
多分支结构和双池化注意力机制的RetinaNet行人检测
2025-01-10 00:00:00凌以运王智白云谢世步韦秋伶何雨鲜
物联网技术 2025年1期
关键词:行为分析












摘 要:行人检测技术结合行人跟踪和行为分析等技术,可广泛应用在交通、安防和机器交互等与人们生活息息相关的领域,但行人的多尺度变化一直是行人检测的难点。针对传统RetinaNet算法在多尺度行人检测过程中存在的误检、漏检和检测精度低等缺陷,提出一种改进的RetinaNet算法来提升网络模型的检测能力。主要有以下两方面创新:首先,为了获取到更多的语义信息,采用多分支结构来扩展网络,以提取不同深度下不同感受野的特征;其次,为了使模型更关注行人特征的重要信息,在模型预测头部分嵌入双池化注意力机制,增强通道间特征信息的相关性,抑制不重要的信息,以提高模型的检测精度。在COCO等不同的数据集上进行实验,结果表明,与传统的RetinaNet模型相比,所提出的模型在各个评价指标上均有所提升,具有良好的性能,可以满足行人检测的需要。
关键词:行人检测;RetinaNet;多分支结构;行人特征;双池化注意力机制;行人跟踪;行为分析
中图分类号:TP391 文献标识码:A 文章编号:2095-1302(2025)01-00-06
0 引 言
行人检测是一项能够从图像或视频中准确地检测出行人以及行人位置的技术,该技术可以应用到生活中的各个领域,例如其在自动驾驶和智能安防等领域都起到了重要的作用[1]。随着人工智能的发展,深度学习技术越来越成熟,对当今社会的发展具有重要的价值和意义。基于深度学习技术的行人检测已经成为了当前研究的热点[2-3],经过不断的创新和发展,已取得了较好的成果。按照不同的研究方法可以将行人检测技术分为基于传统特征提取的行人检测和基于深度学习的行人检测。
随着神经网络的快速发展和广泛应用,目标检测方法的性能得到了很大程度的提升。基于深度学习的目标检测算法可以分为2个阶段:第一阶段的SSD算法[4]、YOLO系列算法[5]、RetinaNet算法[6]等目标检测算法是基于逻辑回归的检测算法,检测速度快,但精度较低;第二阶段的R-CNN算法、Faster R-CNN算法[7]等是基于候选区域选择的算法,检测速度慢,但是精度高。因此,这两类算法各有优缺点。随着各项技术的不断提高,研究者们开始致力于突破行人检测的难点。
行人的多尺度问题一直是行人检测过程中的难点,因为在不同的距离和视角下,图像或视频中的行人呈现出的尺寸大小不一致,还伴随着遮挡和图像模糊的情况,不利于机器检测。针对以上问题,本文将RetinaNet模型应用于行人检测中,并在此基础上提出了基于多分支结构和双池化注意力机制的RetinaNet行人检测。本文的主要贡献总结如下:
(1)通过添加多分支结构来增强主干网络和特征金字塔之间的联系,扩展网络宽度,多方位提取不同深度下的多尺度行人特征信息,提升特征的表达能力。
