
改进性的文本聚类算法研究
2009-12-04 01:18长江大学计算机科学学院湖北荆州434023
长江大学学报(自科版) 2009年4期
赵 鸣,吴 磊 (长江大学计算机科学学院,湖北 荆州 434023)
改进性的文本聚类算法研究
赵 鸣,吴 磊 (长江大学计算机科学学院,湖北 荆州 434023)
在互联网技术日益发展的今天,如何快速对海量的文本进行归类是数据挖掘的一项重要课题。 提出了一种改进型的文本聚类算法,计算句子相似度时综合考虑基于词频统计的特征向量表示法和关键词之间的关系,减少了相似度对于输入次序和频数的敏感度,有效地提高了计算小文档和简单句子相似度的准确度和文本聚类结果的准确率、召回率。
文本聚类;特征向量;相似度
经典的文本聚类算法很多,K均值聚类算法是目前比较流行的一种基于划分的算法。该算法中文档相似度计算通常采用向量空间模型,它们在假设术语间相互独立的基础上,通过逻辑表达式或向量间的内积反映用户查询和文档的相似度,将查询结果按相似度的降序排列后提供给用户[1]。它们对用户的查询项进行精确匹配,因此只能反映用户所要检索内容的某一方面,无法保证语义概念上的匹配。而且算法效果与样本输入的次序和词频相关,只有当句子包含的词数足够多时,相关的词才会重复出现,其效果才能体现出来,因此该算法只适合于词频较大的大文档[2]。对于小文本文档,K均值聚类算法很难反映出其语义特征,检索效果较差。为此,笔者提出了一种改进型的K均值聚类算法,解决中小文档聚类问题。
1 改进型的K均值聚类算法

图1 传统K均值聚类算法流程图 图2 改进型的K均值聚类算法流程图
改进型的K均值聚类算法是在原有算法的基础上作如下改进:通过改进权重和特征向量表示来改进相似度的计算方法,即计算句子相似度时不仅考虑基于词频统计的特征向量表示法,而且结合词语间的关联度值,考虑了关键词之间的关系,减少了相似度对于输入次序和频数的敏感度,在某种程度上考虑了语义理解,有效的提高了计算小文档和简单句子相似度的准确度和文本聚类结果的准确率、召回率。其传统算法和改进算法流程如图1和图2所示。
由图2可知,改进型的K均值聚类算法对文档集进行切词预处理后,再作如下处理:①对文档中每个词进行权重计算,根据权重进行文本特征向量表示;②每个文档视为一个事务,文档中的关键词组视为事务中的一组事务项,执行关联规则算法,得出基于词与词的关联规则,并按照文中给出的算法求出词语间的关联度矩阵。然后由改进的相似度算法计算出句子间相似度值,执行K均值聚类算法得到几个簇的子集。
1.1特征向量表示和权重计算
关键词是组成文本的基本元素。关键词权重反映了该词对标识文本内容的贡献程度和文本之间的区分能力。各个关键词在不同文本中的出现频率满足一定的统计规律,因此可根据关键词的频率特性来分配关键词权重。文本空间被看作是由一组正交词条向量所组成的向量空间。每个文本表示为其中一个范化特征向量V(d) = {t1,w1(d);…;ti,wi(d);…;tn,wn(d)},其中,ti为词条项;wi(d)为ti在文档d中的权值。
