
DCFF⁃Net:基于人体骨骼点的双流跨级特征融合动作识别网络
2024-11-30 00:00:00余翔连世龙
现代电子技术 2024年23期

















摘" 要: 在基于骨骼的动作识别任务中,骨骼点特征对于动作识别来说至关重要。针对现有方法存在输入特征不足、特征融合策略粗糙、参数量大等问题,提出一种基于人体骨骼点的双流跨级特征融合网络。首先,针对特征输入,用欧氏距离骨架特征(EDSF)和余弦角度骨架特征(CASF)两种局部关节特征来表征人体骨骼序列,帮助网络识别不同体态和体态相似的人体动作;其次,考虑到部分动作类别的运动轨迹与全局运动的相关性,引入全局运动特征(GMF)弥补局部关节特征在此类动作上识别精度不足的问题;此外,为了加强不同特征之间的信息交互,提出一种跨级特征融合模块(CLFF),对不同特征层、不同属性的动作特征进行特征互补,丰富了网络的特征形式;最后,网络采用一维卷积(Conv1D)进行搭建,减轻了模型的计算负担。实验结果表明,所提模型在JHMDB身体动作数据集上获得了84.1%的识别准确率,在SHREC手势动作数据集上分别获得了97.4%(粗糙数据集)和95%(精确数据集)的识别准确率,取得了与先进方法相当的性能。
关键词: 动作识别; 骨架特征; 运动轨迹; 局部关节特征; 全局运动特征; 跨级特征融合
中图分类号: TN911.73⁃34; TP391" " " " " " " " " "文献标识码: A" " " " " " " " " 文章编号: 1004⁃373X(2024)23⁃0081⁃08
DCFF⁃Net: Dual⁃stream cross⁃level feature fusion network
for skeleton⁃based action recognition
YU Xiang, LIAN Shilong
(School of Communications and Information Engineering, Chongqing University of Posts and Telecommunications, Chongqing 400065, China)
Abstract: In the skeleton⁃based action recognition task, skeleton features are crucial for action recognition. In view of the insufficient input features, rough feature fusion strategies, and a large number of parameters in the existing methods, a dual⁃stream cross⁃level feature fusion network (DCFF⁃Net) based on skeleton is proposed. For feature input, two local joint features, Euclidean distance skeleton features (EDSF) and cosine angle skeleton features (CASF), are used to characterize the human skeleton sequence to help the network identify human body movements in different