
基于改进ED-YOLOv5s的矿井安全帽佩戴检测算法
2024-11-12 00:00:00郭云飞侯艳文陶虹京
无线互联科技 2024年19期





摘要:煤矿井下工作中安全帽佩戴是事关工人生命安全的一大关键要素。基于视频图像进行分析的技术虽可以较好地检测工人安全帽佩戴情况从而将事故带来的损害最小化,但是在矿井下的图像收集过程中往往存在各种各样的现实因素,例如环境复杂、存在多个目标等,给技术人员造成很大的干扰。针对以上问题,文章通过引进EMA注意力机制与DIoU损失函数,提出了一种改进的ED-YOLOv5s模型。在自制数据集上对该模型进行了消融实验,结果表明该模型相比原模型在图像检测速度和精度方面都有较大的提升。随后,文章将该算法与YOLOv7-tiny、YOLOv8进行对比实验,结果显示文章算法在矿井下安全帽检测的mAP@50%达到了97.3%。
关键词:图像分析;YOLOv5s;EMA;DIoU
中图分类号:TP391 文献标志码:A
0 引言
在我国众多高危行业(尤其是煤矿行业)中,安全帽对施工人员的生命安全起着至关重要的作用,然而一些工人缺乏安全意识不全程佩戴安全帽的现象屡见不鲜。对于上述情况,我国很多矿业的生产现场使用视频分析技术对工人佩戴安全帽情况进行识别与检测,但该技术在识别过程中存在检测精度低、图像检测速度慢等问题,因此,基于视频的检测识别技术迫切需要改进。
基于深度学习的方法可分为“两阶段”方法和“单阶段”方法[1]。“两阶段”方法首先使用算法提取特征,然后生成候选区域,最后使用分类器进行分类回归。该方法的优势在于显著提高检测精度,但不具备良好的时效性。“单阶段”方法采用端对端的方式对图像中的目标位置进行检测、分类。SSD[2] 模型和YOLO[3] 模型是“单阶段”算法中常用的2类。SSD模型对小目标检测能力较差。YOLO模型的原理是将安全帽检测识别转化为回归问题,使用卷积神经网络对输入图像进行预测,判定边界框位置及目标类别概率,小目标检测能力较强。