(2)改进了注意力机制,提出使用双池化注意力机制来增加关键特征信息的权重,使模型更注重关键特征信息。
1 多分支结构和双池化注意力机制的RetinaNet算法
1.1 整体结构
针对行人的多尺度问题采用多尺度预测方法能解决部分困难。大尺度的行人特征明显,经过多次卷积后仍然能够提取到语义信息;但小尺度的行人分辨率低,包含的特征信息少,存在着特征提取不充分或者经过多次的卷积后语义信息丢失的问题,容易导致漏检。因此要采用合适的方法充分地提取多尺度行人的信息,保证语义信息不丢失。本文设计了图1所示的网络结构,将多分支结构应用在RetinaNet模型中的主干网络与特征金字塔之间,即在C3、C4、C5层的横向连接处增加多分支结构,以此充分提取并高效利用特征信息,增加特征的多元化。在浅层网络,能够捕获细致的纹理信息;在中层网络,通过多尺寸的感受野和池化操作可以捕获多样化的特征信息;在深层网络,对抽象的特征进行提取,既能够增强网络对不同尺度目标的分析能力,又能够加深和加宽网络,进而有效提取到多层次的信息。在特征金字塔与预测分支之间添加双池化注意力机制,对每个经过特征融合后的分支进行信息筛选,使模型关注更有用的行人特征信息,增强网络的检测性能,使预测更加准确。
1.2 多分支结构
一般来说,在神经网络模型中,通过扩展模型深度和宽度能够提高模型的表现能力,但也存在着副作用。由于随着神经网络层次的加深,会产生许多参数,甚至导致过度拟合,由此一来不仅训练成本高,而且效率低。使用Inception网络结构则可以很好地解决这一问题。不同于之前的大多数网络直接将卷积层堆叠起来以得到深度的网络,文献[8] 提出利用Inception模型通过稀疏连接,设置多个不同尺度的卷积核并行结构,再拼接特征,由此扩大网络的宽度和深度,使模型拥有更好的性能。通常使用大的卷积核能够提取到距离像素点较远的信息,使用小的卷积核可以提取到距离像素点较近的信息。传统意义上较大的卷积核具有更好的感受野,但是在运算过程中容易丢失部分重要的信息。Inception网络结构通过分解卷积核将单个较大的卷积分解成对称小卷积或者非对称卷积,在增加网络宽度和深度的同时减少参数量。采用分解卷积,在不改变感受野的同时,还能降低参数量,提升模型的非线性表征能力。使用3×1和1×3卷积连续滑动后组合,其感受野等效于3×3卷积的感受野。
本文采用的多分支结构如图2所示,将输入分成4个分支并行,每个分支先运用1×1卷积获取图像的相关信息,减少特征通道数,降低维度;通过减少通道数来聚合信息,使特征在深度上被叠加。
在网络中通过较小的卷积尺寸能够更好地捕获图像相邻区域的细节信息,并且信息相关性较高;再运用多尺度卷积核在深度不一的网络中进行卷积,获取多尺度的感受野,将细节特征转换为高级语义特征;然后将从不同支路得到的结果按照通道拼接,聚合了所有分支的特征信息后得到多通道特征图,最后输出结果。
本文采用的特征融合方式是拼接,由于使用了较多的卷积来提取图像信息,因此在维度上进行叠加操作可以更有效地实现信息的完整融合。
