
面向轨道交通装备全寿命配件服务技术研究
2024-12-08 00:00:00王川安帅张杜玮
中国新技术新产品 2024年9期
关键词:全寿命周期


摘 要:面对轨道交通装备运行维护过程中配件服务协同难、响应效率低等问题,本文探索了配件消耗量与车辆检修信息、车辆运行状态等因素间的相关性,利用挖掘算法构建库存预测模型,并探讨统一库存管理与多仓库协同智能调度模式,以实现库存的统一管理、统一调度。最后利用信息化技术搭建了配件服务一体化支撑平台,进行配件库存的智能优化、智能调拨,经验证,该平台在提升配件服务效率、优化库存结构等方面均具有良好的应用效果。
关键词:轨道交通装备;配件服务;全寿命周期;库存预测
中图分类号:U 23 " " " " " 文献标志码:A
在交通强国、数字中国的战略指引下,国家立体交通网络持续发展,行业呈现数量多、运量大、分布地域广、服役环境复杂以及网络化等综合特征,轨道交通装备安全运行关系国计民生。作为保障轨道交通装备安全运行的关键要素,配件的重要性不言而喻。传统的配件服务往往受地域限制,无法进行灵活调拨和协同,服务效率较低。为解决该难点,方伯芃以多价值链协同创新理论为基础,分别从价值、成本等影响配件服务效率的因素等视角建立了多价值链协同优化模型,并提出面向配件多链协同选择优化的博弈策略,为配件服务决策优化提出了相应理论[1]。陶茂华以服务价值链运营模式为研究主题,建立了涵盖运营流程、组织协同和构建过程并基于客户个性化需求的服务链创新模式[2]。WANG W等以维修服务中配件供应为主题,提出了协同运作策略优化模型[3]。
本文聚焦轨道交通装备运维过程中配件高效、快速面临的问题,建立有效的库存优化模型和库存共享模式,并运用大数据、物联网和云计算等融合技术搭建配件服务平台,为配件服务模式的持续创新提供助力。
1 研究思路
本文针对轨道交通装备运维过程中配件服务的痛难点,以“共商共建、共享共赢”为总体思路,以“优化库存结构、降低库存总量、加快库存周转”为核心要素,聚焦影响配件需求的关键要素,构建面向车辆运维的优化策略模型,并融合多种新兴技术体系搭建配件服务一体化平台,全面打造“按预测储备、按实际领用、按消耗结算”的服务型配件保障体系。
本文深入研究了轨道交通装备运维过程中影响配件需求的关键要素和在轨道交通装备运维计划修向状态修转变过程中影响配件需求的核心因子,引入人工智能算法能力,建立库存预测模型,以有效指导配件库存。利用数字化手段,结合配件服务的区域协同模式,实现各区域库存信息的协同共享,并利用工单协同能力,实现配件管理过程的流程化、在线化支撑。
