。为了较好地解决这两个难点,陪护机器人口语对话系统设计了一套知识库组织规则、简化了句子相似度计算方法并以此为基础设计了一套简单高效的答案检索方法。
1.1 对话知识库的设计
为了能够尽可能真实地模拟人与人的聊天,使得人机交互的过程自然流畅,我们设计了一套格式,用于将对话知识存放到xml文件中,我们称这些xml文件为知识文件。陪护机器人口语对话系统的知识文件中的知识有两种:一种叫QandAKnowledge,适用于陪护对象主导聊天过程的情况,如图2所示;另一种叫HostKnowledge,适用于机器人主导个<question>项,表示聊天对象的一个问题;<answer>项表示针对该问题的回答;该问题的所有子问题及其回答都存放在<subQuestions>项中。在 HostKnowledge中,每个<topic>项,表示聊天话题;<talk>表示机器人针对该话题的提问;该话题的所有子问题及其回答都存放在<subQuestions>项中。这样设计可以方便知识文件中各条知识的读取与管理,简化答案检索,提高答案检索效率与查准率。

图2 QandAKnowledge样例

图3 HostKnowledge样例
1.2 句子相似度计算
汉语句子就是一个字符串,是由一组不同含义的单词组成,由于字符串的特殊性,很难用一个特定的数值来确定它的大小或位置,所以如何描述两个字符串之间的距离,也就是如何计算两个句子的相似度就成为了一个值得探讨的问题。
句子相似度的计算方法比较多:周法国等提出了一种句子及时相似度的新方法,该方法通过融合句子的词形相似度、词序相似度、句长相似度和距离相似度等信息来计算句子的相似度;裴婧等通过对不同关键词加权的方法对常用的句子相似度方法做了改进;闰宏飞等提出了一种通过词汇在句子中出现的频率以及该词汇距离中心疑问词的距离来计方法:基于词特征的句子相似度计算,基于词义特征的句子相似度计算以及基于句法分析特征的句子相似度计算。赵妍妍等通过对比实验得出如下结论:对于相关领域内的句子相似度计算来说,词义特征起到了很大的作用,因为在相同的主题下,同义词出现的较多,所以基于词义特征的方法比较适合解决这种问题。
1.2.1 简化的基于词义特征的句子相似度计算
上述各参考文献中的句子相似度计算方法,都是通过融合句子的词形、句长、词序、距离等多种语法和语义信息来完成的。这样的计算方法有以下特点:①时间复杂度较高,需要进行大量复杂的运算;②这种多信息融合的方式,对查准率和召回率的改善并不是十分明显;③相似度的计算结果受到各个融合参数的直接影响,而这些融合参数通常是人为设定的,具有较强的主观性。由于陪护机器人硬件性能较弱,这些特点决定了这种计算方法不能够满足陪护机器人口语对话系统对响应时间的要求。由于在进行问题理解时,对问题进行了分类,所以聊天对象的问题和待检索知识库中的问题属于同一领域,根据赵妍妍等人的实验结论,结合陪护机器人口语对话系统的硬件性能及实际需求,我们将文献[7]中提到的基于词义特征的句子相似度计算方法进行简化,得到简化的词义特征句子相似度计算方法,并将其作为完成句子相似度的计算核心部分。简化的词义特征句子相似度计算方法如下:
假设句子A包含的词为A1、A2、 …、An,B包含的词为B1、B2、 …、Bm,定义Ai(1≤i≤m)和Bj(1≤j≤n)之间的相似度用; 令Nthesaurus=则句子A、B的词义距离相似度sim_SE
1.2.2 句长相似度计算
