
基于可变形卷积与注意力的无人机航拍车辆目标检测算法
2024-11-30 00:00:00梁刚赵良军宁峰席裕斌何中良
现代电子技术 2024年23期




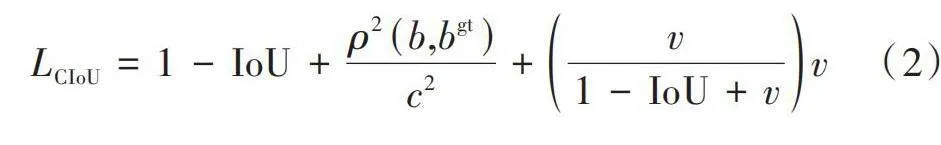












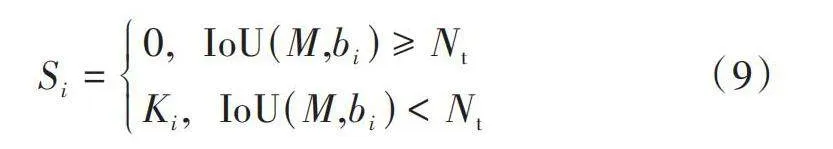



摘" 要: 在无人机航拍图像中,车辆目标较小,尺度变化大,背景复杂且分布密集,导致精度过低的问题。因此,提出一种基于改进的YOLOv5的无人机航拍图像车辆目标检测算法。增加小目标检测层,减少小目标特征丢失,从而提高小目标检测精度;设计了一个名为DAC的新特征提取模块,它融合了标准卷积、可变形卷积和通道空间注意力机制,旨在增强模型对车辆尺度变化的感知能力,并让模型聚焦于复杂背景下的车辆目标;将损失函数更改为Focal⁃EIoU,以加速模型收敛速度,同时提高小目标车辆的检测精度。使用Soft⁃NMS代替YOLOv5中采用的非极大值抑制,从而改善目标密集场景下的漏检和误检情况。在VisDrone2019数据集上进行了消融实验、对比实验和结果可视化。改进后的模型平均精度(mAP)比基线模型提高了8.4%,参数量和GFLOPs仅增加了4.8%和3.79%,验证了改进策略的有效性和优越性。
关键词: 无人机图像; 车辆检测; 小目标检测; 可变形卷积; 损失函数; 非极大值抑制
中图分类号: TN911.73⁃34; TP391" " " " " " " " " 文献标识码: A" " " " " " nbsp; " " "文章编号: 1004⁃373X(2024)23⁃0138⁃09
Deformable ConvNets and attention based object detection algorithm
for vehicles in UAV aerial photography
LIANG Gang1, ZHAO Liangjun1, NING Feng2, XI Yubin1, HE Zhongliang1
(1. School of Computer Science and Engineering, Sichuan University of Science amp; Engineering, Yibin 644000, China;
2. School of Automation and Information Engineering, Sichuan University of Science amp; Engineering, Yibin 644000, China)
Abstract: In UAV aerial images, the vehicles (the objects) are small, the scale changes greatly, and the background is complex and distributed densely, which results in low accuracy. Therefore, an improved YOLOv5 based object detection algorithm for vehicles in UAV aerial images is proposed. A small object detection layer is added to reduce the feature loss of small objects, so as to improve the accuracy of small object detection. A new feature extraction module called DAC, which combines standard convolution, deformable ConvNet (DCN) and channel space attention mechanism, is designed, which aims to enhance the model′s perception of changes in vehicle scale and allow the model to focus on vehicles (the objects) under complex backgrounds. The loss function is changed to Focal⁃EIoU to speed up the convergence of the model and improve the detection accuracy of small vehicles (the objects). The Soft⁃NMS is used to replace the non⁃maximum suppression used in YOLOv5, so as to improve missed detections and 1 detections in scenarios with dense objects. Ablation experiments, comparison experiments and result visualization are conducted on the VisDrone2019 data set. The mean average precision (mAP) of the improved model is 8.4% higher than that of the baseline model, and its number of parameters and GFLOPs are only increased by 4.8% and 3.79%. The effectiveness and superiority of the improved strategy are verified.