postures and similar postures. Considering the correlation between the motion trajectories of some action categories and global motion, global motion features (GMF) are introduced to make up for the lack of recognition accuracy of local joint features in such actions. In addition, in order to strengthen the information interaction among different features, a cross⁃level feature fusion (CLFF) module is proposed to complement the action features of different feature layers and different attributes, which enriches the characteristics of the network form. The network is built with Conv1D, which reduces the computational burden of the model. Experimental results show that the proposed model achieves a recognition accuracy of 84.1% on the body action dataset JHMDB and 97.4% (coarse dataset) and 95% (fine dataset) on the gesture action dataset SHREC. To sum up, the proposed network achieves the performance comparable to the advanced methods.
Keywords: action recognition; skeleton feature; motion trajectory; local joint feature; global motion feature; cross⁃level feature fusion
0" 引" 言
人体动作识别是计算机视觉领域的热门研究方向之一,在人机交互、医疗康复、智能监控等领域应用广泛[1⁃4]。对于人体动作识别任务,有不同的数据输入模态,主要包括RGB视频、人体骨架序列、深度图等[5⁃9]。相较于RGB视频和深度图序列,人体骨骼点数据只包含人体的动作姿态信息,具有数据量少、复杂度低、不易受背景光照影响等特点,更加符合人体动作在运动中的实际变化[10]。此外,人体骨骼点数据可以减少隐私泄露。因此,基于人体骨骼点的动作识别方法受到了越来越多学者的关注。
目前,基于骨骼点的动作识别任务还存在着以下挑战。
1) 人体骨骼点数据量大且存在冗余信息,现有的方法对于骨骼点特征的表征十分单一,有些只关注到了局部关节特征,而有些只关注到了全局运动特征(Global Motion Feature, GMF)。所以如何从大量冗余数据中找出理想的骨骼点表征形式显得尤为重要。
