
矿产资源潜力评价中定性数据标准化检查
2010-01-12 01:39常思思汪新庆
物探化探计算技术 2010年3期
常思思,汪新庆,2,过 剑,刘 夏
(1.中国地质大学 数学地质与遥感地质研究所,湖北武汉 430074;2.中国地质大学 地质过程与矿产资源定量预测国家重点实验室,湖北武汉 430074)
0 前言
为了积极开展矿产远景调查和综合研究,并科学评估区域矿产资源潜力,为科学部署矿产资源勘查提供依据,国土资源部部署了全国矿产资源潜力预测评价工作。随之获得的成果数据,其种类繁多复杂、规模庞大异常。这些数据具有数据源丰富,数据量庞大,数据类型众多,数据结构复杂,即所谓多源、多量、多类、多维[1]的特点。另一方面,标准定性数据在潜力资源评价中又占了相当数量,对这些数据进行检查显得尤为重要。作者在本文中通过建立数据字典,数据标准来检查标准定性数据,以确保数据的正确性和完整性。
1 定性数据检查的必要性
1.1 地质数据分类
地质数据都具有数量巨大,众多繁多,结构复杂的特征[1]。地质数据按照其数据意义分为定性数据和定量数据,它们共同描述和反映了地理世界中的实体及地理现象[2]。
其中,定性数据是以字符型数据为主,而字符型数据又可以分为以下二类[1]:
(1)名义型数据。此数据没有次序之分,仅仅是对对象的客观描述。比如岩石名称、岩石组合、图层名称、图元编号、异常编号、地层代号等字段。
(2)有序型数据。此数据相互之间程度有所差异。例如矿石品级、勘探工程密度、构造层次、断裂规模、蚀变强度等等。
1.2 定性数据标准化描述
由于数据检查对象为字符型定性数据,大量数据都是以文本形式存在,计算机难以对这些数据进行有效的检查。并且在地学上,不少术语一词多解或者同物异名,这也给检查带来了困难。因此在检查之前,需要对这些数据进行规范化标准处理,将文本内容代码化[2、3]。代码便于操作,可提高检索和查询的效率,还可增强数据的共享性。因此,在地质数据库中应该大量使用代码数据[1]。
对于有序型数据,因为其数据之间有明显程度上差别(例如“断裂规模”),其值分为巨型、大型、中型和小型,这样很容易对其进行编码。
对于名义型数据,只有那些确定其值的才可以编码(例如“岩石名称”)。