多分支结构表达式为:
(1)
式中:F表示卷积;X表示输入图像;Xi(i=1, 2, 3, 4)表示4个分支的结果;Xout表示输出结果。多分支结构的设计不是盲目地增加深度和宽度,而是通过Pooling操作来保持信息不变,起到防止信息丢失的作用;通过分解特征,充分利用信息,提高特征内部的相关性;利用更小的卷积核进行降维,使网络的深度和宽度达到平衡。
1.3 双池化注意力机制
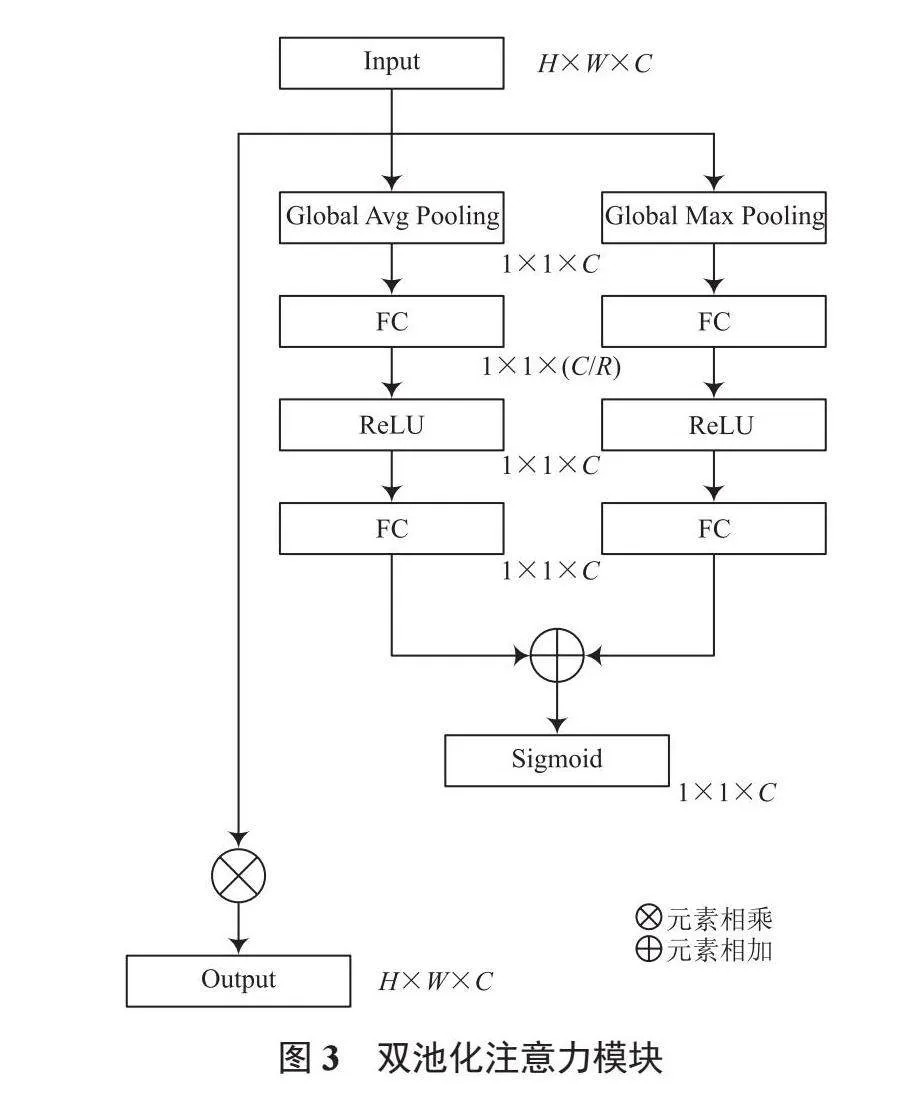
特征层在不同的通道所携带的信息不同,通道相关性也不一样,由于单一的池化操作不能完整地反映整个图像的特征信息,容易导致部分重要信息丢失。鉴于此,结合全局平均池化和最大池化的作用,选择双池化的注意力机制来获取更全面的特征信息。双池化注意力模块如图3所示。
双池化注意力模块由3个并行的部分组成:
(1)第一个分支X1完成特征映射。
(2)第二个分支X2先进行全局平均池化,全局平均池化让卷积结构更简单,能够压缩输入特征,减少参数量,达到优化网络结构、防止过拟合的目的,再依次经过全连接层、激活函数、全连接层,如式(2)所示:
(2)
式中:FC表示卷积;X表示输入图像;α表示ReLU激活函数。
(3)第三个分支X3与第二个分支类似,不同的是该分支采用了最大池化来聚合特征信息,学习新的权重,如式(3)所示:
(3)
最后将第二分支X2和第三分支X3所提取的特征逐元素相加融合,经过Sigmoid激活函数,再将输出与第一分支X1的原始特征结合进行元素相乘,得到加权后的特征并输出结果,用式(4)表示:
(4)
式中:β表示Sigmoid激活函数;Xout表示输出结果。
双池化注意力模块的参数见表1。其中,H和W表示图像的高和宽,C为通道,R为通道因子。
1.4 损失函数
模型的训练过程就是使误差不断减小的过程。本模型的训练采用的损失函数为定位损失和分数损失函数。损失计算公式为:
(5)
定位损失函数Lreg采用的是smooth L1 Loss函数,具体公式为:
(6)
式中:x为预测框与真实框的差值。
分类损失Lcls使用的是Focal Loss函数,具体公式如下:
(7)
pt (8)
式中:pt表示正样本的概率;y表示真实标签的值;αt为调节因子,当负样本数较多、正样本数较少时,可以用来改善正负样本的分布权重;γ为聚焦参数,可有效降低较容易检测样本的权重,将训练过程集中于较难检测的样本。由此,通过Focal Loss函数解决了容易检测和难检测样本的不平衡问题,从而提升了模型的精度。经过实验可知,αt=0.25、γ=2时,能提高正样本的权重、减小负样本的权重,达到较好的检测效果。
2 实验结果与分析
2.1 实验环境
实验环境配置为:操作系统采用Windows;CPU采用Intel i7-8700处理器;GPU采用GTX1080 10 GB;深度学习框架采用Pytorch。
2.2 实验数据
为了丰富行人数据集,使结果更具有真实性,本实验使用不同的数据集进行检测。
