
MCMC 算法在数值模拟中的应用
2024-11-21 00:00:00党红陈艳娇李建丽
统计与管理 2024年10期
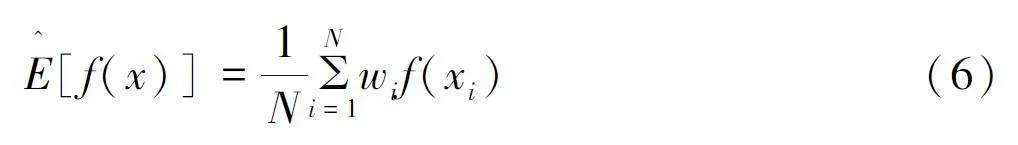
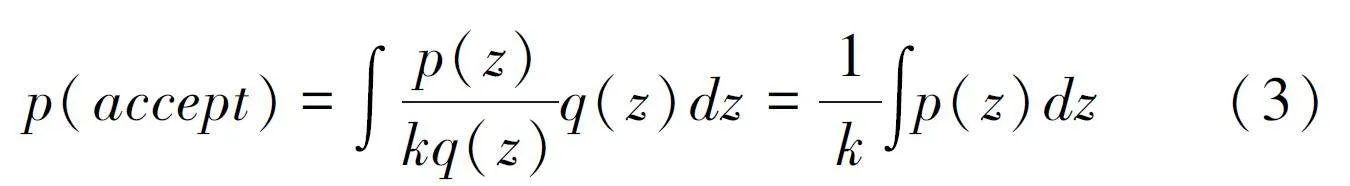
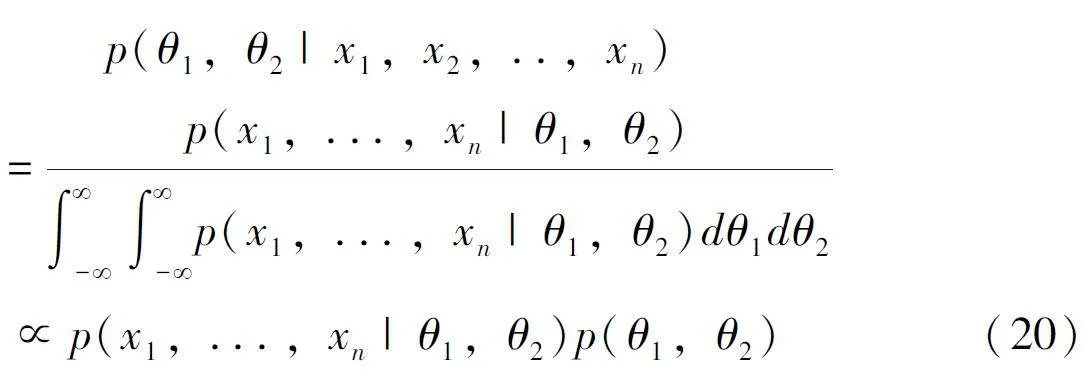
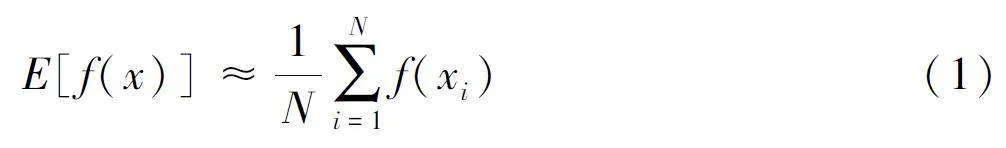




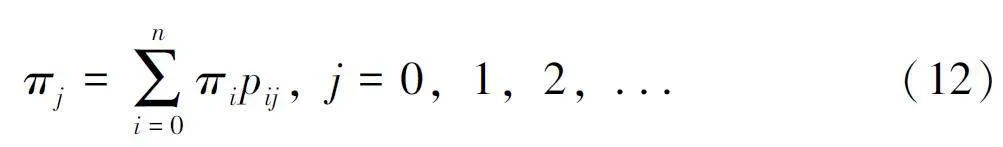
摘 要: MCMC 算法是一种基于随机采样的统计计算方法, 通过构建马尔可夫链, 从而实现对复杂系统的抽样和模拟。文章基于蒙特卡洛马尔可夫链的相关原理, 重点分析蒙特卡洛马尔可夫链在数值模拟中的应用。首先, 介绍了MCMC 算法及相关算法的原理, 包括蒙特卡洛方法的原理和三种常用的采样方法—直接采样、接受拒绝采样和重要性采样、马尔可夫链的原理和平稳状态、MCMC 算法的原理及两种经典的采样算法—Metropolis Hastings 算法和Gibbs 采样; 其次, 着重研究MCMC算法的应用, 包括蒙特卡洛方法在拟合参数、求解不规则面积以及接受拒绝采样的应用, 马尔可夫链在租车还车问题中的应用以及使用MCMC 算法估计回归系数的应用; 最后, 文章指出MCMC 算法的改进方向, 促进MCMC 算法更广泛的应用。
关键词: 数值模拟; 蒙特卡洛方法; 马尔可夫链; MCMC 算法
基金项目: 山西省高等学校教学改革创新项目“转型发展背景下地方高校理工科专业《概率论与数理统计》教学改革与实践” (J20221082); 长治学院教学改革创新项目“新工科背景下《概率论与数理统计》课程的实践教学研究” (JC202310)
中图分类号: O212 文献标识码: A
文章编号: 1674-537X (2024) 10. 0004-10
一、引言
随信息时代的发展, 数值模拟技术在越来越多的领域被广泛应用, 然而, 随着问题的复杂度和数据量的增加, 传统的数值模拟方法往往面临着计算效率低下、模型参数估计困难等挑战。
作为基于随机抽样的统计计算方法, MCMC 算法可以有效的解决上述问题, 被广泛应用于从复杂概率分布中抽样。在数值模拟的过程中, MCMC 不仅可以为数值模拟提供抽样方法, 还能帮助深入理解复杂模型, 并进行模型参数的优化、评估不确定性、进行贝叶斯推断等。能够有效克服传统数值模拟方法的局限性, 帮助解决复杂问题。
随着国内外的学者们的探索研究, MCMC 算法在数值模拟中的应用方面出现了更多研究成果, 涉及金融、地震预测、贝叶斯统计、机器学习等领域。在我国, 郭翠将MCMC 算法应用于利率期限结构模型, 确定连续时间资产定价模型中的后验分布, 为金融方面提供了重要参考[1] ; 赵晨等人利用MCMC 算法对地震弹性抗阻反演方法进行优化,结合地质特征, 对地下储存层参数进行预测, 为油气勘探提供了参数支撑[2] 。在国外, Andrew Gelman等人在贝叶斯统计建模中广泛应用MCMC 算法, 提出了一系列基于MCMC 的贝叶斯建模方法, 为贝叶斯统计的发展做出了重要贡献[3] ; Radford Neal 在机器学习领域利用MCMC 算法进行模型训练和推断, 提出了一种基于MCMC 的变分推断方法, 能够高效地处理复杂的概率模型[4] ; Christian Robert 等人提出了一种基于MCMC 的贝叶斯模型比较方法,能够比较复杂模型之间的相对优劣, 为统计学中的模型选择问题提供了一种有效的解决方案[5] 。这些研究为MCMC 算法在数值模拟中的应用提供了丰富的理论基础和实践经验, 为其在实际问题中的应用奠定了坚实的基础。
通过深入研究MCMC 算法在数值模拟中的应用, 不仅可以为理论研究提供新的思路和方法, 还可以为很多领域提供重要的参考和指导。因此, 深入探讨MCMC 算法的原理和应用现状具有重要的理论和实践意义, 对推动相关领域的发展和应用具有重要的促进作用。
二、MCMC 算法及相关原理
MCMC 算法由蒙特卡罗方法和马尔可夫链两个MC 组成。因此, 要介绍MCMC 的原理, 需先引入蒙特卡罗方法和马尔可夫链的相关原理, 为深入理解MCMC 做理论基础, 后介绍MCMC 算法的原理。