“断裂规模”、“岩石名称”均为某一些有相同意义数据的集合,数学中称其为枚举值;而其它一些如“断层名称”对于其值不能事前确定即不是枚举值,则这些数据不能将其编码。在实际工作中,将确定数据项其值能够代码化的枚举值称之为下属词。
1.3 定性数据检查必要性
定性数据在地学数据库中占有相当大的比例,现以全国矿产资源评价数据库为例,将所有数据项按数据类型、字段数进行分类统计,统计结果如图1所示。
从图1可知,字符串数据的字段数量占总字段量的77.8%,而双精度数据占字段数量8.15%,其中标准化过的定性数据占整个字段数量的20.6%。由上可知,定性数据在全国矿产潜力资源评价数据中,占有相当大的比例,所以对以描述性文字为主的定性数据做检查,是一件十分棘手的事情。
再例如对于字符名义型数据,“岩石名称”其数据值可以为火成岩、橄榄岩、辉石橄榄岩、斜辉橄榄岩、闪长岩、二长岩、安山岩、正长岩等一系列岩石名称。以全国矿产资源评价数据库为例,根据《全国矿产资源评价数据模型数据项下属词规定分册》可知,对于“岩石”名称这个数据项,共有2 446项可填值。在数据的录入中,由于是手工录入,很难保证值一定就在2 446项中,而对于这种字符型定性数据检查,一般都采用普通的文本编辑功能进行简单的检查,既费时又费人力。而且地学数据一般以海量计算,这样往往难以有效地达到对数据进行检查分析的目的。如何确保这些数据的正确性和完备性,是一个有待解决的问题。作者通过将可代码化的有序型、名义型数据进行信息编码,并以此建立标准模式字典,使其标准与数据字典有机的联系起来,以此来确保数据的正确性和完备性。
2 定性数据标准化检查内容
对标准化字符型定性数据检查内容主要有以下三项。
2.1 属性精度
在矿产资源潜力评价应用系统中,数据采集员时常需要对地质矿产分类代码,进行频繁地检索、查证、术语归属验证,以及层次归并或层次分解等操作。同时,在将地质调查成果入库时,由于地矿术语的复杂性,在涉及到地矿术语的录入上,工作人员很容易将错误的术语录入。而且由于各个矿产地建库标准不一样,对于同种数据项可能有不同描述,属性误差也尤为严重。
2.2 数据完整性
数据完整性主要是用于检查有无多余数据或者缺少数据。由于制图标准不一样,属性字段对于标准也就各不相同。对于同一种图层,矿产区所提交的图层属性数据项缺失情况不尽相同。