数据集1是从COCO数据集和PASCAL VOC数据集中挑选出的带有“person”标签图片的混合数据集,共3 288张,包含了生活中各个场景和尺度的目标图像,并且按照8∶2划分训练集2 630张,测试集658张。
数据集2是Caltech行人数据集,是由美国加州理工大学通过车载摄像头拍摄的,图片的分辨率为640×480,约含有25万张图片、35万个行人框。将该数据集分为训练集和测试集。Caltech行人数据集的数据量较多,包含不同尺度的行人,本文选择其中带有标签“person”的图片作为实验数据,其中4 310张图片构成训练集,4 225张图片构成测试集。根据文献[9],按照行人在图像中的高度,将测试数据集划分为多个不同尺度等级的子集,划分准则见表2。
2.3 实验参数
本文实验使用的模型是改进的RetinaNet行人检测算法模型。为了让神经网络达到更好的预测效果,训练时的输入图像大小为512×51,batch为8,优化器为Adam,初始学习率为1×10-4,学习率的下降方式使用余弦退火法,动量为0.9,权重衰减为0。通过观察本文算法在150个epoch训练过程中损失的变化判断训练的效果。结果表明,随着训练epoch的增加,Loss曲线呈现出下降的趋势并且越来越平滑,在0.05左右趋于稳定,达到收敛状态,说明在训练过程中效果达到最优。
2.4 评价指标
为了更好地评估网络模型的检测性能,针对不同的数据集,采用了不同的算法与评价指标来验证模型。在混合数据集中,选择以下指标作为本模型的评价指标:
(1)准确率(Precision):表示预测为行人的数量占原样本行人的比例,其值越大说明误检的目标越少。表达式为:
(9)
(2)召回率(Recall):表示行人数据集中行人被预测为正例的比例。表达式为:
(10)
式(9)和式(10)中:TP表示行人正样本被正确检测的数量;TN表示图片中行人负样本被正确检测的数量;FN表示把真实行人样本检测为负样本的数量;FP表示图片中负样本被检测为正样本的数量。
(3)F1分数:是精确率和召回率的一种加权平均,即精确率和召回率的调和平均数。表达式为:
(11)
(4)AP:是在IOU阈值下的平均精度,表示被Precision与Recall曲线包围的区域。表达式为:
(12)
(5)mAP:是全部目标种类的平均精度,此值越高,模型的识别精度越高。表达式为:
(13)
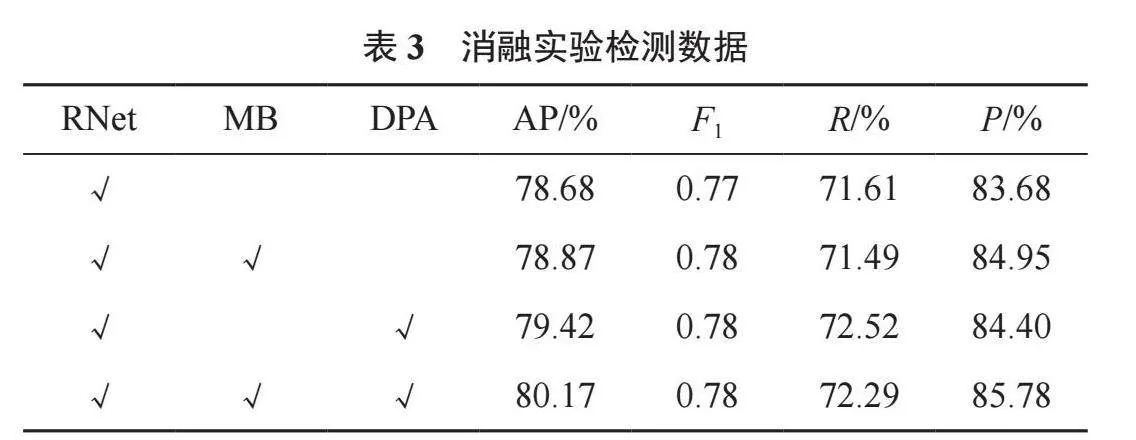
本文研究的检测目标仅有人,因此mAP等于AP。由式(13)可知,mAP结合了精确率和召回率,考虑到了假阳性和真阳性,因此大多数检测模型使用该值作为合理的评价指标。加入多分支结构时,算法的mAP达到了78.87%,提高了0.19个百分点,增强了特征的表达能力,检测性能得到小幅提升。加入注意力机制时,算法的mAP达到了79.42%,提高了0.74个百分点,召回率和准确率提高了0.91个百分点和0.72个百分点,说明注意力机制进一步加强了重要特征权重。同时加入2个模块时,整体mAP指标达到了80.17%,提升了1.49个百分点,召回率提升了0.68个百分点,准确率提升了2.1个百分点。 以上数据证明,各模块都使模型性能有不同程度的提高,对于提升网络性能方面有巨大帮助。
