
VR环境下基于多观测角度人眼成像特性的注视估计研究
2024-11-30 00:00:00牛锐房丰洲任仲贺侯高峰李子豪
现代电子技术 2024年23期









摘" 要: 在虚拟现实(VR)的沉浸式场景中,基于先进的注视估计技术实现精确的注视点渲染,能够优化计算资源分配效率、缓解用户体验过程中可能产生的眩晕感。目前,可用的VR环境下的注视估计数据集只有单观测角度眼睛图像,缺乏不同观测角度的眼部图像数据集。文中构建了一个包含23 040张多观测角度眼睛图像的注视估计数据集与一个包含15 824张带有瞳孔标注的多观测角度眼睛图像的瞳孔检测数据集,并提出了一种结合多观测角度眼睛图像特征以相互补偿的多分支网络模型。将注视估计数据集样本用于模型的训练过程,预测欧氏距离损失可以达到7.68像素。进一步,将包含瞳孔位置信息的权重地图与图像融合,瞳孔位置信息的融合输入增强了模型的性能,欧氏距离损失降低到7.45像素。这项研究表明,所开发的模型能够提升VR环境下的注视估计精度,从而推动注视估计技术在VR产品中的广泛应用。
关键词: 注视估计; 虚拟现实; 卷积神经网络; 多分支网络; 特征融合; 瞳孔检测
中图分类号: TN911.73⁃34; TP391.4" " " " " " " " " "文献标识码: A" " " " " " " " 文章编号: 1004⁃373X(2024)23⁃0001⁃07
Study on gaze estimation based on multi⁃angle eye imaging
characteristics for VR environment
NIU Rui, FANG Fengzhou, REN Zhonghe, HOU Gaofeng, LI Zihao
(State Key Laboratory of Precision Measuring Technology and Instruments, Laboratory of Micro/Nano Manufacturing Technology,
Tianjin University, Tianjin 300072, China)
Abstract: In immersive virtual reality (VR) scenes, accurate gaze point rendering based on advanced gaze estimation technology can optimize computational resource allocation efficiency and alleviate possible dizziness during user experience. Currently, the available VR gaze estimation datasets only have eye images from a single observation angle, and lack eye image datasets from different observation angles. In this paper, a gaze estimation dataset containing 23 040 eye images with multiple observation angles and a pupil detection dataset including 15 824 pupil annotation images with multiple observation angles are constructed, and a multi⁃branch network model combining features of eye images with multiple observation angles compensating for each other is proposed. The samples of the gaze estimation dataset are used in the training process of the model and the predicted Euclidean distance loss can reach 7.68 pixels. Furthermore, the weight map containing pupil position information is fused with the image. The fusion and input of pupil position information enhances the performance of the model, and the Euclidean distance loss is reduced to 7.45 pixels. This study demonstrates that the developed model can improve the accuracy of gaze estimation in VR environments, so as to promote the widespread application of gaze estimation technology in VR products.