2.3 值域一致性[4]
值域一致性是值对值域的符合程度,此为逻辑一致性其中一种。在矿产潜力资源评价项目中,由于图层没有按照《全国矿产资源潜力评价数据模型》来划分图层。图层代码不规范,属性字段代码、类型、长度不一致,都能使提交上来的属性数据不规范,属性值不符合数据项值域要求。
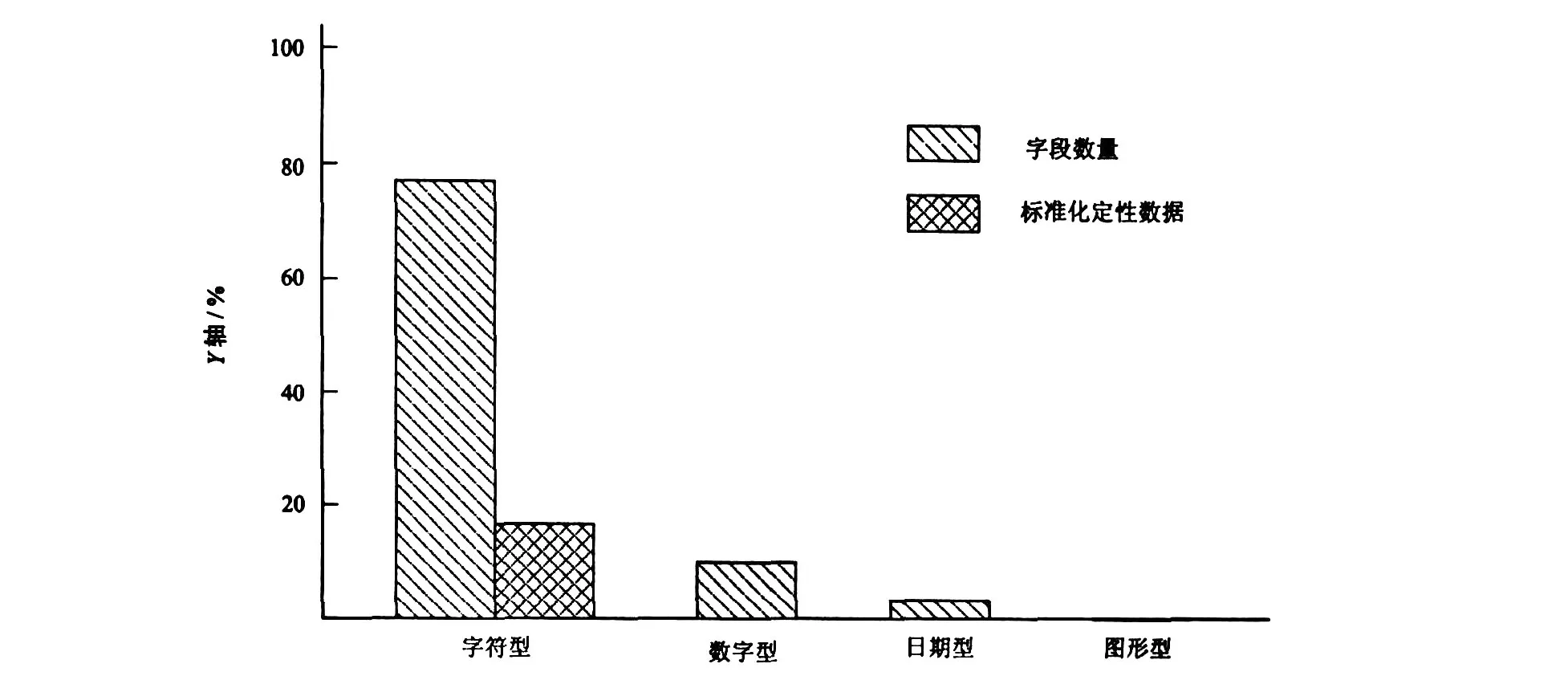
图1 数据类型统计Fig.1 Statistics for data types
对于以上情况光靠人工或者一般方式的程序检查很难查出错误,这样就导致后期的地矿数据检查工作变得繁重。检查内容如表1所示。
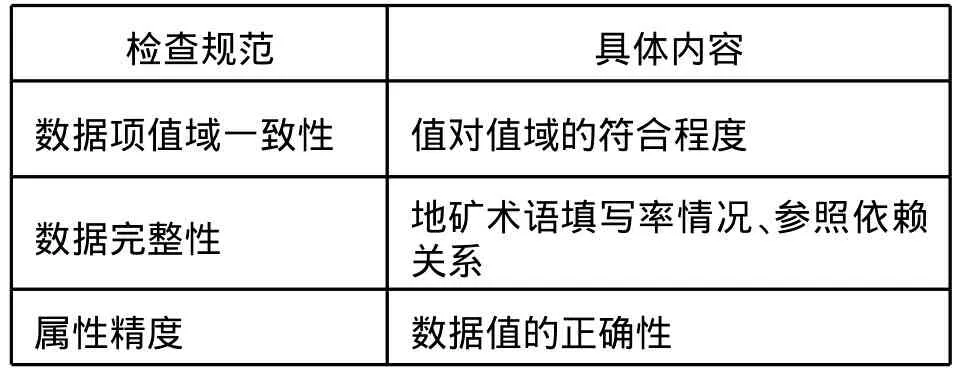
表1 检查内容[4]Tab.1 Checking contents
3 定性数据标准化检查策略
3.1 基于数据字典的数据检查思路
数据字典(Data Dictionary,DD)也称为数据目录或系统目录[5],是关于数据库系统中各类数据描述的集合,是进行详细的数据收集和数据分析所获得的主要成果。在数据库设计的第一阶段,即需求分析阶段,用数据流图(Data Flow Diagram,DFD)来表达数据和处理的关系,而其中的基础数据则用数据字典来描述。
利用数据字典将字典的结构设计好,把模型、标准等所有的基础数据作为一条一条的记录,放入到相应的数据字典中。用数据字典来管理数据,用户可以直接操作数据字典,不管数据怎样变化,只要数据字典的结构不变,程序始终是不变的,因为程序只是针对数据字典的结构来操作。通过操作结构取得数据,而不是像一般的方法那样直接操作数据,如图2所示。
从图2中可以看出,数据字典相当于是一个中间层,程序通过操作固定的字典结构,读出动态变化的数据,这样程序就可以不用改变,就可以应对变化的数据,达到不同的效果。这对程序编码而言是一劳永逸的,大大提高了程序开发的效率,同时也体现出了数据字典的灵活性。
3.2 标准化检查策略数据字典设计
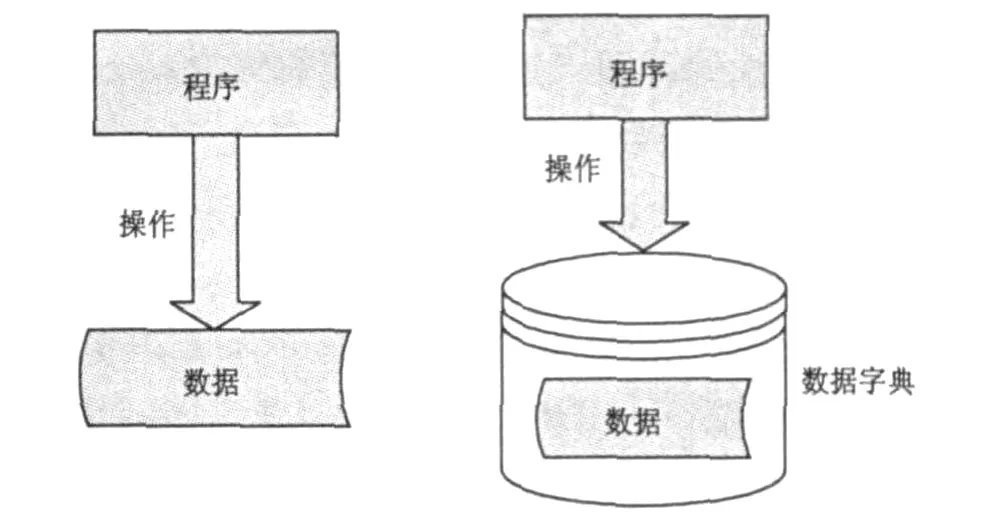
图2 一般检查和字典检查的对比图Fig.2 Comparison chart of general checking and dictionary checking
