
基于FVSM的核聚类算法在文本聚类中的应用
2010-04-14 01:25杨延锟许少华大庆石油学院计算机与信息技术学院黑龙江大庆16331
长江大学学报(自科版) 2010年1期
杨延锟,许少华 (大庆石油学院计算机与信息技术学院,黑龙江大庆1 6331 8)
文本分类是文本信息处理的一个重要研究领域,对提高文本检索、文本存储等应用的处理效率有着重要意义[1,2]。如何提高文本分类器的识别率和推广能力是文本信息处理面临的问题。在传统的向量空间模型 (Vector Space Model,VSM)中,文本被简单地表示成向量,作为向量空间的一个点,然后通过计算向量间的距离决定向量类别的归属[3]。该模型的不足之处在于它一般不考虑向量中各个特征项在文档中的位置信息,而只是简单地根据词频统计公式获取特征向量,这使得距离的计算不够准确,从而导致分类精度不够高。针对传统VSM模型在文本特征表示方面的不足,笔者构造了基于文本特征的模糊向量空间模型 (Fuzzy Vector Space Model,FVSM),并利用Mercer核将文本的特征向量映射到高维特征空间,并在特征空间中进行聚类[4]。核聚类算法在性能上比经典的聚类算法有较大的改进,它通过非线形映射能够较好的分辨、提取并放大有用的特征,从而实现更为准确的聚类。同时,算法收敛速度较快,在经典聚类算法失效情况下也能得到正确的聚类。以中国期刊网全文数据库部分文档数据为例进行试验,试验结果表明了该文本自动聚类方法的有效性。
1 文本模糊核聚类算法
1.1 模糊特征向量的构造方法
构造特征向量首先要构造一个特征项集。一个有效的特征项集,必须具备以下2个特征:①完全性。特征项能够体现全部文档内容。②区分性。根据特征项集,能将目标同其他文档相区分。假设已经获得一个满足上述2个条件的特征项集。在文本特征向量的构造方面,传统VSM模型或者对特征项集采用二值 (0,1)编码,即特征向量是特征项的精确集合;或者对特征项集采用加权处理,以各特征项的权值构成特征向量,这虽然比二值编码前进了一步,但权值的计算一般只与各特征项在文档中出现的频数有关,这样部分高频特征项的权值很容易对某些频数过低的特征项权值产生一定的抑制作用,进而会影响聚类的效果。考虑到各个特征项在文档中的地位及重要性的不同,笔者在构造特征向量时采用了模糊集合方法,给予每个特征项一定的隶属度,即按其对反映主题的重要程度取 [0,1]区间值,构造模糊特征向量,这是符合实际情况的[5]。
