
基于OCR技术的档案智能化收集方法研究
2024-11-12 00:00:00张婷琳陈祥本丁晔张勇
无线互联科技 2024年19期

摘要:为实现档案信息的智能化管理,文章提出了一种轻量化的端到端档案智能化收集系统。首先采用轻量化的目标检测神经网络PP-PicoDet作为布局检测器,用于对档案材料的版面分析;然后采用SLANet深度学习神经网络进行表格的结构化识别;最后使用开源的Paddle OCR引擎进行文本识别。系统对表格识别的准确度达到75.8%,印刷体文本识别准确度达到98.3%,总推理时间少于0.85 s。该系统为实现端到端的档案资料智能化收集,提高档案资料整理的效率提出了一种有效解决方案。
关键词:档案智能化收集;深度学习;光学字符识别;中文表格;手写体识别
中图分类号:TP391 文献标志码:A
0 引言
目前许多存放在档案馆的历史文档都是以手写形式存在,只有近十几年来的资料才开始以图片的形式保存。纸质档案在存储中存在许多弊端,如易损坏、物理存储空间需求大、检索效率低等。随着信息技术的不断发展,大量的纸质档案资料须要进行数字化整理以适应数字化时代的需求。传统的人工数据录入方式效率低且成本高昂,而光学字符识别(OCR)技术能够将图像中的文字进行自动识别并转换为可编辑的数字文本,更加方便快捷。自动进行文本分析、信息提取和挖掘将极大地提高档案资料整理的效率,有助于建立完善的档案信息管理系统,提升信息化水平。
OCR技术在识别印刷体和手写体文本方面已经取得了显著进展,但仍然存在一些问题:低分辨率图像中,字体大小、扭曲、阴影等因素可能导致字符识别错误;手写文本质量差异大,使得OCR识别难度增加;无法处理复杂的文档格式和布局,容易导致识别错误或丢失重要信息等。这些问题在档案整理中都可能出现。因此,改进当前的OCR技术以提高识别准确度和效率,是实aa4285e4d6ff36c151a265a315bd3897现档案信息化管理的关键问题。
1 光学字符识别技术
OCR技术是一种将图像中的文字转换为可编辑文本的技术。在数字化时代,它在信息处理、文档管理和自动化任务中发挥着至关重要的作用。传统的OCR方法主要依赖特征工程和模式匹配,效果容易受到图像质量、字体和大小等因素的影响。而基于深度学习的OCR方法不仅能自动学习图像中的文字特征,还具有更好的鲁棒性和准确性[1]。OCR技术的工作流程通常包括以下几个关键步骤。
1.1 图像预处理
图像预处理是对输入图像进行预处理,包括去除噪声、调整图像尺寸、灰度化等操作,以提高后续识别步骤的准确性。
1.2 文本检测
文本检测是在预处理后的图像中检测出文本的位置和边界框。常用的文本检测算法可分为基于回归的算法、基于分割的算法和二者结合的方法。基于回归的算法改进自一般的目标检测算法,在识别规则形状的文本上表现良好,如TextBoxes、CTPN和EAST等。基于分割的算法,如PSENet和DBNet,借助Mask-RCNN目标实例分割框架,在不同场景文本检测中展现出更好的效果。但这些算法的后处理复杂,速度较慢。
1.3 文本识别