图4所示的传统RetinaNet与本文算法的可视化检测结果更直观地凸显了本文算法在检测性能上的优势。由图4(a)可以看出,本文算法可以较好地检测出遮挡的人和不同尺度的人。
2.5 在混合数据集上的实验结果
2.5.1 消融实验
为验证本文所添加的多分支结构和双池化注意力模块对模型的作用,进行消融实验。实验数据见表3。
2.5.2 对比实验
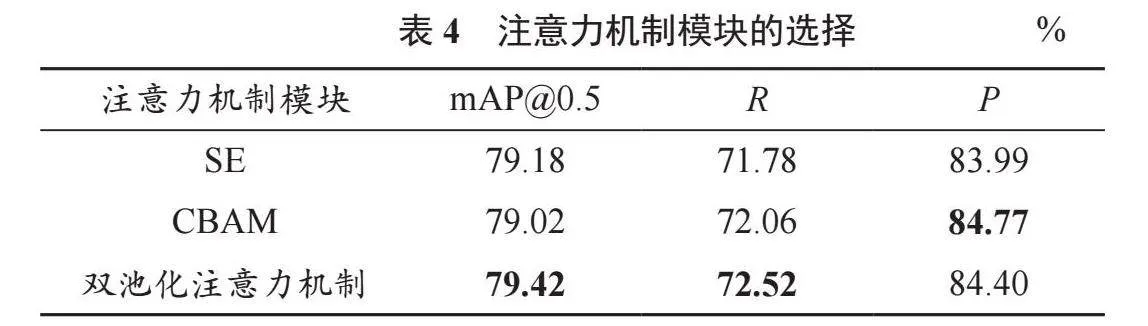
为证明上文提到的双池化注意力机制模块的效果,选择SE和CBAM模块做对比实验,实验检测结果见表4。
从表4可以看出,3种注意力机制都可以使基础RetinaNet的网络检测性能有所提升,而本文提出的双池化注意力机制的mAP高于SE和CBAM模块,表明其对行人特征信息的专注力更胜一筹。
本文算法与SSD算法的可视化检测效果对比如图5所示。
从与SSD的对比图中可以看到,SSD算法对中小尺度行人的检测效果不理想,小尺度行人的漏检情况严重,而本文算法可以准确地检测出小目标,在单阶段的SSD算法中,本文提出的算法也有比较好的结果。同样地,由图6所示的本文算法与Faster R-CNN算法的可视化检测效果对比情况可以看出,本文算法的检测效果更好。
2.6 在Caltech数据集上的实验结果
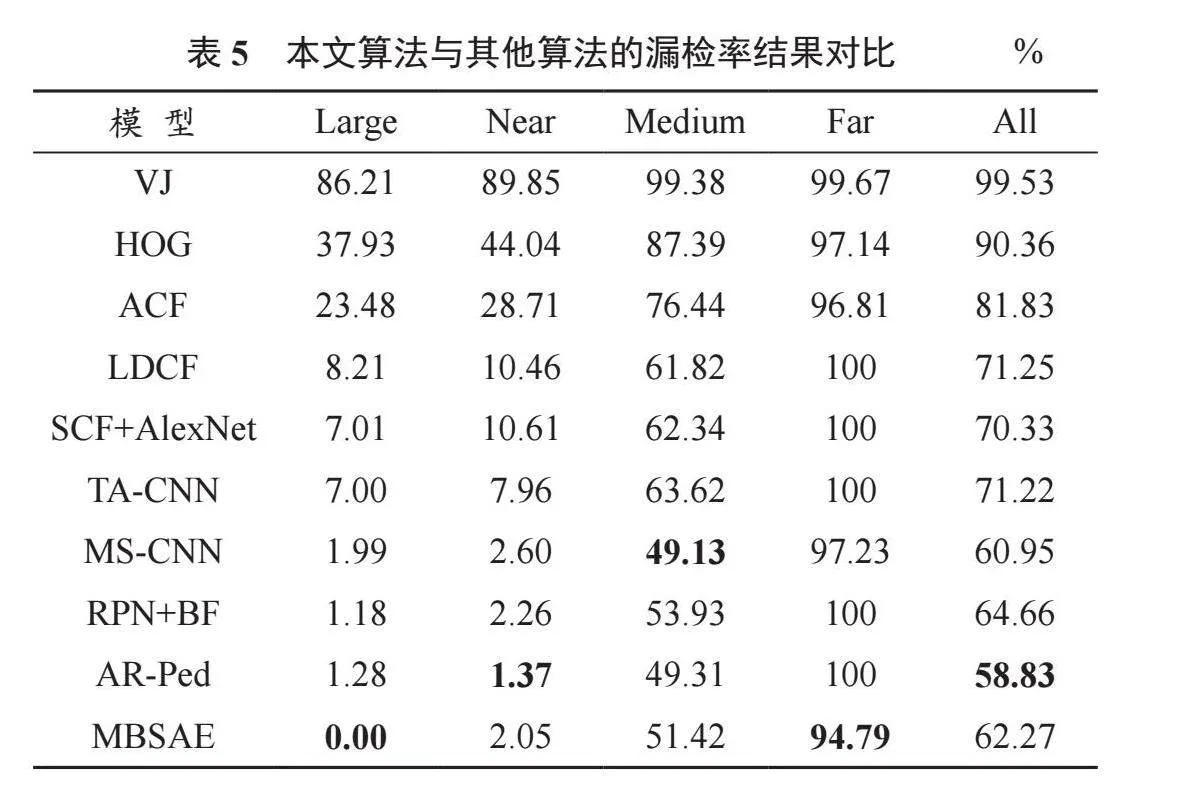
Caltech数据集明确地区分了行人的尺度范围,可以更好地了解各个尺度上行人的检测情况[10-11]。改进后的RetinaNet模型在各个尺度下的漏检率都有不同程度的下降。在大尺度(Large)上的效果较好,漏检率下降至0,在中尺度(Medium)上的漏检率下降了0.72个百分点,在小尺度(Far)上的漏检率下降了1.44个百分点,整体子集(All)下降了1.18个百分点。多分支结构和注意力机制的加持让RetinaNet模型的特征提取能力增强,能够对较为关注和感兴趣的行人特征信息进行精准捕捉。
本文采用不同的算法在Caltech数据集上进行实验,其中包括采用传统的手工特征的方法:ACF、LDCF等,以及深度学习的方法:RPN+BF、MS-CNN等。本文提出的多分支结构和注意力机制的算法(Multi Branch Structure and Attention Mechanism, MBSAE)与上述方法的漏检率对比结果见表5。
采用本文算法和RetinaNet算法在Caltech数据集上的图片检测结果如图7所示。
由图7可知,当远处多个小尺度的行人并排出现时,RetinaNet算法出现了严重的漏检和误检情况,而本文改进的算法能更好地检测到远处与近处的行人,说明本文提出的改进方法具有更强的检测能力。