Keywords: gaze estimation; virtual reality; convolutional neural network; multi⁃branch network; feature fusion; pupil detection
0" 引" 言
VR技术是一种能够创造三维虚拟世界的计算机仿真技术,利用辅助硬件设备和软件系统,生成一个高度沉浸的虚拟环境,为用户带来多种感官体验。然而,要实现真正意义上的沉浸自然交互,VR技术仍面临若干挑战,其中计算资源分配与用户体验中的眩晕问题尤为突出。
在VR应用中,计算资源的有效分配是VR设备流畅运行的基础。高质量的交互体验依赖于实时的高分辨率图像渲染,这对计算能力提出了极高的要求[1]。同时,用户在长时间使用VR设备后常会遭遇“虚拟现实眩晕”现象,视觉和前庭感觉在描述运动状态时的不一致成为晕动病的催化剂[2]。眩晕感极大地降低了VR交互的舒适度,成为制约VR技术发展的重要障碍。
为应对上述挑战,研究人员引入了注视点渲染技术,该技术能够在减少总体计算工作量的同时,确保感知层面的高水平图像质量,有效分配计算资源并减少眩晕感。通过用户的实际注视点动态调整图像的渲染质量,确保用户主要注视区域的画面保真度最高,而边缘区域则适当降低渲染精度,以此高效利用计算资源并减轻因视觉与运动感知不匹配导致的不适感。
实现注视点渲染的关键在于精确且实时地估计用户的注视位置。注视估计技术可以通过记录眼睛注视特定位置时的相关物理参数来测量和估计注视区域。该技术已在VR [3⁃5]领域得到广泛应用,有助于增强人们对吸引注意力的事物的理解。此外,先进的注视估计对现代工业的发展也起到了促进作用[6⁃7]。注视估计方法一般分为基于二维映射的方法、基于三维模型的方法和基于外观的方法。通过采用注视估计技术,针对人眼注视区域分配更高的渲染分辨率,同时减少外围非注视区域的视觉复杂度,能有效提升VR设备的资源利用效率。
文献[8]开发了一种头戴式设备来估计用户视觉平面上的注视点,进一步开发了3D眼睛模型,可以从眼睛图像中有效定位眼睛注视点,所提出系统的平均准确率、查准率和召回率均可以达到97%以上。文献[9]提出了一种应用于VR环境的轻量级的基于神经网络的方法,仅利用过去的凝视数据来预测未来的凝视位置,在采用OpenNEEDs这一标准数据集进行严格评估时,相较于已有基线模型提高了3%~22%。
本文研究的目标在于通过VR环境中多观测角度的眼睛图像全面分析眼睛特征,进一步开发注视估计模型。该模型旨在融合来自不同观测角度的眼睛图像信息,利用深度学习算法实现对用户注视点的高精度预测。目前公开的大型数据集主要为单个观测角度的眼睛图像数据,仅基于单一观测角度的眼睛图像进行注视估计,对于眼睛特征信息的捕捉不够全面。基于以上问题,本文构建了一个多观测角度注视估计(MAG)数据集和一个多观测角度瞳孔检测(MAP)数据集,包括高低两个观测角度的眼睛图像。本文进一步提出了一种结合多个观测角度眼睛图像的注视估计模型,并融合权重地图,引导模型聚焦于关键区域的信息,进一步提高注视估计精度。
1" 多观测角度眼睛图像采集
本文提出了一种采集多观测角度眼睛图像数据的图像采集装置。通过该装置,可以同时捕获左眼和右眼的高低角度的四种图像。图像采集装置包括两个红外双目摄像头、红外光源、头部承托装置、标定屏和采集图像数据的计算机。
