
基于改进YOLOv8的道路病害视觉识别算法
2024-11-30 00:00:00张强杜海强赵伟康崔冬
现代电子技术 2024年23期

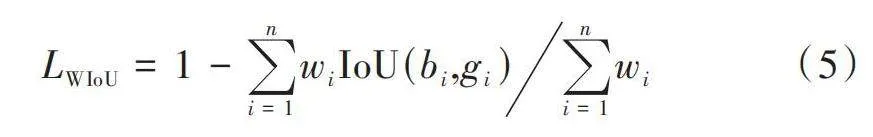










摘" 要: 道路病害检测对于确保道路的安全性和可持续性至关重要,对城市和社会的发展具有积极作用。为提高目前道路病害检测模型的性能,文中提出一种基于改进YOLOv8的道路病害检测算法。设计一种新型高效的特征融合模块(DWS),提高模型获取特征信息和全局上下文信息的能力;提出将ECABlock、LeakyReLU激活函数与卷积相结合的新模块ELConv来提高深层网络对目标的定位能力;另外,使用Dynamic Head检测头替换原始YOLOv8的头部,结合尺度、空间和任务三种注意力机制提升模型头部表征能力;最后,采用WIoU损失函数代替原损失函数来改善边界框精确度和匹配度。相比基线模型,改进模型在road damage detection数据集和RDD2022_Japan数据集上都得到了有效的验证,表明改进模型满足当下道路病害检测的需求,展示了高灵活性、准确性和效率。
关键词: 道路病害检测; 深度学习; YOLOv8; 特征融合; 激活函数; Dynamic Head; WIoU损失函数
中图分类号: TN911.73⁃34; TP391.4" " " " " " " " " " 文献标识码: A" " " " " " " "文章编号: 1004⁃373X(2024)23⁃0119⁃06
Road damage visual recognition algorithm based on improved YOLOv8
ZHANG Qiang, DU Haiqiang, ZHAO Weikang, CUI Dong
(School of Information and Electrical Engineering, Hebei University of Engineering, Handan 056038, China)
Abstract: Road damage detection is crucial to ensure the safety and sustainability of roads, and plays a positive role in the development of cities and society. A road damage detection algorithm based on improved YOLOv8 is proposed to improve the performance of the current road damage detection model. A new and efficient feature fusion module DWS is designed to enhance the model ability of obtaining feature information and global context information. A new module ELConv, which combines activation functions ECABlock and LeakyReLU with convolution, is proposed to improve the deep network′s ability to locate objects. In addition, the detection head Dynamic Head is used to replace the head of the original YOLOv8. The three attention mechanisms of scale, space and task are combined to improve the representation ability of the model head. The loss function WIoU is used to replace the original loss function to improve the accuracy and match of the bounding box. In comparison with the baseline model, the improved model is verified on both the road damage detection dataset and the RDD2022_Japan dataset effectively. It shows that the improved model can meet the current needs of road damage detection, demonstrating high flexibility, accuracy and efficiency.
