
基于SVM的论文元数据抽取方法研究
2010-01-27 07:15欧阳辉禄乐滨
电子设计工程 2010年5期
欧阳辉,禄乐滨
(空军工程大学 电讯工程学院,陕西 西安 710077)
随着DOI的应用与发展,信息的自动抽取研究得到了广泛关注,但自动抽取器对电子文档进行元数据自动抽取基本上都是从电子文档的头文件中进行抽取,抽取的字段以文档的形式特征(类型、生成时间、软件相关信息等)为主,而关键内容的相关元数据则难以获得[1]。
数据库中的科技论文文献有近90%是PDF格式的文档,目前对PDF格式文档进行元数据抽取主要采用间接抽取法,即先把PDF格式的文档转换为其他格式文档后再进行元数据抽取。在文献[2]中李朝光等人进行了从TXT文档中基于正则表达式来提取论文元数据的研究,成功率达到74.3%。在文献[3]中,通过把PDF文件用工具PDF2HTML工具转换成中间文档,再总结出标题、作者名、作者地址、E-mail共4类论文元数据特征,最后利用XSLT作为抽取规则制定语言进行抽取,但是元数据类型不够丰富,特征总结不够全面,还有待于进一步研究。
一个PDF文档由文件头、文件体、交叉引用表、文件尾4部分组成,是8位二进制字节序列,也可以用7位ASCII来描述。它是以二进制传输和存储的,可由简单文本组成,也可能是由文本和各种类型的图像(彩色图像、灰度图像和二值图像)混合组成[4]。
对于论文元数据抽取来说,PDF文档的文件头、交叉引用表、文件尾等额外文档描述信息对基于统计的模型甚至是一种干扰。研究发现,pdfbox开源库对PDF文档进行过滤处理后可以得到自由文本格式论文,这样就可以通过libsvm开源库建立支持向量机仿真模型对转换后的文档进行元数据抽取。
1 支持向量机(SVM)
支持向量机(Support Vector Machine,SVM)是由统计学习理论发展而来的一种机器学习方法,它以最大化分类间隔构造最优分类超平面来提高支持向量机的泛化能力,具有训练样本小、学习速度快、易于扩展等特点[5],已经成为目前的研究热点,在模式识别,包括手写字符识别、网页或文本自动分类、说话人识别、人脸识别、遥感图像分析等方面都有非常出色的表现[6]。
1.1 支持向量机的原理
支持向量机建模的过程就是解决最优分类超平面的参数确定问题,确定各个参数实质是一个二次优化问题,其几何意义是求在约束条件下分类间隔的最大值,对于输入空间中的非线性问题,可以通过核函数计算特征空间中向量与支持向量之间的内积使其转化为特征空间的线性分类问题,判别函数如下:

对于非线性问题,仅仅依靠核函数会导致目标空间维数过高,为此这里引入松弛变量和惩罚因子来解决该问题,这样就把一个复杂的最优化问题简化为对原有样本数据的内积运算和选择适当的核函数及其参数的问题,这样构造出的支持向量机也称为软间隔支持向量机。最常用的软间隔支持向量机是C-SVM,参数C为惩罚因子。
1.2 多分类支持向量机模型