对于红外光源的选择,本文采用波长为940 nm的3×3红外LED阵列来提供环境照明。如图1所示,两个双目红外相机位于受试者眼睛的上下两侧,标定屏幕位于受试者的对侧,头部承托装置帮助受试者固定头部位置,红外光源安装在低角度红外双目摄像机的中部,标定屏幕用于显示标定点。在图像采集装置中,采集相机由两个垂直放置并通过光学平台固定的双目红外相机组成。双目相机的分辨率为1 280×480,将双目相机的图像分为相同尺寸的左右相机图像,每张图像分辨率为640×480。
每个受试者需要依次注视36个标定点,每个点之间[x]方向的间隔为250像素,[y]方向的间隔为150像素。每个注视点的半径为10个像素单位,实际测量约为0.25 cm。本次实验的受试者共12人,其中部分受试者采集了多组数据,实验共采集16组数据。每组数据包括左右眼睛的高低观测角度的图像与对应的注视点二维坐标。
MAG数据集是通过将不同角度的眼睛图像与受试者注视校准点时的校准点坐标相关联来创建的。样本数量为23 040张,标签为[2D(x,y)]格式的标定点坐标。
本文进一步提供了一个带有瞳孔区域标注的MAP数据集,数据集包含15 824张多观测角度眼睛图像,覆盖了高低两个观测角度的左右眼睛图像,并且使用labelme对每张图像中的瞳孔区域进行了标注。
2" 多观测角度注视估计模型
2.1" 卷积神经网络
在深度学习领域,卷积神经网络(CNN)以其独特的结构和高效的特征提取能力成为图像识别、目标检测等任务的首选模型之一。CNN的基本操作是对图像的局部区域进行卷积提取,建立一个窗口在输入图像上滑动,计算输入图像与卷积核的点积和,在每层的卷积操作中使用相同的卷积核来减少参数的数量,并结合池化操作基于局部区域特征来实现位移不变性。
然而,由于内存空间和运算能力的限制,神经网络模型在嵌入式设备上的运行仍然是一个巨大的挑战。在模型部署上,本文采用轻量化卷积神经网络作为特征提取主干网络。轻量化卷积神经网络的主要思想在于设计更加高效的模型,可以在资源受限的环境下实现足够的性能,即通过人工设计神经网络架构、模型压缩、特征图重用等技术将网络参数减少,并且不损失网络的性能。常用的轻量化卷积网络包括SqueezeNet、ShuffleNet、MobileNet系列等。
经过实际测试与调研,本文起始阶段选用ShuffleNetV2[10]作为注视估计模型的特征提取网络。为进一步探索不同网络架构对此任务的适用性与效能,后续实验中将ShuffleNetV2替换为SqueezeNet、ResNet以及MobileNetV2等其他高效神经网络模型,通过对比分析与评估,选出在注视估计任务中表现最优的特征提取网络。
2.2" 模型构造
由于观测角度的不同,眼睛图像的特征分布也会有很大的区别,现有的方法对于不同观测角度的图像特征没有充分地研究。针对于不同观测角度图像信息对于模型预测的影响,本文提出了高观测角度注视估计(HAGE)模型、低观测角度注视估计(LAGE)模型,并在此基础上,融合两个观测角度眼睛图像特征提出了多观测角度注视估计(MAGE)模型。HAGE模型和LAGE模型均为双分支网络,不同的是,HAGE模型的输入层接收的是高观测角度眼睛图像,而LAGE模型的输入层接收的是低观测角度眼睛图像;MAGE模型为4个分支的多分支网络,通过融合不同观测角度的眼睛图像特征,MAGE模型可以接收到更加丰富的眼睛特征信息,显著增强了模型的鲁棒性与准确性。三个模型均选用ShuffleNetV2 0.5×作为特征提取的主干网络。