文本识别是在文本检测切割出的文本区域中识别出文本内容。对于印刷体这类排版规则的文本,常采用基于CTC的算法和基于Sequence2Sequence的算法。对于手写体和场景文本等存在弯曲、覆盖和模糊的不规则文本,会添加校正模块或使用基于注意力机制的方法关注序列间的相关性,其中Transformer算法的各种变体取得了较好的效果。
1.4 后处理
后处理是对识别结果进行后处理,包括纠正识别错误、去除不必要的字符等,以提高最终的识别准确性。
传统的纸质档案资料以纸张作为载体,通过拍照、扫描等方式将其转换为电子图片,然后使用OCR技术实现对纸质档案的自动化信息提取。对于清晰、标准字体的印刷体文本,当前技术通常能够实现高准确率的识别。然而,中文手写体识别由于书写个体差异大和中文结构复杂,一直是OCR技术中的难题之一。表格数据的识别涉及结构化信息的提取,包括表格的行列识别和单元格内容的识别。相比于普通文本,表格数据的识别需要更复杂的算法和处理步骤。因此,中文表格与手写体的识别是基于OCR技术实现档案资料智能化管理的最大挑战。
2 基于OCR技术的档案智能化收集方法
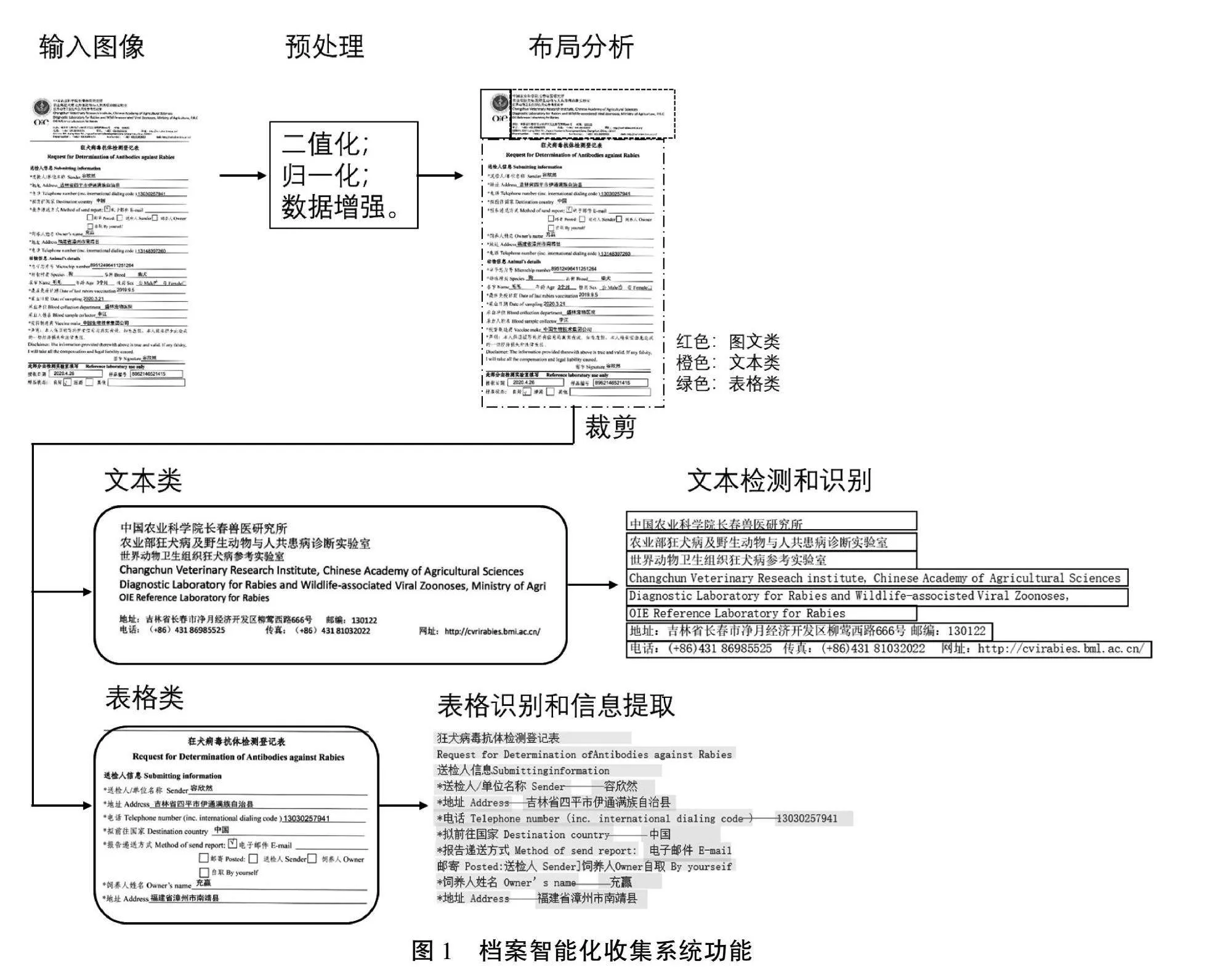
本节主要介绍对档案资料中常见的印刷体、表格和手写体进行智能化识别的OCR技术。通过与常见的OCR方法的比较,选择识别准确率高且轻量化的网络模型,实现端到端的档案智能化收集。整个端到端系统功能如图1所示。
2.1 预处理
首先通过拍照、扫描等方式将纸质档案资料转换为.jpg格式的电子图片,并将图片调整到统一大小(800×608像素)。由于本文重点关注档案中文字信息的提取,因此使用自适应阈值算法对图片进行二值化和归一化处理,将其转换为黑白图像,从而更有效地将文本与背景分离,便于后续的文本检测和识别。采集图像时可能会出现模糊、扭曲、阴影等问题,也会遇到多种多样的手写文本场景。为了提高模型的鲁棒性和泛化性能,须要进行数据增强。通过随机旋转、缩放、弹性变换、模糊、添加高斯噪声和裁剪等方法,可以增加样本的数量和多样性。本文使用Python中的OpenCV库函数实现数据增强。
2.2 布局分析
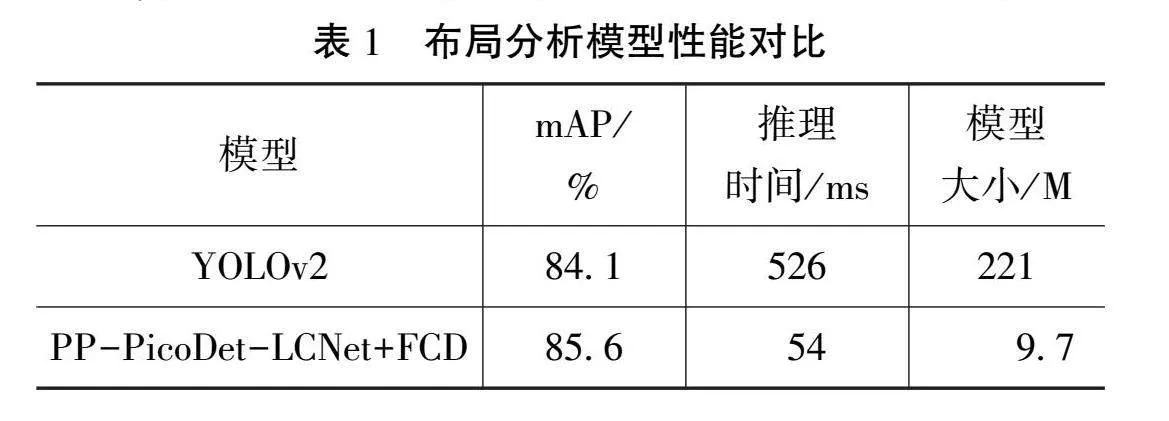
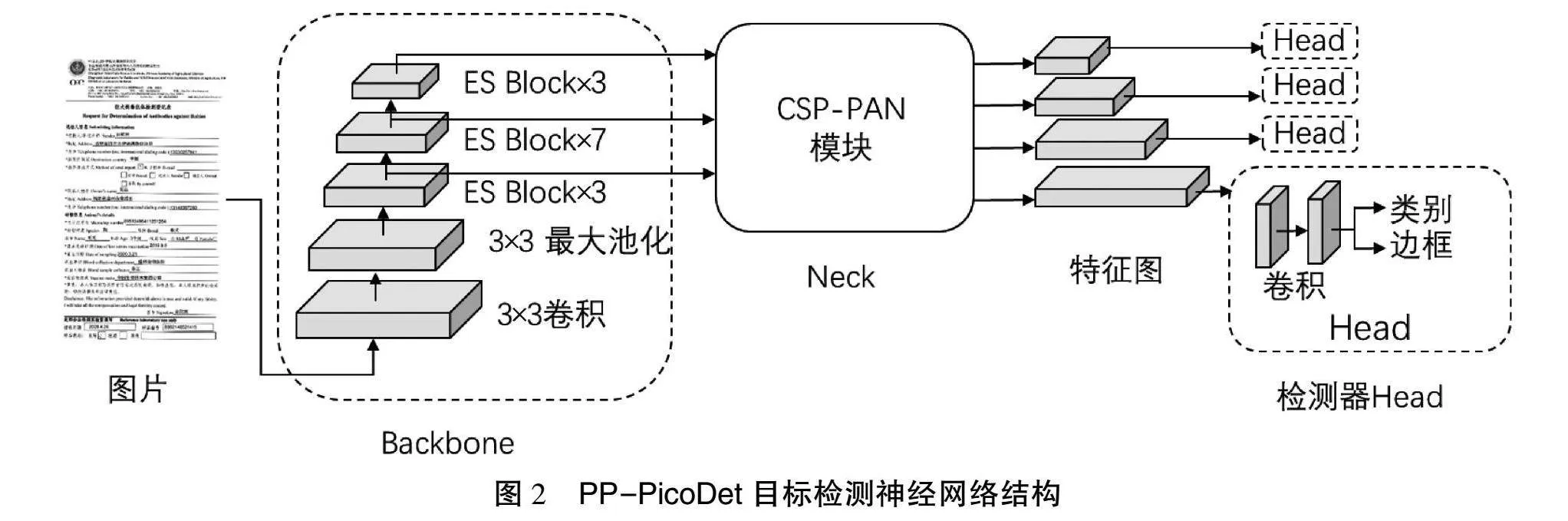
布局分析模块将每个档案文档页面划分为不同的内容区域,包括纯文本、标题、表格、图片和列表等,便于后续对不同区域的识别,网络结构如图2所示。该模块采用轻量化的目标检测神经网络PP-PicoDet作为布局检测器[2-3]。使用CSP-PAN模块作为Neck层,采用SimOTA动态标签分配策略并以PP-LCNet为主干网络Backbone层。通过一次性神经结构搜索(One-shot Neural Architecture Search, One-shot NAS)算法,自动找到目标检测的最优结构。与市面上流行的YOLO目标检测算法相比,PP-PicoDet具有轻量化和运行速度快的优势[2-3]。在CPU上运行时,它可以达到与PP-YOLOv2相当的检测精度,但运行速度快11倍。为进一步压缩目标检测模块,并使模型更轻量化,使用知识蒸馏算法中的特征一致性蒸馏(Feature Consistency Distillation,FCD)算法[4],同时考虑局部和全局特征图。局部蒸馏分离图像的前景和背景,使学生网络专注于教师网络的关键像素和通道;全局蒸馏重建不同像素之间的关系,将其从教师网络传递给学生网络,以补偿局部蒸馏中缺失的全局信息。
