
基于深度学习的监控视频浓缩方法
2025-01-10 00:00:00余科张磊王向阳李杲阳蒋长帅
物联网技术 2025年1期







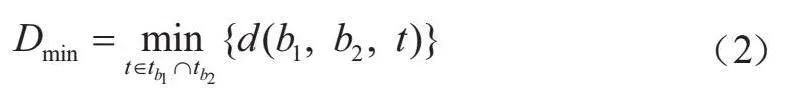
摘 要:视频监控作为一种有效的侦测手段,在公共安全领域被广泛应用。但是视频过长、浏览效率低下的问题长期困扰着相关人员。为此,文章提出一种高效的视频浓缩方法,该方法可以将几十小时的监控视频浓缩至几十分钟甚至几分钟。该方法采用YOLOv5算法检测并提取目标,对各目标的运动时空轨迹进行重排,再将各目标与背景融合,最终得到短时浓缩视频。实验结果表明,该方法既能有效缩短监控视频时长,又能保留视频中的重要信息,是一种高效、实用且具备一定推广价值的视频浓缩方法。
关键词:视频监控;视频浓缩;目标检测;背景建模;时空轨迹;深度学习
中图分类号:TP391.41 文献标识码:A 文章编号:2095-1302(2025)01-0-04
0 引 言
近年来,随着社会安全保障体系的不断完善,在路口、商场、车站等各类公共场所部署着大量的安防摄像头。在追捕犯罪分子时,这些监控视频可以为公安侦查提供依据。然而,一个案件往往涉及的视频录像长达几十甚至数百小时,需要多名侦查人员通过快进浏览的方式进行查看,这一过程耗时费力,效率低下,且容易错失破案的关键时机。如何在有限时间内(即数分钟内),实现对数小时视频内容的高效浏览,同时确保不遗漏视频中的任何关键目标,是一项重大的挑战。在此背景下,视频浓缩技术应运而生[1-2]。该技术高度面向应用且具有广阔的应用前景。
视频浓缩的显著特性是可在数分钟内浏览数小时视频录像中所有的活动目标,浏览浓缩视频可极大地缩短查看原始视频的时间,提高效率和人工识别的准确性。在公安部门的视频调查中,侦查人员通过浏览浓缩视频,可以快速锁定可疑人员,为追踪逃犯以及寻找案件线索提供有力支持。此外,对于监狱和银行等重点安全区域,安保人员可以定期查看浓缩视频,及时发现并弥补安全漏洞,防止意外发生[3]。
视频浓缩,又称动态视频摘要,可以对长时视频进行时长缩短,从而实现监控视频的快速查看[4]。视频浓缩可以看作是对视频内容的一个简单概括,以自动或半自动的方式,先通过分析运动目标,提取运动目标,确定目标的运动轨迹。随后,对目标的时空状态进行分析,并对其进行组合优化,将不同时刻的目标融合到背景图像中,以达到缩减视频时长的目的。通过视频浓缩,一段长达几个小时的监控视频,可以被浓缩到几分钟,同时在浓缩后的视频中仍然可以查看原始视频中的各种事件[5]。视频浓缩技术原理示意图如图1所示。
1 本文方法
为了准确地提取目标的运动轨迹,本文首先采用YOLOv5算法对输入视频进行目标检测。然后,利用卡尔曼滤波器和匈牙利算法进行目标跟踪和轨迹匹配[6],从而获取移动目标的基本信息。最后,使用背景建模技术提取视频背景,对目标对象进行重排,再利用图像叠加技术生成浓缩视频。本文方法的流程如图2所示。
1.1 背景建模
背景建模[7]的目的是获得不含运动目标信息的静态背景图像,通过将图像中的背景与前景分离,能够更好地进行后续处理。本文采用平均背景建模方法,该方法效果优异、计算速度快,适用于大多数场景。
均值背景法[8]是指通过对多幅图像求平均值来得到图像的背景,即对一段时间内若干不变化或者变化缓慢的像素点求平均值,并对所得平均值进行回归处理,即可作为背景图像的灰度值。
该方法的实现流程如下:
(1)输入一段视频序列,对其按照每秒30帧进行采样,得到N帧图像f。
(2)每帧图像的每个像素点为(x, y),对上述N帧图像的像素求均值,得到背景图像。背景建模方法如式(1)所示:
(1)
式中:f(x, y, i)是第i帧图像,其中i = 0, 1, 2, 3, ..., N;Background(x, y, i)为第i帧的背景图像,背景图像中每一个像素点的值为该像素点N帧图像灰度的累加平均。
1.2 目标检测
由于监控视频包含的运动目标种类众多,为了实现高效压缩和检索,视频浓缩系统必须识别出有价值的对象,如在安防系统中,主要需要对人车进行识别。为了得到高效精确的检测结果,本文采用基于深度学习YOLOv5框架的目标检测算法。