Keywords: road damage detection; deep learning; YOLOv8; feature fusion; activation function; DyHead; loss function WIoU
0" 引" 言
随着城市化进程的不断加速,道路网络的建设和维护变得尤为重要。然而,传统的道路巡检方法通常依赖于人工巡查,这既费时费力又昂贵,且容易出现漏检或误检。因此,研究高效率、低成本的道路病害检测方法具有重要的现实意义。
早期的道路病害检测技术以传统LBP、Gabor等纹理特征提取为主,往往在实际中呈现的效果不是很理想。近两年来的研究中,文献[1]提出的改进道路表观病害检测模型(IPD⁃YOLOv5)通过引入ASPP模块和SE⁃Net[2]注意力机制虽然在道路病害检测方面表现出了很多优势,但是增加了模型的计算复杂性,导致需要更多的计算资源和时间来进行训练和推理。文献[3]针对细长路面病害的语义与形状特征,提出了双阶段的Epd RCNN路面病害检测方法。文献[4]将注意力机制模块融入到YOLOv5目标检测模型当中,该通道注意力机制模块为道路病害的特征赋予权重,以优化检测性能。
尽管现有的研究可以有效地对道路病害进行检测,但在当前的研究中,有三大问题未充分解决:
1) 模型对于复杂道路病害的特征融合不够充分,使得检测精度降低;
2) 模型对于道路病害的特征提取不够充分,仅简单考虑了特征提取与融合,导致在网络中特征信息丢失的问题;
3) 网络的泛化性和鲁棒性也未能有效验证。
基于此,本文提出了一种基于YOLOv8模型改进的道路病害检测算法。
本文首先简要介绍了YOLOv8算法的原理以及模型结构,此后,针对现有道路病害检测研究中存在的问题提出了改进YOLOv8的方案,并进行了实验。该过程中首先对比了不同模型对于道路病害的检测效果,验证了YOLOv8模型在道路病害检测中有一定的优势;其次对比了不同模块嵌入到模型中的检测效果;另外,通过消融实验探究了本文改进方案的有效性,并在公开数据集上验证了模型的泛化性;最后,对本文的研究内容进行了总结。
1" YOLOv8算法
YOLOv8为一个具有里程碑意义的SOTA模型,它包含P5 640与P6 1 280分辨率的目标检测模型,其特性和YOLOv5相似,都是依据缩放系数提供N/S/M/L/X尺度的多种型号,以适应各种应用场景。区别在于,其骨干网络与Neck部分采用了YOLOv5[5]所没有的C2f结构,该结构在梯度流动方面更为丰富。此外,针对不同尺度的模型调整了相应的通道数量。在Head部分,YOLOv8采用了解耦头结构,将分类与检测头分开,并从基于Anchor的思想转变为Anchor⁃Free的思想[6]。YOLOv8网络结构如图1所示。
2" YOLOv8算法改进
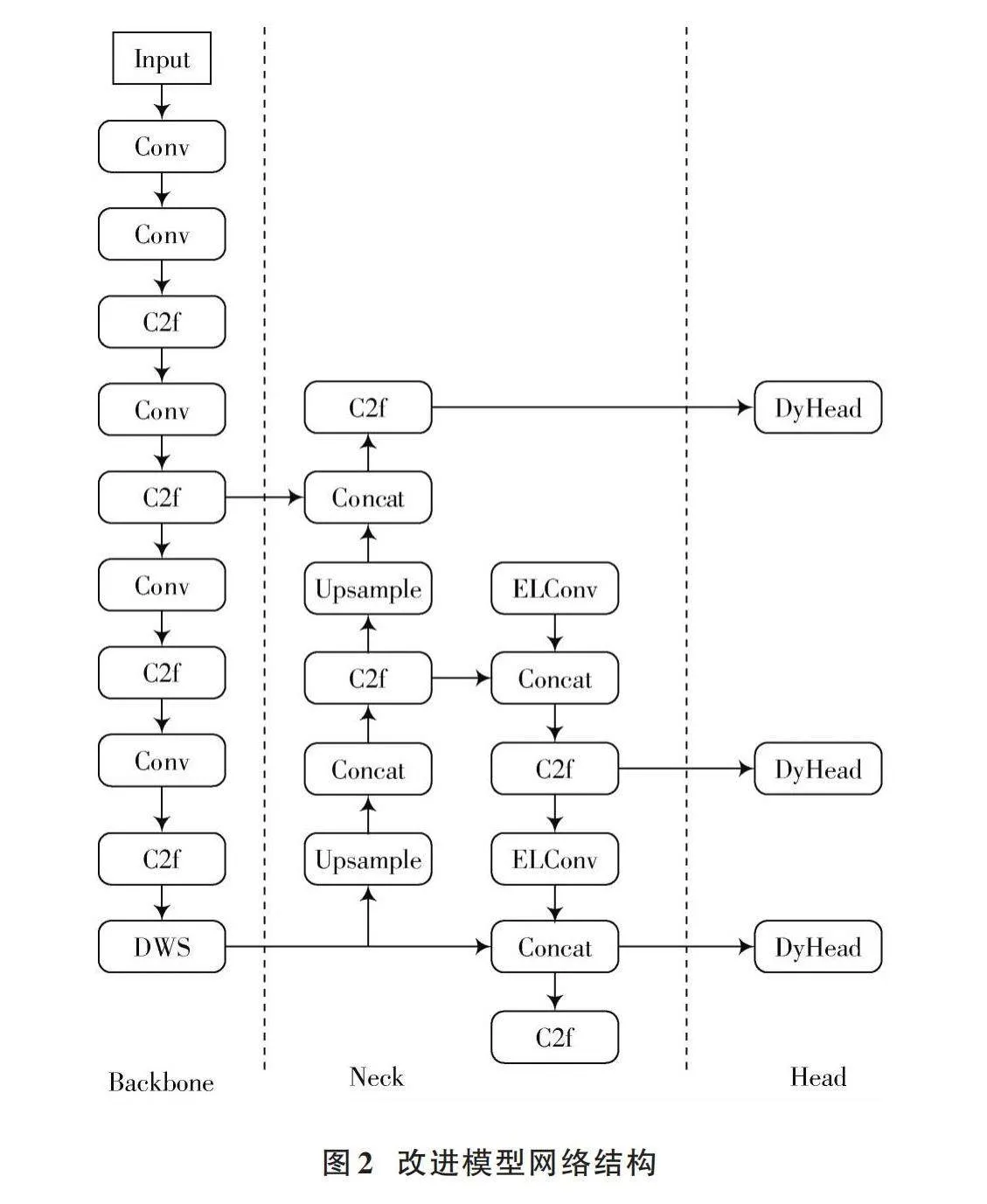