2) 现有的动作识别方法不能同时兼顾轻量化和准确率两项指标,所以要探索构建出最适合提取骨骼点特征的学习网络,同时保证网络的参数量和复杂度较低,来实现高准确率、强鲁棒性的轻量化识别模型。
针对以上问题,受到文献[11]的启发,本文提出了一种基于人体骨骼点的双流跨级特征融合动作识别网络(DCFF⁃Net),主要研究如下。
1) 引入了双流特征输入,将局部关节特征和全局运动特征同时输入到网络,以增加网络对于不同动作和相似动作的识别准确率,并且提升网络的鲁棒性。
2) 提出了一种跨级特征融合模块(Cross⁃level Feature Fusion, CLFF),将局部特征和全局特征进行跨级融合,增加不同层级特征之间的信息交互,帮助网络获取不同特征之间的细节信息。
3) 网络整体采用一维卷积进行搭建,大大减少了模型的参数量和复杂度。
4) 在JHMDB和SHREC数据集上的实验结果表明,本文所提出的方法满足轻量化的应用要求,取得了与先进方法相当的性能。
1" 双流跨级特征融合网络
1.1" 总体架构
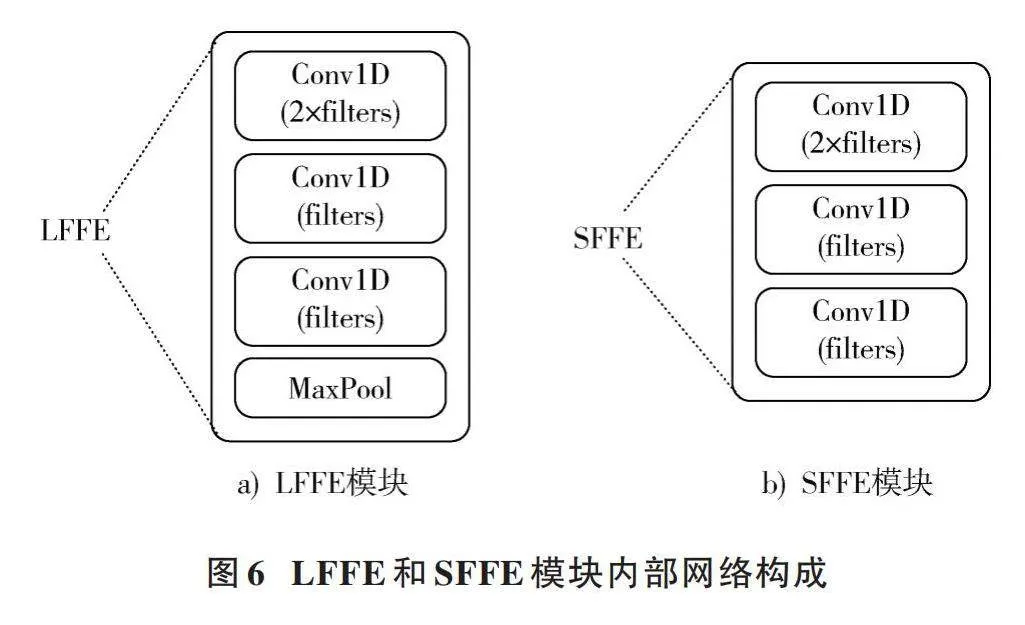
网络整体由特征输入、特征提取、特征融合三部分构成,如图1所示。在特征输入部分,总共有四种特征输入流,分别为欧氏距离骨架特征(Euclidean Distance Skeleton Feature, EDSF)、余弦角度骨架特征(Cosine Angle Skeleton Feature, CASF)、全局慢速动作特征(GSMF)、全局快速动作特征(GFMF)。对于EDSF、CASF、GSMF特征,帧数设置为32帧,而GFMF特征帧数设置为16帧,然后将他们分别输入特征提取器网络中的长帧特征提取模块(LFFE)和短帧特征提取模块(SFFE),接着通过Concat操作拼接四种不同的特征,送入特征融合网络。在特征融合阶段,将LFFE和SFFE模块提取的各级骨骼点特征通过CLFF模块与Concat之后的各级特征进行逐层融合,最后经过全局平均池化层和全连接层输出识别结果。
1.2" 双流特征输入
1.2.1" 局部关节特征
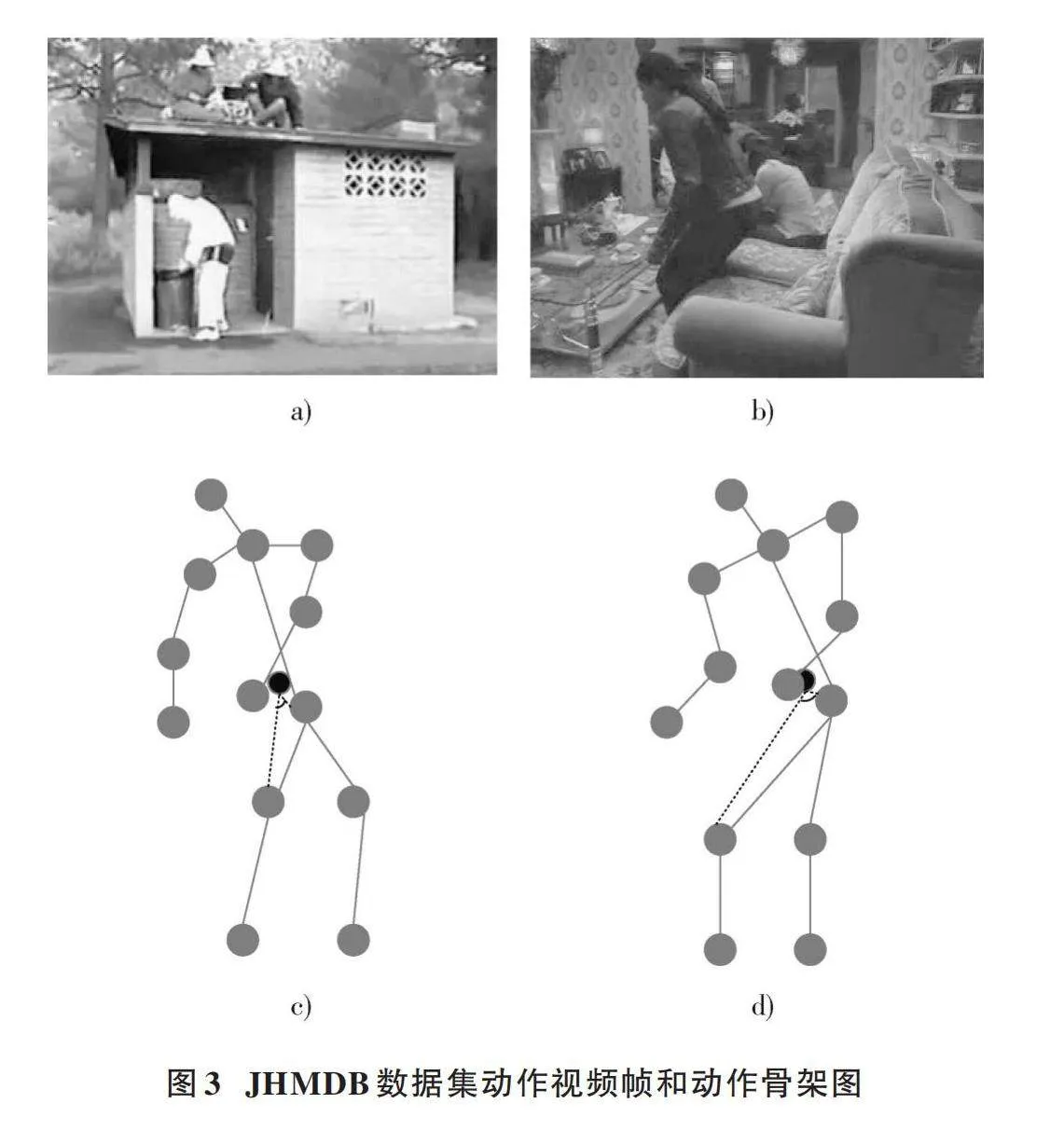
人体局部关节点之间的特征也称为位置视点不变特征。在人体运动的过程中,相邻关节点之间的联系是非常紧密的。如图2所示,当人体骨架序列进行翻转或者旋转时,关节点的坐标发生了改变,而关节点之间的距离和角度其实是没有发生改变的,这种特征具有位置视点不变性,能够很好地表征关节点之间的局部特征关系。
将第[k]帧、第[n]个关节点的2D坐标表示为[Jkn=x,y],同理,关节点的3D坐标表示为[Jkn=x,y,z],那么第[k]帧所有关节点的集合表示为[Sk=Jk1,Jk2,…,Jkn]。
通过欧氏距离公式表示任意两个关节点之间的距离,并将其转化为下三角矩阵的形式,那么第[k]帧的EDSF可以用如下矩阵表示:
[EDSFk=Jk1Jk2⋮⋱Jk1JkN…JkNJkN] (1)
式中:[JkiJkji≠j]表示关节点[i]到关节点[j]的欧氏距离,[k]代表第[k]帧,每个动作由32帧组成;[N]代表每帧的关节点个数。
CASF特征的引入主要是因为在不同的数据集中,对于一些体态相似的动作,EDSF特征无法达到很好的识别性能。为了进一步论证EDSF特征存在的问题,分析了JHMDB数据集中不同动作的视频帧。图3a)、图3b)展示了数据集中捡和坐这两个动作,发现这两个动作在运动过程中都会出现一个弯腰的状态,而这种情况就会对网络的识别造成干扰。为了更加清晰地分析这两个动作,将其通过2D关节点序列进行表征。从图3c)、图3d)可以发现两个动作的EDSF特征是相近的,但是这两个动作在弯腰时人体臀腿之间的关节角度却是不一样的。由此可见,对于相似的动作,EDSF特征不能很好地帮助网络进行识别,反而会成为噪声干扰因素。因此,在网络中引入余弦角度骨架特征,帮助网络区分体态相似的动作类别。