Keywords: UAV image; vehicle detection; small object detection; DCN; loss function; non⁃maximum suppression
0" 引" 言
近年来,无人机技术迅猛发展,其轻巧、快速、便捷的特点[1],常用于林业和农作物检测[2]、交通管理[3]、城市规划[4]、市政管理[5]、输电线路检查[6]、搜救等领域[7]。无人机在交通监测和管理方面的应用主要集中在通过航拍提供实时交通信息,有助于管理者更好地了解交通流量、车辆分布以及交通拥堵情况[8]。目前,获取车辆数据的常用手段包括感应线圈、压电式检测器和地面摄像头等传感器设备。然而,这些设备成本高,安装和维护困难,并且难以进行灵活调整。相比之下,搭载传感器的无人机航空平台更加灵活和高效。
基于卷积神经网络(CNN)的目标检测方法不断被提出,取得了优异的检测效果。根据输入图像的处理方式,有两种类型的对象检测方法:两阶段方法和一阶段方法。Fast R⁃CNN[9]、Faster R⁃CNN[10]和Mask R⁃CNN[11]等为两阶段方法,这类方法具有较高的精度,但提取大量候选区域导致处理效率低下且推理速度较慢;YOLO(You Only Look Once)[12]系列和SSD(Single Shot MultiBox Detector)[13]系列等为一阶段方法,这类方法大幅降低了检测时间,但精度方面可能受到一定的影响。
现有的检测方法难以准确定位和检测无人机航拍图像上的目标,还有很大的改进空间。文献[14]在YOLOv5l的基础上做了一些改进,提出了使用非对称卷积的三个特征提取模块。它们分别被命名为非对称ResNet(ASResNet)模块、非对称增强特征提取(AEFE)模块和非对称Res2Net(ASRes2Net)模块,对YOLOv5主干中不同位置的残差块进行了相应的替换。在Focus之后增加了IECA模块,并使用GSPP替代SPP模块。此外,采用K⁃Means++算法获得更准确的anchor box,并采用新的EIoU⁃NMS方法提高模型的后处理能力。文献[15]提出的UN⁃YOLOv5s算法可以很好地解决小目标检测的难题,采用更精准的小目标检测(MASD)机制,大幅提高中小目标的检测精度,结合多尺度特征融合(MCF)路径,融合图像的语义信息和位置信息,提高中小目标的检测精度,引入新的卷积SimAM残差(CSR)模块,使网络更加稳定和集中。文献[16]在YOLOv7算法上进行了一些改进,去除第二个下采样层和最深的检测头,以减少模型的感受野并保留细粒度的特征信息,引入DpSPPF模块,利用级联的小尺寸最大池化层和深度可分离卷积来更有效地提取不同尺度的特征信息,并对K⁃means算法进行优化,最后利用加权归一化高斯Wasserstein距离(NWD)和交并化(IoU)作为正样本分配和负样本分配的指标。
无人机拍摄交通道路图像中的车辆目标较小,尺度变化大,分布密集。容易出现错检、漏检情况,并且对于复杂背景下车辆目标的特征信息提取能力不足,导致检测精度较低。针对上述问题,考虑到无人机图像的特点,提出了一种改进YOLOv5的无人机航拍图像车辆目标检测算法。改进的工作如下。
1) 增加小目标检测层,引入P2检测层以获取更多小目标的特征信息,能显著提高小目标车辆的检测精度,并使用K⁃means聚类算法重新生成4组先验框。
2) 设计了DAC结构,即在C3模块中用可变形卷积(Deformable ConvNet v2)[17]替换一个原有的标准卷积,并加入CBAM(Convolutional Block Attention Module)[18],以加强模型对不同车辆尺度变化的感知能力和聚焦于复杂背景下的车辆目标。