为了更有效地应对道路病害检测的需求,本文提出了一种改良的基于YOLOv8的模型,其架构如图2所示。图2中设计了一个全新的特征融合模块DWS用于主干网络特征融合;另外,提出了一种新的卷积结构用于替换原网络颈部的卷积;其次,在模型的头部添加了基于注意力机制的目标检测头Dynamic Head[7](DyHead);最后使用Wise⁃IoU[8](WIoU)损失函数代替原模型的损失函数。DWS模块提高了模型获取特征信息和全局上下文信息的能力;ELConv模块提高了深层网络对目标的定位能力;Dynamic Head提高了目标检测头部的表示能力;W⁃IoU损失函数改善了模型在边界框的精确性和匹配度。
2.1" 高效特征融合模块
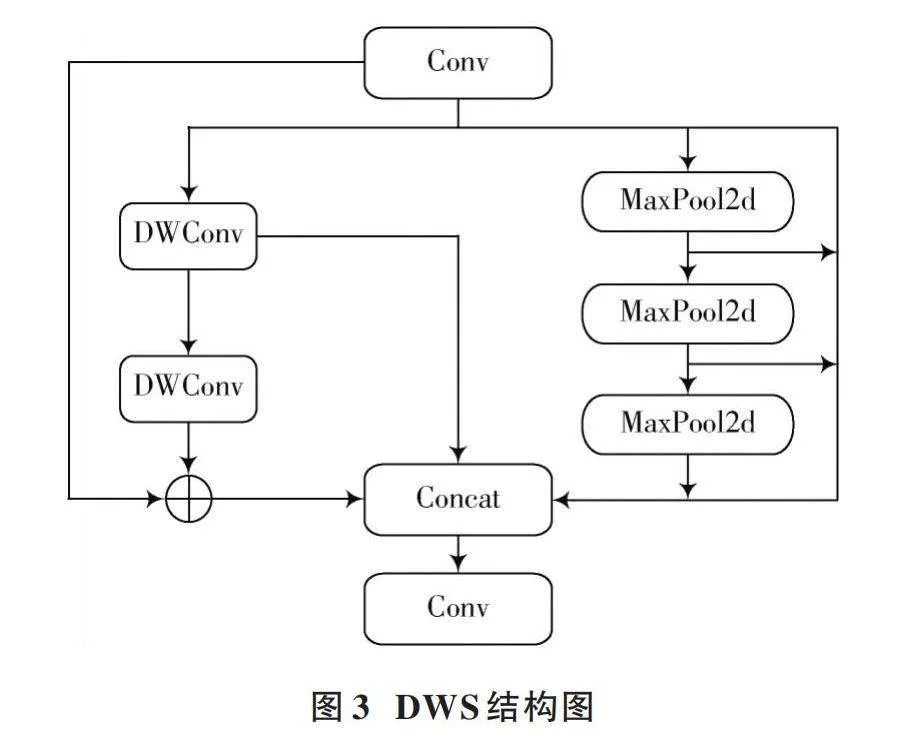
设计的DWS模块为多支路并行模块,可以感受不同尺度的目标信息。通过深度可分离卷积和最大池化等操作,可以有效地提取图像中的特征信息,并且通过不同尺度的最大池化(Spatial Pyramid Pooling)进行特征组合,可以捕获不同尺度下的信息,有助于提高模型的感知能力和泛化能力。DWS结构如图3所示。
DWS模块包含两个普通卷积层、两个深度可分离卷积层DWConv[9]以及三个最大池化层。普通卷积层的输入通道数为[c1],输出通道数为[c](隐藏通道数),卷积核大小为1×1,其输出如式(1)所示:
[cv1(x)=Conv(x,wcv1)+bcv1] (1)
式中:[x]是输入特征图;[wcv1]是第一个卷积层的卷积核;[bcv1]是偏置项。
深度可分离卷积(DWConv)可以表示为深度卷积和逐点卷积两步操作的组合。假设输入特征图为[x],深度卷积核为[wd],逐点卷积核为[wp],则深度可分离卷积表示如式(2)所示:
[DWConv(x,wd,wp)=PD(x,wd),wp] (2)
式中:[D(x,wd)]表示深度卷积操作;[P(x,wp)]表示逐点卷积操作。最大池化操作可表示为:
[MaxPool(x,k)=maxi∈[1,n](xi)] (3)
式中[k]为池化核的大小。
通过普通卷积层、深度可分离卷积层和最大池化层,最终输出6个特征图到连接层并按照指定的维度进行拼接得到新的特征图。最终卷积层的输入通过Concat模块进行拼接,具体拼接方式如式(4)所示:
[Concat=torch.cat(x,y1,y2,y3,x+a2,a1),1] (4)
式中:torch.cat表示拼接操作;[x]是第一个普通卷积层的输出特征图;[y1]、[y2]、[y3]分别是通过三个最大池化层得到的三个特征图;[a1]、[a2]分别是通过深度可分离卷积层得到的两个特征图;最后一个参数“1”表示按照第一个维度进行拼接。
2.2" ELConv模块
增加卷积网络的深度可以捕获更丰富的语义特征,但会降低特征图的分辨率,并丢失一部分位置信息,致使更多的研究倾向于开发更复杂的注意力模块,以获得更好的性能,这不可避免地增加了模型的复杂性。为了解决这一问题,本文提出将通道注意力ECABlock嵌入到卷积当中,并使用Leaky ReLU作为模块的激活函数,达到显著降低模型复杂度的同时带来性能增益的效果。