基于云化、微服务架构理念,建立集库存信息共享和实时监控、库存智能预测、配件协同调度、物流配送为一体的智能化配件服务支撑平台,实现配件服务的全流程端到端支撑,以提升配件响应的及时性、有效性。
2 库存智能预测模型研究
配件库存精准预测是提升配件服务的关键,影响配件库存的关键因素主要是配件消耗量,库存的计算主要基于配件消耗量进行计算,具体算法说明如下:最大库存=一年采购周期内消耗的最大数值;平均库存=平均日耗量×最高储备日;最低库存=定级修和预测数最高储备日内数量取最大值+保险数量(默认平均日消耗);消耗量=计划修消耗+状态修消耗。
通过以上算法可以看出,影响库存的变量就是配件的消耗量。配件消耗受列车检修计划等因素影响,本文通过智能算法对库存进行精准预测。
2.1 库存预测算法研究
配件消耗量的预测是库存管理中的重要一环,将直接影响企业的运营效率和成本控制。本文采集了检修历史需求数据,并采用差分自回归移动平均模型(ARIMA)进行预测,可以更准确地分析备件需求规律,从而把握备件需求,合理压缩备件订货数量。ARIMA模型要求数据必须是平稳的,即数据的统计特性(如均值、方差等)不随时间变化。因此需要对原始时间序列进行平稳性检验。如果数据不平稳,就需要通过差分等方法对数据进行平稳化处理,直到数据变得平稳。在数据平稳和确定模型阶数后,就可以利用历史数据来估计模型参数。这些参数描述了数据间的依赖关系和随机误差的特性。得到模型参数后,需要对模型进行检验,即检查模型的残差是否满足白噪声假设,以确保模型的准确性和有效性。如果模型通过了检验,就可以用于预测。如果平稳后的时间序列表现出明显的季节性特征(即数据在一年内呈现出周期性变化),还需要在ARIMA模型中加入季节性项,以更准确地描述数据的季节性变化。利用经过检验和优化的ARIMA模型,可以预测未来的配件消耗量。预测结果可以帮助企业制定合理的库存计划和订货策略。最后通过比较预测值与实际值间的差异来对预测结果进行分析,评估预测的准确性和可靠性,也可以利用一些统计指标(如均方误差、平均绝对误差等)来量化评估预测的性能,具体算法如下。
2.1.1 AR(Auto Regression)模型
自回归(Auto Regression,AR)模型是一种时间序列分析方法,使用变量自身的历史数据来预测其未来的值。P阶自回归模型(AR(p))表示模型中使用过去p期的观测值来预测当前值,如公式(1)所示。
