
基于网络爬虫技术的财务大数据采集系统设计
2024-12-08 00:00:00周玮
中国新技术新产品 2024年3期

摘 要:随着大数据技术的发展,金融领域对大数据分析的需求不断增加。采集大规模的财务数据是进行深度分析、建立预测模型和识别趋势的基础。因此,本文设计了基于网络爬虫技术的财务大数据采集系统,旨在从多个数据源中自动获取、清洗、分析和存储财务数据。该系统的设计包括网络爬虫采集模块、数据处理模块和数据存储模块,充分考虑了数据的多样性和复杂性,以满足金融市场的需求。通过对系统性能进行测试,验证了系统的稳定性和可扩展性,并展示了该系统在实际应用中的潜力。
关键词:网络爬虫技术;财务系统;大数据;信息采集
中图分类号:TP 399 " " " 文献标志码:A
在快速发展的信息时代,将大数据技术应用于金融领域已成为必然趋势。在各企业及金融机构中,财务数据的采集和分析对其决策至关重要[1]。然而,财务数据会随各种原因频繁变化,具有较强的多样性及分布性,因此采集财务数据是一项复杂且具有挑战性的工作[2]。为了应对这一挑战,本文旨在设计和开发一种高效的财务大数据采集系统,利用网络爬虫技术从多个数据源中自动提取财务数据。本文系统的设计包括网络爬虫采集模块、数据处理模块和数据存储模块。网络爬虫采集模块负责从不同的金融网站和数据提供商获取数据,并根据指定的规则和模板进行解析、提取。数据处理模块负责数据的清洗、转换和聚合,以确保数据的质量和一致性。数据存储模块将处理后的数据存储在可扩展的数据库中,以供后续查询和分析使用。本文对该系统进行了性能测试,以验证系统在不同负载下的各项性能。测试结果表明,本文系统能够有效处理大规模财务数据,并保持较高的稳定性,为金融领域的数据采集和分析提供了一种强大的工具,可更好地助力于企业的财务决策和战略规划。
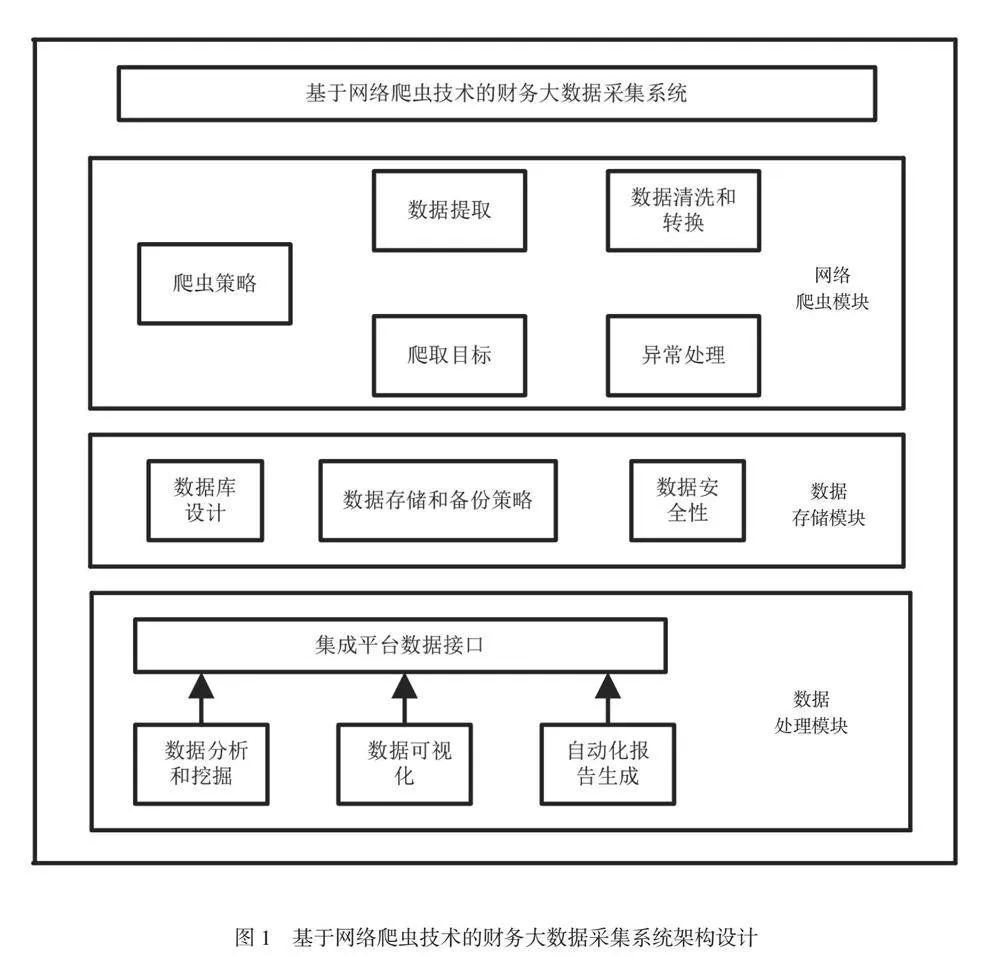
1 财务大数据采集系统架构设计
设计基于网络爬虫技术的财务大数据采集系统时,清晰的系统架构可以确保系统的可扩展性、性能和可维护性。系统架构如图1所示。
系统采用分层架构,将不同的功能和责任分配到不同的层次,以提高其可维护性和可扩展性。网络爬虫模块是该系统的核心,专门负责从互联网上爬取财务数据。该模块需要在一个独立的子系统中运行。数据存储模块用于存储采集的财务数据。系统使用PostgreSQL关系型数据库储存数据[3]。在基于网络爬虫技术的财务大数据采集系统中,数据处理模块具有重要作用,负责清洗、转换、分析和存储从网络爬虫模块获取的原始数据,以使数据成为成功采集的有效数据,并以可视化形态传达给用户。
2 硬件设计
基于网络爬虫技术的财务大数据采集系统硬件设备需要根据系统规模和需求进行定制。选择HP ProLiant DL380 Gen10服务器,该服务器多核Intel Xeon Scalable处理器的内存容量最多为3.5TB RAM(可根据需求配置),存储容量最多为30个SFF或20个LFF硬盘/SSD插槽(支持多种硬盘/SSD配置),包括多个高速网络接口,还包括千兆以太网和万兆以太网。
系统的存储设备可以选择HPE Enterprise SAS HDD企业级硬盘,容量为4TB,以存储大规模财务数据。读写性能为7200RPM,支持RAID技术,提供数据冗余、备份以及Samsung 860 PRO SSD固态硬盘,具有卓越的随机读写性能,用于加速数据存取。容量为256GB~2TB,耐用性高,适用于长时间运行。