3) 使用Focal⁃EIoU(Focal and Efficient IoU Loss)[19]作为模型的边界框损失函数,以加速模型收敛速度并提高检测精度。
4) 将基线模型的非极大值抑制改为Soft⁃NMS[20],以改善在密集场景中容易出现的错检和漏检问题。
1" 改进YOLOv5算法
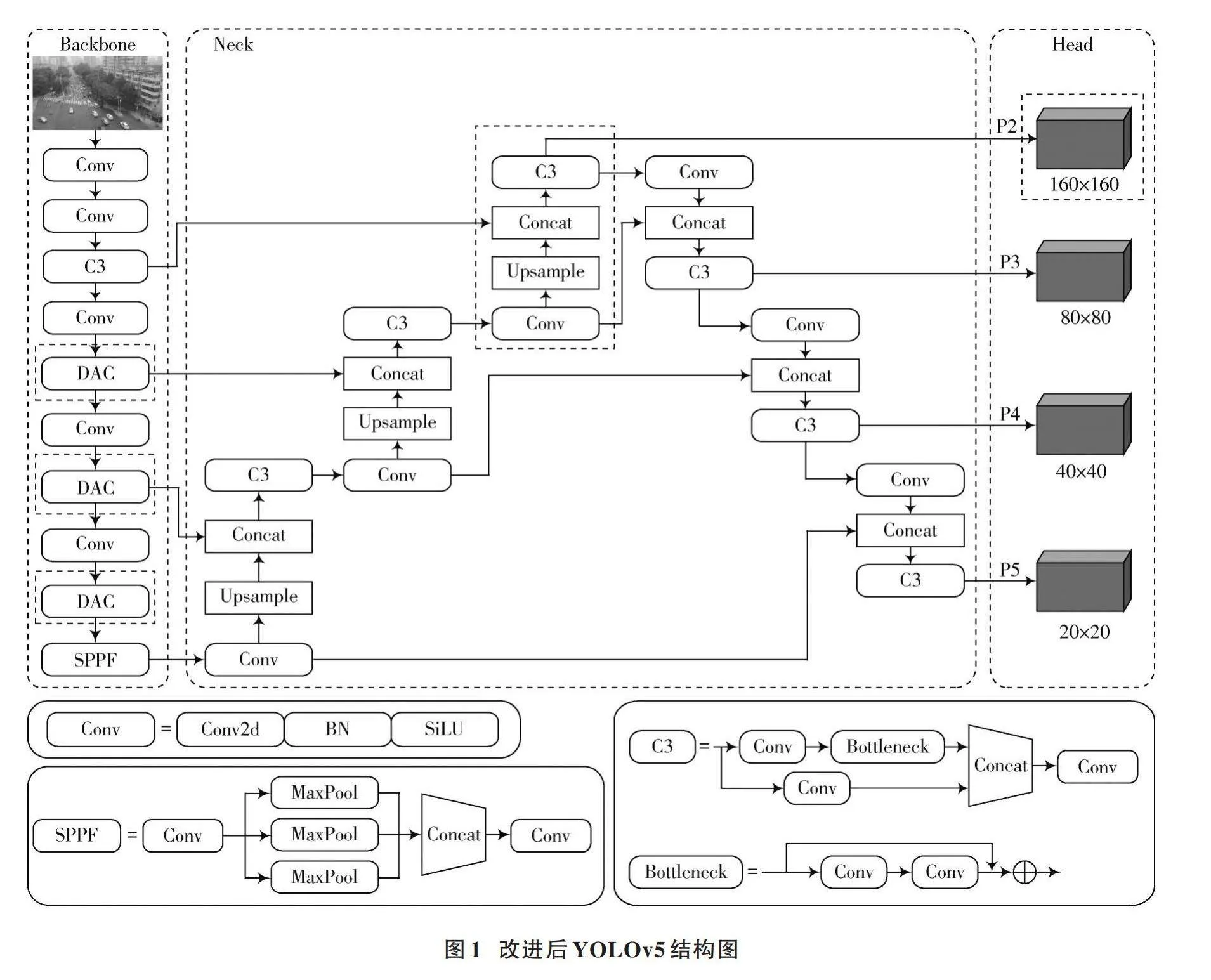
YOLOv5是目前比较主流的一阶段检测方法,它包含五个不同大小的模型,分别是:YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x。随着模型深度的增加,检测精度有所提升,但相应检测速度会下降。本文以YOLOv5s作为基线模型,增加小目标检测层、改进骨干网络和使用Focal⁃EIoU作为边界框损失函数,以及使用Soft⁃NMS代替NMS。改进后的网络结构如图1所示。
1.1" 增加P2检测层
无人机从空中拍摄的图像中车辆目标的像素较小,YOLOv5在Backbone部分进行多次下采样过程能获得更多语义信息,但也丢失了大量的详细特征信息,导致小目标的检测精度过低。为了增强对小目标车辆的特征提取能力,本文在保持其他特征图尺寸不变的情况下,在Neck部分添加了一个分辨率为160×160的P2小目标检测层,如图1虚线框所示。该层有两部分输入,一部分是Backbone中的C3模块进行卷积后得到160×160的特征图,另一部分是对原Neck中80×80的特征图进行卷积和上采样操作后的160×160扩展特征图。通过C3模块融合这两部分特征图,得到包含丰富位置信息的特征图。P2、P3、P4、P5检测层分别对应了4倍、8倍、16倍、32倍下采样的特征图,而4倍特征图的感受野较小,其特征图中包含了大量小目标的纹理特征和更多的细节信息,因此能最大程度保留小目标的特征。
尽管新增的P2检测层会增加网络的参数和计算量,但为了增强对小目标车辆的精确检测,这仍然是可以接受的。由于本文采用的数据集小目标众多,宽高比例较小,因此在训练之前利用K⁃means聚类算法生成了一组更匹配数据集的先验框,如表1所示。
1.2" DAC模块设计
1.2.1" DCNv2模块
在无人机图像车辆目标检测中,车辆的尺度会随着车辆的种类不同而变化,在特征提取阶段仅仅使用标准卷积会导致目标定位准确性下降,容易产生误检。
为了弥补无人机视角下车辆目标检测网络中标准卷积的不足,在特征提取阶段引入了DCNv2。相较于标准卷积,DCNv2通过引入可学习的形变参数,赋予了模型更强的感受野调整能力,使其能够根据目标的实际形状和尺度动态调整感受野,从而更灵活地捕捉各种车辆目标的形状特征,从而降低误检的风险。
可变形卷积(Deformable ConvNet, DCN)是一种改进的卷积操作,其核心思想是引入偏移量来动态调整卷积核的形状,以更灵活地捕捉输入特征的相关信息。DCNv2是DCN的进一步改进版本,通过学习偏移和加权,提高了模型对无人机图像中的车辆多尺度特征提取能力。DCNv2有两个关键步骤:首先,通过卷积操作生成卷积核在输入特征图上沿[x]和[y]方向的采样点偏移量;其次,利用输入特征图和计算得到的偏移量进行双线性插值,确定卷积核在输入特征图上的采样点位置。其结构如图2所示。
DCNv2对网络的参数量和计算复杂度没有很明显的影响,但在实际中大量使用可变形卷积会增加模型的训练时间。为了让模型在高效性能和有效性之间取得平衡,本文仅将骨干网络的C3瓶颈模块(Bottleneck)中的3×3标准卷积替换成DCNv2。
1.2.2" CBAM模块
无人机图像车辆检测任务中,无人机拍摄的角度较广导致大量复杂背景的干扰,车辆目标特征的表示变得不明显。为了解决这一问题,引入CBAM注意力机制,让网络更聚焦于所需检测的目标。该注意力由两部分组成,即通道注意力模块和空间注意力模块,其结构如图3所示。