1.2相似度算法改进
聚类分析按照样本在性质上的亲疏远近的程度进行分类。为了使类分得合理,必须描述样本之间的亲疏远近的程度[3]。刻画样本点之间的相似度[4]主要用相似系数。
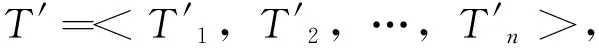
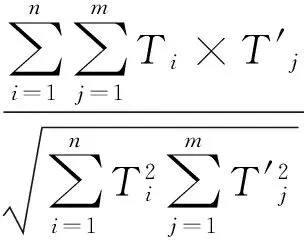
(1)
2)相似度算法改进的具体实现 虽然夹角余弦函数可以衡量2个文档之间的相似性[7],但它忽略各个向量的绝对长度,一个问题用一个句子还是用多个句子来表述时,其绝对长度相差很大,用式(1)计算不准确。为此,笔者提出了一种基于关键词相关性(关联度)的相似度计算方法。计算关键词的关联度时,依据是基于关键词的关联规则,将执行关联规则算法后得到的前件后件同时写入到关联表中,同时出现在一条记录中的关键词具有较大的相关性,其出现同一条关联规则的记录数越多,说明其相关度越大。若同现记录数为 0,其相关性设一较小默认值;若2个词相同,其相关度为1。
整个相似度改进分为2步,首先计算文档中关键词的关联度,形成基于关键词的关联矩阵;随后计算句子的相似度。
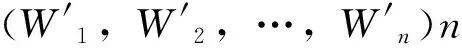
R=(Rij)n×m
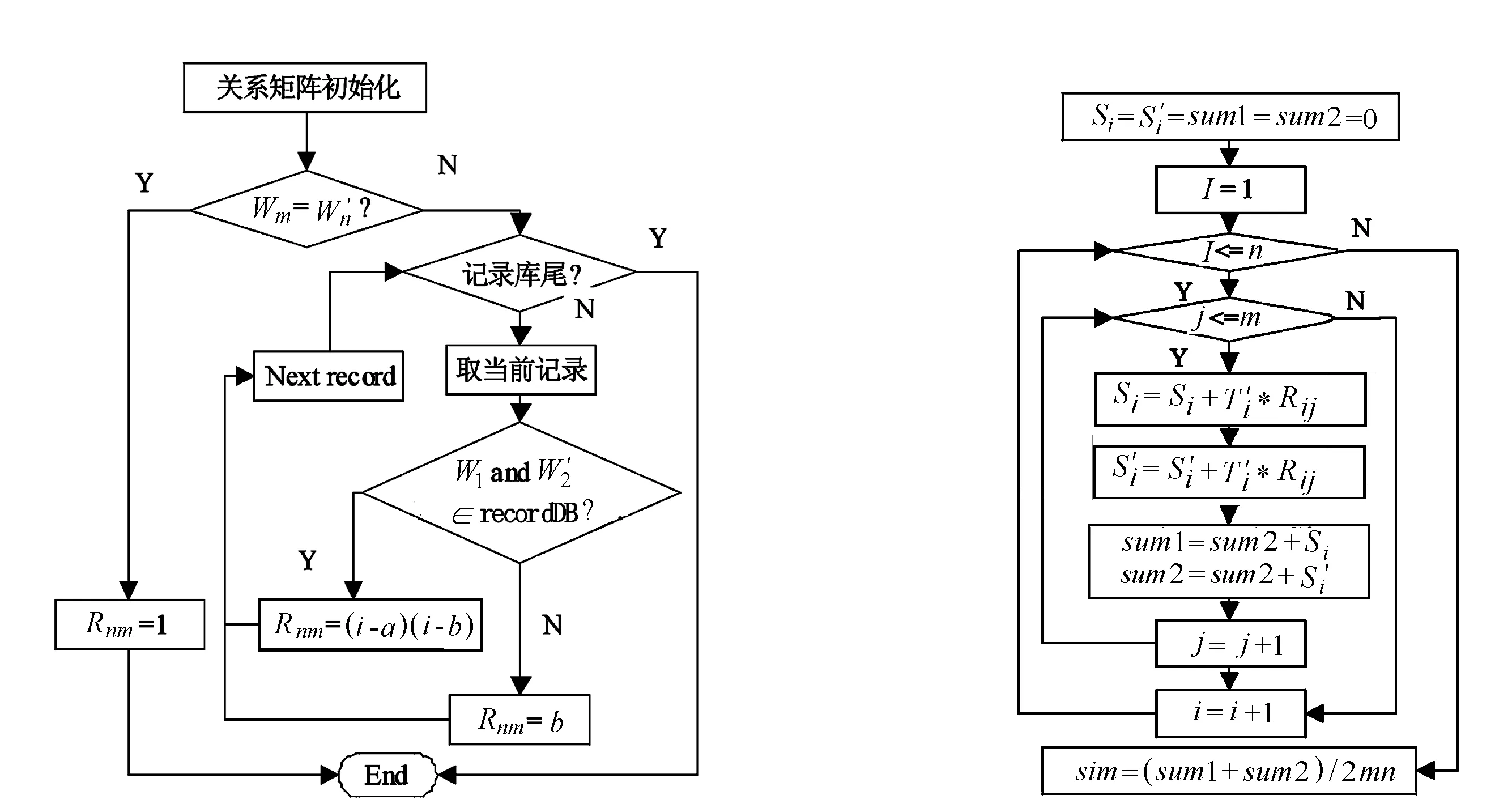
图3 关联度算法流程图 图4 相似度算法流程图
其中,Rij表示关键词Wn和关键词Wm的关联度。具体算法流程如图3所示。
图3的算法流程中,首先根据词频赋予其权重,并用特征向量表示,然后判断2个句子的权重是否相等,若相等,则令Rnm为1;否则判断Wn与Wm是否已经存在记录库中。若存在,令Rnm为(i-a)(i-b);不存在,则Rnm=b,直到记录库未为止。其中a与b的取值需要多次试验进行训练,它们的值与事务数是密切相关的,因此需要根据不同的事务数,确定适当的a与b取值。
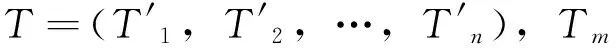
相似度算法如图4所示。
由于词语的出现频繁,使得权重值较大或者句子长度相差较大,经过试验得出的相似度值可能相差很大,这就造成这些数据对象出现孤立点问题,因此需要对这个孤立点进行处理。笔者采用将相似度归一化的方法来消除孤立点对聚类结果的负面影响[8],即句子之间的相似度可以转化成句子之间的隶属度问题,既不会去除这些点,又不会使之过多影响聚类效果。
2 试验结果与结论
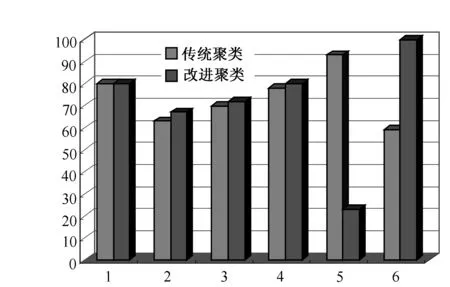
图5 系统聚类精度结果比较
试验分别采用传统聚类算法和改进型聚类算法进行,以k为参数,把n个对象分为k个聚类,使聚类内具有较高的相似度,聚类间的相似度较低。其中改进型的相似度的计算根据一个聚类中对象的平均值(k看作聚类的中心)来进行。试验选用智能答疑平台中计算机基础课程相关问题共300条,执行k-means 文本聚类算法。随机选择 6 个中心点,经过 6 遍中心点变化循环后停止,根据精确度和召回率,2种算法得出聚类结果如图5所示。