Xt=α1Xt-1+α2Xt-2+...+αpXt-p+ut "(1)
式中:Xt为时间序列在某一特定时间点的观测值或实现值;ut为随机误差项,是一个不能被模型直接解释或预测的随机变量,代表除模型所考虑的变量(如历史数据)之外的所有其他影响因素的总和;αp为自回归系数,可衡量历史数据对当前值的影响程度。
如果随机扰动项(或称误差项、残差项)是一个白噪声过程,那么一个仅由这个白噪声过程驱动的P阶自回归模型(AR(p))被称为一个纯AR(p)过程,如公式(2)所示。
Xt=α1Xt-1+α2Xt-2+...+αpXt-p+εt (2)
自回归模型(AR模型)在应用时需要确定一个阶数p,该阶数决定了模型预测当前值所使用历史数据的期数。阶数p的选择对模型的预测性能至关重要,它将直接影响模型能够捕捉到的历史信息量。1)由于模型利用过去的历史数据来预测未来,因此,如果历史数据中有噪声或错误,这些噪声或错误就可能会影响预测的准确性。2)AR模型要求时间序列是平稳的,即其统计特性(如均值、方差和自相关函数)不随时间发生显著变化。如果数据是非平稳的,就需要对数据进行差分或其他变换,使其变为平稳序列。3)如果时间序列数据没有自相关性,即当前值与历史值间没有显著关系,那么使用自回归模型进行预测可能不会获得良好效果。在实际应用中,通常需要通过统计检验(如ACF和PACF图、Ljung-Box检验等)来验证时间序列是否存在自相关性。
该模型可满足基于历史数据预测未来的配件需求。例如,可以使用过去几个月的需求数据来预测接下来的需求趋势。阶数p的选择对预测精度至关重要。
2.1.2 MA(Moving Average)模型
在AR(自回归)模型中,假设模型的误差项或残差项(ut)是一个白噪声过程。但是,如果在实际的时间序列分析中发现AR模型的残差(ut)不是白噪声,即它存在某种形式的序列相关性,那么可认为残差中包括某种可建模的结构,如公式(3)所示。
ut=εt+β1εt-1+...+βqεt-q "(3)
式中:εt为随机误差项;q为移动平均的阶数,表示考虑的历史误差项的数量;β1为移动平均系数,表示随机误差对当前值的影响。
当Xt=Ut时,即时间序列当前值与历史值没有关系,只依赖于历史白噪声的线性组合,就得到移动平均(Moving Averag,MA)模型,如公式(4)所示。
Xt=εt+β1εt-1+...+βqεt-q " (4)