复杂背景中的目标往往具有较低的信噪比和较弱的表现形式,使得它们难以被常规的特征提取方式捕捉到。CBAM通过对特征图进行通道注意力和空间注意力的加权处理,来提升网络对重要特征的关注和提取能力。
1.2.3" DAC模块
由于无人机图像中车辆尺度的变化,且容易混杂在复杂背景中,DCNv2和CBAM的融合有助于提高模型对车辆目标的检测准确性,减少漏检和误检的风险。因此,将DCNv2和CBAM模块一起融合到C3模型的Bottleneck中,形成新的瓶颈模块(DACBottleneck)和DAC模块,其结构如图4和图5所示。
1.3" Focal⁃EIoU
YOLOv5采用的损失函数分为边界框损失、置信度损失和分类损失函数。计算公式如式(1)所示:
[L=Lobj+Lcls+Lbbox] (1)
式中:[Lobj]是目标的置信度损失函数;[Lcls]是分类损失函数;[Lbbox]是边界框损失函数。
YOLOv5使用的边界框损失函数通过CIoU损失函数来计算,其公式如下所示:
[LCIoU=1-IoU+ρ2(b,bgt)c2+v1-IoU+vv] (2)
[v=4π2arctanwgthgt-arctanwh2] (3)
式中:[b]、[bgt]分别表示预测框和真实框的中心点;[ρ]代表计算两个框中心点的欧氏距离;[c]表示两个框的最小方框的对角线距离;[wgt]和[w]分别代表真实框和预测框的宽度;[hgt]和[h]分别代表真实框和预测框的高度。
从式(2)、式(3)中可知,CIoU综合考虑了预测框与真实框的重叠面积、中心距离、宽高比三种要素,但它是通过[v]来反映预测框和真实框的宽高比,而不是计算两者宽高的真实差异,所以有时会阻碍检测框的回归。因此,本文使用将预测框与真实框的欧氏距离平方作为惩罚项的Focal⁃EIoU边界损失函数来代替CIoU,该损失函数由Focal和EIoU组合而成。EIoU的公式如式(4)~式(7)所示:
[LEIoU=LIoU+Ldis+Lasp] (4)
[LIoU=1-IoU] (5)
[Ldis=ρ2(b,bgt)c2] (6)
[Lasp=ρ2(w,wgt)C2w+ρ2(h,hgt)C2h] (7)
式中:[c]、[w]、[h]、[wgt]、[hgt]、[ρ]和CIoU损失函数的含义一致;[Cw]表示覆盖预测框和真实框的最小外接框的宽;[Ch]为覆盖预测框和真实框的最小外接框的高。从上述式子可以看出,EIoU通过减小预测框和真实框宽高上的差异,让模型收敛速度更快且定位更准确,它将损失分为三部分:重叠程度损失[LIoU];中心的损失[Ldis];预测框与真实框边长损失[Lasp]。
在单张样本图像中,回归误差小的锚框数量明显少于误差大的锚框数量。由于质量较差的锚框会导致较大的梯度,这直接影响了模型的训练效果。为了应对这种不平衡情况,通过在EloU的基础上引入Focal Loss,旨在将高质量的锚框和低质量的锚框在训练中分开,以更有效地处理不同质量的目标框。计算公式如式(8)所示:
[LFocal⁃EIoU=IoUγLEIoU] (8)
式中[γ]为抑制异常的超参数。Focal⁃EIoU减小了简单样本的权重,让模型更关注预测框和真实框重叠低的样本,从而提高回归的精度。
1.4" Soft⁃NMS
YOLOv5使用的NMS算法是直接根据置信度的大小来删除得分低的预选框,保留置信度高的预选框,如式(9)所示:
[Si=0," "IoU(M,bi)≥NtKi," "IoU(M,bi)lt;Nt] (9)
式中:[Si]是算法算出的第[i]个检测框得分;[Ki]是各个目标的边界框置信度得分;[Nt]是设置的阈值;[M]代表置信度最大的检测框;[bi]代表第[i]个检测框。由式(9)可知,通过[bi]和[M]的交并比进行比较,如果大于阈值,则会直接删除[bi]。