YOLO模型因其检测速度快、精度高在工业中被普遍应用。科研人员对YOLO模型进行了不断的改进。YOLOv3[4]首先出现了DarkNet53网络,结合使用AIIFO0oCcdzZkZJYMlkruO1ozkcZF6LZjhegre9Rgfs=FPN架构和多尺度融合等方式,提高了对小目标检测的精确度。YOLOv4[5]提出了具有不同层间交叉的CSPDarkNet53,使用 Mosaic数据增强方法和自我对抗训练方式提高网络的检测与识别的性能。YOLOv5[6]引进了模型检测和数据优化处理,操作简单并且易移植,小目标检测精度较高[7-8]。
YOLOv5模型一直处于不断更新中,现已有4种官方的算法模型,分别为YOLOv5s、 YOLOv5m、YOLOv5l和YOLOv5x。YOLOv5s模型的网络深度和特征图宽度最小,考虑到该技术将应用于煤矿行业,本文根据矿下复杂的环境,对模型网络结构进行调整以提高算法检测能力。本文以YOLOv5s为基础,通过引入EMA注意力机制和DIoU损失函数,提出了一种改进的ED-YOLOv5s模型。
1 YOLOv5s安全帽检测算法
1.1 YOLOv5s模型
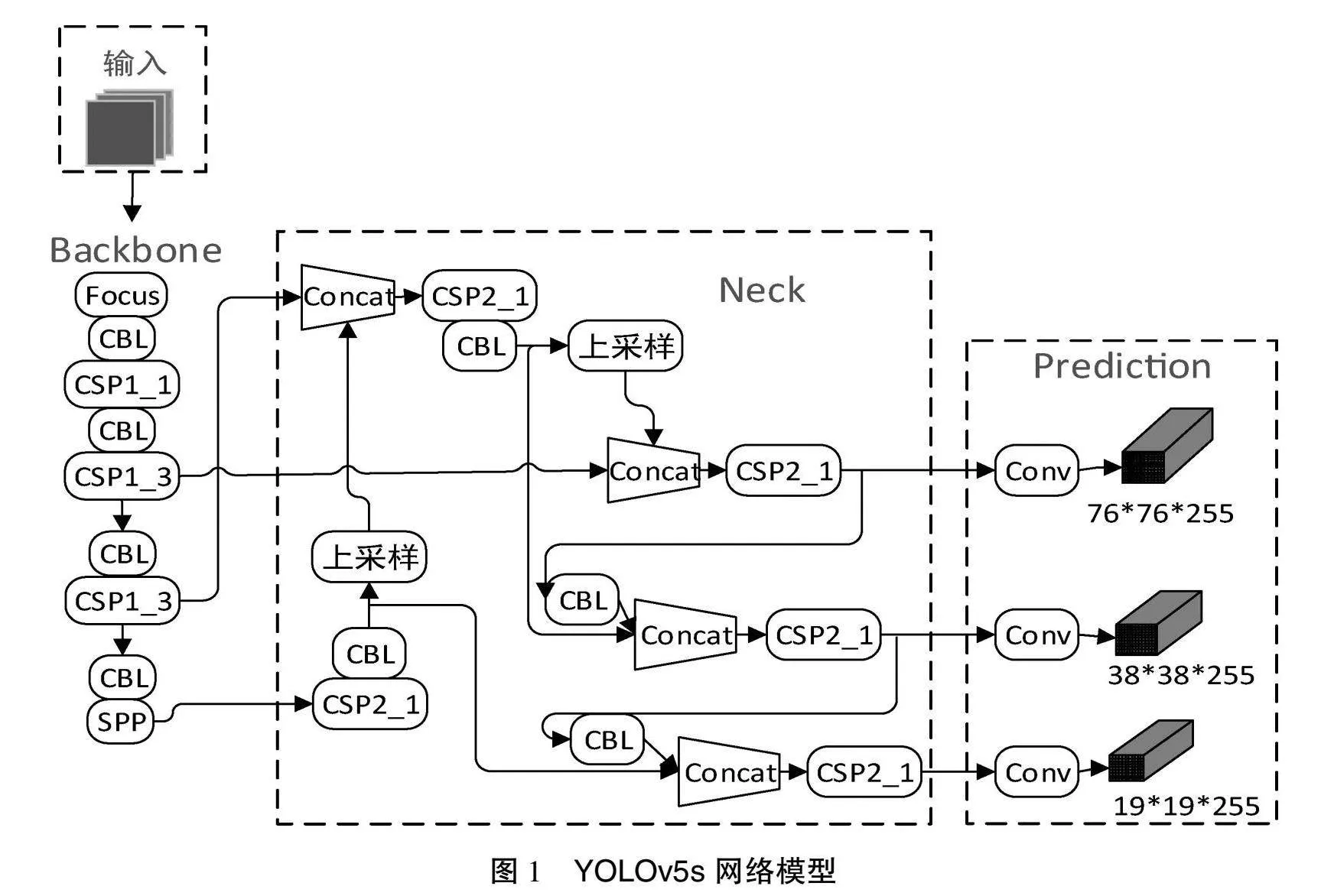
YOLOv5原模型主要包括4个部分:输入端、主干、颈部网络和预测头。输入端采用的是Mosaic数据增强。主干采用Focus和CSPDarkNet53 2种结构相结合。CSPDarkNet53是特征提取的核心,可以借助残差块来快速实现对特征图的降维,在保障检测精度的前提下,提升特征提取性能。颈部网络采用空间金字塔池(Spatial Pyramid Pooling,SPP)和路径聚合网络(Path Aggregation Network,PANet)的结构,用以加强不同特征层的特征聚合,提高不同目标网络检测的能力。最终由输出端输出目标的坐标及分类结果。
YOLOv5s是在YOLOv5的基础上在主干中添加CSP1_X结构,在颈部网络设置CSP2_X结构,增大了2层之间的反向传播梯度值,减小了梯度消失,使得YOLOv5的网络提取特征性能增强。YOLOv5s的网络结构如图1所示。
1.2 YOLOv5s算法原理
输入端对接收到的图像进行处理并校正图像格式。主干网络对输入图像进行特征提取,便于后续对该目标的检测工作。颈部网络对来自主干网络的特征图进行卷积操作或采样操作,保证能同时处理不同分辨率的图像信息以提高检测的鲁棒性。预测头是该模型的核心,可将接收到的已处理的特征图转化为预测结果、生成边界框位置、置信度等信息。