在获得了关节点的坐标向量之后,先计算坐标向量之间的余弦相似度,然后使用反余弦函数来计算两个关节点之间的角度。第[k]帧两个关节点之间的角度可以用如下公式计算:
[Angle(Jki,Jkj)=DegreearccosJki⋅JkjJkiJkj] (2)
式中:[Degree(Jki,Jkj)]表示求两个关节点之间的角度;arccos为反余弦函数;[Jki⋅JkjJkiJkj]表示求两个关节点向量之间的余弦相似度。
利用[Angle(Jki,Jkj)]求得关节点之间的角度后,再将其转化为上三角形矩阵的形式。第[k]帧的CASF表示为如下矩阵:
[CASFk=AngleJk1,Jk2…AngleJk1,JkN⋱⋮AngleJkN,JkN] (3)
同时,为了将两种特征进行充分融合,将两个特征矩阵进行拼接,最终得到如下的特征矩阵形式:
[Feature Matrix=……AngleJk1,JkN-1AngleJk1,JkN⋮⋮⋮AngleJk2,JkNJkN-1Jk1…⋱⋮JkNJk1JkNJk2……] (4)
1.2.2" 全局运动特征
局部关节特征使得网络具备了位置视点不变特性,但是只在网络中加入这种特征是单一且不充分的。如图4所示,当在做挥手这个动作时,手部的各个关节点之间的局部特征并没有发生变化,相反整个手的关节点坐标发生了改变。所以,当动作涉及到全局的运动轨迹时,仅仅靠局部关节特征是不够的。通过计算动作帧之间的时间间隔来表征全局运动,同时,通过取不同的帧间隔将全局运动特征细分为GFMF特征和GSMF特征。全局运动特征可以通过下面的公式计算得到。
[GFMFk=JCk+2-JCk," " k∈{1,3,…,k-2}GSMFk=JCk+1-JCk," " k∈{1,2,…,k-1}] (5)
式中:[k]代表第[k]帧;JC表示每帧关节点的笛卡尔坐标。
1.3" 跨级特征融合模块
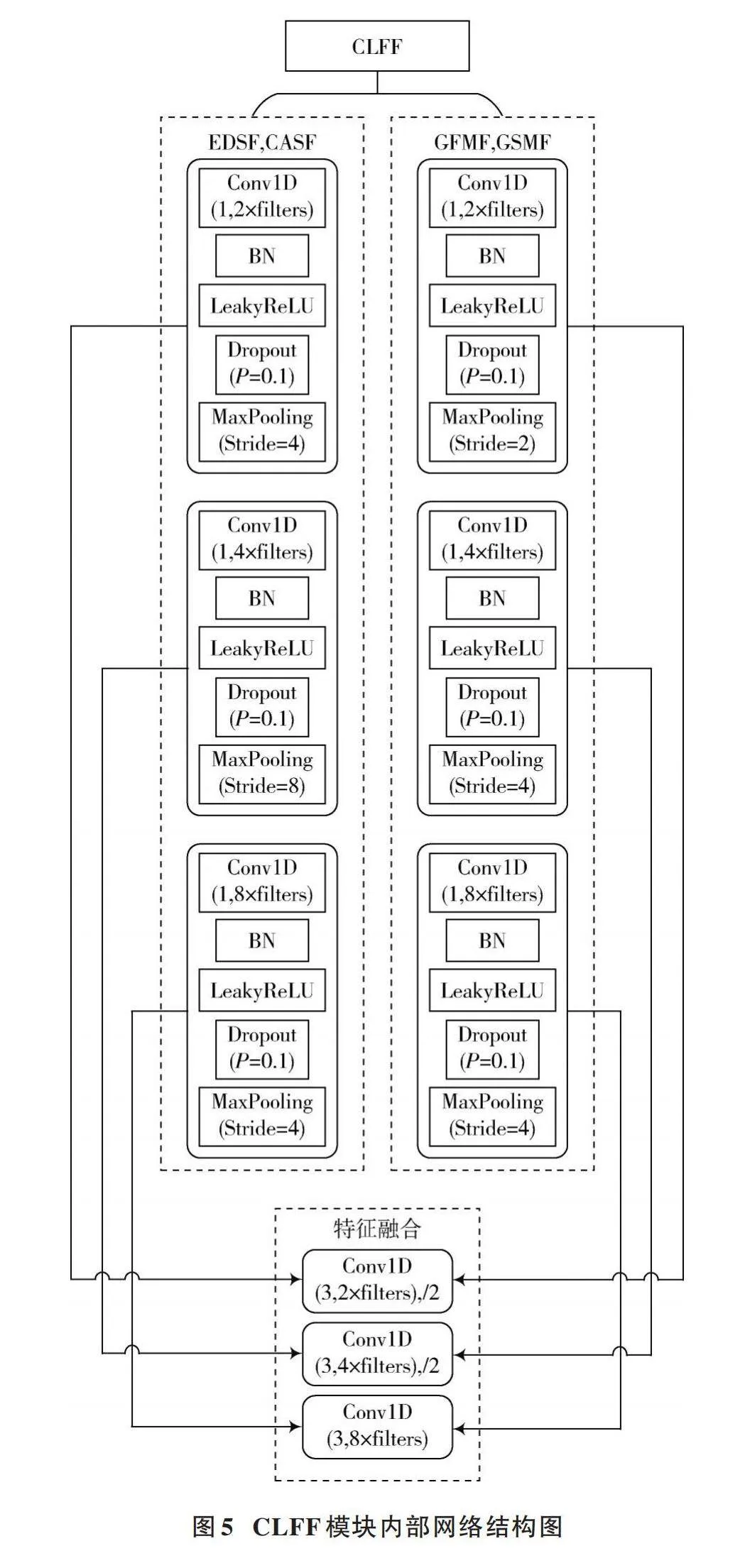
虽然在网络中同时引入了局部关节特征和全局运动特征,但是多特征的输入形式需要有效的特征融合结构对不同特征进行信息交互。现有的一些文献采用特征串联或者是简单地将特征在最后一层进行相连,但是这些方法的融合操作较为粗糙,不能充分挖掘不同层级和不同特征之间的特征信息。由此,设计了一种跨级特征融合模块(CLFF),使用跳跃方式连接不同层级之间的特征,这种方式不仅加强了网络对于不同关节特征的捕捉能力,同时也能将浅层特征和深层特征进行有效地融合,让网络学习到更加复杂的特征表达。对于局部关节特征EDSF和CASF与全局运动特征GFMF和GSMF分别设计了两个CLFF模块,每一个CLFF模块都是由三个卷积块组成,每一个卷积块又分别由一维卷积(Conv1D)、批归一化层(BN)、激活函数(LeakyReLU)、Dropout函数、最大池化层(MaxPooling)组成,如图5所示。