YOLOv5通过调整模型的宽度和深度来有效控制模型的参数量和计算量,据此衍生出了YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x等网络结构。其中,YOLOv5s的参量和计算量相对较少。整体而言,YOLOv5s模型由输入端(input)、主干特征提取网络(backbone)、特征融合网络(neck)、检测头(head)等核心部分组成。这些组件共同协作,确保模型能够实现高精度的目标检测任务。
网络输入的图像大小为640×640,采用Mosiaic数据增强,可以有效提升模型的训练效率和检测精度,对于小目标检测也有良好的效果。针对不同数据集,可以采用自适应锚框计算,该方法能够针对每个训练集自适应计算出最佳锚框值。针对图像的不同长宽比,还可进行自适应图像缩放。
1.3 轨迹组合优化
不同时间段出现的运动目标在同一背景下可能会出现轨迹碰撞以及重叠的情况[9],需要对其进行优化,使不同目标尽量不出现重叠,同时占用更少的视频时长。在实际应用中需要能够判断各目标之间的交互作用。如果2个目标距离越小,那么目标之间发生作用关系的可能性就越大。本文设定了一种轨迹交互状态判断机制,可以看作是目标中心点距离的最小估计Dmin,如式(2):
" " " " " " "(2)
在时间段内,存在轨迹b1和b2,那么Dmin就等于t时刻对应的图像中检测框中心点的欧氏距离。如果,那么轨迹b1和b2对应的目标为2个相互独立的目标。
选定阈值DT,当Dminlt;DT时,视为2个目标之间存在相互干扰,在整个视频时间T内,不断判定,将存在相互干扰动作的运动目标归为一组,后续轨迹优化时,每个分组都被视为一个整体。
1.4 图像融合
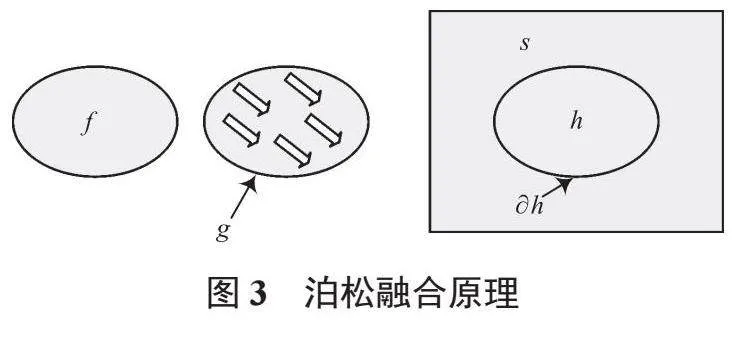
图像融合是指将2幅不同的图像融合为一幅图像[10-11],其中最有代表性的是泊松融合[12]。设定泊松方程并对其求解最优值,从而达到无痕融合的目的。一张图像的主要细节均由梯度体现,该算法的核心思想是保留图片的梯度信息。
泊松融合原理如图3所示。其中,f是待融合目标;g是目标f的梯度;s是背景图片;h是目标f融合的区域; h为边界条件,其主要由背景图片s的像素值决定。泊松融合的实现可以概括为在给定边界条件的前提下,求h区域中的每个像素,从而使区域的梯度接近甚至与g相同。
本文中泊松融合的具体流程如下 :
(1)分别计算识别到的目标框图像A和静态背景B的梯度场;
(2)用图像A对背景图片B上相对位置的梯度场进行覆盖,然后计算融合后的梯度场T;
(3)对融合后的梯度场T进行求导,获得融合后的图像散度S;
(4)进行泊松重建,求解泊松方程组,可得融合图像的像素值。
2 实验与结果分析
本文选用一段路口的监控视频进行实验,该场景较为复杂且布置在室外。图4所示分别为原始视频第1帧、第157帧、第272帧的图像。在第157帧,图4(b)画面左侧正在看书的男士出现;在第272帧,图4(c)画面右下角背包女士出现。未在视频第1帧画面中出现的目标是实验中重点关注的目标。
本文提出的背景建模方法的效果如图5所示。图5(a)为采用高斯混合模型分离算法(MOG)提取的背景。通过实验发现,使用该方法无法完全消除前景干扰,其提取的背景中存在一些运动目标的重影。图5(b)所示是采用均值背景法提取的背景,该方法能够有效消除前景干扰,且随着输入视频图像时长的增加,前景所带来的干扰也会越来越小。
使用YOLOv5检测算法得到的目标检测结果如图6所示。在安防领域中主要检测目标为人,在以车为主要目标的场景中也可以只对车进行检测,检测目标具有针对性,可以排除动物等不相干目标的干扰。在实际代码运行中,系统会保留目标周围1.2倍大小的区域,这样能够获取更丰富的目标信息,同时也更有助于后续的图像和背景融合。
图7所示为本文方法在街道路口的监控视频浓缩结果。可以看到,在原始视频157帧左右出现在图像左侧的男士和272帧左右出现在图像右侧的女士在浓缩视频的第1帧已经出现。对于原始视频中不同时间段出现的多个目标,本文实现了在同一背景下的聚合展示,且融合效果良好。