2.3 表格识别
在档案文档页面中划分的表格区域,需要对表格结构和单元格坐标进行预测,以进一步识别表格中的内容和结构化信息。为此,采用轻量化的SLANet(Structure Location Alignment Network)深度学习神经网络进行表格的结构化识别[5]。具体来说,SLANet的Backbone层使用基于MKLDNN加速策略的轻量化卷积神经网络PP-LCNet,其预训练权重通过SSLD(Simple Semi-supervised Label Distillation)知识蒸馏算法在ImageNet数据集上训练得到,以提高模型精度。Neck层采用CSP-PAN模块,对Backbone层提取的特征进行多层融合,输出通道为96。PAN 结构用于获取多层特征图,CSP 网络则进行相邻特征图间的特征连接和融合,同时采用深度可分离卷积策略以降低计算代价。Head层为特征解码模块SLAHead,用于对齐表格的结构与位置信息,输出表格的结构token和全部单元格的坐标。在结构序列中,每个位置的预测是一个多分类任务,损失函数采用交叉熵。每个单元格的坐标预测是一个回归任务,损失函数则采用smooth L1 函数。
2.4 文本识别
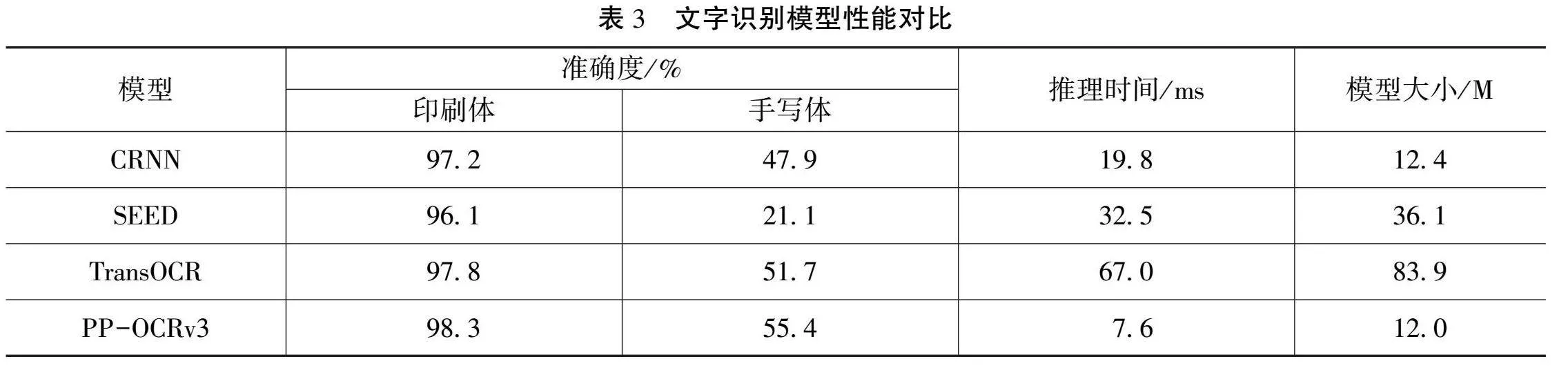
对档案文档页面中的纯文本区域和表格中的文本区域,系统使用开源的Paddle OCR引擎进行文本识别。通过比较2种常用的OCR引擎Paddle OCR和Tesseract OCR,发现PaddleOCR提供了丰富的预训练模型,可以进行迁移学习,而Tesseract OCR需要单独训练模型。此外,PaddleOCR的识别精度更高且更轻量化。因此,本文选择Paddle OCR中的PP-OCRv3超轻量中文识别模型进行文本识别。PP-OCRv3模型引入了SVTR-LCNet文本识别网络,融合了基于Transformer的SVTR算法和基于卷积神经网络的轻量化神经网络PP-LCNet[6]。该模型使用TextConAug数据增强策略、注意力引导的CTC(Connectionist Temporal Classification)训练方法、自监督的预训练模型TextRotNet以及U-DML和UIM技术,可以有效地提高模型效率和识别精度。
2.5 信息提取
信息提取模块主要用于理解和识别文档中的具体信息或信息之间的关系,包括语义实体识别(SER)和关系提取(RE)2个子任务。本文采用飞桨 PaddleNLP推出的UIE-X(Unified Information Extraction-X)开源信息抽取模型。该模型采用结构化抽取语言,对不同的抽取结构进行统一编码,并通过基于模式的提示机制(Schema-based Prompt Mechanism)自适应生成目标抽取结果。UIE-X模型基于文心ERNIE-Layout跨模态布局增强预训练模型,经过大规模数据的训练后,具备很强的迁移性能,仅须少量数据微调即可获得较好的抽取性能。为实现系统端到端的功能并保证模型轻量化,本文选用UIE-mini模型。