基于数据字典和将文字描述的内容代码化更有利于操作,检索和检查的优点。根据1988年由国家标准局颁布了地质矿产术语分类代码(GB9649-88)[5],以及全国矿产潜力资源评价制定了关于地矿术语定性数据的编码规则和代码标准,即《全国矿产潜力资源评价数据模型数据项下属词规定分册》,利用数据库中特有的数据字典技术,建立数据项下属词标准字典ZXDC,即将《数据项下属词规定分册》分类代码,按照已提供的编码方式入库,生成计算机能够识别的下属词数据项编码,这样就将下属词标准化(下属词标准字典如表2所示)。下属词数据项将以字典的方式存储,以供其余数据项调用和检查。这里利用数据字典技术与质量标准,来检查数据项下属词数据的完整性和一致性。

表2 下属词标准字典Tab.2 Standard dictionary of enumeration value
在整个项目中,根据全国矿产资源潜力评价数据模型,建立了图件、图层、数据项等数据字典,用来记录它们之间联系以及模型信息。其中,在标准模式字典D ICT记录模型中,描述了所有图层的属性字段。通过标准模式字典D ICT[6]根据需要获取控制参数,然后通过下属词标准字典ZXDC来判断是否符合标准,不符合的既而根据下属词标准字典ZXDC修改用户数据,从而可以很好地控制数据项下属词的一致性和完整性。
数据检查策略如图3所示。

图3 下属词数据检查策略Fig.3 Checking strategy of enumeration value
4 标准化检查实现
在MAPGIS平台下,采用数据字典技术实现了符合标准描述的定型数据检查模块。流程图如图4所示。
首先从图件中获取图层信息,接着利用所取得的图层信息获取图元属性信息,然后判断要检查的属性字段是否有下属词。这时需要到“标准模式字典D ICT”中去,把需要检查的图层进入到这个字典中进行核对。通过“FIELD_NAME”,就可以知道这个图层中有哪些字段了。例如对于字段名为KCAJA I的蚀变强度,接着在“ZXDC”这一项中查看是否有值,如果有值,就表示该字段有下属词,从表3可以看出,“蚀变强度”有下属词;然后将“ZXDC”中的值读出,这里是“KCAJA I”;最后在“下属词标准ZXDC字典”中,以“ZXDC”中的“KCAJA I”以及“CODE”中的值为关键字查找“C_NAME”中的值。如果用户与其相对应,则说明用户所录入的“KCAJA I蚀变强度”中的值为正确;如果没有查找到,则说明错误,同时要把错误的检查结果显示并输出出来,以便给用户进行修改。
