
数字视频媒体内容的自动理解与分析
2024-11-12 00:00:00唐凯
无线互联科技 2024年19期


摘要:文章研究了基于L2正则化优化的深度卷积神经网络在数字视频媒体内容自动理解与分析中的应用。具体来说,文章分析了视频理解与分析问题,聚焦于DCNN的理论研究,引入了L2正则化方法来对方法进行优化,在实验部分使用YouTube-VOS数据集对方法进行了验证与比较,通过F1分数和交并比指标评估了优化方法相较于标准DCNN提升效果。实验结果表明,该方法在视频对象分割任务中取得了优异的效果,验证了L2正则化在深度学习模型优化中的有效性。
关键词:数字视频;视频分析;深度卷积神经网络;正则化
中图分类号:TP37 文献标志码:A
0 引言
近年来,随着数字视频媒体的迅猛发展和广泛应用,如何高效、准确地理解和分析视频内容成了计算机视觉和多媒体领域的研究热点[1-2]。视频媒体内容的自动理解与分析不仅在智能监控、视频检索、自动驾驶等实际应用中具有重要价值,而且在推动人工智能技术进步方面也具有深远的意义[3-4]。传统的视频理解与分析方法主要依赖于人工特征提取和浅层学习模型,这些方法在面对复杂多变的场景时往往表现出局限性,难以充分捕捉视频中的高层语义信息[5-6]。
近年来,深度卷积神经网络(Deep Convolutional Neural Networks, DCNN)的出现为视频内容的自动理解与分析提供了新的思路[7-8]。DCNN通过多层非线性变换能够自动学习到数据的高层特征表示,从而在图像和视频理解任务中取得了显著的效果。然而,现有基于DCNN的方法在应用于视频分析时仍然面临一些挑战,例如:模型的泛化能力、训练过程中的过拟合问题以及高计算复杂度等。
该研究的重点在于探索基于DCNN的场景理解和语义分析方法。具体而言,文章分析了场景理解和语义中的DCNN存在的问题,研究了该模型的基本原理。为了提高DCNN的性能,文章引入基于L2正则化[9-10]的优化方法以期抑制过拟合现象。该论文结合实际数据集,对所提出的方法进行了实验验证与性能评估。通过理论研究和实验测试,文章旨在进一步推进视频媒体内容自动理解与分析技术的发展,提升现有方法在处理复杂视频场景时的有效性和鲁棒性。
1 基本原理与问题分析
DCNN作为视频理解与分析领域的主要技术之一,其核心原理在于通过多个卷积层和池化层的堆叠,从视频帧中提取多层次的特征。具体而言,DCNN对输入视频帧进行卷积操作来提取图像的局部特征,例如边缘、纹理等,每个卷积层的输出通过激活函数引入非线性,再经由池化层进行降维和去冗余操作,从而保留关键特征并减少计算量。在完成特征提取后,特征图被展平并输入全连接层进行分类或回归任务。
然而,DCNN在其应用也存在一些局限性。该模型通常需要大量标注数据进行训练,而获取大规模高质量的标注视频数据集成本高昂且耗时并且标准DCNN容易出现过拟合现象,特别是在训练数据量不足或数据分布不均衡的情况下。过拟合导致模型在训练集上表现良好,但在测试集或实际应用场景中性能显著下降。
针对上述标准DCNN的局限性,文章引入L2正则化优化方法来改善DCNN在该场景下的性能。具体而言,L2正则化在优化过程中加入了参数平方和惩罚项,使得权重参数趋向于较小的值,防止模型过度拟合训练数据。这不仅有助于提升模型在测试集上的表现,还能增强其在实际应用场景中的鲁棒性和稳定性。此外,L2正则化能够简化模型,减少不必要的复杂度,从而降低计算成本和资源需求,提高模型训练和推理的效率。
2 引入L2正则化的DCNN优化方法
2.1 标准DCNN模型
设输入图像为一个张量X,其中,X∈RH×W×C,H为图像高度,W为图像宽度,C为图像通道数。卷积层的核心操作是卷积运算。在卷积运算中,卷积核K作用于输入图像的局部区域并得到输出特征图Y,其计算方法为:
Yi,j,k=∑Hfm=1∑Wfn=1∑Cc=1Xi+m-1,j+n-1,c·Km,n,c,k+bk(1)
其中,Hf和Wf分别为卷积核的高度和宽度,Km,n,c,k为卷积核的权重,bk为偏置项。
卷积操作完成后,激活函数(·)被应用于卷积输出来引入非线性映射。常用的激活函数为修正线性单元,其表达式为:
(x)=max(0,x)(2)
后续的池化层用于降维和减少参数量,常用的池化操作为最大池化:
Yi,j,k=max(m,n)∈RXi+m-1,j+n-1,k(3)