( 一) 蒙特卡洛方法
“曼哈顿计划” 时期, 为了探究中子在原子弹内扩散和增值问题。科学家们构建了高维玻尔兹曼方程, 并将解决高维玻尔兹曼方程的问题转化为相等形式的随机问题, 并通过计算机模拟成功求得解, 这便是最初的蒙特卡洛方法[6] 。这种方法很像赌场里扔骰子的过程, 因此梅特罗波利斯提议用赌城的Monte Carlo 作为代号, 这就诞生了蒙特卡罗方法[7] 。
蒙特卡洛方法的中心思想是通过从合适的分布上进行抽样, 生成样本来模拟问题的不确定性或者随机性。再基于生成的样本, 使用统计方法对问题进行推断, 估计目标函数的期望值。从密度函数p(·) 中构造样本{xt , t = 1, 2, , N} 估计E[f(xi )] :
即用样本估计 f(x) 的平均值。 当样本 {xi} 之间相互独立, 由格里文科定理, 随样本量增加, 经验分布函数收敛于真实的总体分布函数。样本均值在样本量趋于无穷时依分布收敛于总体期望是大数定理的核心。两个理论相结合可得, 采集样本的数量增加, 估计值就越趋于真实值, 对分布的模拟就更加准确[8] 。
在深厚的理论基础支撑下, 面临着一个核心挑战: 如何对目标分布进行采样, 以显著提升拟合效果。为此, 就要引入蒙特卡洛方法。蒙特卡洛采样技术通常包括三种主要策略: 直接采样、接受-拒绝采样以及重要性采样。以下给出了三个抽样方法的原理:
1. 接采样方法
假如p(z) 是要采样的分布, 若可以得到p(z)的概率密度(probability density function, PDF), 对概率密度函数求积分可以得到分布函数的累积分布函数(cumulative distribution function, CDF), 假设u(i) ~ U(0, 1) , 即u 是(0, 1) 的均匀分布, 则取得样本x(i)
x(i) = CDF-1(u(i) ) (2)
对PDF 求积分后, 得到分布函数CDF , 则可求出u(i) 对应的样本x(i) , 同理可以抽样出N 个样本点x(1) x(2) , …, x(N) , 但是, 现实中很难得到问题的概率密度函数, 也就无法求出累计分布函数。因此, 这种方法只能适用于一些非常有限的分布, 很多实际问题很难通过这种方法去抽样得到样本点。
2. 接受拒绝采样方法
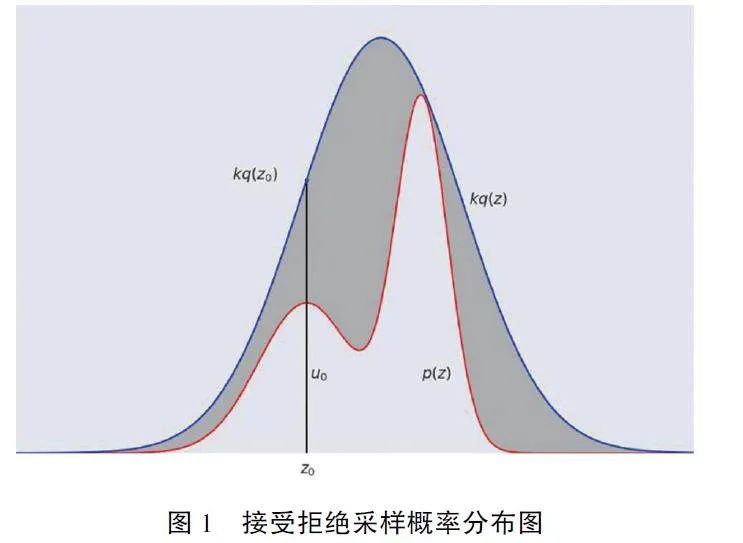
接受拒绝采样的核心思想, 是对较复杂的概率分布p(z) , 引入简单的提议分布q(z) 和一个常数k , 使得对于任意的Zi , 有kq(zi ) ⩾ p(zi ) , 然后对q(z) 进行采样获得样本, 具体的采样方法步骤如下:
第一步, 从q(z) 取出一个样本, 记为zi ; 第二步, 按照提议分布q(z) 随机抽样得到样本zi ,计算接收率α =p(zi )/kq(zi ) , 再按照均匀分布在(0, 1)范围内抽样得到样本ui ; 第三步, 如果ui ≤(p(zi )/kq(zi ) ),则zi 作为抽样结果; 否则, 拒绝zi 并返回第二步,直到获得N 个样本, 则采样结束。
每次采样的接受概率计算如下:
则为了防止舍弃过多样本降低采样效率, k 的选取应该在满足ui ≤(p(zi )/kq(zi ) )的基础上尽可能小。
拒绝采样的优点是容易实现, 缺点是采样效率可能不高。如果p(zi ) 的涵盖体积与kq(zi ) 的涵盖体积比值低, 就会增大拒绝的比例, 降低抽样效率。尤其是在高维空间抽样, 即使p(zi ) 与kq(zi )很接近, 两者涵盖体积的差异也可能很大, 出现维数灾难, 因此, 科学家们想出了其他采样方法。
3. 重要性采样方法
累积分布函数不可的情况可由接受拒绝采样解决, 但对于无法找到适当提议分布或者是在高维中采样的情况, 也无法使用接受拒绝采样法。由此,出现了重要性采样法, 步骤如下:
假设随机变量的概率密度函数为p(x) , 要估计目标分布下某个函数f(x) 的期望, 但是从目标分布中直接采样可能很困难, 即可以选择一个容易采样的提议分布q(x) , 然后利用重要性权重来修正从提议分布中采样得到的样本, 以更好地逼近目标分布。
对于一个函数f(x) , 其在目标分布下的期望值E[f(x)] 可以表示为:
Ep(x) [f(x)] = ∫f(x)p(x)dx (4)
再引入较为简单的提议分布q(x) , 对上式进行变换
记重要性权重wi =p(xi )/q(xi ) , 其中, xi 是从提议分布 q(x) 中采样得到的样本。 估计 E [f(x) ] 的公式为:
重要性采样解决了概率密度复杂的情况, 还能经常被应用于一些需要减小方差的情况, 加权不仅减小了拒绝接受采样中提议分布和概率分布相差过大而带来的误差, 还能有效减小方差[9] 。
蒙特卡洛方法要求样本{xi} 相互独立, 而由于无法判断p(·) 是否标准化, 因而从p(·) 中构造独立样本不太可行。若要强制要求相互独立, 可以从任意分布过程中产生样本{xt} , 其中一种方法是将含有p(·) 的马尔可夫链看作一个固定分布, 这就是上文所阐述的马尔可夫链蒙特卡洛算法。
(二) 马尔可夫链
马尔可夫链(Markov Chain) 的发现可以追溯到19 世纪末和20 世纪初, 以俄国数学家安德烈·马尔可夫(Andrey Markov) 的名字命名, 他是这一概念的创始人和最早的研究者之一。
1880 年, “马尔可夫过程” 的概念首次被马尔可夫提出。1906 年, 马尔可夫发表了一篇名为《关于离散值连续变化的正定连续函数的问题》(Problems on the Theory of Probability) 的论文, 其中他详细讨论了一种离散时间的随机过程, 这就是现在所称的马尔可夫链。随着后续数学家的不断探索, 马尔可夫链理论被不断完善发展[8] 。现如今,马尔可夫链在许多领域, 如概率论、统计学、物理学、计算机科学等方面都有广泛应用。为深入理解马尔可夫链, 需要如下前提:
1. 马尔可夫性质
给定当前状态, 未来状态的概率分布仅依赖于当前状态, 与其他状态无关。是马尔可夫链的关键特征, 条件概率表示为,
P(Xn+1 = j ∣X0, X1, …, Xn)= P(Xn+1 = j ∣Xn)(7)
其中, Xn 表示第n 个状态。
2. 状态空间
x(n) = (x1 (n), x2 (n), … , xk (n)) (8)
其中, 概率向量的每个元素都是概率, 元素和为1, 系统的可能状态数有k 个, 向量中各个元素分别表示第n 次观测时第i 个状态的概率, x0 (n) 被称为初始状态。
3. 随机过程
用T 表示一个无限实数集, 把依赖于参数t ∈ T的一族随机变量{Xt , t ∈ T} 称为随机过程。
4. 转移概率矩阵
对于马尔可夫链中任意两个状态i 和j , pij(i,j = 1, 2, … , k) 表示从状态i 到状态j 的概率, P矩阵元素非负, 且每一行元素之和都为1。
5. 马尔可夫链
假设序列状态是… Xt -2, Xt -1, Xt , Xt +1… ,那么依据马尔可夫链性质, 在Xt +1 时刻的状态的条件概率只依赖于前一刻的状态Xt , 即:
P(Xt +1 | … Xt -2, Xt -1, Xt ) = P(Xt +1 | Xt )(10)
求出系统中任两个状态间的转换概率, 即可确定此马尔可夫链模型。
6. 遍历性
设有一个状态空间为E 的马尔可夫链{Xn , n =0, 1, 2, … } , 若对于任意的i, j ∈ E , 有极限
存在, 则代表马尔可夫链具有遍历性, 遍历性代表, 在有限步骤内, 可以从任何一个状态转移到另一个状态, 则认为这个马尔可夫链是遍历的。
7. 平稳分布
设齐次马尔可夫链{Xn , n = 0, 1, 2, … } 的状态空间为{E = 0, 1, 2,… } , P = (pij ) 代表其转移概率矩阵, 若存在一个概率分布{πj , j ⩾ 0}满足
则称{πj , j ⩾0} 为该马尔可夫链的平稳分布。马尔可夫链的平稳分布{πj , j ⩾ 0} 又可以表示为π ={π0, π1, π2,…} , 则有π = πP , 又由于平稳分布{πj , j ⩾0} 是一个概率分布, 则有Σ∞i = 0πj = 1。
马尔可夫链作为一种随机过程, 显著特征是具有马尔可夫性质, 并存在于离散的指数集和状态空间之中。当马尔可夫链的指数集变为连续时, 它通常被称作马尔可夫过程, 有时也被视作马尔可夫链的一个特定子集。当一个随机过程符合马尔可夫性时, 将其归类为马尔可夫过程[10] 。