1) 如图2所示,HAGE模型的结构为输入层接收高观测角度的左眼和右眼图像,图像分别输入两个独立的ShuffleNetV2 结构的分支网络,并且通过两个分支网络得到高观测角度的左眼图像特征[Fhl]和高观测角度的右眼图像特征[Fhr]。通过全连接层将两张特征图降维输出,在特征维度上进行拼接来融合两个不同的特征,得到高观测角度的眼睛总特征[Fh],输入全连接层得到预测注视点坐标。
2) LAGE模型的结构与HAGE模型的结构相似,不同的是输入层接收的图像为低观测角度的左眼和右眼图像数据。将得到的低观测角度的眼睛总特征输入全连接层,经过与HAGE模型相同的操作,得到输出的注视点二维预测坐标。相比于细节更加明显的高观测角度的眼睛图像,低观测角度的眼睛图像没有睫毛遮挡的问题,因此两个观测角度的眼睛图像的训练结果往往不同。
3) MAGE模型的结构为4个分支的多分支网络模型,输入层接收的图像为高、低两个观测角度的左眼和右眼图像数据。在MAGE模型中4个分支保持独立,采用晚期融合的方式先融合相同观测角度提取的眼睛特征。如图3所示,提取高观测角度眼睛图像特征的2个分支在得到高观测角度的眼睛特征[Fhl]、[Fhr]后,将两个特征降维,减少融合的特征参数量。通过拼接的特征融合方式得到高观测角度的眼睛总特征[Fh]。通过相同方式,提取低观测角度眼睛图像特征的2个分支在经过降维融合后得到低观测角度的眼睛总特征[Fl]。将高观测角度的眼睛总特征[Fh]与低观测角度的眼睛总特征[Fl]进行拼接,得到眼睛总特征[Fall]。将眼睛总特征[Fall]输入全连接层,得到输出的注视点二维预测坐标。
2.3" 模型训练
2.3.1" 数据预处理
由于红外光源和观测角度的影响,不同组的图像特征差异较大。低观测角度由于红外摄像头更靠近红外光源,导致低观测角度所捕获图像的灰度值普遍较高,而高观测角度的红外摄像头距离红外光源较远,所拍摄到的图像灰度值较低。同时,由于观测角度不同,低观测角度的眼睛图像中,面部区域和眼睛区域的占比相比于高观测角度的眼睛图像数据更高。因此,本文针对收集到的四种眼睛图像数据,采取分组归一化与标准化的方法进行预处理。
在预处理时,通常使用均值(mean)和标准差(std)对图像按通道进行标准化,即图像的每个像素值减去均值,再除以标准差。将图像像素值标准化为均值为0、标准差为1的值,有助于提高训练模型的效果,加快模型的收敛速度。
其中,参数均值和标准差分别表示图像每个通道的均值和标准差序列,计算公式如式(1)、式(2)所示:
[mean=1Ni=1Nxi] (1)
[std=1Ni=1Nxi-mean2] (2)
2.3.2" 实验结果分析