对于无人机航拍的图像而言,会存在许多车辆目标密集的场景,因为无人机拍摄视角较高、较广,导致车辆目标间的间距缩小使得密集的情况更为严重。传统NMS通常只关注检测框的重叠度,以及抑制与目标检测框重叠较高的非目标检测框,然而,在某些情况下,这些非目标检测框可能是另一个目标的一部分,进而导致目标遗漏。此外,NMS会直接删除置信度较低的检测框,导致原本有效的单个目标被忽略,从而引发误检和漏检的问题,尤其是小目标。
本文用柔性非极大值抑制算法(Soft⁃NMS)替换原基线模型中的NMS,Soft⁃NMS算法与传统NMS的不同之处在于,它在计算重叠程度时不是简单的二值化阈值,而是使用一种类似高斯函数的方式,将重叠程度转化为一个在0~1之间的实数,然后根据这个实数对所有预测框进行排序。在抑制过程中,不再直接抑制与基准框重叠度高的框,而是根据重叠程度计算一个权重,对所有预测框进行加权求和,最终得到加权和最高的框。该方法能够缓解目标密集情况下检测框处理方式不够细腻导致的漏检或误检的问题。此外,在训练过程中采用NMS方法,仅在推理过程中使用Soft⁃NMS,这样就不会增加模型的计算量。Soft⁃NMS的高斯加权方式如式(10)所示:
[S*i=Sie-IoU(M,bi)σ," " " "∀bi∉D] (10)
式中:[S*i]表示加权后的得分;[Si]表示第[i]个检测框得分;[M]和[bi]与NMS式中的含义一致;[σ]表示标准差。
2" 实验与结果分析
2.1" 实验环境与数据集
如表2所示,给出了实验环境和实验中设置的一些统一的参数准则。若文中没有特殊的说明,则默认使用表中的参数设置。
本文使用由天津大学机器学习与数据挖掘实验室AiskYeye团队收集的VisDrone2019[21]数据集。VisDrone2019数据集包含288个视频片段、261 908帧和10 209幅静态图像,大约有540 000个标注信息。该数据集包含日常生活中的10个场景类别,分别为行人(pedestrian)、人(people)、自行车(bicycle)、汽车(car)、面包车(van)、卡车(truck)、三轮车(tricycle)、遮阳篷三轮车(awning⁃tricycle)、公共汽车(bus)和摩托车(motor)。
由于本文应用主要集中在交通监测和管理方面,所以只提取了car、van、truck、bus四个主要出现在道路上的车辆类别进行检测。为了提升检测效果,本文对数据集进行了扩充,应用加噪声、平移、裁剪等数据增广的方式,具体效果如图6所示,其中图6a)为原图,图6b)~图6f)为增强后的结果。最终形成的训练集包含8 635张图片,验证集有2 160张图片。
2.2" 评价指标
本文使用了多个评价指标,包括精准率(Precision)、召回率(Recall)、平均精度均值(mAP)、模型参数量(Params)、每秒检测帧数(FPS)和浮点运算次数(GFLOPs)。
精准率(Precision)指预测为正样本中实际正样本的比例,公式如下:
[P=TPTP+FP] (11)
式中:TP为正确预测出正样本的检测框数量;FP为负样本被预测成正类的数量。
召回率(Recall)代表正确预测的样本数占总样本数的比例,公式如下:
[R=TPTP+FN] (12)
式中FN为被预测成负类的正样本数。
平均精度均值(mAP)为所有类别检测精度的平均值,公式如下:
[AP=01PRdR] (13)
[mAP=1ni=1nAPi] (14)
式中:[n]为检测类别的数量;AP为[PR]曲线下的面积。
2.3" 实验结果
2.3.1" 消融实验
为了验证本文提出的方法对无人机图像中车辆目标检测的性能有效提高,以YOLOv5s作为基线模型进行消融实验,实验结果如表3所示。其中:mAP@0.5是IoU为0.5时所有类别的平均检测精度;mAP@0.5:0.95是IoU以0.05为步长,从0.5~0.95的全部平均检测精度;FPS指的是模型每秒处理的图片数量,用来衡量检测速度;GFLOPs为网络模型的浮点运算次数。