ELConv模块结构如图4所示。
ECABlock[10]采用了一种更加高效的方法来学习通道注意力,它使用一个1D卷积层对每个通道的特征进行卷积,然后使用Sigmoid函数学习通道注意力。这样可以大大降低计算复杂度,并在一定程度上提高模型性能。
普通的ReLU激活函数[11]虽然对训练神经网络起到有效的作用,但是在训练的过程中可能会出现一些神经元始终不会激活,从而让神经网络表达能力下降,为了避免这一问题,Leaky ReLU激活函数[12]在负半轴增加了一个很小的梯度值,这样在保留一定稀疏性的同时也避免了神经元坏死的问题。Leaky ReLU激活函数的前向传播过程如图5所示。
2.3" 基于注意力机制的目标检测头
Dynamic Head(DyHead)将目标检测头部与注意力统一起来。该方法结合多个自注意力机制,实现了任务感知、空间位置之间和尺度感知,在不增加模型计算量的前提下有效地提高了目标检测头部的表示能力。Dynamic Head在特征的每个特定维度上分别部署注意力机制,即水平、空间和渠道。可感知尺度的注意力模块只部署在水平尺寸上。感知空间的注意力模块部署在空间维度上(即高度×宽度)。任务感知的注意力模块部署在通道上。将张量重塑为三维张量,实现了检测头的统一注意力机制[13]。
2.4" 损失函数的优化
针对目标检测数据集每张图片质量高低参差不齐的情况,使用WIoU损失函数替换原模型的损失函数,WIoU损失函数是一种用于目标检测器的边界框回归损失函数,它结合了IoU度量和平滑项,作为边界框回归损失,包含一种动态非单调机制,并设计了一种合理的梯度增益分配,该策略减少了极端样本中出现的大梯度或有害梯度。WIoU损失函数的定义公式为:
[LWIoU=1-i=1nwiIoU(bi,gi)i=1nwi] (5)
式中:[n]代表目标物体的边界框总数;[bi]指第[i]个物体的预测边界框位置;[gi]为相应的第[i]个物体的实际标注边界框的位置;[wi]为对应权重值;IoU[(bi,gi)]用于衡量第[i]个预测边界框与真实标注框之间的交并比。
3" 实验与分析
3.1" 数据集
为了全面地证明改进算法的有效性,采用自建数据集road damage detection和公开数据集RDD 2022_Japan分别对本文改进算法进行实验验证。
road damage detection数据集部分图片来源于Roboflow,Roboflow为YOLOv8提供了一种更便捷、更快速的方式来准备训练数据。随后对数据集进行了数据增强,并使用LabelImg软件对道路病害进行标注,同时LabelImg软件会生成对应的标签文件,数据集为7分类:alligator cracking(鳄鱼开裂)、edge cracking(边缘开裂)、longitudinal cracking(纵向开裂)、patching(修补痕迹)、pothole(坑洼)、rutting(车辙)和transverse cracking(横向开裂)。road damage det数据集包含3 912张图片,经划分后得到训练集2 738张,验证集783张,测试集391张。