本文使用Adam优化器和余弦退火策略的组合进行训练。对于优化器,本文选择Adam[11]优化器,它通过维持模型梯度的一阶动量和二阶动量以及梯度的平方来调整模型的参数。Adam优化器可以自适应调整学习率,但结果与调整超参数的效果有关。实际测试中,单独使用Adam优化器的效果很差,学习率更新不及时。因此,本文采用Adam作为优化器,并且将余弦退火算法[12]作为调度器。设置相同的[Tmax]与epoch可以使学习率在中前期保持在较高的水平,保证模型收敛的速度,同时在后期再逐渐降低,使得模型的搜索更加细致,避免陷入局部最优解问题。
本文的训练参数设置:学习率为0.001,[Tmax]为50,batch size为16。所有训练和测试实验均在单个GeForce RTX 3090 GPU、Ubuntu 20.04系统和PyTorch 1.12.0平台上进行。
当前主流的评价注视估计效果主要有两种方式:一种是计算注视角度的误差来量化估计;另一种是计算预测点与真实注视点之间的欧氏距离来评价。如在GazeCapture[13]数据集中,在屏幕上建立多个注视点,并将其在屏幕上的二维坐标作为标注,使用欧氏距离(ED)来评价注视估计效果。本文使用欧氏距离作为损失函数和评价指标。
在数学中,欧几里得距离或欧几里得度量指在欧几里得空间中,两个点之间的直线距离。使用这个距离,欧氏空间成为度量空间。在二维平面上,两点[P1x1,y1]、[P2x2,y2]之间的欧氏距离可以通过式(3)计算:
[ED=x2-x12+y2-y12] (3)
用MAG数据集测试三个模型,采用注视估计真实注视点与预测注视点的欧氏距离ED作为每个模型的loss指标。实验过程中采用随机分割以保证其可靠性。每个实验组的训练与验证样本比例设置为4∶1,对实验结果进行分析,比较三种模型的性能。
如图4a)所示,MAGE模型开始训练时的初始损失比HAGE模型和LAGE模型更低,与其他两个模型相比,MAGE模型收敛速度更快,其训练损失可以迅速减少到较低的水平。相比于HAGE模型和LAGE模型,MAGE模型的损失曲线更加平滑,鲁棒性较高。HAGE模型的训练损失最低达到8.357 0像素,而LAGE模型的训练损失最低可以达到7.147 5像素,MAGE模型的训练损失最低,最低可以达到5.805 0像素。
在模型训练过程中,每完成两个epoch的学习,就会进行一次验证,以评估模型的表现。如图4b)所示,HAGE模型和LAGE模型在验证时的曲线震荡幅度较大,而MAGE模型损失曲线较为平滑。HAGE模型的验证损失最小为11.101 0像素,LAGE模型的验证损失最小为9.696 4像素,MAGE模型的验证损失最小为7.677 0像素,与训练损失的差距最小。与HAGE模型和LAGE模型相比,MAGE模型在整个训练过程中都保持了较低的验证损失,表明采用多观测角度的眼睛图像特征对于提高注视预测精度,以及提升模型鲁棒性展现出了显著的正面效应。
如表1所示,对MAGE模型的眼睛特征提取网络进行测试,使用SqueezeNet、MobileNetV2、ResNet、ShuffleNetV2四种网络进行对比。发现使用ShuffleNetV2作为眼睛特征提取网络相比于使用其他网络模型,实时性以及参数量等方面的综合性能最佳,同时模型的欧氏距离误差为7.68像素,精度最高。在实时性表现上,该模型部署于GeForce RTX 3060 GPU平台上,实现了34.38 f/s的推理速度,表明其具有良好的实时处理能力。
