
基于决策树算法的电子通信网络数据流冗余消除方法
2024-11-12 00:00宋坚
无线互联科技 2024年19期





摘要:现有的消除方法在消除数据流冗余数据时,空间缩减比例过低,导致消除效果不理想。针对这一问题,文章引入决策树算法,设计了新的电子通信网络数据流冗余消除方法。在对电子通信网络数据进行集成处理后,文章利用决策树算法,对电子通信网络数据流进行分类。然后,结合相同类别数据的相似度计算结果,文章对数据流中的冗余数据进行了迭代消除。实验表明:应用新方法后,电子通信网络数据流空间缩减比例显著提升,说明新方法的消除效果更理想。
关键词:决策树算法;冗余消除;数据流;电子通信
中图分类号:TP536.5 文献标志码:A
0 引言
当前,电子通信网络中的数据流量呈爆炸性增长。在这一背景下,数据流的冗余问题越发凸显,它不仅占据了大量的存储空间和传输带宽,还增加了数据处理的复杂性和成本。因此,有效地消除电子通信网络中的数据流冗余,成了当前研究的重要课题。
余锦河等[1]利用人工神经网络算法,对用电信息传输冗余量消除进行了仿真。该方法在一定程度上能够减少数据冗余,提高数据传输和处理的效率。然而,该方法基于固定算法模型,难以适应复杂多变的电子通信网络环境。特别是在面对海量的、多样化的数据时,难以准确地识别和处理数据流中的冗余数据。张淑清等[2]基于哈希计算,提出了一种大数据冗余消除算法。该方法虽然能有效消除冗余数据并提高数据可用性,但哈希计算对噪声和缺失数据非常敏感,这可能导致在客户终端数据预处理阶段出现不稳定的情况。
决策树算法作为一种典型的分类方法,具有直观易懂、易于实现和扩展性强的特点。决策树算法可以自动地学习数据中的特征和规律,从而实现对数据流中冗余数据的准确识别和处理。因此,为了解决上述问题,笔者提出了一种基于决策树算法的电子通信网络数据流冗余消除方法。
1 电子通信网络数据集成与预处理
为便于后续的统一管理和分析,笔者针对电子通信网络数据开展集成处理。在这一过程中,笔者采用数据仓库法来高效地集成这些数据[3]。笔者通过“Extract”功能从电子通信网络中抽取数据,之后,通过“Transform”功能对抽取出的数据进行格式转换和清洗,确保数据的一致性和准确性,再通过“Load”功能将数据加载到数据仓库中[4]。
为减少随后的多余数据寻找和排除的困难,对集成后的电子通信网络数据进行预处理显得尤为重要。预处理一般可分为特征类别与数值类别2种。
(1)字符类数据通常包括文本、标签、描述等,须要对这些数据进行清mX7PW+wa59e0EhlpI/teXg==洗、去重、标准化等操作[5]。笔者使用正则表达式去除文本中的无关字符或特殊符号后,将文本转换为统一的格式。
(2)在数值类数据的预处理阶段,笔者对这些数据进行缺失值填充、异常值检测与处理、数据标准化等操作。对于缺失值,可以使用均值、中位数或插值法进行填充;对于异常值,可以使用统计方法或机器学习算法进行检测和处理[6];数据标准化则可以通过公式将数据转换为统一尺度,便于后续分析。
对于缺失值的填补,其计算公式如式(1)所示。
ai=(a1+a2+…+an)/n(1)
其中,ai表示缺失数据;a1、a2、…、an表示序列中除缺失值以外的所有值;n表示缺失值所在序列长度。经过标准化处理后,使得不同特征之间的比较更加公平和有效。
2 基于决策树算法的电子通信网络数据流分类
在处理电子通信网络数据流分类和冗余消除时,直接计算所有数据之间的相似度往往会导致巨大的计算量和较低的工作效率。为了优化这一过程,笔者采用决策树方法对来自电信网络的海量数据进行分类,以减少后续去冗工作的复杂性与困难。
笔者选取了ID3决策树算法进行聚类分析。ID3算法会遍历数据集中的所有属性,计算每个属性作为分裂点时的信息增益[7]。信息增益反映了按照某个属性进行分裂后,数据集纯度提升的程度[8],其计算公式如式(2)所示。
G(S,A)=En(S)-∑VValues(A)|Sv||S|En(Sv)(2)
其中,G(S,A)表示信息增益;S表示待分裂的数据集;A表示候选分裂属性;Values(A)表示A属性的所有可能取值;Sv表示数据集S中属性A取值为v的样本子集;En(S)表示数据集S的熵。在公式中,En(S)用于度量数据集的不纯度,计算公式如式(3)所示。
En(S)=-∑mi=1pilog2pi(3)