此外, 不可约性、常返性、周期性和遍历性也可能是马尔可夫链具有的性质。不可约和正常返是严格平稳的马尔可夫链性质, 它只有一个平稳分布[8] 。遍历马尔可夫链的极限分布收敛于它的平稳分布。马尔可夫链达到收敛后, 它的状态分布保持在某一特定的分布上不随时间变化, 即满足马尔可夫链的稳定性。这种稳定性表明链的长期行为是可预测的, 可以通过链的平稳分布得到。
(三) MCMC 算法
马尔可夫链蒙特卡罗法(Markov Chain MonteCarlo, MCMC), 是蒙特卡罗方法和马尔可夫链的结合。在蒙特卡洛模拟的框架下, 从后验分布中抽取样本时, 若这些样本满足独立性, 依据大数定律, 样本均值会逐渐逼近其期望值。若样本之间不独立性, 为了进行有效的抽样, 需要采用马尔可夫链的方法, 即MCMC 方法。
在已知的分布过于复杂导致无法直接生成样本的情况下, 可根据它的条件分布生成样本。这样生成的随机样本不相互独立, 生成的样本与前一个样本相关, 而由于遍历性条件下, 这些样本可以看作独立样本, 这种基于马尔可夫链基本性质的方法就是马尔可夫链蒙特卡洛算法[7] 。
MCMC 算法的核心原理是利用马尔可夫链的收敛性质, 通过定义合适的转移核函数和接受—拒绝策略, 使得从该链中抽取的样本可以近似地表示目标概率分布, 基本步骤如下:
首先, 需要选择初始状态; 第二步, 确定状态转移; 第三步, 判断接受或者拒绝新状态, 通常是通过比较新状态的概率与当前状态的概率来完成,如果新状态的概率更高, 则接受该状态, 否则, 根据一定的概率规则, 可能会拒绝该状态。第四步,重复进行状态转移和接受或拒绝的过程, 直到满足停止条件为止。第五步, 在MCMC 算法收敛之后,根据得到的马尔可夫链, 可以进行采样。采样过程中, 通常会丢弃一定数量的初始状态, 以保证采样结果的有效性。
在第五步中, 当模拟的马氏链收敛于平稳分布时, 才可以进行后续步骤。判断MCMC 算法收敛性的常用策略主要包括两种。首先, 可以通过观察基于未知参数模拟得到的马尔可夫链的迭代图来进行初步判断。若该链能迅速摆脱初始值的影响, 并在某个特定值附近保持随机波动, 无明显的趋势或周期性变化, 则可视为算法收敛。其次, 另一种有效的方法是应用Gelman-Rubin 方差比检验。此方法涉及构建多条基于不同初始值的平行链, 并计算它们的后验方差和链内方差。若两者值接近或相等,那么可以认为MCMC 算法具有良好的收敛性[11] 。
MCMC 方法将蒙特卡罗方法与马尔可夫链相结合, 有效的解决了复杂分布难以获取样本, 在高维中维数灾难的问题。下面介绍两种MCMC 算法的经典算法, Metropolis-Hasting 算法(MH 算法) 以及Gibbs Sampling (吉布斯采样)。
1. Metropolis Hastings 算法
为了解Metropolis Hastings 算法, 需要先详细阐述Metropolis 算法。对于一个十分复杂的过程, 其中变量分布为π , 并潜在地对应着一个复杂的转移概率矩阵P , 希望通过一个对称的转移矩阵Q , 从简单分布θ 中采样, 以一定概率α 接受采得样本作为对(π, P) 过程的细致平稳分布近似, 用于统计分析。首先, 给定一个对称的提议转移概率矩阵Q , 但该矩阵一般不满足细致平稳条件, 即
πi × Pi, j ≠ πj × Pj, i (13)
为了构造细致平稳条件, 对上式两端同时乘以接受概率α , 得到:
πi × Qi, j × αi, j = πj × Qj, i × αj, i (14)
使得接受概率α 与提议矩阵Q 的组合满足如下概率转移矩阵:
P ^i, j = Qi, j × αi, j
P ^j, i = Qj, i × αj, i(15)
这样一来, 所构造的转移概率P ^ 满足细致平稳条件:
πi ×P ^i, j = πj ×P ^j, i (16)
在Metropolis 算法中, 假设在第t - 1 步得到状态样本x(t -1) = si , 接下来便从θ(s | si ) 中新采集一个样本s ^ 。
以概率α = min{1, π(s ^ ) / π(si )} 接受x(t) =s ^ ,否则x(t) = x(t -1) = si 。该过程对应的转移概率满足:
P ^i, j = Qi, j × αi, j (17)
那么
πi ×P ^i, j = πi × Qi , j × αi , j
= πi × min{1, πj / πi } × Qi , j
= min{πi × Qi , j , πj × Qj, i }
= πj × min{1, πi / πj } × Qj, i
= πj ×P ^j, i (18)
因此, 如上方式构造所得状态转移矩阵P ^ 满足细致平稳条件, 这样获得的采样分布就是π 。
而Metropolis 算法中的接受概率α 的值可能会很小, 延长算法的迭代次数, 影响效率。为了解决这一问题, Metropolis Hastings 采样算法诞生。具体来说, MH 算法将式(20) 等式两边的接受概率放大。将其中的一个接受概率设置为1, 这样就能保证每次迭代过程中接收新状态的概率越大, 加速算法收敛。
αi, j = min{1, πj Qi, j/πi Qj, i } (19)
从上述的抽样方法可以得到, Metropolis -Hasting 抽样基于现有的样本, 即抽样需要基于的条件概率。这样取得的样本不独立, 这就是MCMC 方法与蒙特卡洛方法抽样的一个很大不同[12] 。
2. Gibbs 采样
Metropolis-Hasting 算法可以很好的解决蒙特卡罗方法需要的任意概率分布的样本集的问题, 但是仍有两个缺点: 一个是需要计算接受率, 计算量大, 效率低。第二个是对于高维数据, 取得特征的联合分布比较困难, 吉布斯抽样(Gibbs Sampling)的诞生就是M-H 采样的改进。
假设已知随机变量X 服从具有参数Θ = (θ1,θ2) 的分布X ~ p(X | Θ) , Θ 的先验分布为p(θ1,θ2) 。设{x1, x2, … , xn } 是从该分布抽取出的一组样本, 可以通过贝叶斯定理计算得到后验分布:
此后验分布就是需要进行抽样的目标分布。有两种抽样方法, 一种是在多维角度直接对Θ 进行抽样, 一种是对Θ 的每一个维度θi 逐一地进行一维的抽样。第一种是Metropolis-Hasting 算法的多维推广, 第二种方案就是吉布斯抽样。
吉布斯采样通过全概率分布的目标分布对每一个维度的θi 进行抽样。θ1, θ2 的满概率分布形式如下:
p(θ1 | θ2. x1, … , xn ) =p(θ1, θ2 | x1, … , xn )/pθ2(θ2)(21)
其中, p(θ1, θ2 | x1, … , xn ) 为Θ 的联合后验概率分布, pθ2(θ2) 为后验分布下关于θ2 的边缘分布。由于在这个条件分布中假设θ2 = a 已知, 因此p(θ2) 实际为一个常数, 可以把上式转变为:
p(θ1 | θ2 = a, x1, … , xn )∝ p(x1, …, xn | θ1, θ2)p(θ1, θ2)∝ p(x1, … , xn | θ1, θ2 = a)p(θ1, θ2 = a)(22)
在θ2 = a 已知的前提下, 使用M-H 算法, 甚至更简单的算法, 就可以完成对θ1, θ2 的抽样。至此, 还需要解决对不已知θ2 的抽样。首先, 得到第一个样本Θ1 = (θ11, θ12) , 再利用θi2, 从p(θ1 | θ2 =θi2, x1, … , xn ) 中抽取θi +11 。然后, 利用θi +11 , 从p(θ2 | θ1 = θi +11 , x1, … , xn ) 中抽取θi +12 。构成Θi +1 , 最后, 重复上述步骤, 直到抽取的样本数量满足需求。
可以看到, 抽样的过程中, 每一个样本Θi 总会受到前一个样本的影响, 因此通过吉布斯抽样得到的序列{Θ1, … , Θn } 是一条马尔可夫链。在此基础上, 可以类似M-H 算法, 利用马尔卡夫链相关的性质能够证明, 该马尔可夫链的平稳分布是目标联合概率分布p(θ1, θ2) 。
Gibbs 采样是基于M-H 采样的发展, 在高维更具有优势, 目前应用更为广泛。此外, Gibbs 采样要求数据至少是二维的, 一维概率分布采样仍然需要使用M-H 采样。Gibbs 采样可以获取概率分布的样本集, 蒙特卡罗方法可以用样本集模拟, 二者结合, 突出了MCMC 算法在大数据时代, 尤其在处理高维数据模拟求和任务时, 独特的优势和作用。