通过分析表3的结果可以发现,添加小目标检测层、DAC模块、将损失函数替换为Focal⁃EIoU以及将NMS改为Soft⁃NMS都对检测精度进行了提升。在方法1中,引入小目标检测层,mAP@0.5提高了4.1%。由于增加了C3_1、上采样、Conv、检测头等模块,导致模型的参数量和计算量略有增加,但这能够最大限度地保留小目标车辆的位置信息,从而显著提高了检测精度。方法2中,在骨干网络使用DAC模块替换了基线模型三层的C3模块,相对于基线模型,mAP@0.5提升了0.7%。这强化了在复杂背景下多尺度车辆细节信息的特征提取能力,从而提高了检测精度,同时也带来了一定的参数量增加。在方法3中替换了损失函数,Focal⁃EIoU以欧氏距离平方作为惩罚项,不增加参数量和计算量的情况下,检测精度提高了0.9%。相对于基线模型,检测速度也有一定的提升。方法4是将方法1和方法3相结合,mAP@0.5相比于基线模型提升了4.5%。方法5是在方法4的基础上使用了Focal⁃EIoU,检测精度再次提高了0.4%。在方法6中,将方法5的非极大值抑制替换为Soft⁃NMS,相较于基线模型,mAP@0.5提高了8.4%,比起方法5,检测精度提高了3.4%,虽然模型的参数量和计算量没有增加,但是由于Soft⁃NMS的推理较慢,导致检测速度降低。相比于精度的提升,检测速度的下降在可接受范围之内。
综上所述,实验结果表明,本文提出的每一个改进都提升了模型的检测性能,虽然一些改进带来了一定的参数量和计算量使得检测速度降低,但检测精度提升较大,也能满足实时性检测的需求。
2.3.2" 数据集中各类的实验结果
为了验证改进方法在车辆目标检测中的效果,对改进方法的每个类别进行了精准率、召回率和平均精度的评估,并将其与基线模型进行了对比,结果如表4所示。
根据实验结果显示,改进后的模型在道路上对各类车辆的精准率、召回率以及检测精度都取得了显著提升。具体而言,car、van、truck和bus的mAP分别达到了86.1%、68.1%、69.5%和77.6%,分别相较于基线模型提升了7.1%、8.4%、9.1%和9.1%。因此,改进后的模型对于无人机航拍各类车辆目标检测表现出很好的适用性。
2.3.3" 损失函数对比实验
在基线模型中所使用的损失函数是CIoU,为了验证Focal⁃EIoU损失函数对无人机图像中车辆精度具有更好的提升效果,使用不同损失函数进行对比实验,以mAP@0.5和mAP@0.5:0.95为评价指标。
损失函数对比实验结果如表5所示。
由实验结果可知,Focal⁃EIoU的mAP@0.5和mAP@0.5:0.95的值分别达到了67.8%和45.4%,相比其他损失函数,Focal⁃EIoU具有更好的性能表现和更快的收敛速度。
2.3.4" 对比实验
为了进一步验证本文算法的性能优势,选取了比较有代表性的目标检测算法Faster R⁃CNN、SSD、YOLO系列在VisDrone2019数据集上进行对比实验,实验结果如表6所示。
通过表6可以分析出,本文改进算法在平均精度、参数量、计算量相比其他算法都具有不错的优势。对比YOLO系列中最新的模型YOLOv8s,本文算法的mAP@0.5值提高了5.1%,参数减少了3.76×106,运算次数减少了11.9 GFLOPs。与针对无人机图像目标检测的THP⁃YOLOv5s算法相比,本文算法的mAP@0.5值提高了3.1%,参数量和运算次数分别降低了2.12×106和8.7 GFLOPs,并且相对于二阶段算法Faster R⁃CNN在精度和模型复杂度上都有显著的优势。
2.3.5" 可视化分析
在VisDrone2019数据集中,本文选择了在高空(小目标)、复杂背景和密集场景下具有代表性的图像进行检测,以更直观地评估本文算法。不同场景下的检测效果对比如图7所示。