3" 结合瞳孔位置信息的注视估计模型
3.1" 瞳孔检测
在MAGE模型取得不错的效果后,本文做出了进一步的引申。在原有的多观测角度眼睛图像基础上,本文进一步增加了一个瞳孔区域提取模块。将眼睛图像输入瞳孔区域提取模块,得到一个瞳孔区域的mask,通过权重地图融合策略,将mask与眼睛原始图像进行融合,丰富模型的输入特征信息,进一步总结设计出了多信息注视估计模型(MIGE)。通过将瞳孔区域位置信息与眼睛图像特征信息融合,可以增强模型的有效特征捕捉能力,提高模型的预测性能。
3.1.1" 目标检测算法
传统的目标检测方法需要大量人工标注,并且复杂度高,容易产生大量无用标注。研究人员通常使用深度学习的方法进行目标检测,通过大量数据的训练以及模型参数设计,深度学习模型往往可以达到很高精度的检测效果。常用的用于实时目标检测的深度学习算法有YOLO、SSD、R⁃CNN、Faster R⁃CNN等。其中,R⁃CNN、Faster R⁃CNN模型通过两个步骤实现样本分类。即先由算法生成一系列样本的感兴趣区域,再通过卷积神经网络进行样本分类。而YOLO与SSD则不用产生候选框,直接输出物体的分类概率和坐标值,在处理图像的同时预测边界框和样本分类。两种方法的区别在于,通过两个步骤实现样本分类的准确度较高,而直接进行分类的方法模型运行速度更快。SSD相比于YOLO需要在多个不同尺度特征图上进行预测,在实时性上稍有不足。结合本文的使用场景,对于实时性要求较高,因此选用YOLO算法用于本文的目标检测任务。
3.1.2" 模块训练
在本文的研究工作中,选取最新的YOLOv8 Nano[14]目标检测模型作为瞳孔检测任务的主干网络。本文将MAP数据集划分为训练集和验证集,由于MAP数据集的每个角度的左右眼睛图像的特征不会有很大变化,样本间的差异较小,并且MAP数据集的样本数量较大,选取小比例的验证集也可以很好地反映训练效果。因此将训练集和验证集的比例设置为9∶1。经过100次epoch训练后,YOLOv8 Nano模型在验证集的分类精确率可以达到1.0。取最佳验证模型结果,mAP@0.5可以达到0.995,mAP@0.5:0.95可以达到0.811。模型在IoU阈值为0.5时,精度可以达到0.995,识别能力较为出色,对于目标的检测能力较强。模型在更严格的IoU阈值上的平均精度为0.811,体现出模型在定位任务上也有较好的准确性。
利用YOLOv8 Nano检测模块可以很好地检测出瞳孔区域,并且对于瞳孔区域的边界定位也有较好的准确性,为下一步瞳孔区域信息的融合提供了精确的瞳孔定位基础。
3.2" 权重地图加权
在权重地图加权中,首先从瞳孔检测模型中获得瞳孔的检测识别结果,将瞳孔区域设置为1,背景区域设置为0,制作分辨瞳孔的mask;然后,对这个mask进行处理,生成包含两种权重系数的权重地图。其中,高权重系数用于指示瞳孔区域,低权重系数用于指示背景区域。
在实际实验中,通过对不同像素位置的权重进行精细调整,本文采用了三种权重对比:背景区域权重为0.3,瞳孔区域权重为1;背景区域权重为0.4,瞳孔区域权重为1;背景区域权重为0.5,瞳孔区域权重为1。
如图5所示,为三种权重对比在原图像上的实际效果图。