需要注意的是,AR模型中历史白噪声的影响会间接影响当前预测值(通过影响历史时序值)。该模型可以用来平滑历史数据中的随机波动,特别是当需求受偶发事件影响时。例如,在节假日期间,配件需求可能会突然增加,MA模型有助于调整这种短期波动的影响。
2.1.3 ARMA模型
将自回归模型(AR(p))与移动平均模型(MA(p))相结合,可得自回归移动平均模型(ARMA(p,q))。该模型结合了AR模型和MA模型的特点,能够捕捉时间序列数据中的自相关性和移动平均效应,如公式(5)所示。
Xt=α1Xt-1+α2Xt-2+...+αpXt-p+εt+β1εt-1+...+βqεt-q " (5)
式中:Xt为时间序列在t时刻的值;α1,α2,...,αp为自回归部分的系数,可衡量过去p个时期的时间序列值对当前值的影响;Xt-1,Xt-2,...,Xt-p为时间序列过去的值,可向前追溯p个时期;εt,εt-1,...,εt-p为误差项,代表实际值与过去时期预测值间的差异;β1,β2,...βq为移动平均部分的系数,可衡量过去q个误差项对当前值的影响。
公式(5)表明2点。1)ARMA模型在描述随机时间序列方面的能力涉及AR和MA部分,为随机时间序列提供了一个灵活的建模框架,可用于捕捉序列中的自相关性和移动平均效应。2)平稳性在时间序列预测中代表时间序列的统计属性(如均值、方差和自相关性)不随时间变化。这种性质表明可以利用历史数据来推断未来行为。在平稳性的假设下,可以使用历史数据来估计ARMA模型的参数。一旦模型被正确估计,就可以用来预测未来的观测值。预测通常基于模型的拟合值和预测误差的估计。
自回归部分捕捉序列的趋势或动量,而移动平均部分平滑了噪声和随机波动。在平台设计中,该模型可通过学习历史数据中的模式和噪声来预测时间序列的未来值,如配件需求,对计划库存、优化供应链操作并满足各种组件需求而不过度库存具有一定作用。
2.1.4 ARIMA模型
差分自回归移动平均模型(ARIMA)是一种常用的时间序列预测方法。ARIMA模型可识别数据的自相关性和移动平均性,并应用差分技术来稳定序列来捕捉和预测时间序列中的动态效应,特别适合处理受多种不可控因素影响的非平稳时间序列数据。在检修备件需求预测中,ARIMA模型通过差分处理、自回归和移动平均技术来捕捉数据的动态效应,并能够适应节假日等特殊情况下的需求波动。因此,ARIMA模型是检修备件需求预测中的一种有效工具。对于非平稳的时间序列数据,例如长期的需求趋势或季节性变化,ARIMA模型可以通过差分法将数据转换为平稳序列,再应用ARMA模型进行预测,从而可提高对配件需求变化的预测准确性,优化库存管理和配件供应计划。