RDD 2022_Japan数据集[14]来源于RDD 2022。RDD 2022由东京大学发布,其中包括47 420幅道路图像,数据集共捕捉到四类道路损坏,包括D00(纵向裂缝)、D10(横向裂缝)、D20(网状裂缝)和D40(坑洞),选取其中10 506张照片作为数据集,经划分得到训练集8 404张,验证集1 050张,测试集1 052张。
3.2" 实验设备及评价指标
本文选用PyTorch深度学习架构对网络模型进行开发及优化,并进行了模型的训练以及实验。训练所使用设备的CPU为14 vCPU Intel[Ⓡ] Xeon[Ⓡ] Gold 6330 CPU,GPU为RTX 3090(24 GB),设置batch_size为16,初始学习率lr为0.01,训练轮次400轮,CUDA版本为11.0。本文从[F1]分数、模型的mAP@0.5(mean Average Precision)、模型的mAP@0.5:0.95、模型的参数量(Params)、每秒10亿次的浮点运算数(GFLOPs)五个指标来评价模型的性能。以正确率和召回率作为基本指标,使用准确率和召回率作为基础评估指标,同时计算基于这两者得分的[F1]分数和平均精度均值(mAP),以全面评价模型识别的准确性。此外,使用GFLOPs来衡量模型的计算复杂度,Params指标则用以表示模型所占用的存储空间。一般而言,Params和GFLOPs的数值越低,说明模型对计算资源的需求越少。
3.3" 消融实验
设置消融实验来分析本文中各改进模块对模型性能的影响。所有消融均在road damage detection数据集上进行,评价指标选用[F1]分数、mAP@0.5和mAP@0.5:0.95。表1是以YOLOv8模型为基线,√表示在模型中使用该模块。
由表1数据可知,单独替换原模型损失函数为WIoU,各项指标都没有变动,单独引入本文设计的DWS模块,[F1]分数、mAP@0.5和mAP@0.5:0.95分别提高了1%、0.6%和1.9%;单独替换颈部卷积为ELConv,三个评价指标分别提升了1%、0.9%和2.1%;替换目标检测头为DyHead,替换损失函数为WIoU,三个指标分别提高了1%、1.7%和1.7%;在替换目标检测头为DyHead,替换损失函数为WIoU的基础之上使用DWS特征融合模块,三个指标分别提升了2%、2.2%和2.9%。最后一个为本文最终改进模型,[F1]分数、mAP@0.5和mAP@0.5:0.95分别提高了3%、3.1%和4.8%。本文提出的优化策略在保持较低的参数增长和计算负担的基础上,其他各项指标均达到了提升的效果。
为了验证优化后的损失函数的有效性,将原始模型与仅改进损失函数的模型进行对比,图6为原始模型和改进模型的损失曲线对比图。