通过统计我们发现,由于分词和去停用词的原因,在日常对话常用句子中,经常会出现以下情况:假设去停用词后句子1包含的词为w1,句子2包含的词为w2;w1是w2的子集,但句子1和句子2并不同义,如图4所示。此时,如果仅使用简化的基于词义特征的方法来计算句子相似度,句子1和句子2的相似度会比较大。如果引入句长信息作为句子相似度计算时的参考量,就可以简单有效地将句子1和句子2区分开来。如果引入句长信息作为句子相似度计算时的参考量,就可以简单有效地将句子1和句子2区分开来。因此在计算句子相似度时,我们加入了句长特征作为辅助信息,来完成句子相似度的计算。
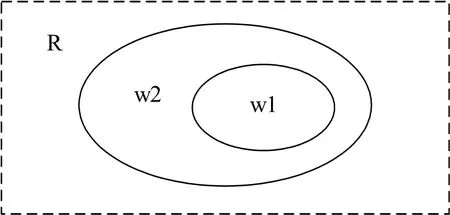
图4 w1是w2的子集的情况
设句子S的长度为句子中单词的个数,记为 ()LenS。则句子 A, B 的相似度 _simSL计算公式如下:
1.2.3 句子相似度计算
通过融合上述句子的词义特征和句长特征来计算句子的相似度,既可以提高答案检索时的查准率,又可以通过较简单的句长相似度计算来限制针对聊天对象问题的查找范围,从而提高答案检索的效率,降低对聊天对象问话的反应时间,使得系统更加人性化。句子相似度计算如下:
句子 A、B的相似度sim(A,B) =λ1*sim_SE(A,B)+λ2*sim_SL(A,B);其中:λ1∈ ( 0 ,1),λ2∈ ( 0 ,1),λ1+λ2=1,并且λ1>λ2。
1.3 答案检索
在系统初始化时,首先将知识库文件中每一个<question>项和<topic>项,通过一个递归函数将其中存放的知识读取到一棵二叉树中,图2对应的树如图5所示。
然后将这些二叉树分别保存到动态数组 ArrQAnd-AKnowledge和ArrTopicKnowledge中;将ArrQAndAKnowledge数组按照各个知识树“问题”字段关键词个数由少到多的顺序排序;为 ArrQAndAKnowledge数组按照“问题”的关键词个数的多少建立倒排索引表Table_words。然后将用于标识当前话题的指针pTopic设置为NULL。在进行答案检索时,如果pTopic等于NULL则根据聊天对象问话字符串中包含侧词语个数,通过查看 Table_words并结合句子相似度计算方法中对句长相似度计算的要求,将ArrQAndAKnowledge数组中的某一范围内的知识树的“问题”字段与聊天对象的问话进行句子相似度计算。假设得到的句子相似度分别为 eq1、eq2…eqn,并且最大相似度为eqi,其对应的知识树为Tree_A。如果eqi大于0.7,则将Tree_A的“答案”字段作为回答内容反馈给语音合成模块,同时将Tree_A赋给pTopic;否则在字符串“哦”、“是的”、“应该是”、“有可能”、“你说什么”中随机挑选一个字段作为回答内容反馈给语音合成模块,将pTopic设置为NULL,并将用户的问话记录到“未知问题”文件中。如果pTopic不等于NULL则计算pTopic的左子树和右子树的“问题”字段与聊天对象的问话的相似度eqLeft和eqRight;如果eqLeft和eqRight均小于0.3则将“看来你不想聊这个话题了,咱们换个话题吧”作为回答内容反馈给语音合成模块,否则将左右字数中“问题”字段与聊天对象的问话的相似度较大的那颗子树的“答案”字段作为回答内容反馈给语音合成模块,并将该字数赋给pTopic。在系统使用中,当持续 30秒钟未捕捉到聊天对象的问话输入时,或者连续出现三次无法找到答案的问话时,系统就会在ArrTopicKnowledge中随机选择一个聊天话题和聊天对象聊天。此时答案的检索过程与上述检索过程中 pTopic不等于NULL的情况类似,在此不做赘述。这种答案检索方法可以把某一话题内的答案检索范围限定在知识树中某结点的左右子树内,从而有效缩短了响应时间。