3 结果与讨论
3.1 数据集
由于档案资料种类繁多,决定了档案收集系统模型所使用的训练数据需要具有多样性。本文采用文档数据、手写体数据、表格数据等多个公开数据集,分别对系统中布局分析模块、表格识别模块、文本识别模块和信息提取模块进行了预训练,然后使用采集的档案资料图片对系统模型进行微调。其中,印刷体文本数据集来自开源数据库Text_Render生成的文档式的合成文本图像( https://github.com/Sanster/text_renderer),文本为印刷体文本。该数据集共包含500000个样本,其中80%被随机划分为训练集,10%为验证集,10%为测试集。表格数据使用TableGeneration表格工具生成(https://github.com/WenmuZhou/TableGeneration),生成了20000张图片,并按8∶1∶1的比例随机划分为训练集、验证集和测试集。合成文本和表格的语料库均来源于维基百科、亚马逊和百度百科。手写文本数据来自飞桨 AI Studio(https://aistudio.baidu.com/datasetdetail/102884),包括公开数据集Chinese OCR、中国科学院自动化研究所的手写中文数据集CASIA-HWDB 2.x以及网上开源数据合并组合的数据集。其中,训练样本共200000个,测试样本共10000个。本研究共采集了档案图片2000张,用于对系统模型进行参数微调,其中随机选择了1600张用于训练,400张进行模型测试。
3.2 试验结果与分析
布局分析模块采用了PP-PicoDet-LCNet 2.5x 模型作为教师网络,同时使用PP-PicoDet-LCNet 1.0x模型作为学生网络,采用FCD知识蒸馏算法。如表1所示,与YOLOv2目标检测算法相比,目标检测精度的平均精度均值(mean Average Precision,mAP)提高了0.5%。此外,推理时间方面,平均CPU耗时显著减少至54 ms,同时模型大小仅有9.7 M。因此,模型在轻量化和性能方面均优于YOLOv2。
本文还将表格识别模块SLANet模型与最新的几种效果较好的模型(TableMaster和飞桨表格识别模型PP-Structure的TableRec-RARE网络)进行了对比。如表2所示,SLANet的预测时间最短,同时在准确度和TEDS(Tree-Edit-Distance-based Similarity)方面都有所提高,超过了TableRec-RARE。尽管TableMaster在准确度和TEDS指标上略高于SLANet,但其模型规模大且参数多,是SLANet的27.5倍,推理时间是SLANet的2.8倍。因此,综合考虑轻量化和预测性能,SLANet的优势更为明显。