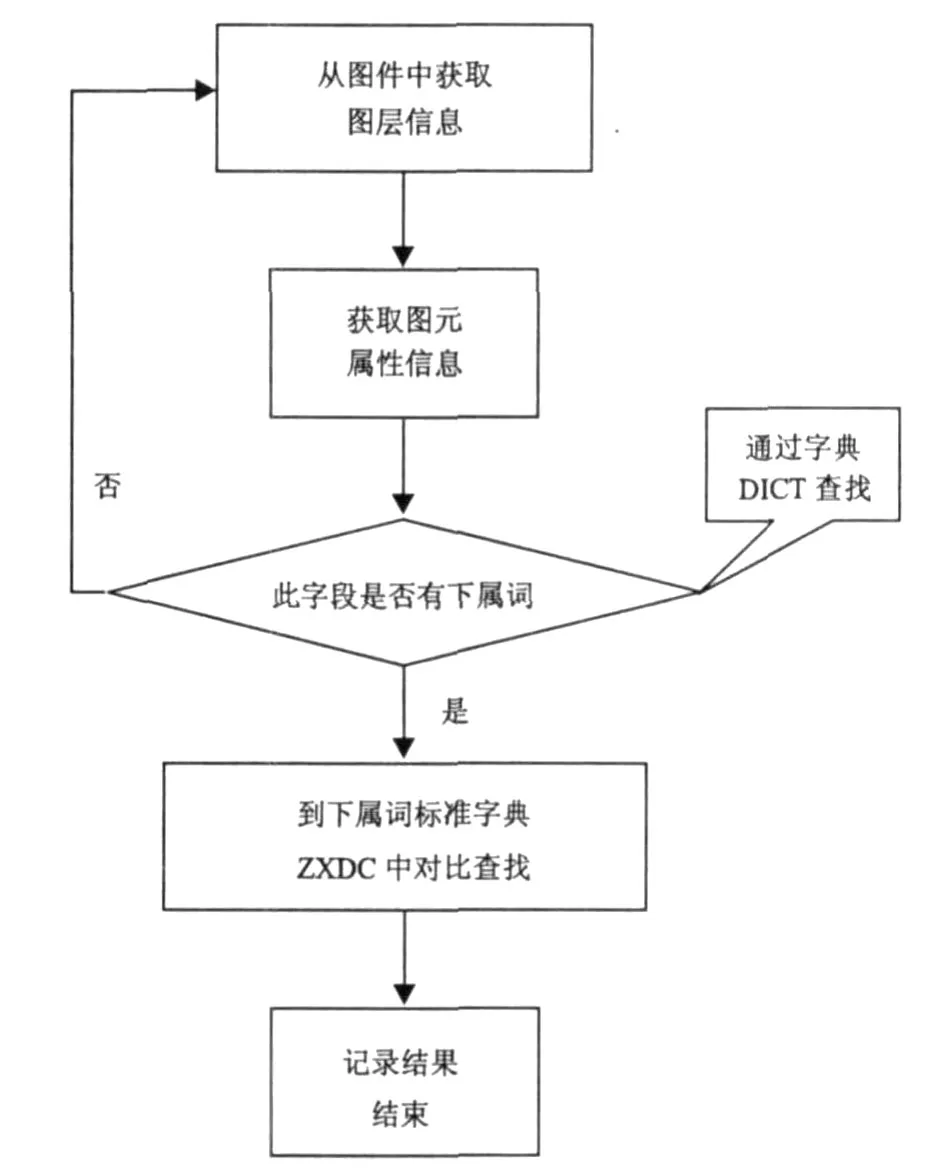
图4 下属词检查流程Fig.4 Checking process of enumeration value

表3 标准模式字典Tab.3 Standard mode dictionary
5 结论
由于数据在设计的过程中经常会发生变化,一些数据是一开始初定的,但是在后面项目的进行中,还是会有些改变。所以如果用一般的方法来检查的话,一旦数据发生了变化,用户的程序都要随时改变,这样不但不灵活,而且还会大大降低程序开发的效率。经实践证明,利用数据字典技术,可以检查出在定型数据中的隐藏错误,很好地控制了数据的完整性。利用标准规范可以有效检查数据的一致性,并且这样既保证了数据的变化,也能保证程序的变化达到最小。这比较人工检查更为准确、更省时省力。
“全国矿产资源潜力预测评价”项目,其规模之大堪称建国以来地调行业之最。随之获得的成果数据,其种类繁多复杂,规模庞大异常,涉及到的部门、人员众多,要确保这项工作能够顺利进行,首先要保证入库数据的正确性,这里主要停留在实现了符合标准定型数据的数据项检查,而对于图件、图层数据检查是以后工作的重点。
致谢:感谢导师汪新庆副教授不遗余力的指导我,并在研究步骤和研究方法的确定上提出了许多宝贵的修改意见。在研究过程中始终得到全国矿产潜力资源评价数据模型管理项目组的支持,得到中国地质大学(武汉)过剑硕士、邵雯硕士的帮助,在此一并表示衷心的感谢。
[1] 吴冲龙,汪新庆,刘刚,等.地质矿产点源信系统设计原理及应用[M].武汉:中国地质大学出版社,1996.
[2] 周姗爱.地质数据模型与数据描述标准化及相关技术研究[D].武汉:中国地质大学(武汉),2007,5:36.
[3] 左仁广,夏庆霖.矿产预测定型数据不确定性评价[J].金属矿山,2007,(8):7.
[4] 中国地质调查局地质调查技术标准DD2006-07.地质数据质量与评价[S].2006.