三、MCMC 算法的应用
(一) 蒙特卡洛方法的应用
蒙特卡洛方法被广泛应用于估计、优化、积分等问题, 在统计学、物理学、金融学等领域广泛应用, 尤其在高维、复杂问题上表现出色。以下介绍几种蒙特卡罗方法在数值模拟中的经典应用。
1. 蒙特卡洛方法拟合正态分布的参数
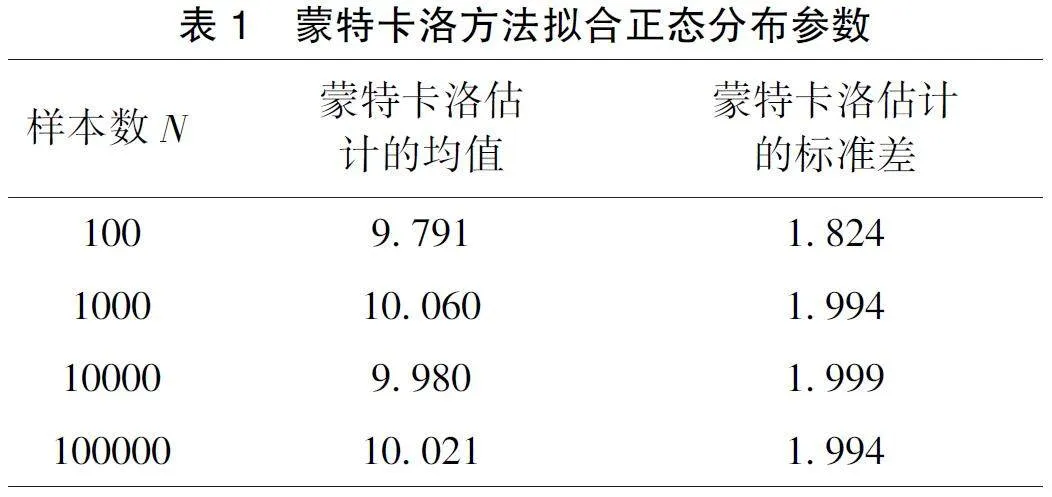
利用Python 软件分别生成包含100 个, 1000,10000 个样本的正态分布数据, 均值为10, 标准差为2。后定义了一个函数, 用于执行蒙特卡洛拟合。这个函数接受样本数据和模拟次数作为参数, 然后在样本数据中进行随机的有放回地抽样, 计算均值和标准差, 并返回估计的均值和标准差, 结果如表1:
可以看出, 随着样本数量的增加, 蒙特卡洛模拟对参数的拟合更准确。在实际应用中, 可以通过增加抽样次数和改变初始参数值来提高拟合的准确性。
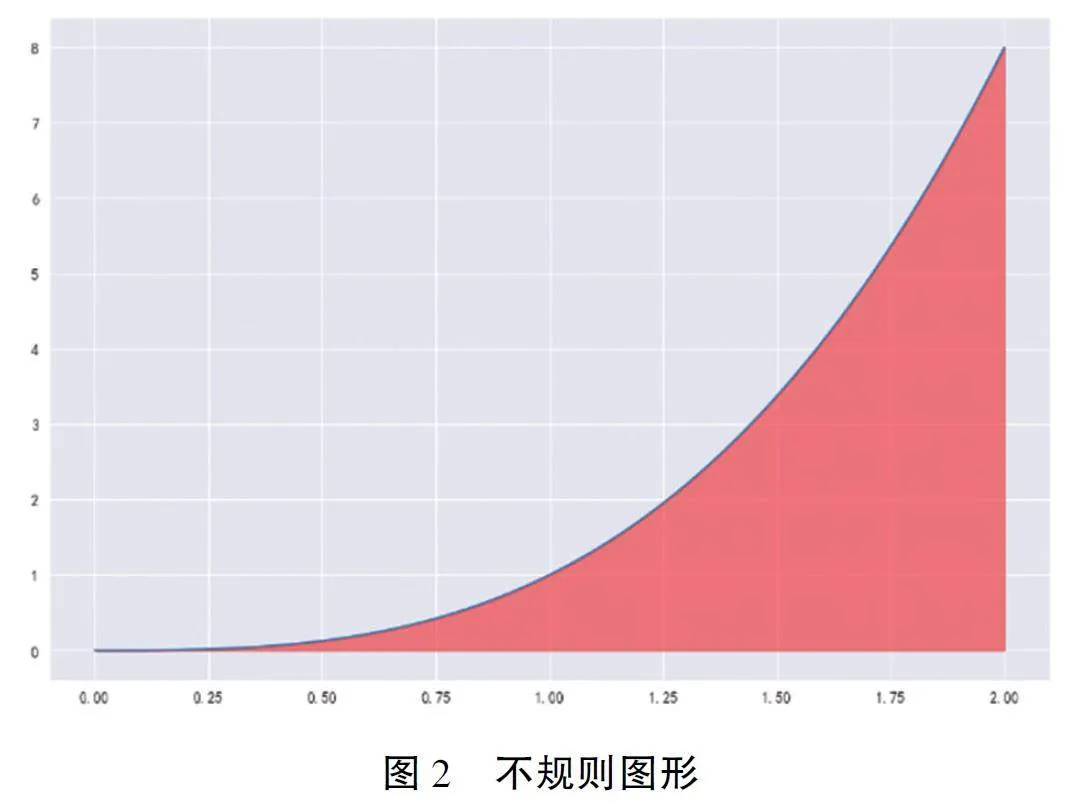
2. 蒙特卡洛方法求解不规则图形的面积
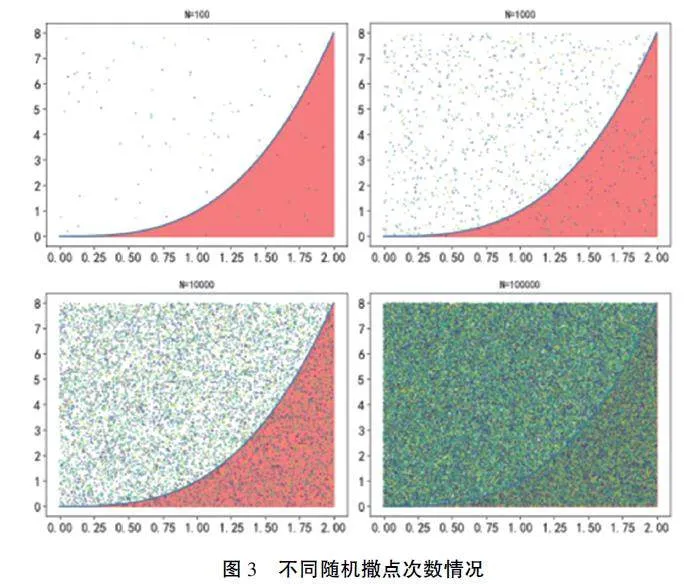
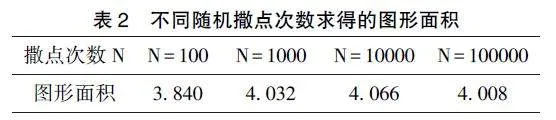
如图2, 若想对红色的面积进行计算, 需要在x∈[0, 2], y ∈[0, 8] 的区域均匀随机撒点, 如果点进如红色区域, 则计数为1, 否则为0, 最后只要将撒在红色区域的数量除以撒点的总数N 除以满足撒点总数再乘上x ∈ [0, 2], y ∈ [0, 8] 的面积,则可得到红色区域的面积。
以下分别进行100 次, 1000 次, 10000 次,100000 次的随机撒点, 得到模拟的结果以及根据撒点情况计算的红色面积如图3;
图3 显示: 随着撒点数量的增加, 区域内被击中部分的面积也不断增加, 可以得到更加准确的数字, 为了更精确的求得红色区域面积, 将N 次撒点计数为1 的累计和除以撒点的总数N 再乘上x ∈[0, 2], y ∈ [0, 8] 的面积, 则可得到红色区域的面积, 结果如表2:
需要注意, 随机拟合得出的面积是一个近似值, 且随着样本数量的增加, 近似值更接近真实值, 上述应用的采样要求均匀随机, 但并不是所有MC 采样都需要应用均匀采样, 如重要性采样,因此, 通过应用特定的非均匀采样策略, 可以显著提高算法的收敛速度。
3. 接受拒绝采样的应用
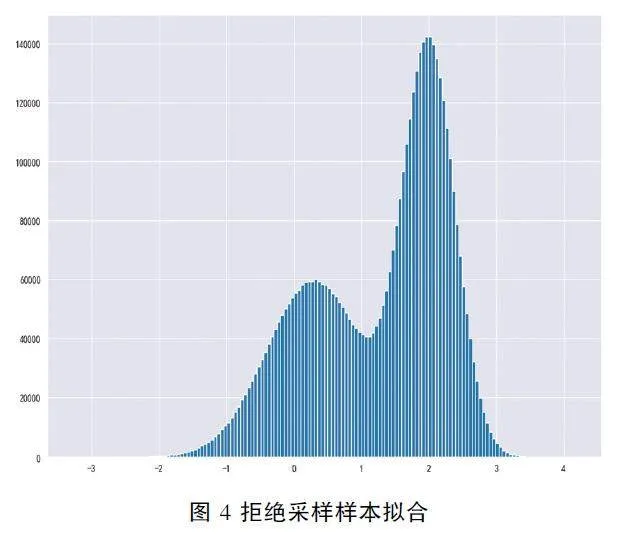
定义函数f1(x) = 0. 3exp( - (x - 0. 3)2) +0. 7exp( - (x - 2)2/0. 3 )/k , 生成从-4 到6 的横坐标范围, 步长为0. 01, 将横坐标范围x 和对应的概率密度函数f1(x) 绘制成图像设置为红色。
设置抽样数量10000000, 设置正态分布的标准差为1. 2, 均值为1. 4, 使用函数生成符合指定均值和标准差的正态分布随机样本z。根据生成的正态分布随机样本z, 使用概率密度函数计算对应的概率密度函数值qz 。设置k = 2. 5, 根据k 和qz 生成均匀分布的随机样本u , 根据生成的正态分布随机样本z , 使用定义的概率密度函数计算对应的真实概率密度函数值pz , 根据生成的随机样本u 和真实概率密度函数值pz , 选取满足条件pz ⩾ u 的样本, 得到抽样结果sample, 绘制直方图, 对直方图进行归一化处理, 使得面积为1, 结果如图4。
则采样拟合的分布与原分布相比基本一致, 且拟合效果随着样本数量增加越来越好, 以上是蒙特卡洛方法中接受拒绝采样在抽样中的应用。
(二) 马尔可夫链的应用
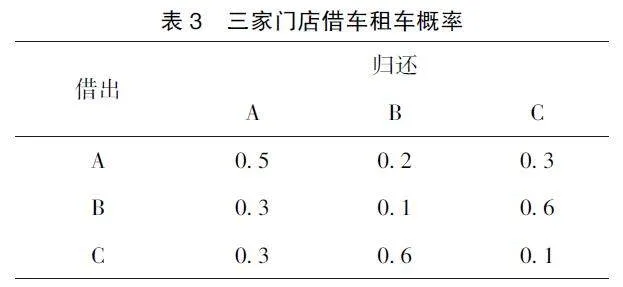
马尔可夫链在实践中有许多应用, 如: 马尔可夫链可用于文本生成, 通过学习文本中单词或字符之间的转移概率来生成新的文本, 还可以用来建模语音信号中的音素序列, 达到语音识别。在金融领域, 马尔可夫链可以用来模拟资产价格的随机演变过程, 被用于股票价格预测、风险管理和期权定价等。在生物信息学中, 马尔可夫链可以用来建模DNA、RNA 和蛋白质序列的序列变化和序列结构[14] 。在网络分析中, 马尔可夫链可以用来建模网络中节点之间的转移过程。此外, 马尔可夫链还可以用于预测天气和传染病病情。下面以一模型为例, 有A, B, C 有三家租车的门店, 租赁和归还可以选择任何一个门店, 从不同门店借出和归还的概率如表3:
由表3 的数据可以写出转移矩阵为
则可确定还车模型, 接下来用此模型进行预测, 已知一辆车位于B 门店, 三次借还以后, 计算这辆车最可能在哪个门店。
若初始状态向量为:
X(0) = (0, 1, 0) (24)
则
X(1) = X(0) P = (0. 300, 0. 100, 0. 600)
X(2) = X(1) P = (0. 360, 0. 430, 0. 210)
X(3) = X(2) P = (0. 372, 0. 241, 0. 387)
(25)
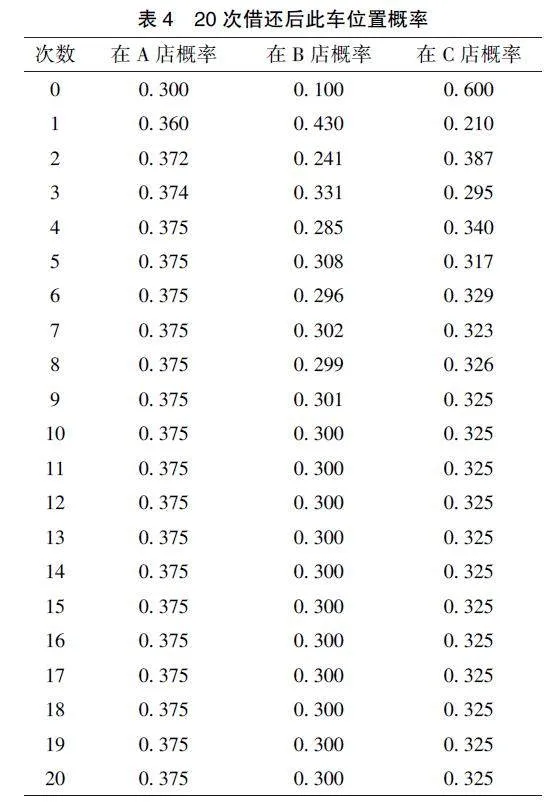
故三次借还后这辆车最可能在C 门店, 用Python 软件模拟, 借还1 次至20 次后, 此车停在三个门店的概率结果如表4 所示:
表4 显示: 当n 增大, 状态向量趋近于
X(n) = (0. 375, 0. 300, 0. 325) (26)
则多次归还后, 从A, B, C 三家门店归还的概率分别趋近于0."375、0. 3、0. 325, 达到平稳状态。
(三) MCMC 算法的应用
使用MCMC 算法进行数值模拟被广泛应用。在统计学习领域, MCMC 算法在广泛应用与贝叶斯统计推, 用于从后验分布中抽样。在数学领域,MCMC 算法可以用于计算高维积分, 特别是对于复杂的概率分布。在计算机领域, MCMC 算法用于对马尔可夫随机场(MRF-Markov Random Field , 简称MRF) 进行建模和推断[15] 。在生物信息学领域: MCMC 算法可以用来模拟蛋白质的折叠过程,从而找到最稳定的构象。在金融学领域, MCMC 算法对金融模型进行参数估计、风险评估等。在机器学习领域, MCMC 算法可以用于拟合深度学习模型的参数、进行变分推断等。
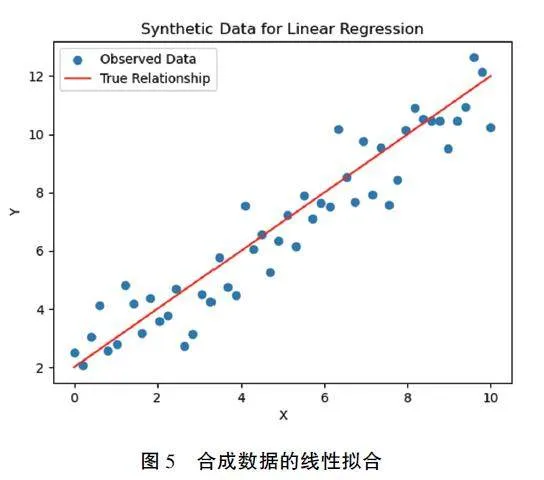
下面以线性回归模型为例, 用MCMC 算法来估计回归系数。先定义一个线性模型linear_ regression(x, beta), 其中x 是自变量, beta 是回归系数, 选择了一组真实的回归系数true_ beta = [2, 1], 为了生成观测数据, 在自变量x 的范围内生成了一组数据点, 并通过线性回归模型加上正态分布的噪声来生成因变量y_ observed。具体来说, 在0 到10之间生成了50 个等间隔的自变量数据点。然后,使用linear_ regression 函数和真实的回归系数true_ beta 来计算相应的因变量y_ true。接着, 生成了服从正态分布的噪声数据noise, 然后将其加到真实的因变量y_ true 上, 得到最终的观测数据y_ ob⁃served。将合成后的数据进行可视化, 并对散点进行拟合, 结果如图5 所示。
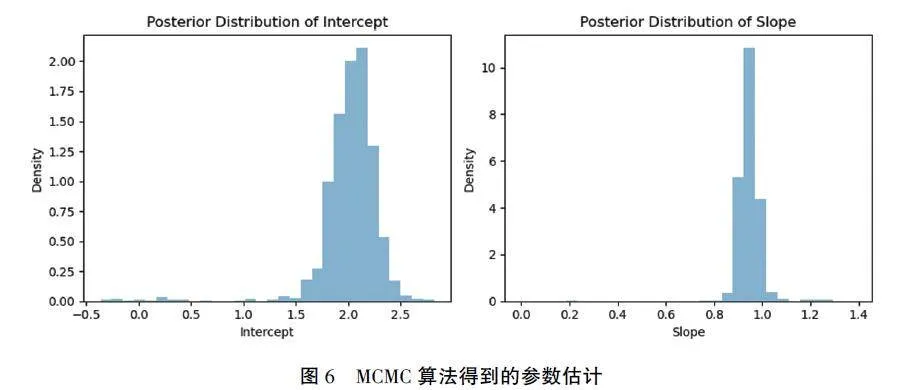
接下来, 使用MCMC 算法估计线性回归模型中的参数, 得到参数的后验分布样本之后, 可计算参数的后验均值、标准差等统计量, 也可以使用这些样本来进行后续的推断和预测。利用Python 软件进行数值模拟, 结果如图6 所示。
可得到截距和斜率的后验分布。这就是MCMC算法在数字领域的应用实例, 显示了MCMC 算法在解决各种复杂问题中的强大能力, 学习MCMC 算法在各个领域都有着重要的意义。
四、总结
使用MCMC 算法进行数值模拟中在各个领域都有强大的应用。通过构建马尔可夫链, MCMC 算法能够从复杂的概率分布中抽样, 解决了许多传统方法难以处理的问题。在过去几十年里, MCMC 算法已经被广泛应用于各个领域, 包括统计学、机器学习、贝叶斯推断、物理学、生物学等。其应用涵盖了参数估计、模型选择、数据合成、图像处理等多个方面, 为科学研究和工程应用提供了重要支持。