经过以上实验证明,通过多分支结构设计多尺寸的卷积核能够检测到更多不同尺度的目标,充分获取图像特征信息;注意力机制能够抑制非相关的信息使模型对相关信息赋予更多的关注,增强模型的多尺度检测能力。在数据集上的检测结果充分证明,本算法能适应多尺度的行人检测,在检测精度上有着明显的效果,一定程度上证明了本文改进的模型在行人检测方面的适用性。
3 结 语
本文针对传统的RetinaNet算法在多尺度行人检测上的不足进行改进和优化,通过添加多分支结构作为特征增强模块,增加了网络的宽度,提升了模型的非线性表征能力,使其能够提取丰富的多尺度特征。为了使模型能够更专注地检测重要信息,添加双池化注意力模块,抑制了不重要的信息,使模型的检测准确率得到进一步提升。在公开的数据集中将本文算法与其他算法进行对比,本文算法的检测精度达到了80.17%,充分证明了本模型拥有较好的检测能力和较好的泛化能力。在今后的研究中,将继续对模型进行优化,考虑采用迁移学习和对抗网络的方法丰富数据集,提升模型的检测精度和速度,继续解决模型应用于雨、雾、雪天等恶劣环境时的检测难题,使其能更好地完成行人检测的任务。
注:本文通讯作者为王智文、白云。
参考文献
[1] REN J, HAN J. A new multi-scale pedestrian detection algorithm in traffic environment [J]. Journal of electrical engineering amp; technology, 2021, 16(2): 1151-1161.
[2] NATAPRAWIRA J, GU Y, GONCHARENKO I, et al. Pedestrian detection using multispectral images and a deep neural network [J]. Sensors, 2021, 21(7): 2536.
[3] JI Q G, CHI R, LU Z M. Anomaly detection and localisation in the crowd scenes using a block‐based social force model [J]. IET image processing, 2018, 12(1): 133-137.
[4] ZHOU H, YU G. Research on pedestrian detection technology based on the SVM classifier trained by HOG and LTP features [J]. Future generation computer systems, 2021, 125: 604-615.