多分类支持向量机是专门解决有多个类别的分类算法。支持向量机最初是为两类分类问题而设计的,但在实际应用中更多的是需要从多个类中提取出所需要的数据和信息,这使得多类分类问题的应用更普遍。对于多分类问题,最常用的方法是将多分类问题转化成两类分类问题来求解,选定其中的一个类或多个类作为正类,将其余的类作为负类,建立两分类的支持向量机,再对余下的类多次运用两分类的支持向量机将其一一分开,该类主要的方法有one-against-one、one-against-all、DDAGSVM及树型支持向量机等方法。
比较以上4种方法,“one-against-all”方法对K类问题只要建立K个支持向量机,训练过程很快,但在预测过程中存在无解的危险,当K个支持向量机对该样本都输出为否时,该样本就找不到属于它的类,出现无解的情况。“one-againstone”方法和DDAGSVM方法对K类问题都要建立K(K-1)/2个支持向量机,建立支持向量机的速度相对较慢,而且“oneagainst-one”方法在测试过程中每一个样本都需要经过这K(K-1)/2个支持向量机的分类,因此其训练速度和分类速度都较慢。DDAGSVM方法每个测试样本也需要从根节点走完一条到叶子节点的路径才能判别出目标所属的类别,经过的支持向量机的分类次数为K次,其分类速度较快,而且每条路径都以叶子节点结束,所以不会出现无解的情况。但该方法存在差错积累,一旦在根节点分类错误,则在后续节点就不能找到正确分类,只能一错再错,最后得到错误分类。
树型支持向量机多类分类方法实质上是一种决策二叉树的方法。基于二叉树的多类SVM首先将所有类别分成2个子类,再将子类进一步划分成2个次级子类,如此循环,直到所有节点都只包含一个单独的类别(即叶子节点)为止。该方法分类准确率高,分类速度快,但难点是树型结构的设计和差错积累问题。
从分类准确率角度分析,在树形结构中,越上层的节点(即越早分离出来的类)的分类性能对整个分类模型的推广性影响越大。在文献[7]中,通过例证得出越易分辨的类放到上层,最终的总分类误差数越小。因此,应该让最易分割的类最早分割出来,即在二叉树的上层节点处分割,这样才能使得上层的SVM子分类器具有更高的推广性能,减少差错积累,提高分类准确率。找出最易分割的类别的基本思想是,让与其他类相隔最远的类最先分割出来,此时构造的最优超平面也应具有较好的推广性。
而判断一个算法好坏除了要判断其错分率,空间复杂度等指标外,还要判断其运行时间,这里的时间是指训练时间(建立所有支持向量机的时间)和分类时间(判断一个新的未知的样本点属于哪个类)。
训练时间主要在于求解单个支持向量机的时间和建立支持向量机的个数,文献[7]从理论上分析了“正态树”和“偏态树”的训练总时间,得出相同样本数量的情况下,“正态树”的训练总时间最短。
分类时间主要在于求出未知样本点所在的类需要经过的支持向量机运算的个数。在树形结构中,分类时间主要取决于二叉树的层数,即所建立的二叉树的深度越大,其分类时间越长,反之越短。因此,二叉树的深度越小越好。
1.3 基于平衡二叉树的多类分类支持向量机
为了优化仿真模型,这里提出基于平衡二叉树的支持向量机多类分类方法(BBT-SVM),算法步骤如下:
1)定义类与类之间的距离 dij(i,j=1,2,3,…,k;i=j)。 在线性情况下,2样本x1,x2间距定义取2个样本的欧氏距离