1.3 ED-YOLOv5s算法
由于煤矿下复杂多样的环境,改进后的视频分析技术依然存在无法准确提取多尺度目标的关键特征、检测不具备实时性等问题。为提高检测实时性、准确率,本研究在不损失检测精度的前提下,提出了一种改进的ED-YOLOv5s的安全帽检测模型。改进如下:
1.3.1 引入EMA注意力机制
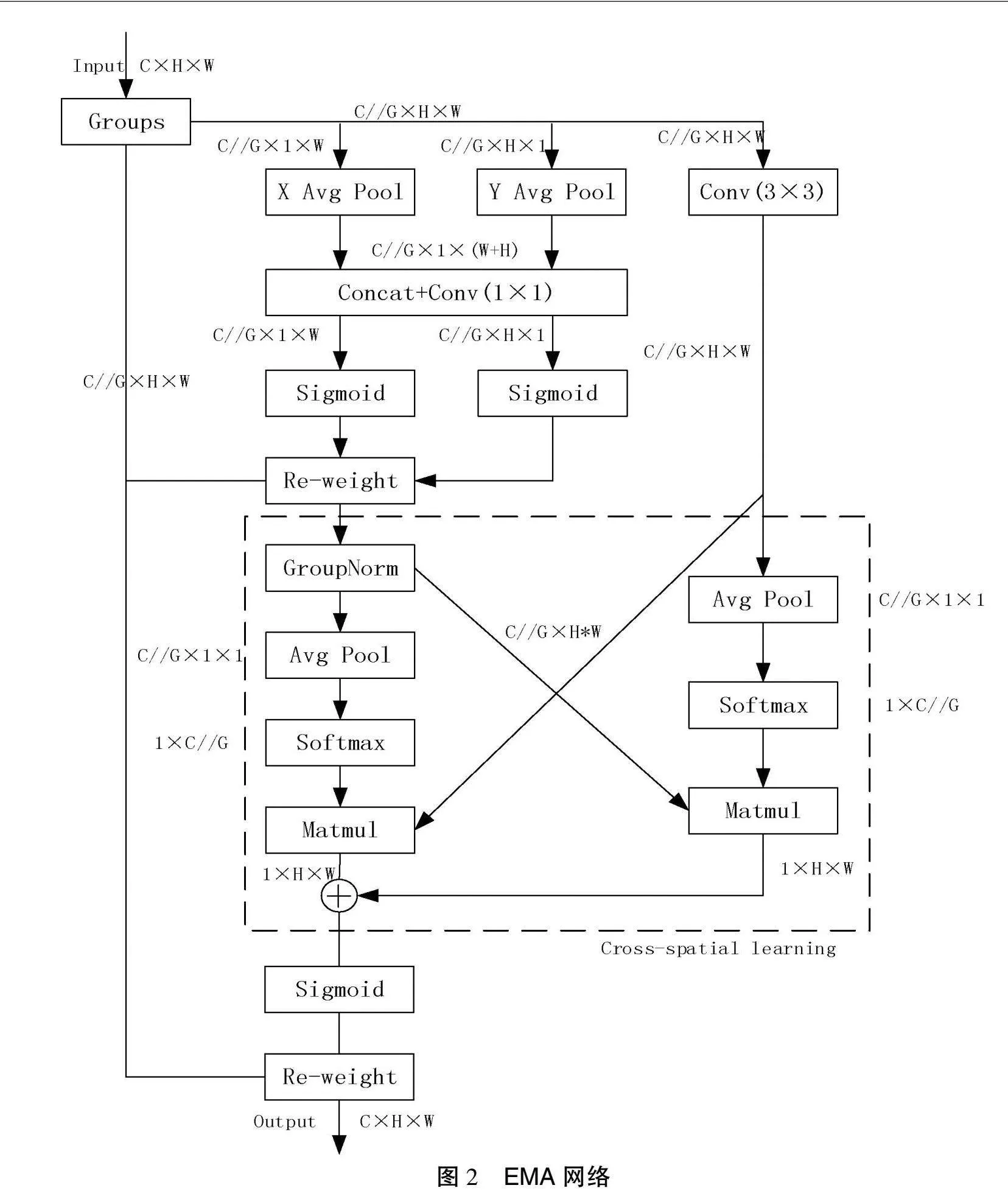
深度学习中的注意力机制是指在复杂环境中将注意力放在关键点上,选出关键信息,忽略无关信息。注意力机制也可以形象地理解为在生活中当人们在查找图片中的物体信息时,会更仔细地关注符合此物体特征的图片,忽略不符合的图片区域,即注意力的合理高效分配。此模块已经被应用于自然语言处理、图像检测、语音识别等诸多领域。基于注意力机制的模型可以用来记录信息间的位置关系,进而根据信息的权重去度量不同信息特征的重要程度[9]。此外,加入此模块后建立动态权重参数,提高了深度学习算法效率和运行速度,对传统深度学习有很多改善。EMA网络如图2所示。
根据注意力机制的原理可知,计算公式为:
Attention(Query,Source)=∑Lxi=1Similarity(Query,Keyi)×Valuei
其中,Lx表示Source的长度,Attention从大量信息中有选择地筛选并聚焦到这些重要信息上,忽略不重要的信息。聚焦的过程体现在权重系数的计算上,权重越大越聚焦在对应的Value值上。
EMA注意力机制由AE、AM、AR 3个模块组成。AE是指EM算法的第E步,该步骤为观测数据形成被骨干网络提取的特征图,包含数据Z形成的注意力图。AM模块即为EM算法的第M步,该步骤对AE模块得到的似然函数进行计算求得最大期望,进而得到一组新的基。以上2个模块进行交替工作,当数据表现为收敛时,AR模块对此进行重建特征图。
EMA模型与一般的注意力机制不同,它不参与计算每个像素之间的联系,而是本着期望最大化的理念来查找一组具有代表性的基,然后使用这组基对先前骨干网络提取得到的特征图进行重新组建,在满足上下文信息的条件下获得具有最少点的特征图,可以有效地降低时空复杂度。换言之,EMA模型可以根据较高权重去着重考虑关键信息,忽略低权重信息。即使在复杂环境中,EMA模型也可以抓住主要信息,实现了信息处理资源的高效分配,具有较高可扩展性和鲁棒性。此外,EMA模型还可以将选定的重要信息与其他模块进行共享,实现信息的互通。