虽然MCMC 算法已经取得了巨大成功, 并在许多领域得到了广泛应用, 但仍然存在一些挑战和改进的空间。首先, 随着数据的增加, MCMC 算法和并行化方法需要被开发, 应对大规模数据带来的挑战。因此, 需要开发适用于大规模数据的, 以加速计算和提高效率。其次, 改进MCMC 算法的采样效率是当前研究的一个重要方向。通过引入新的采样策略、优化算法参数或并行计算等手段, 提高算法的收敛速度和采样效率, 尤其是在高维参数空间中的应用。再者, MCMC 算法在贝叶斯推断中扮演着重要角色, 但在复杂模型和大规模数据情况下, 后验推断可能变得困难。因此, 需要进一步研究高效的后验推断方法, 包括变分推断、近似推断等, 以应对复杂模型和大规模数据的挑战。最后, MCMC算法已经在多个学科领域得到了广泛应用, 但不同领域之间的交叉应用仍然有待深入探索。未来的研究可以关注跨学科合作, 将MCMC 算法与其他领域的方法结合, 为更广泛的应用场景提供解决方案。
参考文献:
[1]郭翠 MCMC 方法在利率期限结构模型中的应用[D]. 暨南大学,2012.
[2]赵晨,郭淑文,金凤鸣等. 基于优化MCMC 算法的地震弹性阻抗反演方法[J]."矿产与地质,2023,37(03):587-596.
[3]Gelman A , Carlin J B , Stern H S ,et al. Bayesian data analysis, third edition[ J] . Journal of the American Statistical Association, 2003, 45(2):21-100.
[4]Neal R M . Bayesian leaning for neural networks[J]. Mackay Neura/ Computation, 1996:46-152.
[5]Reviewer D P F . Monte Carlo Methods: Monte Carlo Methods in Statistical Physics[J]. Computing in Science & Engineering, 2000, 2(6):73-74.
[6]刘朝晖. 计算机诞生,推动人类文明进阶[J]. 新民周刊,2023,(05):36-37.
[7]周将. 基于蒙特卡洛模拟的防洪设施可靠性分析[J]."价值工程,2024,43(10):150-153.
[8]周艳斌 基于马尔可夫链蒙特卡洛法的蚂蚁游走模型[D]. 电子科技大学,2023
[9]邵豪,王伦文,朱然刚等 基于重要性采样的超图网络高效表示方法[J]. 软件学报,1-18.
[10]肖北芳. 基于MCMC 算法的贝叶斯分位数回归方法的实证应用[D]. 湖南师范大学,2015.
[11]杨新辉. 随机抽样的方差缩减以及MCMC 收敛诊断[D]. 北京交通大学,2018.
[12]张广智,赵晨,涂奇催,等. 基于量子退火Metropolis-Hastings 算法的叠前随机反演[J]. 石油地球物理勘探,2018,53(01):2-9.
[13]赵启钤. 基于吉布斯采样算法的虚拟样本生成技术研究[D]. 北京化工大学,2023.
[14]刘洪艳,刘良森. 生物化学教学案例的构建—人工智能预测蛋白质结构[J]. 化学教育(中英文),2024,45(02):92-97.
[15]李兮嘉. 基于马尔科夫链蒙特卡洛算法对条件生成对抗网络生成图片质量的改进[D]. 山东大学,2023.
猜你喜欢
成都信息工程大学学报(2019年4期)2019-11-04 00:56:02
阅读与作文(英语初中版)(2019年8期)2019-08-27 03:59:25
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
中学生数理化·高一版(2017年9期)2017-12-19 12:15:15
西安工程大学学报(2016年6期)2017-01-15 14:09:28
科技视界(2016年18期)2016-11-03 23:14:27
科技视界(2016年18期)2016-11-03 22:57:21
科技视界(2016年18期)2016-11-03 20:38:17
中国科技博览(2016年18期)2016-10-19 09:40:28
科技视界(2016年22期)2016-10-18 14:53:19