网络中特征输入形式为[(B,C,N)],其中[B]为batch_size,[C]为特征帧数,默认为32,[N]代表特征维度,对于JHMDB和SHREC这两种不同的数据集,[N]分别为105和231。CLFF模块中的三个卷积块分别对应LFFE模块和SFFE模块的三个卷积块,每个卷积块都将进行一次跨级特征融合操作,分别与特征融合阶段的各层级特征进行融合。LFFE和SFFE模块内部网络构成如图6所示。从图6中可以看到,网络中的长短帧特征提取模块LFFE和SFFE都包含了三个一维卷积块,主要的不同在于LFFE模块增加了一个MaxPooling层,以保证两个特征提取通道的特征保持相同的帧数,以进行后续的Concat操作。CLFF模块中的最大池化层MaxPooling的作用主要是为了设置不同层级特征的通道数,方便进行特征融合。对于EDSF和CASF,CLFF模块中的MaxPooling的步长分别设置为4、8、4,对于GFMF和GSMF特征,MaxPooling的步长设置为2、4、4。对于EDSF和CASF,CLFF模块的处理过程表示为:
[EmBed1(EDSF,CASF)→EmBed2(EDSF,CASF)→EmBed1(EDSF,CASF)] (6)
对于GFMF和GSMF特征,CLFF模块的处理过程表示为:
[EmBed1(GFMF,GSMF)→EmBed2(GFMF,GSMF)→EmBed1(GFMF,GSMF)] (7)
[EmBed1]和[EmBed2]的定义如下所示:
[EmBed1=MLRBNConv1D(1,x)EmBed2=MLRBNConv1D(3,x)] (8)
式中:数字1和3代表一维卷积核的大小。
2" 实验结果与分析
2.1" 数据集
JHMDB数据集[12]是对HMDB51数据集[13]的二次标注。JHMDB从HMDB51中提取了21个动作类别的928个视频剪辑,其中每个动作类别包含36~55个视频剪辑,每个视频剪辑包含15~40帧。本文选取JHMDB数据集中的14个动作类别,并且只使用2D关节点坐标进行动作识别。
SHREC数据集[14]是一个关于手势识别的数据集,考虑到手运动和手形状变化的差异,数据集根据手势使用手指的数量细分为14个手势类别的粗糙数据集(Coarse Datasets)和28个手势类别的精确数据集(Fine Datasets)。对于该数据集,按照官方[11]的样本划分规则,将1 960段序列样本作为训练集,840段序列样本用作测试集。
2.2" 实验设置
本文所有实验均在PyTorch框架上进行,使用Python 3.9和CUDA 11.7。GPU为NVIDIA" RTX" A5000 24 GB显存,CPU为Intel[Ⓡ] CoreTM i9⁃13900K。选用Adam优化器计算移动平均梯度和移动平均平方梯度,其中,[β1]和[β2]两个参数用于控制两个指数加权平均的衰减率,分别设置为[β1]=0.9,[β2]=0.999。对于输入的骨架序列,设置为32帧。对于超参数,设置初始学习率为0.002,epoch为600,batch_size为512。
2.3" 消融实验
2.3.1" 双流特征输入的有效性实验
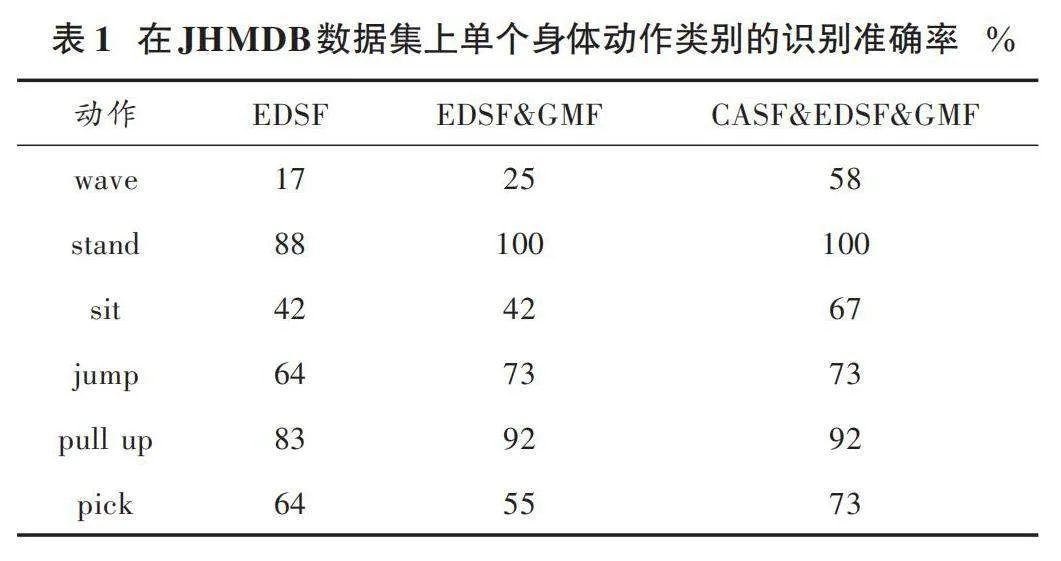
为了验证双流特征输入的有效性,在网络中依次加入局部关节特征和全局运动特征,观察单个动作类别准确率的变化,结果如表1、表2所示。表1显示了JHMDB数据集的部分单个动作的识别率,这些动作涉及到了局部关节运动以及全局运动。引入EDSF特征,此时挥手、坐、捡等动作的识别准确率较低。在EDSF特征的基础上,引入全局运动特征,挥手这个动作的识别准确率有一定程度上的提高,对于涉及全局运动轨迹的动作,如跳跃、引体向上,识别准确率都得到了提高,这说明全局运动特征能够更好地表征此类动作特征。在网络中引入CASF特征,发现对于坐和捡这两种体态相似的动作,网络的识别准确率有大幅度的提升,这也验证了CASF特征能够弥补EDSF特征的不足,帮助网络识别区分容易混淆的动作,增强网络的识别能力。