1.3.2 引入DIoU损失函数
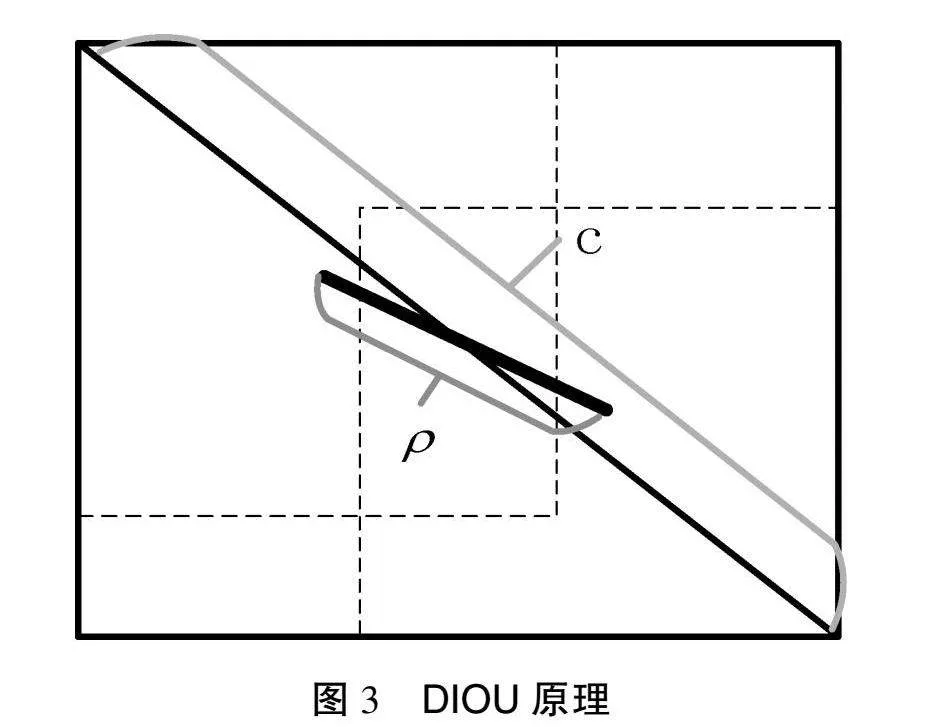
损失函数是用来评价模型稳定性的重要指标,可以较大程度地影响检测结果和模型收敛速度,对于目标检测的精度及模型收敛速度有重要作用。DIoU损失函数可以加快边界框回归速率,提高定位精度,加快对目标的检测速率。该损失函数在IoU损失函数的基础上添加了一个惩罚,可以最小化和归一化中心点距离,加快了收敛过程。此外,DIoU损失函数是对GIoU损失函数的优化,收敛速度更快。
在训练过程中,当出现绝缘子数据集与预测框中心点位置相同的情况时,尽管预测框形状不同,DIoU回归值大小依然保持相同。当2个边界框之间存在包含、平等和垂直等情况时,DIoU能使预测框更快地回归[10]。
DIoU的损失函数可以表示为:
LDIoU=1-IoU+ρ2(b,bgt)c2
在上述公式中,ρ为欧氏距离,c为目标预测框与实际框内部最小的外接矩形之间的对角线距离。DIoU同时考虑了两者的重叠面积与中心点距离。当发生预测框在真实框内部且两者存在交集时,在参考中心点距离后可加快边界框回归速率,进而加快DIoU损失函数的收敛。DIoU的原理如图3所示。
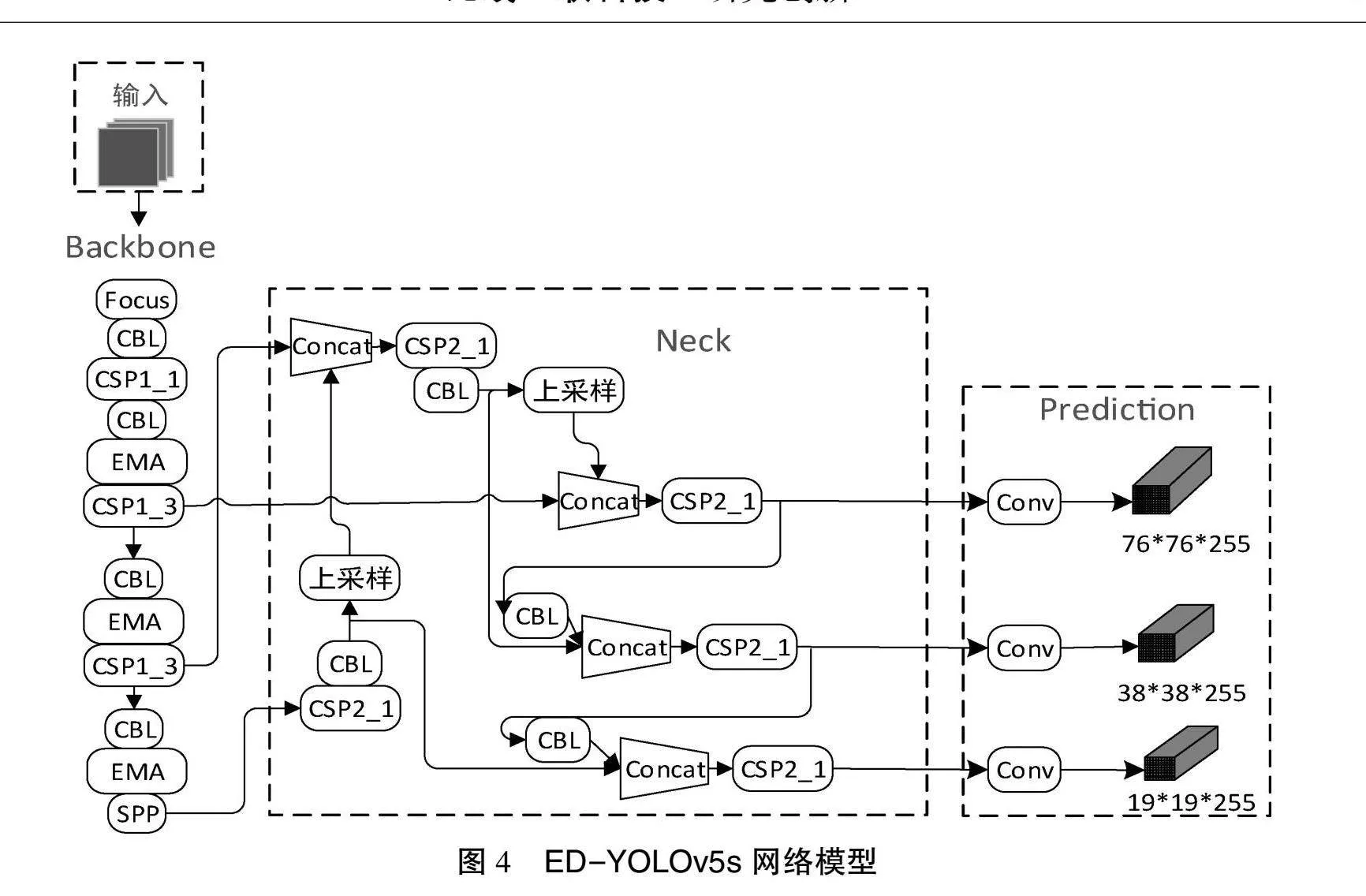
2 ED-YOLOv5模型网络结构
改进后的ED-YOLOv5s如图4所示。本文在YOLOv5s模型中的骨干网络添加注意力机制(EMA)模块,将图像中安全帽设置为提取特征,进而检测工人安全帽佩戴情况。将基于Focal Loss和GIoU Loss的组合替换为DIoU损失函数,加快了收敛速度。
3 实验与分析
3.1 实验环境
本研究使用自制数据集。该数据集分为训练集、验证集、测试集3类,共包含6421张图像。此数据集中包含了井下及地面工人安全帽佩戴的数据,综合考虑了场地、光线、个人姿势和是否遮挡等复杂条件,具备十足的可靠性。在测试过程中,所有YOLO模型训练的epoch为100,Batch-size为8,学习率为0.0001,而且为避免测试中出现过拟合采用了早停策略。