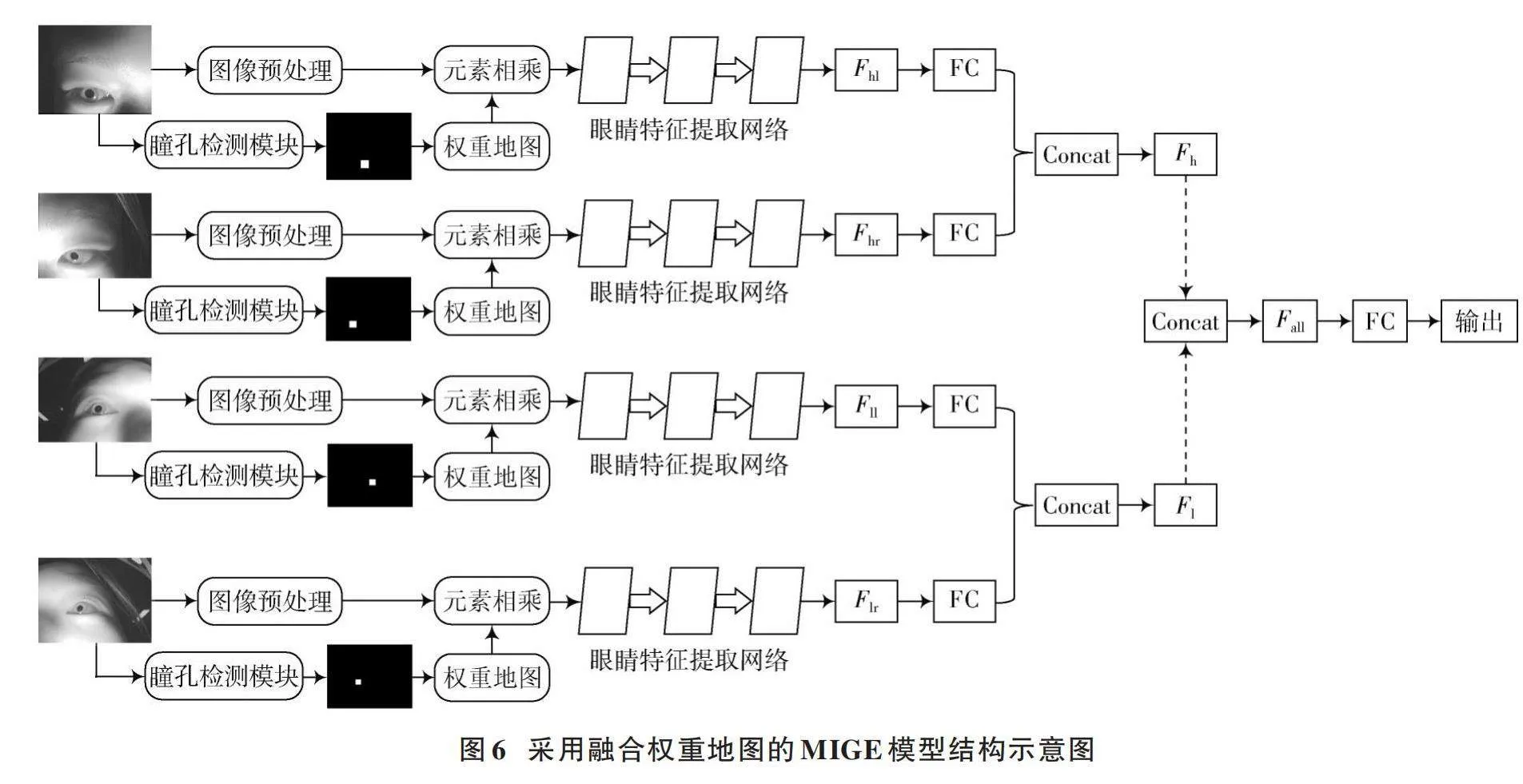
如图6所示,将生成的权重地图的权重分布与眼睛图像进行元素相乘,得到带有区域权重的眼睛图像。这样做可以抑制图像的非瞳孔区域,从而突出眼睛图像区域的分布特征。在这个过程中,瞳孔区域的像素保持不变,以便模型更加关注目标区域。而背景区域的像素则没有被mask直接遮挡,而是乘以一个较低的权重系数,以便在保留图像的整体结构和信息的同时,减弱背景的影响。之后将得到的特征信息输入眼睛特征提取网络,进一步融合多观测角度眼睛特征,最后输出得到预测注视坐标。
3.3" 模型对比
如图7所示,实验分为三组采用了三种权重对比。每组的批量大小和学习率设置相同,训练与验证样本比均设置为4∶1。将三种权重地图与眼睛图像进行元素相乘,得到带有瞳孔区域权重的眼睛图像。
对实验结果进行分析,比较接收三种权重地图的结果差异。三种权重设置的模型的训练曲线基本保持相同,训练曲线较为平缓。背景区域权重设置为0.3的模型的训练损失最低达到6.651 4像素;背景区域权重设置为0.5的模型的训练损失最低可以达到6.301 8像素;背景区域权重设置为0.4的模型的训练损失最低,最低可以达到5.428 7像素。
通过图7b)可以看到:背景区域权重设置为0.3和0.5的模型的验证曲线在前期训练阶段波动较为明显;背景区域权重设置为0.4的模型的验证曲线一直保持在较为平缓的状态。背景区域权重设置为0.3的模型的验证损失最小为8.178 4像素;背景区域权重设置为0.5的模型的验证损失最小为8.480 9像素;背景区域权重设置为0.4的模型的验证损失最小为7.448 9像素,与训练损失的差距最小。通过对比发现,将背景区域权重设置为0.4,瞳孔区域权重设置为1时,模型可以学习到结合瞳孔区域的有效特征,同时对于背景区域的有效特征信息也可以做到很好的捕捉,不会过度抑制背景区域的有效特征,此时模型的效果最好。
4" 结" 语
本文研究了VR环境下的注视估计技术,提出了一种结合多观测角度眼睛图像信息的注视估计方法,构建了MAG数据集和MAP数据集,用于提供模拟VR环境下的多观测角度眼睛图像数据。本文进一步开发了多分支模型MAGE来提取不同角度的眼睛特征,模型欧氏距离误差可以达到7.68像素,当模型部署在GeForce RTX 3060 GPU上时,其推理性能达到了34.38 f/s。与单观测角度注视估计相比,多观测角度注视估计可以捕获更多的有效信息。
本文结合瞳孔位置信息,提出了MIGE模型,使用YOLOv8 Nano算法在MAP数据集上训练封装一个瞳孔检测模块。
采用瞳孔检测模块来制作包含瞳孔区域信息的mask,通过权重地图融合策略,将融合信息输入MIGE模型进行训练,模型的预测效果进一步提升,在验证集上的欧氏距离误差从7.68像素降低到7.45像素。
注:本文通讯作者为房丰洲。
参考文献
[1] JABBIREDDY S, SUN X, MENG X, et al. Foveated rendering: Motivation, taxonomy, and research directions [EB/OL]. [2022⁃05⁃09]. https://arxiv.org/abs/2205.04529v1.