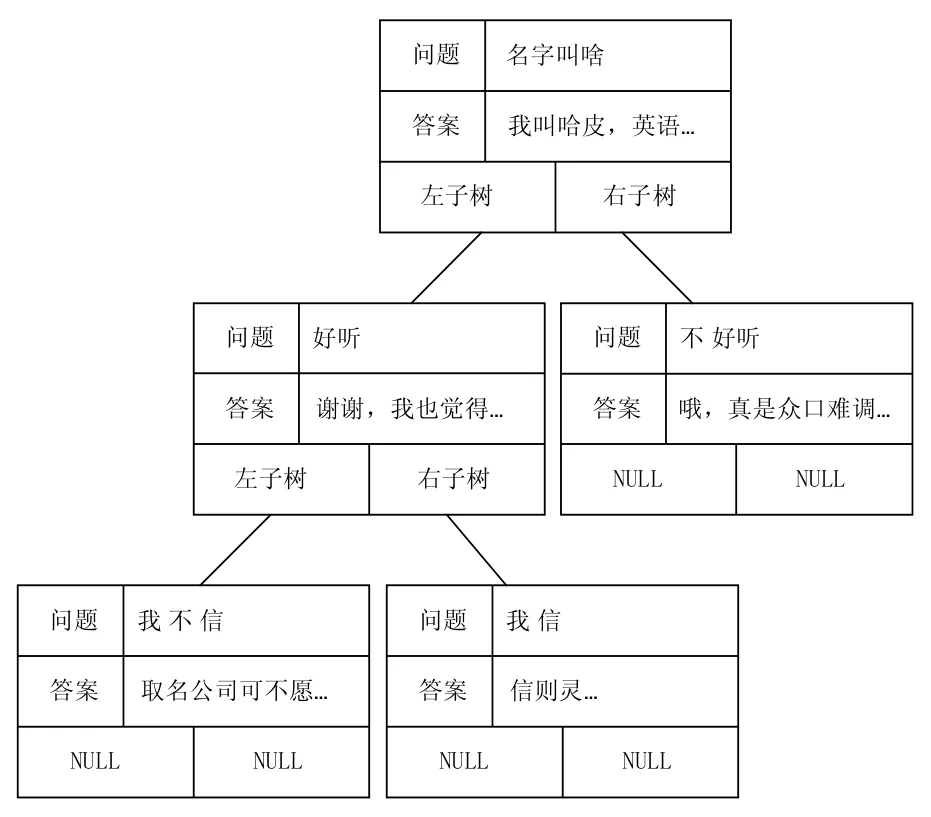
图5 一颗知识树
2 实验结果及分析
对 78个回合的聊天结果的统计分析显示,陪护机器人口语对话系统对话过程比较自然,系统能对多数的问话给出合理的回答。不能给出正确回答的原因主要有两个,一是语音识别模块识别错误,导致无法系统无法从聊天知识库中查找的正确答案;另外一个原因是聊天知识库中的话题还不够丰富,所以有些问题无法找到答案。系统能够通过不断提问的方式引导聊天对象就某一话题展开多个回合的交流,能够在需要时主动提出新的聊天话题或转移新话题,使得聊天过程具有较好的连续性。系统的平均响应时间为1.73秒,能够满足日常聊天的需求。
尽管系统较好的实现了围绕某些话题聊天、以较小的硬件代价完成快速的答案检索等功能,但是系统仍有以下两个待改进的地方:
(1)聊天知识库的构建需要人工完成,是一件费时费力的工作,并且缺乏灵活性,由此导致这种系统在应用到新的知识领域时,比较困难。
(2)系统只记录上一句聊天内容,这就无法从对话记录中提取更多的信息,在交互过程中体现出来,增加系统的智能性。
3 结论
与一般的职能问答系统不同,陪护机器人口语对话系统需要使对话的过程对话尽量自然流畅、有较好的连续性和趣味性、有较小的系统响应时间。由于受到成本的限制,陪护机器人核心控制器的处理器、内存的硬件性能又相对较弱。为了满足陪护机器人口语对话系统的要求,本文设计了一套以话题为单位的聊天机器人知识库构建规则。在使用中,将知识库文件中的知识读到一个个知识树中,把话题内的答案检索范围限定在知识树中某节点的左右子树内,从而有效缩短了响应时间;同时系统使用了简单有效的句子相似度计算方法和准确高效的答案检索模块,有效解决了以较小的硬件代价完成快速的答案检索的问题。
[1]吴尉林.可移植的稳健口语理解方法研究[D].上海交通大学.2007.
[2]王彬.汉语人机对话系统中口语处理的研究[D].清华大学.2004.
[3]黄际洲.聊天机器人知识库自动抽取算法的研究与实现[D].重庆大学.2006.
[4]周法国,杨炳儒.句子相似度计算新方法及在问答系统中的应用[J].计算机工程与应用.2008.
[5]裴婧,包宏.汉语句子相似度计算在 FAQ 中的应用[J].计算机工程.2009.
[6]闰宏飞,陈钟.词汇与中心词的距离信息对句子相似度的影响[J].清华大学学报(自然科学版).2005.
[7]赵妍妍,秦兵等.基于多特征融合的句子相似度计算[C].全国第八届计算语言学联合学术会议(JSCL-2005).2005.
猜你喜欢
制造技术与机床(2019年6期)2019-06-25
意林(2017年9期)2017-06-06
少年文艺·开心阅读作文(2017年4期)2017-04-07
中国交通信息化(2016年9期)2016-06-06
专利代理(2016年1期)2016-05-17
图书馆研究(2015年5期)2015-12-07
质量与标准化(2010年5期)2010-05-03
质量与标准化(2010年3期)2010-05-03
读写算·高年级(2009年3期)2009-11-16
青少年科技博览(中学版)(2006年4期)2006-04-14