网络设备选择Cisco Catalyst 9000 Series交换机,进行高速网络连接,支持千兆以太网或万兆以太网。管理功能丰富,包括虚拟局域网(VLAN)支持等,支持负载均衡和冗余链路聚合(LAG)。系统选择Cisco ISR 4000 Series路由器,安全性设置包括防火墙和虚拟专用网络(VPN)支持。系统的爬虫节点选择Microsoft Azure云虚拟机执行网络爬虫任务,定期抓取目标网站上的财务数据,对所采集数据进行处理,然后将其传输到服务器并进行存储和分析。
3 系统各模块设计
3.1 网络爬虫采集模块
在基于网络爬虫技术的财务大数据采集系统中,网络爬虫模块是整个系统的关键组成部分。该模块的主要任务是从目标网站上抓取财务数据。网络爬虫模块的具体运行流程如图2所示。
爬虫模块初始化需要设置抓取策略、数据存储方式等参数,定义爬虫应该访问的网页(如特定网站的首页或入口页面)及如何访问。根据一定规则生成待抓取的URL列表,再进行URL去重,确保不会重复抓取同一页面[4]。使用SHA-256哈希函数来计算每个待抓取的URL的哈希值,将URL的内容映射为一个固定长度的哈希码,具体流程如下。1)初始化一些常数(常量K),这些常数是SHA-256算法的一部分。2)将输入数据分成512位(64字节)的块。3)将512位块扩展成64个32位字,再将中间哈希值初始化为上一块的哈希值。进行64轮循环,每轮都对中间哈希值进行更新。4)将最后一轮的中间哈希值与上一块的中间哈希值相加,得出最终的SHA-256哈希值。5)继续处理下一个块,直到所有块处理完毕。6)处理完所有块后,将最终结果组合成256位(32字节)的哈希值,最终的SHA-256哈希值即为输出结果。
在上述方法中,如果新URL的哈希值已存在于集合中,说明该URL与已抓取的某个页面相同,因此不进行抓取,从而实现了URL去重。从去重后的URL队列中获取下一个要抓取的页面链接后,系统需要下载该页面的内容,解析下载的页面,提取财务数据,并根据XPath抽取规则进行数据处理。将解析后的数据存储到数据库或文件中,确保数据的持久性。检查已抓取的网页链接,确保不会重复抓取相同的页面[5]。根据请求间隔公式计算下一次请求的等待时间,以避免过于频繁的请求,具体如公式(1)所示。
t=f(RT,AP) (1)
式中:t表示下一次请求的等待时间,ms;RT表示目标网站的响应时间,ms;响应时间是上一次请求到目标网站并收到响应的时间;AP表示目标网站的访问策略,包括最小请求间隔、最大请求频率和请求失败的重试策略等;f表示计算等待时间的函数。
函数f接受输入参数RT(目标网站的响应时间)和AP(目标网站的访问策略),并返回等待时间作为输出。请求结束后,重复执行步骤3~6,直到所有目标页面都被抓取完毕或达到预设的抓取数量及时间限制,爬虫模块完成所有任务,才可结束运行。
3.2 数据存储模块
数据存储模块在基于网络爬虫技术的财务大数据采集系统中具有重要作用,负责将从网络爬虫模块获取的财务数据存储到持久化存储介质中,以供后续分析、查询和使用。设计数据存储模块时,选择适当的数据库系统,如PostgreSQL关系型数据库,以满足财务数据的存储和查询需求。定义数据表结构,具体如下。1)字段:包括公司名称、日期、总收入、总支出、利润。2)数据类型:使用整数(INT)或浮点数(DECIMAL)存储数值数据,使用日期/时间(DATE/TIME)存储日期和时间数据,使用文本(VARCHAR)存储公司名称。3)索引:公司名称和日期。4)主键:公司税号。