设特征项集为{T1,T2,…,TN},特征项在某一文档中出现的频数采用模糊集合方法计算,则模糊特征向量可按如下原则构造[6]:
1)若特征项在原文中已被作者选为关键词 (如果有的话),应给予隶属度1;
2)若特征项在标题和摘要 (如果有的话)中出现,应给予较高的隶属度;
3)若特征项出现在正文中的一些 “关键句”,即那些包含诸如 “关键在于……”、“旨在……”、“主要目的 (标)是……”等的句子,应给予较大的隶属度;
4)若特征项出现在引言和结论段中,应给予一定的隶属度;
5)若特征项出现在段首或段尾,应给予一定的隶属度;
6)若特征项在正文中有较高的出现频度,应随着频度的增加逐次增加其隶属度;
7)若一个特征项同时处于上述多种地位,则其隶属度以求和方式迭加;
8)若一个特征项的同义词、近义词或转义词出现时,应根据其间的语义联系大小作为该特征项的一次或部分出现统计在出现频数中;
9)构造特征向量时还应考虑特征项的专指度。特征项的专指度可用文档总数与含有该特征项的文档数的比值表示。专指度过低的特征项会抑制聚类的精确性。因此对于专指度较高的特征项,应适当增加其文档频数;而对于专指度较低的特征项,则应适当减小其文档频数。
根据上述原则,模糊特征向量的构造步骤如下:
1)分别对P篇文档,按原则1)~8)计算特征项集{T1,T2,…,TN}中每个特征项的文档频数;
2)依原则9)按式(1)构造P篇文档的特征向量{fT(Tp1),fT(Tp2),…,fT(TpN)},(p=1,2,…,P)。

式中,VTFpk表示特征项Tk在文档p中的出现频数;N表示全部训练文本中的文档数;Nk表示含有特征项Tk的文档数目。
3)对以上特征向量归一化,可得P篇文档的模糊特征向量~Tp={Tp1,Tp2,…,TpN};(p=1,2,…,P)。
1.2 模糊核聚类算法基本原理