3.2 消融实验
为了验证改进的ED-YOLOv5s的性能,本研究进行了消融实验。该实验以YOLOv5s模型为基础模型,对EMA注意力机制、DIoU损失函数分别进行分析,了解各模块对提升模型性能分别发挥的作用以及对结构改进的有效程度。根据结果的精确率(P)、平均均值精度(mAP@50%)、召回率(R)的数值来分析改进后的ED-YOLOv5s网络对井下安全帽佩戴情况的检测性能。依据算法参数量、每秒传输帧数来评价改进算法的优劣。实验结果如表1所示。
表1给出了使用数据集后的消融实验结果, ①为加入EMA注意力机制, ②为加入DIoU损失函数, ③为同时加入EMA注意力机制和DIoU损失函数。结果显示mAP@50%分布提升1.0%、0.7%、1.2%,同时加入EMA注意力机制和DIoU损失函数模型的mAP@50%值最大;加入EMA注意力机制的模型精确度明显提高,表明此模块可以较好地捕捉关键特征。同时,加入DIoU损失函数后FPS值显著增大,检测更具实时性。依据mAP@50%值及FPS值可知本研究ED-YOLOv5s算法精度更高、检测速度更快,可以更好地适用于煤矿企业。
3.3 对比试验
当引入EMA注意力机制模块后,本研究发现EMA注意力机制的数量与添加位置的不同也会使模型产生不同的精度、检测速率。因此,本研究针对不同情况进行了对比实验,实验结果如表2所示。
表2给出了3种不同模型及原始模型在自制数据集上的检测与识别数据。可以看出:4种模型的参数量和模型体积大致相等;YOLOv5s的模型召回率最高,但精度偏低;YOLOv5s+1EMA的图像处理速度最快,但精度低于YOLOv5s+3EMA;YOLOv5s+2EMA的精度、mAP@50%值以及FPS值均小于其余3种模型,性能较差。相比之下 YOLOv5s+3EMA的精度最高、mAP@50%值最大、检测实时性最好。
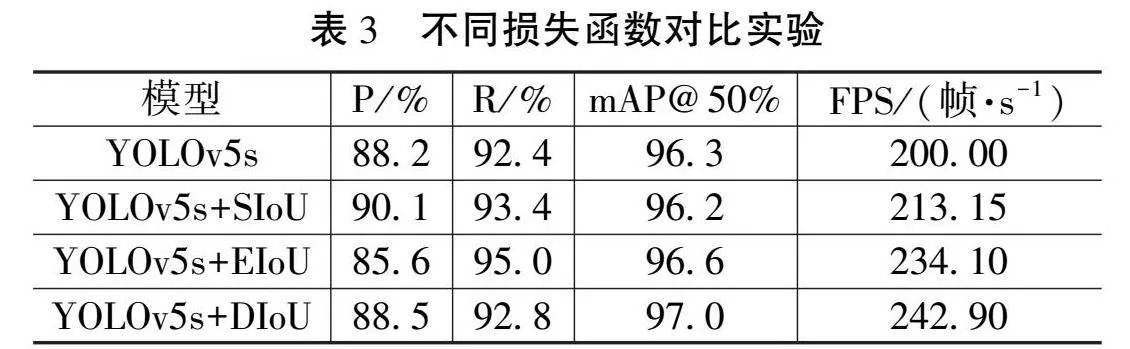
为直观地看出不同损失函数对YOLOv5s模型图像处理速度和精度的影响,本文对YOLOv5s原模型以及分别采用SIoU损失函数、EIoU损失函数、DIoU损失函数的4类模型进行了对比实验。实验结果如表3所示。