数据表的结构设置要适应财务数据的特性和查询需求,如果财务数据非常庞大,则需要考虑采用数据分区策略,以提高查询性能。采用数据质量控制策略,确保数据的准确性,如公式(2)所示。
(2)
式中:a为准确性;Iz为正确数据条目数;Is为总数据条目数。
数据储存模块会建立定期的数据备份和恢复策略,应对数据丢失或灾难性故障,以此来确保系统高效、安全地存储和管理网络爬虫获取的财务数据。
3.3 数据处理模块
数据处理模块在基于网络爬虫技术的财务大数据采集系统中具有重要作用,包括数据分析和挖掘、数据可视化以及自动化报告生成。在数据处理模块中,数据分析和挖掘是深入研究采集的财务数据,提取有用的信息,并为进一步决策提供支持。系统构建线性回归模型,用于建立连续数值型目标变量与一个或多个自变量之间的线性关系模型,其基本方程如公式(3)所示。
Y=β0+β1·X1+β2·X2+...+βn·Xn+ε (3)
式中:Y是要预测的目标变量;X1,X2,...,Xn是特征自变量;β0是截距项;β1,β2,...,βn是自变量的回归系数;ε是随机误差。
线性回归的目标是通过调整系数β1,β2,...,βn来找到最佳拟合的线性模型,以最小化误差项ε,可以使用最小二乘法来估计这些系数。该方法通过最小化观测值与模型预测值之间的平方差找到最佳拟合,优化线性回归模型目标函数Z的方程如公式(4)所示。
Z=∑(Yi-(β0+β1·X1i+β2·X2i+...+βn·Xni))2 (4)
式中:Yi是第i个观测值的目标变量值;β0+β1·X1i+β2·X2i+...+βn·
Xni是对第i个观测值的模型预测值。
通过找到最小化目标函数的系数,获得最佳拟合的线性模型,用于预测新数据点的目标变量值。数据可视化功能是根据模型预测得出分析结果,使用Matplotlib工具,将结果以图形和图表的形式呈现出来,帮助用户更好地理解和洞察数据。系统创建交互性可视化,使用户能够通过悬停、缩放、过滤等方式与数据进行互动,以更深入地了解财务数据信息。系统自动将数据分析结果和可视化图像嵌入报告中,确保报告中的信息与分析结果同步。使用脚本及工具自动排版和生成报告,然后将报告以PDF、HTML格式导出并发送给用户,以传达采集的财务数据。
4 测试试验
4.1 试验准备
为评估基于网络爬虫技术的财务大数据采集系统在不同负载下的性能表现,测试其稳定性和各项性能。试验硬件环境选择Dell PowerEdge R740服务器,2×Intel Xeon Gold 6240 2.6GHz处理器,系统内存256GB DDR4,存储1TB SSD,网络带宽为1Gbit/s。操作系统为Ubuntu Server 20.04 LTS,爬虫框架采用Scrapy 2.5.0,MySQL 8.0数据库,Python 3.8数据分析工具,Apache JMeter 5.4.1负载测试工具。
