
基于Python 爬虫的招聘信息采集与分析
2024-12-15 00:00:00崔晓青
电脑知识与技术 2024年34期




摘要:本文利用Python爬虫技术,从天津电子信息职业技术学院就业信息网采集近五年招聘信息,并运用数据采集、预处理和可视化分析方法,揭示了该院毕业生就业地区分布、岗位需求及专业匹配度等趋势,为学生职业规划和就业指导提供数据支撑。
关键词:Python爬虫;招聘信息;采集;处理;可视化分析
中图分类号:TP311文献标识码:A
文章编号:1009-3044(2024)34-0057-03开放科学(资源服务)标识码(OSID):
0引言
高校就业形势日益严峻,各方积极努力为毕业生创造良好就业环境。高校就业信息网的建设为毕业生提供了便捷的就业信息获取渠道,但也面临着信息量庞大、检索难度增加的挑战。
为解决这一问题,本文基于天津电子信息职业技术学院就业信息网数据,利用Python爬虫技术,对近五年招聘信息进行采集、处理和可视化分析,为学院就业指导工作提供数据支持。
1招聘信息爬取研究现状
在国内,众多学者已经开始应用网络爬虫技术收集与整理招聘信息。现有研究已利用Python、Jsoup、Scrapy等技术对招聘信息进行爬取和可视化分析,主要关注岗位技能、工作年限、薪资水平等方面。例如,郭瑾[1]通过Matplotlib库面向主流招聘网站分析。张鹏[2]基于Jsoup对BOSS直聘信息筛选判断。郑灿伟等[3]使用基于Scrapy框架分析招聘数据。高凤毅等[4]使用Matplotlib从某招聘网站进行关键词整理筛选。
本文在此基础上,通过设计爬虫模型完成数据信息的获取和可视化展示,进一步探究天津电子信息职业技术学院毕业生就业现状与趋势。
2技术概述
2.1技术方案
Python爬虫技术指利用爬虫程序自动抓取网络数据的一种技术。Python语言在易用性、库支持及数据处理能力等方面具有显著优势。使用Python爬虫技术可以实现在海量数据中实时准确地采集目标数据,并进行智能化分析和处理,挖掘出数据背后潜在的价值与意义[5]。
使用Requests库发送HTTP请求,获取网页数据。Requests库简化了HTTP请求的发送过程。它能够发送各种HTTP请求(如GET、POST、PUT、DELETE等),并自动处理cookies、重定向、超时等问题。
使用JSON库解析网页数据。JSON库是Python标准库中专门用于处理JSON数据的工具。作为轻量级数据交换格式,它简单易读且便于编写。JSON库提供了几个主要功能:dumps用于将Python对象编码成JSON字符串,loads用于将JSON字符串解码成Py⁃thon对象,dump用于将Python对象写入到文件中(以JSON格式),load用于从文件中读取JSON数据并解析为Python对象。这些功能使得Python能够方便地与JSON数据进行交互,进而实现数据存储、网络数据传输等多种功能。
直接使用XPath在动态网页数据抓取时会遇到问题。由于动态网页的内容往往不是直接加载在HTML源码中,而是通过JavaScript代码在客户端动态生成或修改的原因,当从服务器获取到HTML源码时,页面上实际显示的内容可能还没有被渲染或生成。利用网络请求分析技术对请求参数(如URL)、响应状态码(如200表示成功、404表示未找到等)、响应内容(如JSON数据)等因素进行分析,配合Requests库技术获取页面数据。
常用的数据处理方法有数据清洗,数据转换及数据合并等。数据清洗的以去除数据噪声、填补缺失值和纠正错误数据格式为目的。数据转换以将数据从一种格式或结构转换为另一种格式或结构为方式。数据合并以消除不同量纲数据之间的差异,使得数据在同一尺度上进行比较和分析为目的。这些方法提高了数据的质量和可靠性。
使用CVS进行文件存储。CVS文件存储作为数据文件格式的代表,它采用纯文本形式对表格数据进行存储。具有简洁、可读性好及灵活性强等特点。CVS文件存储经常用于数据交换、数据备份与恢复、数据分析等场景。CSV文件可通过编辑器手动创建,也可以通过编程语言写入。
2.2遵循反爬机制