图6中,灰线代表原始函数损失曲线,黑线代表优化损失函数后的算法损失曲线。由图6可知,改进模型的损失函数可以更快达到收敛状态。
3.4" 不同模型检测与识别对比实验
为了验证YOLOv8模型在道路病害检测中的优势,与其他主流的目标检测算法模型进行比较。以[F1]分数、mAP@0.5和mAP@0.5:0.95和计算量GFLOPs作为评价指标,数据集选用自建数据集road damage detection,表2展示了对比结果。
由表2可知:YOLOv8模型在多个评价指标上超过了两阶段的Faster⁃RCNN[15]算法和单阶段EfficientNet[16]算法,并且与RT⁃DETR⁃L相比,RT⁃DETR⁃L模型虽然检测精度比YOLOv8提升了0.1%,但是其参数量和计算量庞大;与YOLO系列其他算法YOLOv3tiny[17]和YOLOv4tiny[18]相比,YOLOv8在保持低参数量、低计算量的同时,[F1]分数分别提高了14%和15%,mAP@0.5分别提高了7%和8.3%,mAP@0.5:0.95分别提高了5.9%和8%。结果显示,在针对道路病害识别的任务中,YOLOv8算法在与其他流行的目标检测方法对比中表现突出,显示出其在这一领域的适用性。
3.5" 泛化性验证
为了进一步验证改进模型的泛化性,分别将原始YOLOv8算法与本文提出的改进后模型算法在公开数据集RDD 2022_Japan上进行实验。以mAP@0.5和mAP@0.5:0.95作为评价指标,实验结果如表3所示。
数据显示改进模型在四个类别上的检测精度均高于YOLOv8模型,改进模型的效果在公开数据集上得到了验证。
4" 结" 论
基于传统的YOLOv8算法,本文设计了高效特征融合模块,提出了一种新的卷积结构ELConv模块,替换原模型头部为DyHead检测头,引入WIoU函数作为模型的损失函数,提出了一种新型道路病害检测识别方法。本文的主要贡献如下。
1) 设计了高效的特征融合模块DWS,提高模型获取特征信息和全局上下文信息的能力。
2) 针对现有部分研究存在对深度网络特征提取不充分的问题,提出了新的ELConv卷积模块,目标的空间信息得到了更好的感知,检测精度得到了有效提升。
3) 引入了添加基于注意力机制的目标检测头DyHead,结合尺度、空间和任务三种注意力机制,提升了目标检测头部的表示能力。
4) 使用WIoU损失函数替换原模型的损失函数,改善了模型在边界框的精确性和匹配度。在公开数据集RDD 2022_Japan上验证了模型的泛化性。
最终通过实验证明,本文提出的改进YOLOv8算法有效解决了现有研究中存在的问题,可以满足道路病害的检测需求。
注:本文通讯作者为崔冬。
参考文献
[1] 喻露,戴甜杰,余丽华.基于改进YOLOv5的道路病害智能检测[J].福建工程学院学报,2023,21(4):332⁃337.
[2] 王燕,王振宇.基于改进SE⁃Net和深度可分离残差的高光谱图像分类[J].兰州理工大学学报,2024,50(2):87⁃95.