原始视频时长为10 s,经过浓缩,时长缩减为4.3 s,浓缩比为0.43。主要因为原始视频中若干个目标一直存在于镜头中,若场景中目标较为稀疏,视频时长有望进一步得到压缩。
3 结 语
本文提出了一种基于深度学习的监控视频浓缩方法,使用YOLOv5目标检测方法对视频中的目标进行提取,同时采用均值背景法对背景进行建模,后续的目标轨迹优化为新的浓缩视频目标运动提供了依据;最后采用泊松融合方法实现多目标和背景图像的融合,将不同时刻的目标在固定背景下进行重排展示,达到了压缩视频时长的目的。实验结果表明,本文方法效果良好,能够应对多种场景,可以为安防侦查提供可靠依据,并且能够显著提高视频浏览效率。
但是本文方法也存在一些不足,首先是个别时段会存在误检漏检的情况,后续将着手从提供更加完善的标注数据集以及优化检测算法这两方面进行改进。其次是针对不同时刻目标轨迹碰撞的问题仍需优化。
参考文献
[1] BASKURT K B, SAMET R. Video synopsis: A survey[J]. Computer vision and image understanding, 2019, 181: 26-38.
[2]张云佐,郭亚宁,李文博.融合时空切片和双注意力机制的视频摘要方法[J].西安交通大学学报,2022,56(12):127-135.
[3]徐达. 基于深度学习的视频摘要方法研究与实现[D]. 南京:南京邮电大学,2023.
[4] ANURADHA K, ANAND V, RAAJAN N R. An effective technique for the creation of a video synopsis[J]. Journal of ambient intelligence and humanized computing, 2020: 1-6.
[5]李林翰.基于对象相似性的视频浓缩技术研究[D]. 武汉:华中科技大学,2018.
[6] 蔡恬,林哲.融合深度学习目标识别的监控视频摘要浓缩方法[J].现代计算机,2020(24):49-53.
[7] 樊香所,文良华,徐兴贵,等.改进特征空间的红外弱小目标背景建模法[J].科学与电子信息学报,2023,21(9):1109-1116.
[8]葛钊,赵烨.一种基于最短路径的视频摘要方法[J].合肥工业大学学报(自然科学版),2021,44(2):193-198.
[9] RA M, KIM W Y. Parallelized tube rearrangement algorithm for online video synopsis [J]. IEEE signal processing letters, 2018, 25: 1186-1190.
[10] YUNZUO Z, TINGTING Z. Object interaction-based surveillance video synopsis [J]. Applied intelligence, 2020, 8(4): 4648-4664.
[11]王浩,彭力.基于改进的全卷积网络的视频摘要算法[J].激光与光电子学进展,2021,58(22):415-423.
[12]何炳阳,张智诠,杨建昌,等.红外和可见光图像泊松融合算法[J].光子学报,2019,48(1):172-181.
猜你喜欢
软件(2016年4期)2017-01-20 09:38:03
科教导刊·电子版(2016年28期)2017-01-10 22:25:23
科技创新与应用(2016年33期)2016-12-17 14:59:01
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
电脑知识与技术(2016年26期)2016-11-24 18:19:53
电脑知识与技术(2016年24期)2016-11-14 01:59:47
数字技术与应用(2016年9期)2016-11-09 23:10:41
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