开发中要遵循反爬机制的原则。开发者尊重目标网站的规定,如遵守网站roboats.txt文件规则,同时避免过度请求、模拟登录等行为,以合法合规的方式获取数据,确保爬虫行为的合法性和网站的稳定性。
3爬取招聘信息系统架构和实施
3.1数据采集
3.1.1路径确定
学院就业信息网在线招聘页面是动态网页,通过查看源码,该网页的URL由两部分组成,其中如下URL为固定不变部分:
其后由多个可变参数组成。分别时参数start、起始页码startPage和每页显示条数count。如下为完整的URL构造:
start_page=1:这个参数通常用于指定请求的起始页码,这里表示请求的是第一页的数据。
count=15:这个参数指定了每页应该返回的数据条数。这里表示每页显示15条数据。
start=startPage+1:这个参数通常它用于指定从哪个条目开始获取数据。这里表示起始页码startPage的下一个位置。
_=时间戳:这个参数通常用于防止浏览器缓存结果。通过在请求中添加一个时间戳(通常是当前时间的某种表示),可以确保每次请求都是最新的,因为URL会随着时间戳的变化而变化。
构建一个完整请求URL后,需要获取请求头数据headers,构造请求参数params,组成请求方法参数组(url,headers,params)。随后,调用requests.get()方法,将基础URL、请求头和请求参数作为参数传入,发起GET请求获取页面数据,并返回结果。
3.1.2网页分析
根据3.1.1小节,得到学院就业信息网在线招聘页面的第一页数据,页面内包含15条招聘信息。通过json解析数据的loads函数,将页面返回结果response解析为json数据。通过关键字“data”获取数据列表信息,companyList=dataJson['data']。
3.1.3数据获取
利用源码查看功能找到目标关键字key值,从data数据列表中获取对应关键字的信息并封装成一组招聘信息字典companyMessage,所有封装好的com⁃panyMessage字典组合成一个列表MessageList。
3.1.4循环爬取
每页招聘信息包含15条数据,通过计算每页信息的数量,利用for循环进行递归获取。预设想要获取total条数据,通过page=(total//count+1)(地板除,除完之后取整数部分)运算计算当前页码,其中通过startPage满足range(page)范围循环调用爬取函数。
3.1.5数据存储
本文通过定义存储函数和写入函数,可以将循环爬取的数据以结构化方式保存到CSV文件中。存储函数saveData接收数据列表;列名csvHeader=['公司名称','所需专业','岗位名称','发布时间','公司简介','招聘类型']作为表头;提取关键信息;函数Dict⁃Writer则利用Python的csv模块将数据循环遍历并写入指定的CSV文件中。其中,循环部分逻辑为:如果文件不存在,则写入表头writeHeader;如果文件已经存在,则直接追加数据。这种方法极大地促进了数据的持久化存储,使得数据能够长期保存并随时可用。处理编码问题时,根据实际需求确定数据库和表的默认编码为UTF-8,在存储过程中使用了MySQL自带的函数进行编码转换,保证数据输入和输出格式一致。为了防止数据丢失,采取了将数据备份到不同设备的方式,对敏感数据进行加密存储。同时限制了对存储服务器的未经授权的访问,避免数据泄露和丢失。
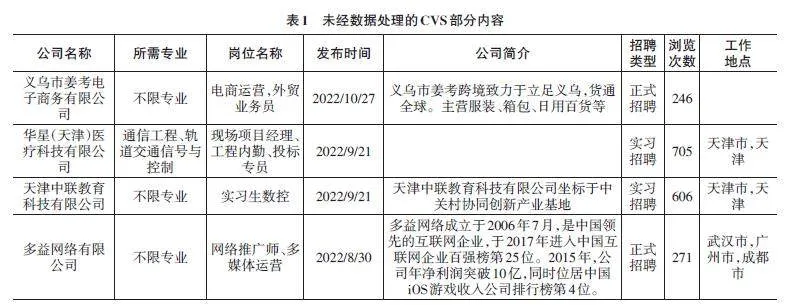
存储成功后,保存的招聘信息中,“公司简介”和“工作地点”部分内容有缺失或者格式不一致(天津市,天津或者天津市)的情况。未经数据处理的CVS部分内容如表1所示。
3.2数据处理
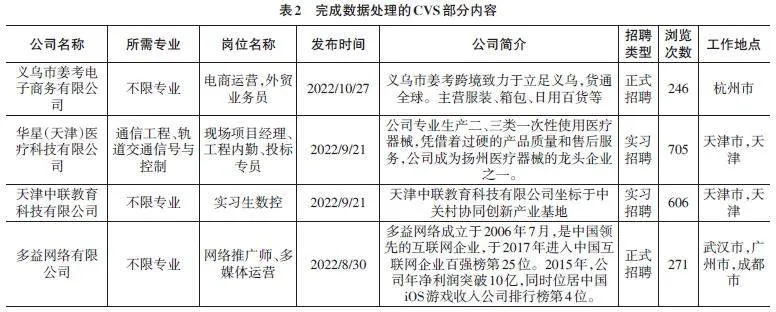
经过爬取后保存的招聘信息中,“公司简介”和“工作地点”两列部分内容空缺值需要合理填补,“工作地点”列格式进行统一处理。这个过程是数据预处理和数据清洗的重要环节。针对空缺值问题,使用手动查询和输入的方式进行了补充。针对格式问题,利用Excel文本分列功能、查找和替换功能及Excel的宏等多种方式进行修改统一。处理后的CVS文件内容如表2所示。
3.3可视化分析