图7a)展示了高空场景的检测对比图,可以观察到图像中的车辆变得十分微小,且不同车辆的尺度变化较大。图7b)展示了复杂场景下的检测对比图,由于无人机拍摄的图像受到昏暗和部分光照的影响,导致图像质量较差。图7c)展示了密集场景下的对比检测图,可以看到图像中目标之间相互重叠的情况十分严重。
从基线模型和改进后模型的检测对比图来看,在图7a)中,原始基线模型将路边的栏杆误检为car类,并且将van类别错误检测为car类。在第二列的复杂场景中,原始基线模型将本应为truck类的目标误检为bus类。在图7c)的密集场景中,基线模型产生了许多冗余的检测框,尤其是在密集排列的车辆部分,而改进后的模型为每个类别都分配了相应的框。改进后的算法与YOLOv5相比,在任何场景下都表现出更高的检测精度,同时减少了漏检和误检的现象发生。
3" 结" 语
本文研究并分析了无人机航拍图像检测方法的不足,根据无人机航拍图像的特点,在YOLOv5的基础上进行了改进,引入了一系列创新措施,包括增加小目标检测层、修改主干网络、调整损失函数以及改进非极大值抑制机制,旨在全面提升模型的检测性能。通过在VisDrone2019数据集上进行实验,本文着重提取了道路上经常出现的4个车辆类别,并对模型进行了深入评估。
实验结果显示改进后的模型不仅在检测精度方面取得显著提升,而且总参数量和计算复杂度保持在合理水平的同时展现了出色的性能。
通过与其他先进检测模型进行对比,验证了本文改进方法的有效性。未来,将持续专注于研究无人机航拍图像中不同车辆目标的独特特征,并不断提出更加精准的优化策略。在数据收集和标注方面,以后将计划扩大涉及的类别目标,扩展研究的应用领域,以更全面地满足多样化场景和目标类别的挑战,为未来无人机技术在各个实际应用领域中的推广提供坚实的理论和实践基础。
注:本文通讯作者为赵良军。
参考文献
[1] LUO X D, WU Y Q, ZHAO L Y. YOLOD: A target detection method for UAV aerial imagery [J]. Remote sensing, 2022, 14(14): 3240.
[2] PEI H T, SUN Y Q, HUANG H, et al. Weed detection in maize fields by UAV images based on crop row preprocessing and improved YOLOv4 [J]. Agriculture, 2022, 12(7): 975.
[3] BYUN S, SHIN I K, MOON J, et al. Road traffic monitoring from UAV images using deep learning networks [J]. Remote sensing, 2021, 13(20): 4027.
[4] LAHOTI S, LAHOTI A, SAITO O. Application of unmanned aerial vehicle (UAV) for urban green space mapping in urbani⁃zing Indian cities [J]. Unmanned aerial vehicle: Applications in agriculture and environment, 2020(1): 177⁃188.
[5] BAIOCCHI V, NAPOLEONI Q, TESEI M, et al. UAV for monitoring the settlement of a landfill [J]. European journal of remote sensing, 2019, 52(3): 41⁃52.