所谓的聚类就是已知一个数据项目集,将该集合划分成一个类集,使得类内相似性最大,类间相似性最小。聚类属于非监督模式识别问题,其特点是输入空间的样本没有期望输出。聚类的过程完全依赖于样本之间的特征差别。传统的聚类方法都没有对样本特征进行优化,而是直接利用样本特征进行聚类。这就使得聚类的有效性在很大程度上取决于样本的分布情况。例如一类样本散布较大,而另一类样本散布较小,传统的聚类方法效果就比较差。如果样本分布更加混乱,则聚类的结果就会面目全非。因此,对于文本聚类问题,笔者融合模糊向量的特征描述能力和核聚类方法强大的特征提取能力,提出模糊核聚类算法。首先,对文本特征进行模糊提取,构造了能够合理描述文本内容的模糊特征向量;其次,针对构造的模糊特征向量,采用具有强大分辨能力的核聚类算法[7]完成文本聚类。该方法利用Mercer核,将输入空间样本映射到特征空间,增加对样本特征的优化,使映射后的样本具有更好的聚类形式。
假设输入空间样本Xk∈RN(k=1,2,…,L)被某种非线性映射Φ映射到某一特征空间得到Φ(X1),Φ(X2),…,Φ(XL),则特征空间中,向量的点积形式可以用Mercer核表示为:

特征空间中Euclidean距离可表示为:

式(3)可作为聚类相似度的度量函数。聚类准则是使的下面的目标函数最小:
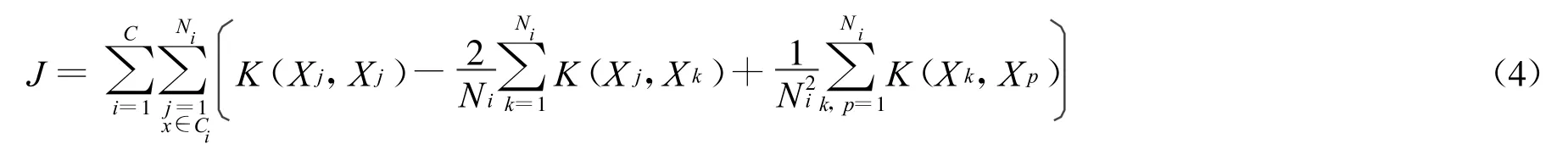
式中,C是聚类类别数;Ni是第Ci类样本的个数。依式(3)计算各样本的类属情况,同时迭代修正各类中心。当各类中心稳定时聚类结束。
1.3 模糊核聚类算法实施步骤
模糊核聚类算法实施步骤如下:
1)确定聚类类别数C,聚类误差Emax,初始化聚类中心Wi(k),i=1,2,…,C;
2)按式(3)计算各样本到聚类中心的距离(i=1,2,…,C;j=1,2,…,L):
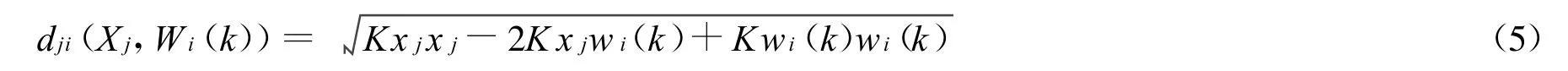
令:
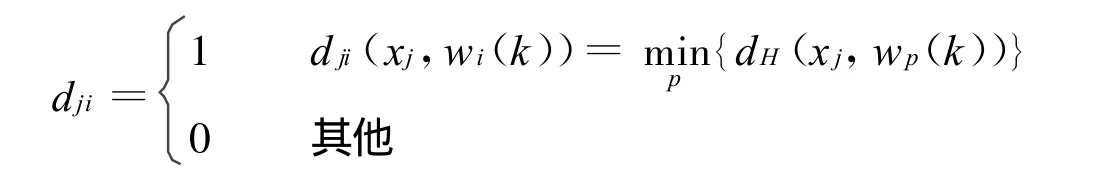
3)修改核矩阵Kxjwi(k),Kwi(k)wi(k):
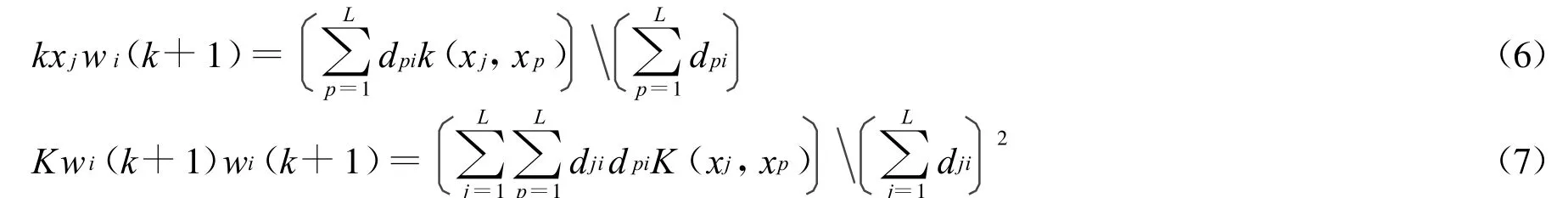
4)计算误差:
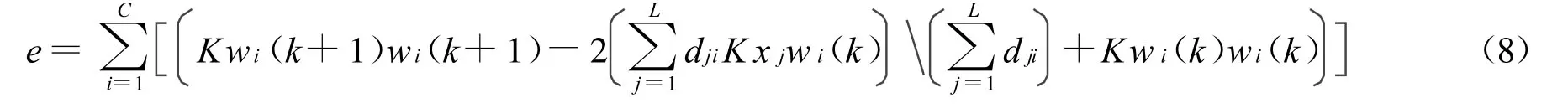
5)如果e<Emax,停机;否则转步2)。
最后得到的聚类结果是,若dji=1,则xj∈Wi(i=1,2,…,C;j=1,2,…,L)。
2 实际应用
作为该方法的一个应用,笔者选择中国期刊网全文数据库 (CNKI)作为测试样本源。根据CNKI已有的分类情况,作者下载了8个主题类共960篇文档作为测试语料库。每个主题的语料包括120篇文档。综合全部文档的特征,共抽取了72个关键词 (每类9个,其中第1个为该类的类属词)组成特征项的集合。按照前述方法构造全部语料样本的模糊特征向量。评价与测试文档聚类效果需要2个重要指标,即召回率recall(Ci)和正确率precision(Ci):
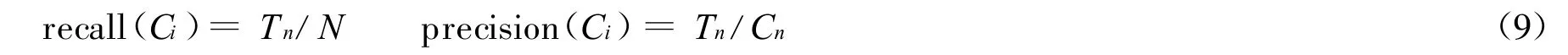
式中,Tn为通过聚类算法被正确聚类为Ci类的文档数目;N为未聚类之前属于Ci类的文档数目;Cn为通过聚类算法被聚类为Ci类的文档数目。采用如下的高斯核函数实现式(3)的计算:

根据采集的文本类属情况,聚类数取为8类,限定误差取为0.001,限定迭代次数为500次。初始聚类中心取为前8个样本。该算法的聚类结果如表1所示。
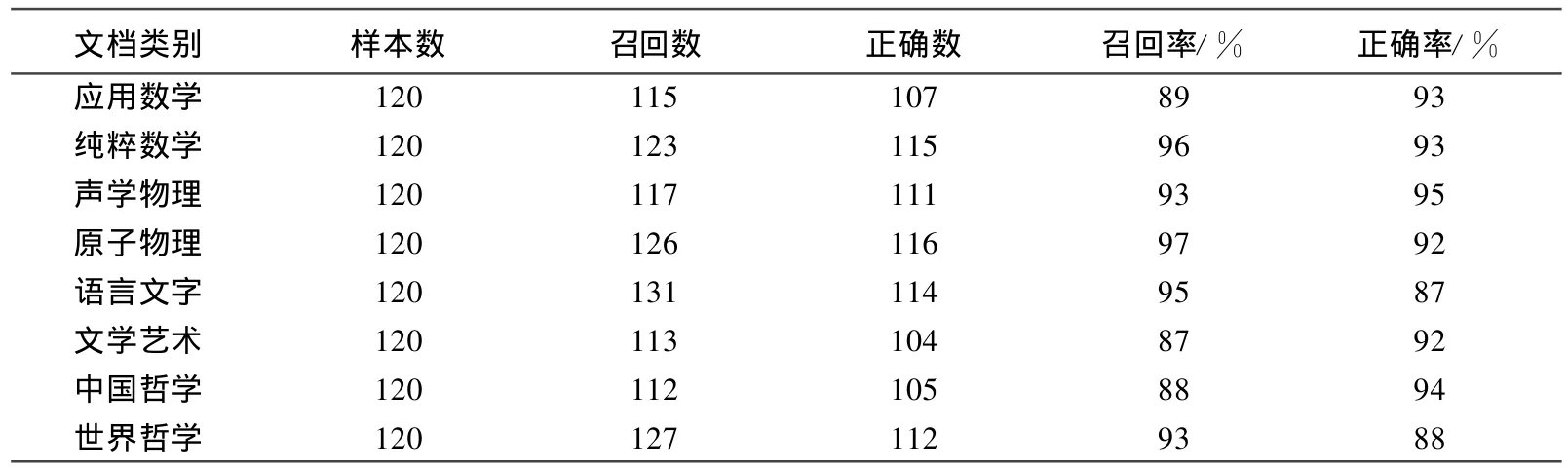
表1 模糊核聚类算法的聚类结果
由表1可以看出,每个主题的聚类正确率都在87%~95%之间。观察表1可发现,召回率高的类正确率不一定高 (如语言文字类);而召回率低的类不见得正确率也低 (如文学艺术类);召回率和正确率可能同时较高 (如声学物理、原子物理类)。这说明对于自身特征不明显的召回率较低的主题类,尽管该方法有较低的自识能力,但却有着较高的排斥能力;对于自身特征较明显而易于与其他类产生特征交叉的主题类,该方法的自识能力较强,排斥能力较弱;而对于自身特征很明显的主题类,召回率和正确率都比较高,模型表现出了良好的聚类能力。
为进一步说明该方法的有效性,笔者对全部960个模糊向量采用K-均值聚类方法进行聚类,并采用相同的限定误差和迭代次数,初始聚类中心也取为前8个样本。聚类结果如表2所示。