[2] AHARONI M M H, LUBETZKY A V, WANG Z, et al. A virtual reality four⁃square step test for quantifying dynamic balance performance in people with persistent postural perceptual dizziness [C]// 2019 International Conference on Virtual Rehabilitation (ICVR). New York: IEEE, 2019: 1⁃6.
[3] CHEN D L, GIORDANO M, BENKO H, et al. GazeRayCursor: Facilitating virtual reality target selection by blending gaze and controller raycasting [C]// Proceedings of the 29th ACM Symposium on Virtual Reality Software and Technology. New York: ACM, 2023: 1⁃11.
[4] GIUNCHI D, BOVO R, BHATIA N, et al. Fovea prediction model in VR [C]// 2024 IEEE Conference on Virtual Reality and 3D User Interface Abstracts and Workshops. New York: IEEE, 2024: 867⁃868.
[5] SATRIAWAN A, HERMAWAN A A, LUCKYARNO Y F, et al. Predicting future eye gaze using inertial sensors [J]. IEEE access, 2023, 11: 67482⁃67497.
[6] FANG F Z. On the three paradigms of manufacturing advancement [J]. Nanomanufacturing and metrology, 2023, 6(1): 35.
[7] MA Q Y, YU H Y. Artificial intelligence⁃enabled mode⁃locked fiber laser: A review [J]. Nanomanufacturing and metrology, 2023, 6(1): 36.
[8] LEE K F, CHEN Y L, YU C W, et al. Gaze tracking and point estimation using low⁃cost head⁃mounted devices [J]. Sensors, 2020, 20(7): 1917.
[9] ILLAHI G K, SIEKKINEN M, KÄMÄRÄINEN T, et al. Real⁃time gaze prediction in virtual reality [C]// Proceedings of the 14th International Workshop on Immersive Mixed and Virtual Environment Systems. New York: ACM, 2022: 12⁃18.
[10] MA N, ZHANG X, ZHENG H T, et al. ShuffleNet V2: Practical guidelines for efficient CNN architecture design [C]// Proceedings of the European Conference on Computer Vision (ECCV). Heidelberg: Springer, 2018: 122⁃138.
[11] REDDI S J, KALE S, KUMAR S. On the convergence of adam and beyond [EB/OL]. [2019⁃04⁃26]. http://arxiv.org/abs/1904.09237.
[12] CAZENAVE T, SENTUC J, VIDEAU M. Cosine annealing, mixnet and swish activation for computer Go [C]// 17th International Conference on Advances in Computer Games. Heidelberg: Springer, 2021: 53⁃60.
[13] KRAFKA K, KHOSLA A, KELLNHOFER P, et al. Eye tracking for everyone [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 2176⁃2184.
[14] HUSSAIN M. YOLO⁃v1 to YOLO⁃v8, the rise of YOLO and its complementary nature toward digital manufacturing and industrial defect detection [J]. Machines, 2023, 11(7): 677.
作者简介:牛" 锐(1999—),男,河南安阳人,在读硕士研究生,研究方向为注视估计、图像处理。
房丰洲(1963—),男,博士研究生,博士生导师,研究方向为超精密制造、微纳制造、光学设计制造与检测。
任仲贺(1993—),男,山东济宁人,在读博士研究生,研究方向为视线追踪、机器视觉。
侯高峰(1994—),男,河北保定人,在读博士研究生,研究方向为医学图像处理、深度学习。
李子豪(1998—),男,河北沧州人,在读博士研究生,研究方向为工业领域的目标识别和机器视觉。
猜你喜欢
科技资讯(2017年11期)2017-06-09 18:28:13
电子技术与软件工程(2017年5期)2017-04-23 23:37:37
现代电子技术(2017年7期)2017-04-14 19:20:42
商周刊(2017年24期)2017-02-02 01:42:55
计算机应用(2016年12期)2017-01-13 20:26:21
海外星云(2016年7期)2016-12-01 04:18:00
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
电脑知识与技术(2016年10期)2016-06-16 21:27:26
教育教学论坛(2016年12期)2016-03-30 22:45:35