[6] 聂晶鑫.基于改进YOLOv5的铁路接触网绝缘子检测方法[J].现代电子技术,2024,47(2):31⁃36.
[7] DE OLIVEIRA D C, WEHRMEISTER M A. Using deep learning and low⁃cost RGB and thermal cameras to detect pedestrians in aerial images captured by multirotor UAV [J]. Sensors, 2018, 18(7): 2244.
[8] LIU X, ZHANG Z Y. A vision⁃based target detection, tracking, and positioning algorithm for unmanned aerial vehicle [EB/OL]. [2021⁃04⁃12]. https://onlinelibrary.wiley.com/doi/10.1155/2021/5565589.
[9] GIRSHICK R B. Fast R⁃CNN [C]// Proceedings of the IEEE International Conference on Computer Vision. New York: IEEE, 2015: 1440⁃1448.
[10] REN S Q, HE K M, GIRSHICK R B, et al. Faster R⁃CNN: Towards real⁃time object detection with region proposal networks [C]// Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015. [S.l.: s.n.], 2015: 91⁃99.
[11] HE K M, GKIOXARI G, DOLLÁR P, et al. Mask R⁃CNN [EB/OL]. [2018⁃01⁃24]. https://arxiv.org/abs/1703.06870?file=1703.06870.
[12] JIANG P Y, ERGU D J, LIU F Y, et al. A review of Yolo algorithm developments [C]// Proceedings of the 8th International Conference on Information Technology and Quantitative Management. Amsterdam, Netherlands: Elsevier, 2021: 1066⁃1073.
[13] LIU W, ANGUELOV D, ERHAN D, et al. SSD: Single shot multibox detector [C]// Proceedings of 14th European Conference on Computer Vision. Heidelbrug: Springer, 2016: 21⁃37.
[14] LUO X D, WU Y Q, WANG F Y. Target detection method of UAV aerial imagery based on improved YOLOv5 [J]. Remote sensing, 2022, 14(19): 5063.
[15] GUO J, LIU X, BI L, et al. UN⁃YOLOv5s: A UAV⁃based aerial photography detection algorithm [J]. Sensors, 2023, 23(13): 5907.
[16] ZENG Y L, ZHANG T, HE W K, et al. YOLOv7⁃UAV: An unmanned aerial vehicle image object detection algorithm based on improved YOLOv7 [J]. Electronics, 2023, 12(14): 3141.
[17] ZHU X Z, HU H, LIN S, et al. Deformable ConvNets v2: More deformable, better results [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 9300⁃9308.
[18] WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional block attention module [EB/OL]. [2018⁃07⁃17]. https://arxiv.org/abs/1807.06521.
[19] ZHANG Y F, REN W Q, ZHANG Z, et al. Focal and efficient IoU loss for accurate bounding box regression [J]. Neurocomputing, 2022, 506: 146⁃157.
[20] CHEN F X, ZHANG L X, KANG S Y, et al. Soft⁃NMS⁃enabled YOLOv5 with SIoU for small water surface floater detection in UAV⁃captured images [J]. Sustainability, 2023, 15(14): 10751.
[21] ZHU P F, WEN L Y, DU D W, et al. Detection and tracking meet drones challenge [J]. IEEE transactions on pattern analysis and machine intelligence, 2021, 44(11): 7380⁃7399.
[22] ZHENG Z H, WANG P, LIU W, et al. Distance⁃IoU loss: Faster and better learning for bounding box regression [EB/OL]. [2019⁃11⁃19]. https://arxiv.org/abs/1911.08287.
[23] GEVORGYAN Z. SIoU loss: More powerful learning for boun⁃ding box regression [EB/OL]. [2022⁃05⁃30]. https://doi.org/10.48550/arXiv.2205.12740.
[24] TONG Z J, CHEN Y H, XU Z W, et al. Wise⁃IoU: Bounding box regression loss with dynamic focusing mechanism [EB/OL]. [2023⁃01⁃26]. https://doi.org/10.48550/arXiv.2301.10051.
作者简介:梁" 刚(1999—),男,四川广元人,硕士研究生,研究方向为目标检测。
赵良军(1980—),男,湖北京山人,博士研究生,研究方向为图像处理、卫星遥感。
宁" 峰(2000—),男,四川德阳人,硕士研究生,研究方向为目标检测。
席裕斌(1999—),男,陕西汉中人,硕士研究生,研究方向为语义分割。
何中良(1995—),男,四川南充人,硕士研究生,研究方向为语义分割。