本文对印刷体文本和手写体文本进行了单独识别,以测试系统的文本识别性能。通过与几种表现较好的模型比较,发现由于印刷体文本排版较规则且字形规整,更容易被识别,其识别准确率达到95%以上。而手写体文本属于易出现弯曲、覆盖和模糊的不规则文本,因此其识别正确率较低,具体模型识别性能如表3所示。CRNN和PP-OCRv3的算法均采用了基于CTC注意力引导的方法,而TransOCR则基于Transformer的自注意力模块作为解码器。这些模型的识别准确率均高于SEED,再次证实了自注意力机制在序列识别中的优势。CRNN和PP-OCRv3的模型更为轻量化,但PP-OCRv3的运行时间更短,且识别准确度更高。
与飞桨PP-Structure的Ⅵ-LayoutXLM模型相比,UIE-X信息提取模块的F1 score提高了10%。尤其是对于文本行无序和含噪声的文档图像,UIE-X识别效果更好。虽然UIE-X模型规模更大,但其具备强大的模型迁移能力,无须耗费时间使用大量数据进行训练,仅须对30个少量样本进行微调,即可达到0.89的F1 score值。
4 结语
本文提出了一种轻量化的端到端档案智能化收集系统,通过与常见的OCR技术进行比较,选择了识别正确率高且轻量化的网络模型,以实现端到端的档案智能化收集。本文重点解决了当前OCR技术在识别档案资料中常见的表格、图表或非线性文本等复杂的文档格式和布局的问题。同时,为了将系统部署到移动设备前端,尽量平衡了模型精度和推理速度。系统对表格识别的准确度达到了75.8%,印刷体文本识别准确度达到了98.3%,而总推理时间不超过0.85 s。因此,本文系统可以实现端到端的档案资料智能化收集,为提高档案资料整理的效率提供了一种有效的解决方案。未来的工作将进一步解决图像采集中造成的低分辨率或低质量扫描等噪声的影响,提高手写体4cac820ab21bae3716d5e87d2ea33bb4识别精度并提高大型文档识别效率,以更好地服务于档案信息智能化管理系统。
参考文献
[1]王睿,林凯.基于神经网络的OCR技术在自动阅卷系统中的应用研究[J].现代计算机,2024(30):103-106.
[2]倪吴广,汪朵拉,张卓.基于PP-PicoDet技术的智能垃圾分类[J].计算机测量与控制,2023(31):291-298.
[3]陈永祺,顾茜,林郁.基于PP-PicoDet的半自动标注烟丝异物检测研究[J].中国烟草学报,2023(29):11-21.
[4]YANG Z,LI Z,JIANG X,et al.Focal and global knowledge distillation for detectors:2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR),June 18-19,2022[C].London:INSPEC,2022.
[5]陈雨,蒋三新.基于改进结构与位置对齐网络的表结构识别法[J].国外电子测量技术,2023(42):57-62.
[6]DU Y K,CHEN Z N,JIA C Y,et al.SVTR:Scene text recognition with a single visual model:31st International Joint Conference on Artificial Intelligence(IJCAI 2022),July 23-29,2022[C].New York:EI,2022.
(编辑 沈 强)
Research on intelligent collection method of archives based on OCR technology
ZHANG Tinglin1, CHEN Xiangben2*, DING Ye1, ZHANG Yong2
(1.Yancheng Institute of Technology, Yancheng 224051, China;
2.Yancheng Institute of Science and Technology Information, Yancheng 224002, China)
Abstract: In order to realize the intelligent management of file information, a lightweight end-to-end intelligent file collection system is proposed. Firstly, a lightweight object detection neural network PP-PicoDet is used as a layout detector to analyze the layout of archival materials. Then, SLANet deep learning neural network is used for structural recognition of the tables. Finally, the open source Paddle OCR engine is used for text recognition. The accuracy of the system for table recognition is 75.8%, the accuracy of printed text recognition is 98.3%, and the total reasoning time is less than 0.85s. This system brings forward an effective solution to realize the intelligent collection of file data from end to end and improve the efficiency of file data sorting.
Key words: intelligent collection of archives; deep learning; optical character recongnition; Chinese form; handwriting recognition