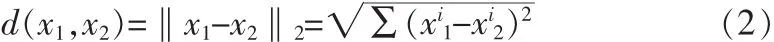
在非线性情况下,2样本x1,x2间距定义为

式中,ø(x)为向量x经过核函数映射到高维向量空间后所对应的向量。 k(x1,x1)=ø(x1)gø(x2)为核函数。
2)分别对各个类别与其他类别距离值按由大到小的顺序排列,并重新编号。例如,第i类与其他类距离值为dij(i,j=1,2,3,…,k;i=j),按由大到小排序为
3)比较各类的D1,选出具有最大D1的2个类。 若Ci的大于Cj的即则Ci排在Cj之前。 若Ci的与Cj的相等,即,则再比较Ci的与Cj的,若Ci的大于Cj的,即,则Ci排在Cj之前。 若Ci的与Cj的相等,即,则再比较Ci的与Cj的依此类推,则得到具有最大距离的2个类A和B,用表示。从类集合中去掉类A和类B,重新比较各类的D1,挑出各类中具有最大D1的个类C和D,用表示。最后得到序列:若类别总数为奇数,则会留下最后剩下的类别,记为Z)。
5)分别以左右子树包含的类为集合,重复步骤2)~步骤4),建立左右子树。
6)重复步骤5),直至得到所有叶子节点,算法结束。
该改进算法融合了最大类间距离和平衡树的思想,从理论上分析,最大类间距离保证较高的分类准确率;运用平衡树的思想,使分类树的深度最小,而且使正例和反例的样本数目近似相等,分类错误率较低。
对于K类问题,比较各方法的性能,如表1所示。
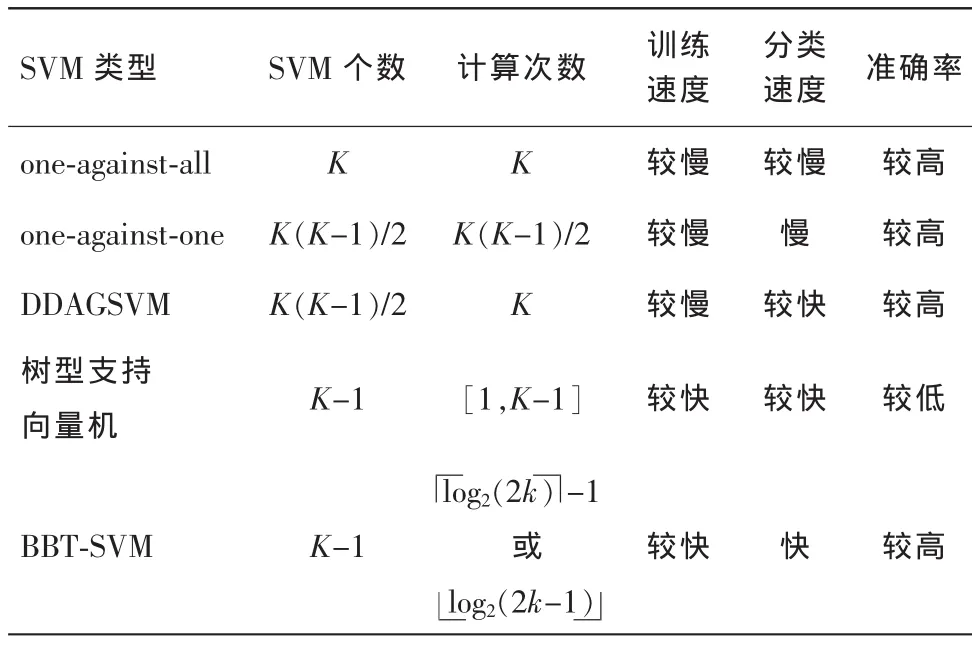
表1 多类分类支持向量机的比较
2 建立SVM的仿真模型
2.1 SVM模型的确定
针对论文元数据的特点,选取6类典型元数据作为测试对象,树中度为2的节点则为支持向量机,则支持向量机的个数为5个,每个支持向量机都选择C-SVM模型且C值的限定范围为 (10-5,105)。本模型中采用的核函数是径向基函数: K(x,y)=exp[(x-y)2/δ2],δ 为模型要确定的参数,在本模型中限定范围为(10-5,105)。
本文用于训练的数据集为随机选取的2万篇论文,用于实验的论文元数据类别初步定为出版社信息、标题、作者、摘要、关键词,参考文献等6类。首先将样本去噪,对数据进行规范化,处理奇异样本点,最后样本用特征向量表示。根据式(2)和式(3)并按照平衡二叉树支持向量机的建立步骤进行计算,建立的BBT-SVM模型如图1所示。
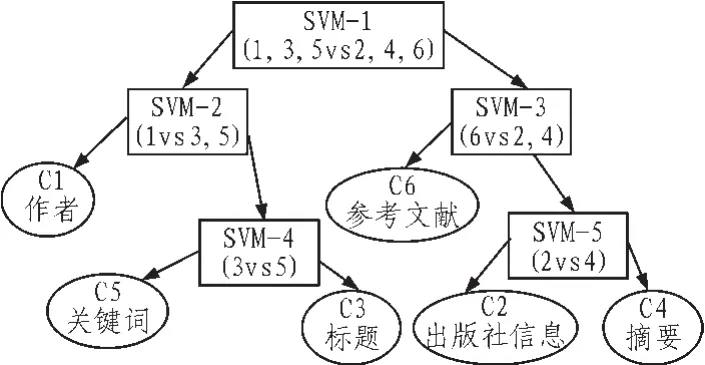
图1 基于BBT-SVM的论文元数据抽取模型
2.2 SVM模型的优化仿真
这里用MyEclipse 6.0结合MATLAB 7.1并选用libsvm开源库编程建立仿真模型,用交叉验证法寻找最佳参数,用k-fold法计算交互检验准确度和均方根误差,实验中k取10,采用径向基核函数,运用交叉验证法使核参数σ和惩罚因子C在区间(10-5,105)进行搜索,如图2所示,由交叉验证法搜索出的各支持向量机模型的参数如表2所示,从而得到最优SVM仿真模型。

图2 网格搜索法得到SVM-1的最佳参数

表2 BBT-SVM模型中各SVM的参数
3 结果分析