部署系统到服务器,并安装所需软件和依赖项,配置数据库、爬虫框架和数据分析工具等。创建一个测试用的财务数据集,包括模拟的公司财务报告和股票市场数据。使用Apache JMeter创建性能测试计划,需要定义的测试场景如下。1)基本负载测试,模拟系统在正常负载下的性能。2)峰值负载测试,模拟系统在高负载情况下的性能。3)数据量测试,测试系统处理大规模数据集的性能。4)稳定性测试,持续运行系统,以测试其稳定性。
4.2 试验结果
在每个测试场景下,模拟多个并发用户进行数据采集和处理,运行测试试验并记录测试结果。具体的测试结果数据表见表1。
从表1的测试结果数据来看,基于网络爬虫技术的财务大数据采集系统在各种测试场景下的吞吐量都相对较高,最高为105Mbit/s,表明系统能够有效处理大量的请求数据,获取大量财务数据。在各测试场景下,系统均能表现出较低的平均响应时间,为21.2ms~25.0ms,用户可以快速获取所需数据,用户体验感较好。另外,系统在不同测试场景下均能支持数量较高的最大并发用户数,表明系统具有良好的并发处理能力,能够满足多用户同时访问的需求。在各种测试场景下,系统的错误率均相对较低,≦1.5%,稳定性和可靠性较高,能够有效处理各种异常情况。
综合上述优点,基于网络爬虫技术的财务大数据采集系统在稳定性和可靠性方面表现良好,适用于大规模的财务数据采集和处理任务,系统能够在不同负载和条件下保持高效运行,为用户提供可靠的数据采集服务。
5 结语
综上所述,本文介绍了基于网络爬虫技术的财务大数据采集系统的具体设计。该系统的成功设计不仅为金融领域的数据采集和分析提供了一项强大的工具,还展示了大数据技术和自动化技术在金融决策支持中的巨大潜力。试验证明了该系统的稳定性,可为金融机构、研究机构和各企业提供较可靠的数据采集方式。未来,研究人员可以继续改进系统,增加更多的数据源和分析功能,以适应不断变化且复杂的金融市场。基于大数据和网络爬虫技术的财务数据采集系统将在金融领域发挥越来越重要的作用,为决策者提供更深入的洞察方式及更好的决策支持。
参考文献
[1]夏瑶.基于BP-SVM算法的中大型企业财务危机预警系统[J].西安文理学院学报(自然科学版),2023,26(1):17-20.
[2]李敏.大数据视角下企业财务管理系统信息化建设探究[J].西部财会,2022(10):36-38.
[3]程承.大数据对企业财务系统管理的影响与对策探讨[J].中国管理信息化,2022,25(19):105-108.
[4]方悦,赵红,陈继林.基于集成学习的财务信息一体化系统设计[J].九江学院学报(自然科学版),2022,37(1):54-58.
[5]阎泽群.基于网络爬虫技术的大数据采集系统设计[J].现代信息科技,2021,5(12):83-86.
猜你喜欢
科学家(2016年3期)2016-12-30 00:03:25
电子技术与软件工程(2016年19期)2016-12-19 17:25:38
中国经贸(2016年19期)2016-12-12 21:05:17
电子技术与软件工程(2016年18期)2016-11-14 01:10:50
中国科技博览(2016年22期)2016-11-01 18:39:42
中国科技博览(2016年18期)2016-10-19 10:02:50
新闻世界(2016年10期)2016-10-11 20:13:53
科技视界(2016年20期)2016-09-29 10:53:22
中国记者(2016年6期)2016-08-26 12:36:20