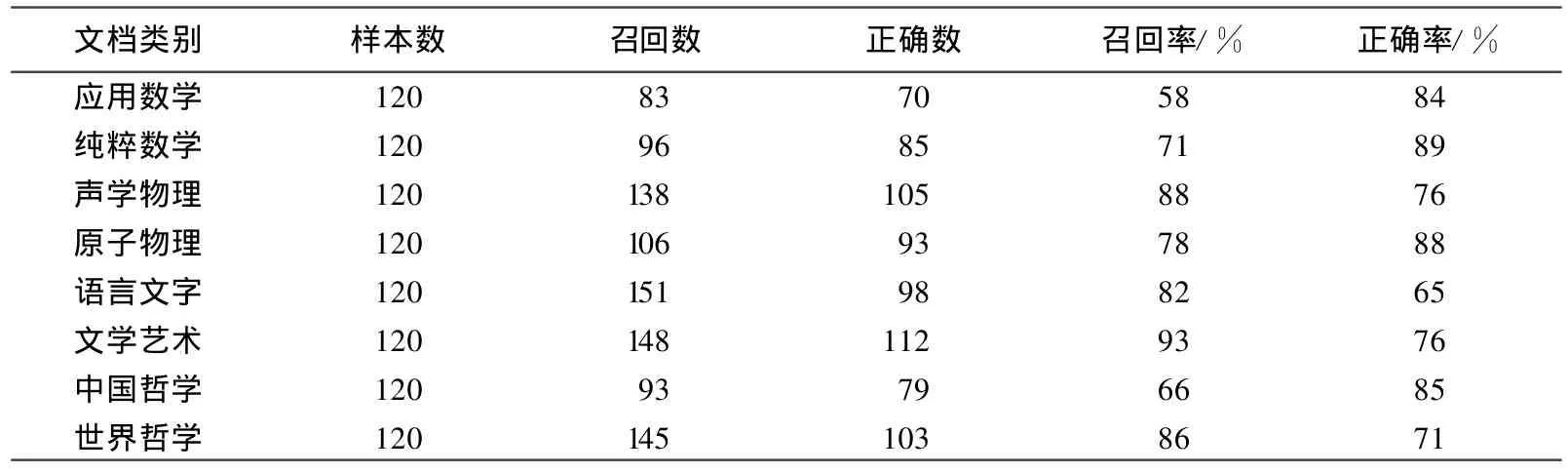
表2 K-均值聚类算法的聚类结果
表2聚类结果表明,笔者提出的模糊核聚类算法明显优于K-均值聚类算法。
3 结 语
文本的自动聚类是信息处理领域中的一项重要研究课题,笔者对文本自动聚类作了探讨,针对实际聚类问题中文本特征、类属特征的模糊性及特征信息对于反映文本类别的重要性,提出了基于模糊向量空间模型的核聚类算法。由于对特征空间的描述,采用了模糊数学方法,充分考虑了各个特征在反映文本主题上的重要性,增强了该方法对复杂聚类问题的适应性。试验结果表明,该方法取得了很好的聚类效果。但在文本特征的抽取及赋值、聚类模型的完善、学习算法的改进、权重评价等许多方面还有待于进一步研究。
[1]何新贵.模糊知识处理的理论与技术 [M].第2版.北京:国防工业出版社,1998.
[2]何新贵,彭甫阳.中文文本的关键词自动抽取和模糊分类[J].中文信息学报,1999,13(1):9~15.
[3]周涛,张艳宁,袁和金,等.粗糙核k-means聚类算法 [J].系统仿真学报,2008,20(4):921~925.
[4]周林峰,丁永生.基于遗传算法的Mercer核聚类方法 [J].模式识别与人工智能,2006,19(3):307~311.
[5]索红光,王玉伟.基于参考区域的k-means文本聚类算法 [J].计算机工程与设计,2009,(2):401~403,407.
[6]普运伟,朱明,金炜东,等.核聚类算法最佳聚类数的自适应确定方法 [J].计算机工程,2007,33(4):11~13.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
客联(2022年3期)2022-05-31
保定学院学报(2022年2期)2022-04-07
中国新闻周刊(2021年26期)2021-07-27
天津科技大学学报(2018年4期)2018-08-22
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
信息安全研究(2016年4期)2016-12-01
网络安全与数据管理(2010年1期)2010-05-18