[5] 吴冲龙,汪新庆,刘刚,等.资源信息系统教程[M].武汉:中国地质大学出版社,2001.
[6] 汪新庆,刘刚,袁艳斌,等.地质矿产术语分类代码在地矿点源信息系统中的应用[J].地球科学,1999,24(5):529.
[7] 戴刚毅,鲍征宇,张锦章.基于GIS的矿山空间数据库的建立[J].物探化探计算技术,2000,22(1):78.
[8] 宋国耀,张晓华,肖克炎,等.矿产资源潜力评价的理论和GIS技术[J].物探化探计算技术,1999,21(3):199.
[9] 马小刚,汪新庆,毋丽红,等.应用数据字典实现多源地质空间数据的通用管理[J].矿业研究与开发,2007,27(1):38.
[10]陈永清,汪新庆,陈建国,等.基于GIS的矿产资源综合定量评价[J].地质通报,2007,26(2):145.
[11]左仁广,汪新庆,马小刚.矿产预测评价基础数据库的入库策略探讨与实现[J].国土资源科技管理,2005,1:77.
[12]刘展,王万银,黄继先,等.矿产资源评价系统的地质矿产数据模型[J].西安石油学院学报,2002,17(1):11.
[13]王本洋,余世孝.基于ArcView GIS的数据字典技术研究[J].遥感技术与应用,2003,18(6):429.
[14]吴冲龙.资源信息系统导论[M].武汉:中国地质大学出版社,1998.
[15]李裕伟.空间信息技术的发展及其在地球科学中的应用[J].地学前缘,1998,5(2):337.
[16]孟小红,王卫民,姚长利,等.地质模型计算机辅助设计原理与应用[M].北京:地质出版社,2001.
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30
甘肃科技(2020年19期)2020-03-11
计算机与生活(2019年11期)2019-11-12
科技与创新(2019年14期)2019-08-12
中成药(2018年12期)2018-12-29
摄影之友(影像视觉)(2018年1期)2018-03-22
影像研究与医学应用(2015年6期)2015-08-15
中国检察官(2015年14期)2015-02-27
中国检察官(2015年12期)2015-02-27
土木建筑工程信息技术(2013年3期)2013-10-17