[5] HE L,WANG Y X, CHEN G Y. The hierarchical local binary patterns for pedestrian detection [C]//2021 5th CAA International Conference on Vehicular Control and Intelligence (CVCI)." Tianjin, China:IEEE, 2021: 1-8.
[6] KUMAR K, MISHRA R K. A heuristic SVM based pedestrian detection approach employing shape and texture descriptors [J]. Multimedia tools and applications, 2020, 79: 21389-21408.
[7] LI G, ZONG C, LIU G, et al. Application of Convolutional Neural Network (CNN)–adaboost algorithm in pedestrian detection [J]. Sensors and materials, 2020, 32: 1997-2006.
[8] SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. [S.l.]: IEEE, 2016: 2818-2826.
[9] MIHCIO LU M E, ALKAR A Z. Improving pedestrian safety using combined HOG and Haar partial detection in mobile systems [J]. Traffic injury prevention, 2019, 20(6): 619-623.
[10]王子元,王国中.改进的轻量级YOLOv5算法在行人检测的应用[J].数据与计算发展前沿,2023,5(6):161-172.
[11]毛雨晴,赵奎.基于改进YOLOv5的多任务安全人头检测算法[J].计算机工程,2022,48(8):136-143.
猜你喜欢
东方教育(2016年6期)2017-01-16 20:51:05
现代电子技术(2016年23期)2017-01-12 09:40:23
电子技术与软件工程(2016年20期)2016-12-21 11:43:17
新课程·中学(2016年9期)2016-12-01 11:10:27
电子技术与软件工程(2016年18期)2016-11-14 01:46:35
电脑知识与技术(2016年23期)2016-11-02 23:43:18
经营者(2016年12期)2016-10-21 09:12:11
考试周刊(2016年60期)2016-08-23 17:14:23
中国科技博览(2016年9期)2016-04-25 05:50:16
商(2016年6期)2016-04-20 09:44:12