表2展示了网络在SHREC数据集14个手势类别上的识别结果,当网络中只有单一的局部特征时,一些手势动作的识别准确率并不理想,当网络中引入全局运动特征后,部分手势动作的识别准确率得到了明显的提高,这说明对于基于关节点的动作识别来说,局部关节特征和全局运动特征能够相互弥补特征不足,相比于单通道的特征输入,双流特征输入有利于后期网络的特征提取和融合。
2.3.2" CLFF模块的有效性实验
本文总共进行两组实验来验证本文模块的有效性。在本组实验中,默认在网络中引入了局部关节特征与全局运动特征,实验结果如表3、表4所示。
第一组实验,首先改变CLFF模块的层数,来研究CLFF模块深度对网络性能的影响。CLFF模块的基本层数分别设置为1、2、3。从表3、表4中可以看到,在JHMDB和SHREC两个数据集上,随着层数的增加,DCFF⁃Net的识别准确率在稳步提高,在[L]=3时达到饱和,同时网络整体的参数量也在随之而增加。从中可以看出,CLFF模块能够起到融合不同层级间特征的作用,对网络的识别性能有积极的正向作用。因为[L]=3时网络的识别性能最好,并且参数量只有一定范围的增长,所以在实验中选择[L]=3。
第二组实验,为了验证所提出的跨级特征融合模块的有效性,比较了三种不同的特征融合策略,结果如表5所示。其中,网络的表示如下:
1) DCFF⁃NetLocal表示只对局部关节特征进行跨级特征融合;
2) DCFF⁃NetGlobal表示只对全局运动特征进行跨级特征融合;
3) DCFF⁃NetAll表示对两种特征进行跨级特征融合。
从表5中可以看到,DCFF⁃NetAll的识别性能优于其他两种融合策略,这说明了只融合局部关节特征或者是全局运动特征并不能达到最理想的识别性能,而本文所提出的特征融合结构是最有效的。同时也证明了在基于人体骨骼点的动作识别任务中,局部关节特征和全局运动特征给网络带来的信息是同等重要的。CLFF模块通过将不同层级之间不同维度的特征进行跨级融合,从而能够更好地挖掘局部与全局特征之间的互补特征,帮助网络区分不同和形似的动作形态。
2.4" 与先进方法的比较实验
为了进一步验证本文提出方法的优越性,在JHMDB、SHREC数据集上将所提出的方法与一些经典方法以及先进的动作识别方法进行比较,其中包含了基于CNN网络的方法、基于GCN网络的方法和基于RNN网络的方法,使用这些方法在其原始论文中报告的精度。表6、表7显示了在两个数据集上的识别准确率比较结果。其中:R、F、P、H、S、C分别代表RGB⁃Images、Optical Flow、Pose、Heat Maps、Skeleton and Point Clouds;“—”表示论文没有提供相应的结果。
如表6所示,在JHMDB数据集上,本文提出的方法的识别准确率达到了84.1%,优于现有的方法,达到了最好的识别性能。与经典的动作识别方法PoTion[16]和Chained Net[15]相比,识别准确率分别提升了16.2%和27.3%,从中可以看出本文所提出的方法相比于经典的人体骨骼点识别方法具有优越性。与DD⁃Net[11]相比,虽在参数量上有0.2×106参数量的增加,但是在识别精度上却提升了6.9%。DD⁃Net在网络结构上没有使用特征融合策略,忽视了不同层级之间的特征交互。如表7所示,在SHREC数据集上,对于14 Gestures类别,本文方法的识别准确率为97.4%,超越了先进方法PSUMNet[25]和MS⁃ISTGCN[26]。DSTANet[21]在识别性能上与本文方法相当,但是其采用的网络完全基于自注意力机制,忽略了骨骼数据在时间和空间上的维度信息。虽然其提出了解耦方法来平衡骨骼点序列的时间与空间的独立性,但是这也使得网络产生了更多的参数量。对于28 Gestures类别,TD⁃GCN[27]略微优于本文的方法,原因主要是前者采用时间相关的邻接矩阵来学习人体骨架的拓扑结构,并且此方法使用的GCN网络能够从时间和空间上提取特征,而本文方法基于CNN网络,缺乏在时间维度上的特征提取能力。