其中,R表示池化窗口的区域。在卷积和池化操作之后,特征图被展平并输入全连接层。全连接层的输出z通过线性变换和激活函数得到,其计算公式为:
z=(Wh+b)(4)
其中,W为权重矩阵,h为输入向量,b为偏置项。在训练过程中,该模型通过最小化损失函数L(θ)来优化模型参数θ,常用的损失函数为交叉熵损失,其表达式为:
L(θ)=-∑Ni=1yilog(y^i)+(1-yi)log(1-y^i)(5)
其中,N为样本数量,yi为真实标签,y^i为预测概率。该过程中,梯度下降算法被用于优化损失函数,该方法通过计算损失函数对参数的梯度θL(θ),按照学习率η更新参数:
θ←θ-ηθL(θ)(6)
通过反复迭代,DCNN模型的参数逐步被优化,最终实现对输入数据的高效学习与分类。
2.2 基于L2正则化的优化方法
为了改善DCNN的性能,文章引入了L2正则化方法来抑制过拟合并提升模型的泛化能力。L2正则化通过在损失函数中增加一个正则项来实现该目的,正则项用于惩罚模型的复杂度,使得权重参数趋向于较小的值。具体而言,L2正则化的损失函数定义为:
Lreg(θ)=L(θ)+λ∑iθ2i(7)
其中,L(θ)为原始的交叉熵损失函数,θ表示模型的参数,λ为正则化系数,控制正则化项的权重。正则项∑iθ2i是所有权重参数的平方和,旨在防止权重参数过大导致的过拟合现象。
在反向传播算法中,参数优化目标为最小化正则化后的损失函数Lreg(θ)。因此,参数的梯度计算也需要包括正则化项的影响,具体来说,参数θ的梯度更新方法为:
θLreg(θ)=θL(θ)+2λθ(8)
其中,θL(θ)是原始损失函数L(θ)对参数θ的梯度,2λθ是正则化项对参数θ的梯度。最终,参数更新方法为:
θ←θ-η(θL(θ)+2λθ)(9)
式(9)表明,在每次迭代中,模型参数不仅根据原始损失函数的梯度进行更新还要考虑正则化项的影响,从而使得权重参数趋向于较小的值。
3 实验与分析
3.1 数据集与实验环境
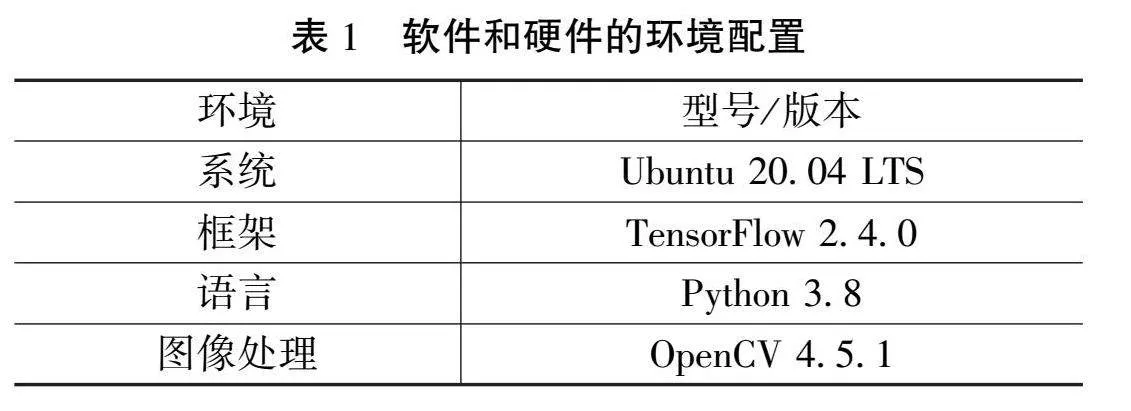
YouTube-VOS数据集是一个大规模、高质量的视频对象分割数据集,特别适用于视频内容理解和分析任务。该数据集包含大量真实世界的多种类视频片段,每个视频帧都附有精确的对象分割标注,覆盖了丰富的场景和多样的物体类别。该数据集因其数据量大、标注精细、类别多样,成为视频理解领域的重要基准数据集,广泛应用于视频场景理解等研究任务中。为了对文章中研究的方法进行评估,实验采用了YouTube-VOS数据集对方法进行了测试,实验环境配置如表1所示。
3.2 效果分析
该实验以YouTube-VOS数据集为基准,利用如表1配置的实验环境对文章中的基于L2正则化的DCNN优化方法进行测试,具体步骤包括:对YouTube-VOS数据集进行预处理,提取视频帧并进行数据增强;构建并训练DCNN模型,使用L2正则化项优化损失函数,控制过拟合并提高泛化能力;在训练过程中,监控验证集的损失和准确率,通过超参数调优确保模型性能最佳;训练完成后,使用独立的测试集评估模型的实际性能,测量其在视频对象分割任务中的准确性和鲁棒性;将实验结果进行可视化展示,分析方法的有效性和优势,从而验证该DCNN优化方法在数字媒体视频内容理解与分析中的应用效果。
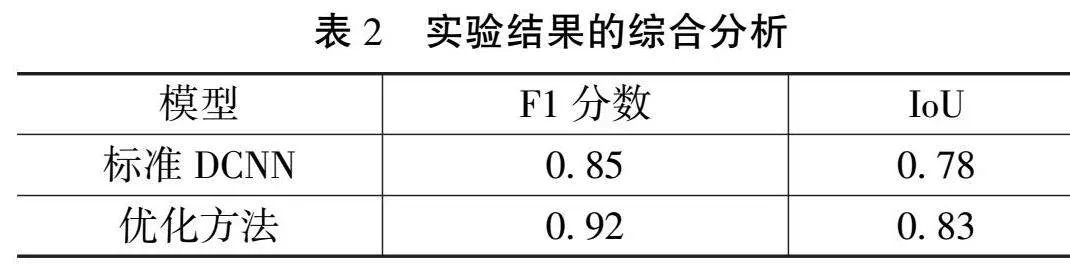
为了对实验效果进行综合分析,该实验对比评估了标准DCNN和文章中基于L2正则化的DCNN优化方法,使用了F1分数和交并比(Intersection over Union, IoU)作为评价指标,实验结果如表2所示。
在视频对象分割任务中,文章中的优化方法相较于标准DCNN模型表现出显著的提升。从F1分数来看,优化方法达到了0.92,而标准DCNN模型仅为0.85,说明该方法在模型的精确率和召回率之间取得了更好的平衡,对目标物体的识别和分割更为准确和全面。通过IoU指标的评估,所研究方法(0.83)远高于标准DCNN模型的0.78,表明所研究的优化方法预测的目标物体区域与真实标注区域的重叠度更高,具有更好的空间匹配性和精准度。这些结果充分验证了引入L2正则化的优化方法在DCNN中的有效性,能有效控制过拟合现象,提升模型在复杂场景下的稳定性和泛化能力。因此,该方法不仅在理论上有所突破,也在实验结果上得到了充分的验证和支持,为视频内容理解与分析领域的进一步研究和应用提供了重要参考。