2.2 备件聚类模型研究
当前检修备件分类存在以下3个问题。1)分类界面不清楚。当前备件分类系统缺乏明确的分类标准和界限,导致分类结果不清晰。2)分类结果模糊。分类标准不明确,同一类备件间的特点差异较大,造成分类结果模糊。3)不利于库存管理策略。模糊的分类结果不利于备件管理人员制定和实施针对性的库存管理策略。
针对上述问题,本文采用聚类分析分类法并结合信息熵来进行优化。聚类分析是一种无监督学习方法,可根据数据间的相似性,将数据自动划分为多个簇(Cluster)。在备件分类中,聚类分析可以根据备件的多个属性(如功能、用途、尺寸和材质等)将它们自动分组,使同一组内的备件具有较大相似性,而不同组间的备件具有较小相似性。
信息熵是衡量信息不确定性的一个指标,在聚类分析中可用来评估聚类结果的稳定性和合理性。采用信息熵优化,可以自动选择最佳聚类数目,避免人为设定K值带来的主观性和不确定性。此外,信息熵优化还可以提高聚类算法的鲁棒性和稳定性,使聚类结果更准确、可靠。
在备件分类中使用结合信息熵优化的改进型聚类分析法,可显著提高分类的准确性和稳定性。该方法通过迭代计算聚类结果的信息熵,自动选择最佳聚类数目和聚类中心点,从而得到更清晰、准确的备件分类结果,如公式(6)所示。
(6)
具体步骤如下所示。1)数据预处理。主要是标准化、异常点过滤。2)随机选取K个中心,记为μ1(0),μ2(0),...,μk(0)。3)定义损失函数,即。4)令t=0,1,2,...为迭代步数,重复直到J收敛。对于每个样本,将其分配到距离最近的中心;对于每个类中心K,重新计算该类的中心。通过该算法,可以将备件自动分为K类,为备件分类管理提供支撑。
3 零配件管理模式研究
围绕“强基达标、提质增效”工作主题,根据“共商共建、共享共赢”总体思路,与用户合作成立区域配件中心,配件中心以“优化库存结构、降低库存总量、加快库存周转”为宗旨,以“净化配件采购渠道、降低库存资金占用”为目标,采用配件一体化服务平台,发挥物资计划、运营、信息和综合管理职能,全面打造“按预测储备、按实际领用、按消耗结算”的服务型配件保障体系。
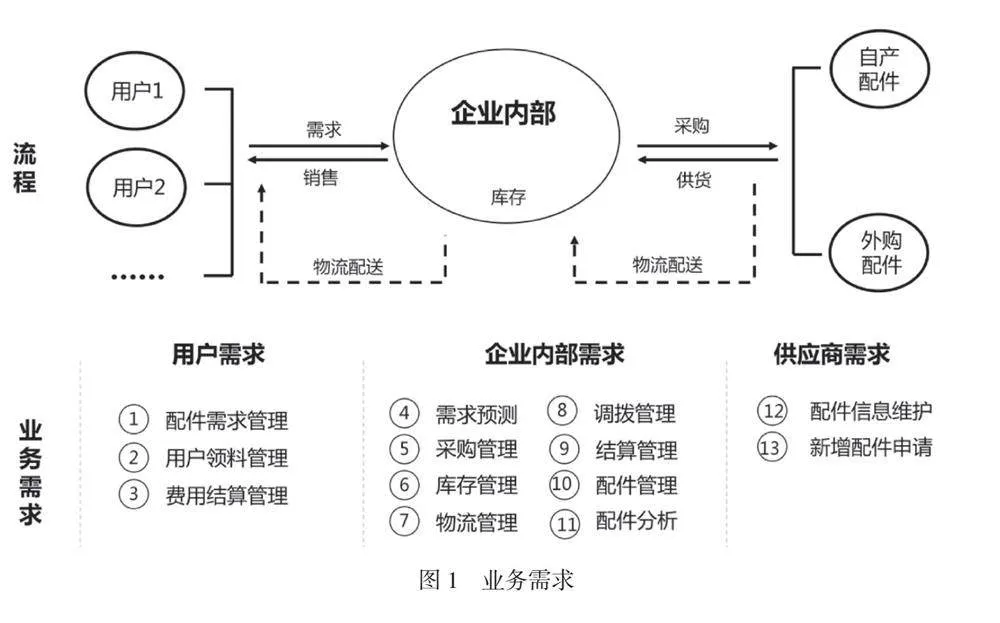