3" 结" 语
本文提出一种基于人体骨骼点的双流跨级特征融合动作识别网络(DCFF⁃Net)。首先,在网络特征输入部分引入了双流特征输入,将局部关节特征和全局运动特征进行融合,帮助网络区分不同动作和体态相近的动作,增强了网络的鲁棒性;其次,在网络结构上设计了一种跨级特征融合模块(CLFF)来构建不同层级之间的特征信息交互,使得网络能够获取更多有用的人体骨骼点信息。实验结果表明,本文提出的方法在基于人体骨骼点的动作识别任务中取得了与先进方法相当的识别性能,网络的参数量也较少。但本文方法对于一些复杂相近动作特征的区分能力不是很强,所以在未来的工作中,将尝试加入更多的附加特征信息如RGB图像、热力图等,帮助网络获取更多的特征信息,并进一步研究适用于人体结构特征的网络结构。
注:本文通讯作者为连世龙。
参考文献
[1] DUAN H D, ZHAO Y, CHEN K, et al. Revisiting skeleton⁃based action recognition [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2022: 2959⁃2968.
[2] ZHENG H, ZHANG B, LIN J, et al. A two⁃stage modality fusion approach for recognizing human actions [J]. IEEE sensors journal, 2023(22): 23.
[3] XIN W T, LIU R Y, LIU Y, et al. Transformer for skeleton⁃based action recognition: A review of recent advances [J]. Neurocomputing, 2023, 537: 164⁃186.
[4] KE L, PENG K C, LÜ S. Towards To⁃a⁃T spatio⁃temporal focus for skeleton⁃based action recognition [C]// Proceedings of the AAAI Conference on Artificial Intelligence. [S.l.: s.n.], 2022: 1131⁃1139.
[5] ZHEN R, SONG W C, HE Q, et al. Human⁃computer interaction system: A survey of talking⁃head generation [J]. Electronics, 2023, 12(1): 218.
[6] SINGH K, DHIMAN C, VISHWAKARMA D K, et al. A sparse coded composite descriptor for human activity recognition [J]. Expert systems, 2022, 39(1): e12805.