4 结语
文章通过引入L2正则化优化方法,成功改善了DCNN模型在数字视频媒体内容理解与分析中的性能。通过对比实验结果,该研究证明了优化方法相对于传统DCNN在精确度和目标完整性上的显著改善。未来的研究方向可进一步探索更复杂的数据集和场景,进一步优化模型结构与参数,以提升模型的普适性和鲁棒性。该成果为数字媒体内容理解技术的进一步发展提供了有力支持,对于提高视频内容分析的自动化水平具有重要的理论和实际意义。
参考文献
[1]顾曰国.多媒体、多模态学习剖析[J].外语电化教学,2007(2):3-12.
[2]朱云,凌志刚,张雨强.机器视觉技术研究进展及展望[J].图学学报,2020(6):871-890.
[3]张天予,闵巍庆,韩鑫阳,等.视频中的未来动作预测研究综述[J].计算机学报,2023(6):1315-1338.
[4]黄凯奇,陈晓棠,康运锋,等.智能视频监控技术综述[J].计算机学报,2015(6):1093-1118.
[5]赵祥模.自动驾驶测试与评价技术研究进展[J].交通运输工程学报,2023(6):10-77.
[6]尹宏鹏,陈波,柴毅,等.基于视觉的目标检测与跟踪综述[J].自动化学报,2016(10):1466-1489.
[7]刘杨涛,徐鑫.基于深度卷积神经网络的行人检测实现[J].南阳理工学院学报,2020(6):58-63.
[8]王容霞,贺芬,杨伟煌,等.融合DCNN的面部特征检测在驾驶员危险驾驶中的应用研究[J].商丘职业技术学院学报,2022(2):71-76.
[9]杨浩,马建红.正则化参数求解方法研究[J].计算机测量与控制,2017(8):226-229.
[10]吕国豪,罗四维,黄雅平,等.基于卷积神经网络的正则化方法[J].计算机研究与发展,2014(9):1891-1900.
(编辑 王永超)
Automatic understanding and analysis of digital video media content
TANG Kai
(Huai’an Senior Vocational and Technically School, Huai’an 223005, China)
Abstract: The article investigates the application of deep convolutional neural networks based on L2 regularization optimization in automatic understanding and analysis of digital video media content. Specifically, the article analyzed the basic principles of DCNN and introduced L2 regularization method to optimize the method. In the experimental section, the YouTube VOS dataset was used to validate and compare the method. The F1 score and intersection to union ratio index were used to evaluate the improvement effect of the optimization method compared to standard DCNN. The experimental results show that this method has achieved excellent results in video object segmentation tasks, verifying the effectiveness of L2 regularization in deep learning model optimization.
Key words: digital video; video analysis; deep convolutional neural network; regularization