表3给出了YOLOv5s在分别采用SIoU、EIoU、DIoU不同损失函数后在相同数据集上的检测与识别数据。可以看出:YOLOv5s原模型的精度、检测速度均低于其他3种模型;YOLOv5s+SIoU的精度最高,在精度、模型召回率及检测速度上均优于原模型;YOLOv5s+EIoU的精度最低,但区域3项指标模型均优于上述2种模型;YOLOv5s+DIoU的精度及模型召回率均高于原模型且mAP@50%值和FPS值最大。由此可得采用DIoU损失函数的模型平均均值精度最高,图像检测速度最快,更具实时性。
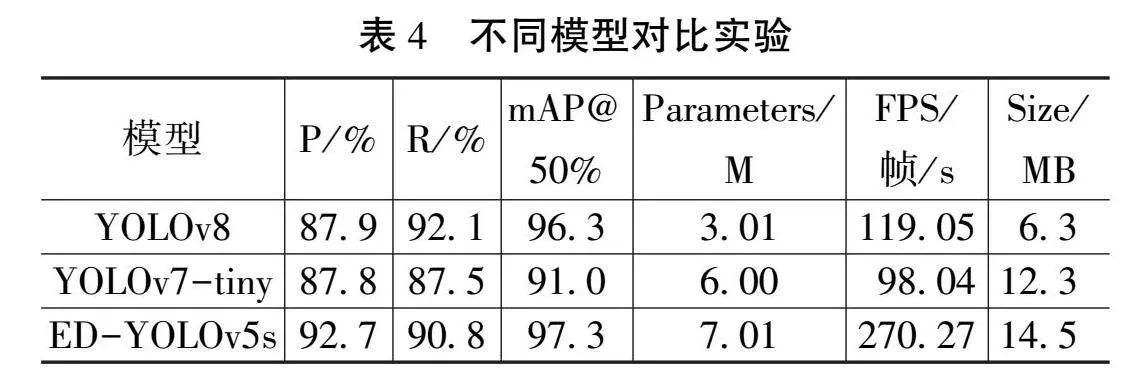
为进一步探究本文模型对矿井下安全帽佩戴情况的检测效果,本研究将改进后的ED-YOLOv5s模型、YOLOv7-tiny以及YOLOv8算法使用相同样本和训练环境,对它们进行客观的指标对比。实验结果如表4所示。
表4列出了3种算法在相同数据集上的检测与识别后的结果。使用检测精度P、模型召回率、平均均值精度等的数据结果对其性能进行评价,结果表明:YOLOv8的精度、mAP@50%值、FPS值均小于ED-YOLOv5s,但参数量和模型体积较小;YOLOv7-tiny的精度、模型召回率、mAP@50%值以及FPS值均小于ED-YOLOv5s和YOLOv8。3种模型中本文改进模型的mAP@50%值最高,图像处理速度最快。
3.4 检测效果
如图5所示,可看出本研究改进的ED-YOLOv5s模型对煤矿井下的图像检测精度高,可以较好地实时性地对工人安全帽佩戴情况进行检测。
4 结语
本研究针对矿井下视频检测精度低、检测速度慢、不具备实时性等问题,以YOLOv5s为基础提出了一种结合EMA注意力机制和DIoU损失函数的改进的ED-YOLOv5s模型。使用自制数据集对该模型进行消融实验,结果表明2处改进点可以显著地提升YOLOv5s的性能。为了解改进效果,本文将该模型与YOLOv7-tiny、YOLOv8进行对比实验。实验结果显示本文模型可以很好地检测工人安全帽佩戴情况,具备检测速度快、精度较高等优势,可以较好地解决煤矿井下的现有问题。
参考文献
[1]李宝奇,黄海宁,刘纪元,等.基于改进SSD的合成孔径声纳图像感兴趣小目标检测方法[J].电子学报,2024(3):762-771.