[7] 黄镇.基于深度学习的高效动作识别算法研究[D].合肥:中国科学技术大学,2022.
[8] YOON Y, YU J, JEON M. Predictively encoded graph convolutional network for noise⁃robust skeleton⁃based action recognition [J]. Applied intelligence, 2022(3): 2317⁃2331.
[9] SÁNCHEZ⁃CABALLERO A, FUENTES⁃JIMÉNEZ D, LOSADA⁃GUTIÉRREZ C. Real⁃time human action recognition using raw depth video⁃based recurrent neural networks [J]. Multimedia tools and applications, 2023, 82(11): 16213⁃16235.
[10] WANG C L, YAN J J. A comprehensive survey of RGB⁃based and skeleton⁃based human action recognition [J]. IEEE access, 2023, 11: 53880⁃53898.
[11] YANG F, WU Y, SAKTI S, et al. Make skeleton⁃based action recognition model smaller, faster and better [C]// Proceedings of the 1st ACM International Conference on Multimedia in Asia. New York: ACM, 2019: 1⁃6.
[12] GHORBANI S, MAHDAVIANI K, THALER A, et al. MoVi: A large multipurpose motion and video dataset [J]. Plos one, 2021, 16(6): e0253157.
[13] KUEHNE H, JHUANG H, GARROTE E, et al. HMDB51: A large video database for human motion recognition [C]// 2011 International Conference on Computer Vision. [S.l.: s.n.], 2011: 2556⁃2563.
[14] LI C K, LI S, GAO Y B, et al. A two⁃stream neural network for pose⁃based hand gesture recognition [J]. IEEE transactions on cognitive and developmental systems, 2022, 14(4): 1594⁃1603.
[15] ZOLFAGHARI M, OLIVEIRA G L, SEDAGHAT N, et al. Chained multi⁃stream networks exploiting pose, motion, and appearance for action classification and detection [C]// Proceedings of the IEEE International Conference on Computer Vision. New York: IEEE, 2017: 2923⁃2932.
[16] CHOUTAS V, WEINZAEPFEL P, REVAUD J, et al. Potion: Pose moTion representation for action recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 7024⁃7033.
[17] ASGHARI⁃ESFEDEN S, SZNAIER M, CAMPS O I. Dynamic motion representation for human action recognition [C]// Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. New York: IEEE, 2020: 546⁃555.
[18] LUDL D, GULDE T, CURIO C. Simple yet efficient real⁃time pose⁃based action recognition [C]// 2019 IEEE Intelligent Transportation Systems Conference (ITSC). New York: IEEE, 2019: 581⁃588.
[19] SHAH A, MISHRA S, BANSAL A, et al. Pose and joint⁃aware action recognition [C]// Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. New York: IEEE, 2022: 141⁃151.
[20] MIN Y C, ZHANG Y X, CHAI X J, et al. An efficient PointLSTM for point clouds based gesture recognition [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2020: 5760⁃5769.
[21] SHI L, ZHANG Y, CHENG J, et al. Decoupled spatial⁃temporal attention network for skeleton⁃based action⁃gesture recognition [C]// Proceedings of the Asian Conference on Computer Vision. Heidelberg: Springer, 2020: 38⁃53.
[22] SHIN S, KIM W Y. Skeleton⁃based dynamic hand gesture recognition using a part⁃based GRU⁃RNN for gesture⁃based interface [J]. IEEE access, 2020, 8: 50236⁃50243.
[23] LIU J B, LIU Y C, WANG Y, et al. Decoupled representation learning for skeleton⁃based gesture recognition [C]// Procee⁃dings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2020: 5750⁃5759.
[24] SABATER A, ALONSO I, MONTESANO L, et al. Domain and view⁃point agnostic hand action recognition [J]. IEEE robotics and automation letters, 2021, 6(4): 7823⁃7830.
[25] TRIVEDI N, SARVADEVABHATLA R K. PSUMNet: Unified modality part streams are all you need for efficient pose⁃based action recognition [C]// European Conference on Computer Vision. Heidelberg: Springer, 2022: 211⁃227.
[26] SONG J H, KONG K, KANG S J. Dynamic hand gesture recognition using improved spatio⁃temporal graph convolutional network [J]. IEEE transactions on circuits and systems for video technology, 2022, 32(9): 6227⁃6239.
[27] LIU J F, WANG X S, WANG C, et al. Temporal decoupling graph convolutional network for skeleton⁃based gesture recognition [J]. IEEE transactions on multimedia, 2023, 26: 811⁃823.
作者简介:余" 翔(1969—),男,重庆人,硕士研究生,教授,研究方向为计算机视觉、人工智能、移动边缘计算等。
连世龙(2000—),男,江苏南京人,硕士研究生,研究方向为计算机视觉。