聚焦零配件供应链生态体系建设,充分融合企业内部、零配件供应商和用户等生态主体的业务诉求,构建集B2B(供应商到企业内部)与B2C(企业内部到用户)于一体的B2B2C服务平台,形成一个融合配件需求、采购、库存和物流等全过程的业务支撑体系,并创新零配件业务管理模式,实现配件服务全过程化和全流程化,具体业务需求如图1所示。
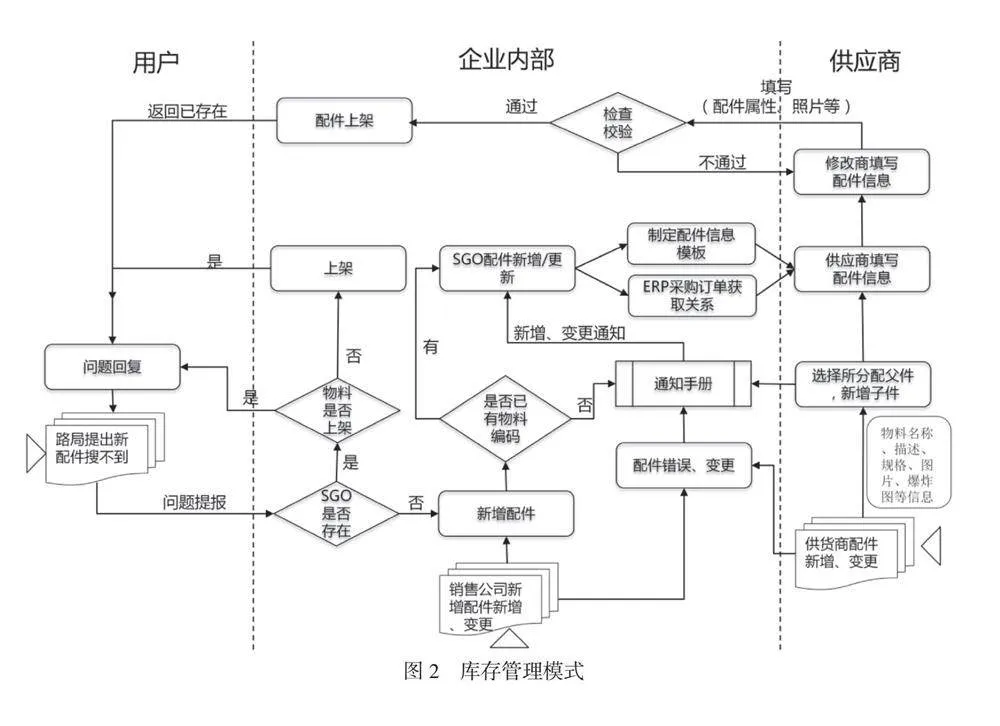
同时,在库存管理模式方面,构建基于全国库存统一调度的配件库存管理模式,实现配件全国库存的分级管理、统一库存调度和统一库存管理,提高库存的利用率,降低库存资金占用。库存分级管理提供区域中心库和服务站库,其中区域中心库满足配件基本需求和中转需求,服务站库满足服务站日常配件使用;统一调度,提供配件库存统一监控、配件库存统一控制和配件按需调度,确保配件以最快速度提供给客户,提高配件库存的使用效率;统一库存管理,提供配件存储规范、配件管理办法、用户操作事项和库存合理优化办法等,提高配件使用效率和合理优化库存。具体库存管理模式如图2所示。
4 搭建配件服务一体化平台
4.1 功能架构
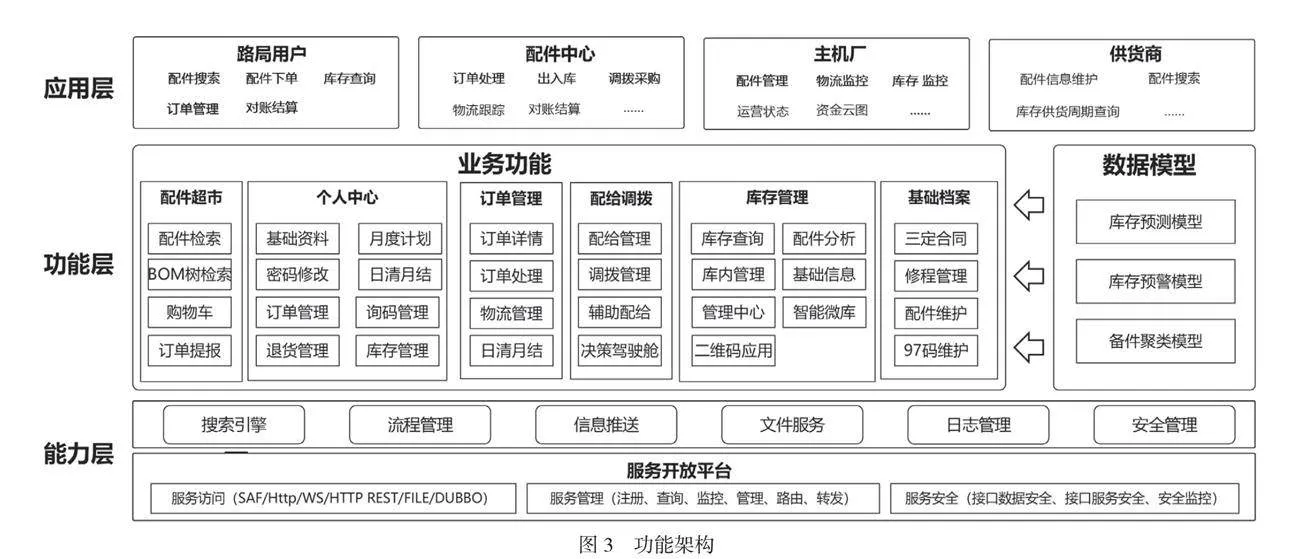
基于以上库存预测算法模型和库存管理模式研究成果,利用多种新兴互联网技术构建面向配件申请、库存管理和统一调度等全流程端到端支撑的配件服务一体化支撑平台,具体系统构架如图3所示。
通过搭建配件服务一体化平台实现配件库存管理、采购订单、智能调拨、配件销售等能力为一体的全流程端到端支撑,并实现零配件的供应商、业主、主机厂等生态体系的一站式支撑。具体说明如下所示。1)能力层。提供平台的基础能力,主要包括搜索引擎、流程管理、信息推送、文件服务、日志管理以及安全管理等基础功能,同时提供服务访问、管理和安全的服务开放能力。2)功能层。主要分为业务功能和数据模型,其中业务功能包括配件超市、订单管理、配给调拨和库存管理等能力。配件超市引入超市的购物车模式,提供订单采购全过程支撑。库存管理提供库存信息的动态监控、智能预警和预测,并融合库存联动,实现库存的动态调整。配给调拨是在库存信息动态共享的基础上实现库存的统一调配和智能调度。基础档案提供历史销售订单、合同等档案信息。数据模型则是基于第2节模型研究成果,通过集成车辆检修、库存等数据搭建库存预测、预警和备件聚类模型,为库存管理智能化提供基础。3)应用层。面向配件服务的供应商、消费方和主机厂等相关方,并结合各自的业务需求形成针对性的工作台,实现应用的个性化服务。
4.2 技术架构
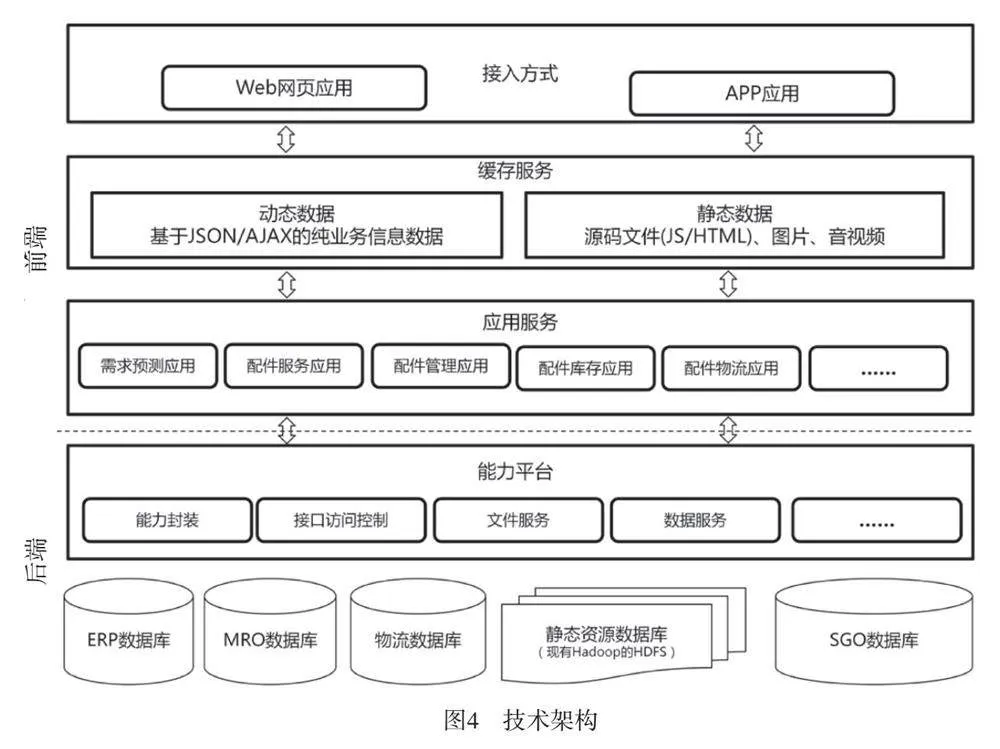