为了检验支持向量机的性能,随机选取3万篇论文文献进行论文元数据抽取,实验结果如表3所示。

表3 论文元数据的抽取结果
在实验结果中,F度量值F=(B2+1)PR/B2P+R,调节B的值可以让用户在查全率和查准率上求得平衡,在文献[8]中,取B=0.5,代表P的重要程度是R的2倍,这是基于元数据提取的查准率比查全率重要的考虑,而在论文文献元数据中初步选取的元数据是基本元数据,都是必须的,所以数据的完备性同准确性一样重要,因此取B=1。
4 结 论
本文针对PDF文件的特点,选用pdfbox开源库对PDF文件进行解析得到,通过分析多类分类支持向量机的特点和性能提出了BBT-SVM模型。运用网格搜索法得到最佳参数得到BBT-SVM最优模型,最后对随机选取的3万篇论文文献进行元数据抽取。经过试验,各类元数据的查全率都提高了86%以上,查准率都在92%以上,F度量值都在89%以上,与基于正则表达式的方法相比提高了20%。由试验数据结果可知,查全率比较低,这是因为文献中的部分论文是加密的PDF文档,pdfbox无法对其进行解析。针对加密的PDF论文文献的元数据抽取是下一步研究的重点。
[1]曾苏,马建霞,张秀秀.元数据自动抽取研究新进展[J].现代图书情报技术,2008,163(4):7-11.
[2]李朝光,张铭,邓志鸿,等.论文元数据信息的自动抽取[J].计算机工程与应用,2002,21(5):189-235.
[3]陈俊林,张文德.基于XSLT的PDF论文元数据的优化抽取[J].现代图书情报技术,2007,147(2):18-23.
[4]陈云榕,刘立柱,丁志鸿.PDF文件中关键信息的提取与组织方法研究[J].计算机工程与应用,2007,27(4):39-45.
[5]范婕婷,赖惠成.一种基于SVM算法的垃圾邮件过滤方法[J].计算机工程与应用,2008,44(28):95-98.
[6]Keerthi S,Chih-Jen Lin.Asymptotic behavior of support vector machines with Gaussian kernel[J].Nerual Computation,2003(15):1667-1689.
[7]刘志刚,李德仁,秦前清,等.支持向量机在多类分类问题中的推广[J].计算机工程与应用,2004,12(7):10-13.
[8]杨宇,张铭,周宝曜.基于多种规则的课程元数据自动抽取[J].计算机科学,2008,35(3):94-96.
猜你喜欢
客联(2022年3期)2022-05-31
新高考·高一数学(2022年3期)2022-04-28
中国新闻周刊(2021年26期)2021-07-27
现代计算机(2021年14期)2021-07-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
武汉轻工大学学报(2016年4期)2017-01-16
信息安全研究(2016年4期)2016-12-01
武汉轻工大学学报(2016年3期)2016-10-27
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23