其中1、2、3、4、5、6 分别代表图像数据,网络数据,打印数据,文件数据流,数据库,智能信息几个方面的文档。由表5可看出,除了簇 5 之外,其他簇的改进型聚类算法精确度和召回率都比传统聚类算法的高,而簇 5即数据库方面的精确率比较低,可能的原因是数据库方面的文档较短,词频较少,因此权重值较小;或者与数据库方面相关的关联规则较少,求出的词语关联度较低或者不准确,以至于相似度计算不准确而造成聚类准确率较低。
3 结 语
笔者通过改进权重和特征向量表示,结合关联规则算法来改进相似度的计算方法,从而达到改进K均值聚类算法的关联矩阵来影响聚类的结果。试验结果表明,该改进方法对智能信息小文本的聚类有显著的效果。由于技术和科研条件不足,该系统还存在很多的问题,更大的适应范围和更有效的聚类结果始终是该系统不断努力的方向。
[1]王钦.基于数据挖掘的智能答疑系统的设计与实现[D].济南:济南大学,2007.
[2] 张正兰,李珊.一个支持自然语言提问的智能答疑系统的实现[J].微机发展,2009,30(8):1966~1968.
[3] 张同珍,申瑞民.基于 Web 的自动答疑系统问题匹配算法研究与实现[J].计算机工程与应用,2003,39(29):103~104.
[4] 田俊华.基于自然语言提问的自动答疑系统设计[J].应用资讯,2005,(1):48~51.
[5] 胡佳妮.文本挖掘中若干关键问题的研究[D].北京.北京邮电大学,2008.
[6] 薛德军.中文文本自动分类中的关键问题研究[D].北京:清华大学, 2006 .
[7] 郭庆琳,樊孝忠,柳长安. 基于文本聚类的自动文摘系统的研究与实现[J].计算机工程, 2006,(4):30~32.
[8] 尚文倩,黄厚宽,刘玉玲,等.文本分类中基于基尼指数的特征选择算法研究[J].计算机研究与发展, 2006,43(10):1688~1694 .
[编辑] 易国华
TP311
A
1673-1409(2009)02-N073-03
2009-02-27
赵鸣(1975-),男,1995年大学毕业,副教授,现主要从事人工智能技术、智能数据挖掘与知识发现方面的教学与研究工作。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
客联(2022年3期)2022-05-31
保定学院学报(2022年2期)2022-04-07
园林科技(2021年3期)2022-01-19
中国新闻周刊(2021年26期)2021-07-27
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
信息安全研究(2016年4期)2016-12-01
读者·校园版(2015年7期)2015-05-14