[3] 许慧青,陈斌,王敬飞,等.基于卷积神经网络的细长路面病害检测方法[J].计算机应用,2022,42(1):265⁃272.
[4] 王鹏飞,黄汉明,王梦琪.改进YOLOv5的复杂道路目标检测算法[J].计算机工程与应用,2022,58(17):81⁃92.
[5] WEN H H, LI Y, WANG Y, et al. Usage of an improved YOLOv5 for steel surface defect detection [J]. Materials testing, 2024, 66(5): 726⁃735.
[6] 李松,史涛,井方科.改进YOLOv8的道路损伤检测算法[J].计算机工程与应用,2023,59(23):165⁃174.
[7] DAI X Y, CHEN Y P, XIAO B, et al. Dynamic head: Unifying object detection heads with attentions [C]// IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2021: 7373⁃7382.
[8] TONG Z J, CHEN Y H, XU Z W, et al. Wise⁃IoU: Bounding box regression loss with dynamic focusing mechanism [EB/OL]. [2023⁃01⁃26]. https://doi.org/10.48550/arXiv.2301.10051.
[9] 张磊,李熙尉,燕倩如,等.基于改进YOLOv5s的综采工作面人员检测算法[J].中国安全科学学报,2023,33(7):82⁃89.
[10] MOHARM K, ELTAHAN M, ELSAADANY E. Wind speed forecast using LSTM and Bi⁃LSTM algorithms over Gabal El⁃Zayt wind farm [C]// 2020 International Conference on Smart Grids and Energy Systems. Heidelberg: Springer, 2020: 922⁃927.
[11] 张恺翊,张宁燕,江志浩,等.深度学习模型中不同激活函数的性能分析[J].网络安全与数据治理,2023,42(z1):149⁃156.
[12] 王攀杰,郭绍忠,侯明,等.激活函数的对比测试与分析[J].信息工程大学学报,2021,22(5):551⁃557.
[13] 高昂,梁兴柱,夏晨星,等.一种改进YOLOv8的密集行人检测算法[J].图学学报,2023,44(5):890⁃898.
[14] ARYA D, MAEDA H, GHOSH S K, et al. Crowdsensing⁃based road damage detection challenge [C]// 2022 IEEE International Conference on Big Data (Big Data). New York: IEEE, 2022: 6378⁃6386.
[15] 王曾龙,蒋勇勇,彭海峰,等.一种基于Faster⁃RCNN的棉花虫害识别与统计方法[J].大众科技,2023,25(5):5⁃7.
[16] TAN M X, LE Q V. EfficientNet: Rethinking model scaling for convolutional neural networks [C]// International Conference on Machine Learning. New York: PMLR, 2019: 6105⁃6114.
[17] ADARSH P, RATHI P, KUMAR M. YOLO v3⁃tiny: Object detection and recognition using one stage improved model [C]// 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS). New York: IEEE, 2020: 687⁃694.
[18] JIANG Z C, ZHAO L Q, LI S Y, et al. Real⁃time object detection method based on improved YOLOv4⁃tiny [EB/OL]. [2020⁃11⁃09]. https://arxiv.org/abs/2011.04244.
作者简介:张" 强(1977—),男,河北邯郸人,硕士研究生,副教授,研究方向为计算机应用技术。
杜海强(2000—),男,河北保定人,在读硕士研究生,研究方向为计算机视觉。
赵伟康(1991—),女,河北邯郸人,博士研究生,讲师,研究方向为计算机视觉。
崔" 冬(1977—),女,河北邯郸人,硕士研究生,讲师,研究方向为数据库技术及应用。
猜你喜欢
今日农业(2022年3期)2022-06-05 07:12:02
江西教育·职教版(2022年9期)2022-04-29 00:44:03
今日农业(2021年8期)2021-11-28 05:07:50
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
烟台果树(2021年2期)2021-07-21 07:18:28
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
今日农业(2020年19期)2020-11-06 09:29:38
电子制作(2019年11期)2019-07-04 00:34:38
今日农业(2019年15期)2019-01-03 12:11:33
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