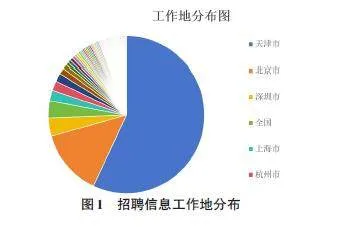
从工作地分布规律来看,针对天津本地的招聘信息比较集中,占整个招聘信息的50%左右,排名第一。其次是北京市、深圳市等。随着天津产业升级和新兴产业的发展,对高技能人才的需求不断增加,为专科生等层次人才提供了更为广阔的就业空间。天津高校致力于服务京津冀协同发展,在招聘信息收集工作中,积极与优秀企业合作,营造良好就业环境,为毕业生提供更多就业机会和发展空间,助力天津高质量发展。因此,就业工作地的分布呈现以天津为核心,紧密依托京津冀协同发展战略,同时展现出向南方发达城市多元拓展的特点。具体见图1招聘信息工作地状态分布图。
此外,从学生对招聘岗位的浏览次数可以看出,不同岗位对学生的吸引强度。其中,能提供广泛就业领域、不设专业限制的岗位,成为学生们心中的热门之选。另外,信息类、计算机类和机械机电类是学院的特色专业,也具有丰富的就业机会,稳居就业岗位吸引力排行榜的前三名。
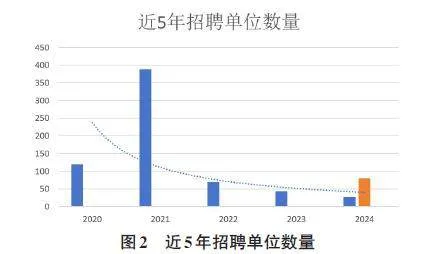
从2020年至2024年(截至5月份)以来,招聘单位的数量整体趋势不容乐观,从2020年到2023年呈现逐年降低的趋势(其中因2024年为1~5月数据,按照同比例算法模拟2024整年的数据为橙色部分。实际上,要准确判断2023之后招聘单位数量的变化趋势,需要具体的、实时的数据支持),其中在2021年达到最大值。就业网招聘信息数量呈现下降趋势的原因可能是多方面的,比如宏观经济、就业形势和学院自身因素等。在全球经济不确定性增加的背景下,可能影响到企业的招聘缩减。学院通过优化招聘流程、提高招聘效率等方式,也会影响招聘信息的发布次数。例如,线上智能化招聘、内部点对点推荐等方式,可以更快速、更精准地找到合适的就业候选人。此外,学院工匠工坊建设作用关键,不仅能够给学生提供扎实的专业知识和技能,也增加了丰富的实习实训机会和就业渠道,提升高质量就业。具体见图2近5年招聘单位数量图。
4结束语
本研究利用Python爬虫技术对天津电子信息职业技术学院就业信息网招聘数据进行了采集与分析,结果表明:从工作地分布规律来看,天津本地占整个招聘信息的50%左右,其次是北京市,深圳市等,招聘岗位一线城市较多,可重点推荐给学生。从学生对招聘岗位的浏览次数可以看出,学生笔记关注就业领域、专业不限的岗位,尤其信息类、计算机类和机械机电类特色专业就业机会多,可加大专业人才培养等。本研究为高校就业指导提供了数据支持,未来研究将进一步改进爬虫程序的效率和稳定性,丰富数据类型,扩展数据来源,进行更深入的数据挖掘分析。
参考文献:
[1]郭瑾.基于Python的招聘数据爬取与数据可视化分析研究[J].轻工科技,2024,40(2):94-96,99.
[2]张鹏.基于Jsoup爬虫的BOSS直聘信息爬取[J].无线互联科技,2023,20(2):106-108.
[3]郑灿伟,贺丹,罗嘉惠,等.基于Scrapy框架的互联网招聘信息可视化技术研究[J].科技与创新,2024(6):6-10.
[4]高凤毅,葛苏慧,林喜文,等.基于Python的招聘网站数据爬取与分析[J].电脑编程技巧与维护,2023(9):70-72.
[5]苏明焱.基于Python的招聘网站信息的爬取与数据分析[J].信息与电脑(理论版),2022,34(24):193-195.
【通联编辑:李雅琪】
猜你喜欢
办公室业务(2016年12期)2017-01-09 16:47:12
现代养生·下半月(2016年5期)2017-01-09 11:44:01
职教论坛(2016年26期)2017-01-06 19:04:59
科技传播(2016年19期)2016-12-27 16:18:28
法制与社会(2016年35期)2016-12-26 16:54:27
现代情报(2016年11期)2016-12-21 23:40:14
现代情报(2016年10期)2016-12-15 12:27:57
戏剧之家(2016年19期)2016-10-31 18:38:40
戏剧之家(2016年19期)2016-10-31 18:04:18
中国科技博览(2016年19期)2016-10-19 12:24:58