[2]王琳毅,白静,李文静,等.YOLO系列目标检测算法研究进展[J].计算机工程与应用,2023(14):15-29.
[3]王涛,冯浩,秘蓉新,等.基于改进YOLOv3-SPP算法的道路车辆检测[J].通信学报,2024(2):68-78.
[4]闵锋,况永刚,毛一新,等.改进YOLOv4的遥感图像目标检测算法[J].计算机工程与设计,2024(2):396-404.
[5]贵向泉,秦庆松,孔令旺.基于改进YOLOv5s的小目标检测算法[J].计算机工程与设计,2024(4):1134-1140.
[6]赵睿,刘辉,刘沛霖,等.基于改进YOLOv5s的安全帽检测算法[J].北京航空航天大学学报,2021(8):2050-2061.
[7]岳衡,黄晓明,林明辉,等.基于改进YOLOv5的安全帽佩戴检测[J].计算机与现代化,2022(6):104-108,126.
[8]张丽丽,陈真,刘雨轩,等.基于ZYNQ的YOLOv3-SPP实时目标检测系统[J].光学精密工程,2023(4):543-551.
[9]陈伟,江志成,田子建,等.基于YOLOv8的煤矿井下人员不安全动作检测算法[EB/OL].(2024-03-25)[2024-07-11].http://kns.cnki.net/kcms/detail/11.2402.td.20240322.1343.003.html.
[10]曹雨淇,徐慧英,朱信忠,等.基于YOLOv8改进的打架斗殴行为识别算法:EFD-YOLO[EB/OL].(2024-01-26)[2024-07-11].http://kns.cnki.net/kcms/detail/43.1258.TP.20240126.0819.002.html.
(编辑 王雪芬)
Detection algorithm for wearing safety helmet undermine based on improved ED-YOLOv5s
GUO Yunfei, HOU Yanwen, TAO Hongjing
(College of Coal Engineering, Shanxi Datong University, Datong 037000, China)
Abstract: Wearing a helmet in underground coal mine is a key factor concerning the safety of workers. Although the video image analysis technology can better detect the helmet wearing of workers to minimize the damage caused by accidents, there are often various realistic factors in the image collection process under the mine, such as complex environment and multiple targets. These problems will cause a lot of interference to the technicians. To address the above problems, this study proposed an improved ED-YOLOv5s model by introducing the EMA attention mechanism with the DIoU loss function. In this paper, we conducted ablation experiments on CUMT-HelmeT dataset, and the results show that it is greatly improved in image detection speed and accuracy compared with the original model. After comparing the algorithm with YOLOv7-tiny and YOLOv8, result display that the mAP@50% is 97.3%
Key words: image analysis; YOLOv5s; EMA; DIoU