技术架构引入业界领先的云化和微服务、前/后端分离的架构模式,后端主要提供能力封装、接口访问控制和文件服务等能力,形成统一的能力平台。前端则重点提供应用服务封装和页面应用的缓存机制,并提供统一的接入方式以支撑Web和App这2种接入方式。在应用服务构建方面,结合具体应用功能封装成应用组件,形成模块化的微服务,有效提升平台的扩展性、灵活性。在网络架构方面,引入虚拟化机制,实现平台资源的动态扩展,保证架构可伸缩性和开放性,满足用户量高并发和用户高交易量。具体技术架构如图4所示。
5 应用效果
本文改进了传统的配件服务模式,实现了超市化的供应链管理和配件需求电商化管理,可直接下单采购,采购周期由原来的3~6个月缩减至15天内;配件储备项目增加23%,运用现场月均遗留故障配件需求比合作前降低了68%,显著提高了配件供应保障能力,取得了良好效益。但受车辆运维预测方法的准确性限制,其库存控制还有一定提升空间,后续将继续深入研究影响配件销售的其他因素和相关性,进一步提升库存预测的精准性和有效性。
参考文献
[1]方伯芃.基于云平台的配件多价值链协同技术研究[D].成都:西南交通大学,2012.
[2]陶茂华.基于个性化需求服务供应链运作模式研究[D].北京:北京交通大学,2012.
[3]WANG W.A model for maintenance service contract design,
negotiation and optimization[J].European journal of operational research,
2010,201(1):239–246.
猜你喜欢
居业(2016年6期)2017-02-05 01:44:05
居业(2016年5期)2017-01-11 17:25:21
建筑建材装饰(2016年11期)2016-12-29 19:00:09
企业技术开发·下旬刊(2016年11期)2016-12-27 16:43:35
科技创新与应用(2016年31期)2016-12-03 03:57:26
知音励志·社科版(2016年9期)2016-11-09 05:34:37
现代经济信息(2016年22期)2016-10-26 21:59:27
现代经济信息(2016年22期)2016-10-26 10:08:07
科学与财富(2016年28期)2016-10-14 01:12:22
现代经济信息(2016年4期)2016-06-20 14:14:32