其中,m表示数据集中类别数量;pi表示第i个类别在数据集中出现的概率。通过计算信息增益,ID3决策树算法能够选择出最佳分裂属性,据此构建决策树的分裂规则[9]。以此,可以先将数据流中的数据按照这些规则进行分类,然后在分类后的数据集中进行冗余消除,从而大大提高工作效率和准确性。
结合上述ID3算法,建立决策树,具体步骤为:
第1步,设定初始信息增益阈值ε;
第2步,假设有m个训练样本,每个样本包含n个属性(特征)和1个类别标签;
第3步,初始化一个节点作为根节点,准备开始构建决策树;
第4步,如果根节点下的所有样本都属于同一类别C,算法运算结束后,把根节点标记成叶子,然后把它的分类设定为C;
第5步,遍历样本的n个属性,对于每个属性A,根据公式(2),计算其信息增益G(S,A),将信息增益最大的属性选为当前节点的拆分属性,其中,S是样本集;
第6步,如果当前节点是根节点且选定的分裂属性的信息增益小于阈值ε,则返回第3步。否则,继续下一步;
第7步,对所选分割属性的每一个可能的取值v,从当前节点延伸出相应的分支。将当前节点下的样本按照分裂属性的取值划分到不同的分支中;
第8步,对于每个非树叶节点,重复第3步至第7步,递归地构建其子树。当所有节点都被标记为树叶节点或达到其他停止条件时,算法终止,得到一棵完整的决策树[10]。
第19期2024年10月无线互联科技·电子通信 No.19October,2024
第19期2024年10月无线互联科技·电子通信 No.19October,2024
利用构建的决策树,完成对电子通信网络数据流的分类处理。
3 数据流冗余数据迭代消除
结合决策树分类结果,计算相同类别中数据的相似度,根据计算结果实现对冗余数据的迭代消除。类间相似度的计算公式为:
S(i,j)=φ∑mi,j=1log2(Yki-Ykj)(4)
其中,S(i,j)表示数据i和数据j之间的相似度;φ表示计算因子;Yki、Ykj表示在k类样本中数据i、j的哈希值。将得到的计算结果S(i,j)与判别阈值W进行对比,判断数据流中的数据是否为冗余数据:若S(i,j)>W,则认为该数据为冗余数据,将其消除;反之,若S(i,j)≤W,则认为该数据不是冗余数据。
4 对比实验
为了验证上述方法的实际应用效果,笔者设计了如下实验。
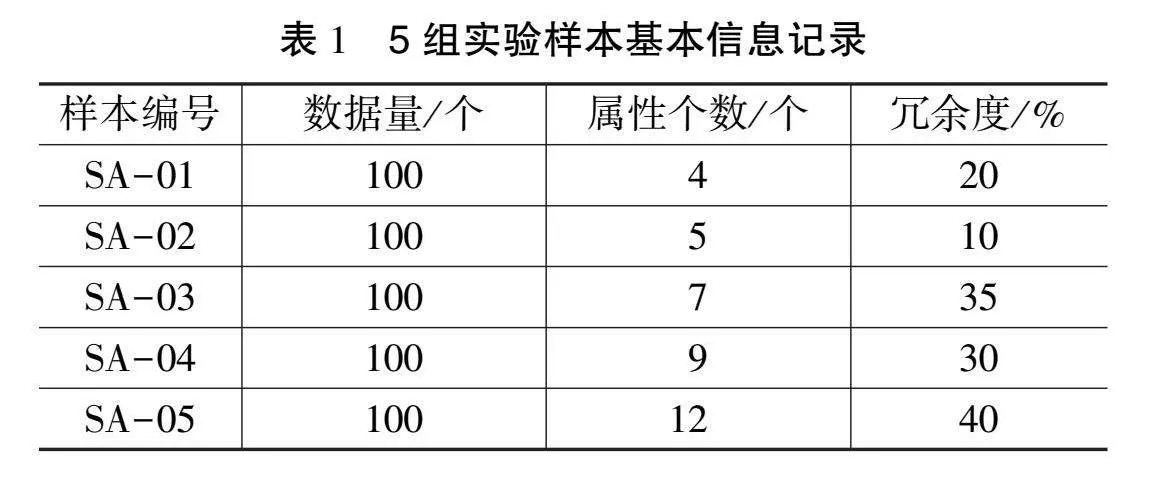
将余锦河等[1]方法设置为对照A组,将张淑清等[2]方法设置为对照B组,将文章上述基于决策树算法的方法设置为实验组,利用3种消除方法,在相同实验环境中对电子通信网络数据流的冗余进行消除。通过对比消除效果,实现对3种方法应用性能的对比。按照表1所示,设置5组实验样本。
从表1中的内容可以看出,5组样本数据量相同,均为100个,属性和冗余度均不相同。在利用3种方法完成冗余消除后,将空间缩减比例作为评价冗余消除效果的量化指标,空间缩减比例的计算如式(5)所示。
L=e/E(5)
其中,L表示空间缩减比例;e表示删除的冗余部分数据量;E表示样本的数据总量。空间缩减比例越高,说明冗余消除的效果越好,即消除的冗余数据越多,节省的存储空间或数据体积越大。
3种方法的空间缩减比例如表2所示。
在对比的5组数据样本中,实验组方法展现出了显著的优势,其空间缩减比例在每组数据中都达到了最高水平,这一表现不仅证明了该方法的有效性,更凸显了其在处理电子通信网络数据流冗余方面的优越性。实验组的空间缩减比例的具体取值稳定地落在 24.0%至36.0%的范围内。这一区间不仅体现了该方法在冗余消除上的稳定性能,也显示了其对于不同类型或规模的数据流都能保持较高的处理效率。而对照A组和对照B组的空间缩减比例均位于10.0%至23.0%的范围内,明显低于实验组。这一对比结果不仅进一步强调了实验组方法的优势,也反映出其他2种对照方法在冗余消除效果上的局限性。
5 结语
笔者提出的基于决策树算法的电子通信网络数据流冗余消除方法,为电子通信网络中的数据流冗余问题提供了新的解决方案。该方法不仅能够准确地识别和处理数据流中的冗余数据,还能够适应不同的网络环境和数据类型,具有广阔的应用前景。
随着电子通信网络的不断发展和数据量的不断增长,数据流冗余消除将面临更加复杂和严峻的挑战。因此,须要进一步研究和探索更加高效、准确和智能的数据流冗余消除方法,为电子通信网络的发展提供有力的支持。同时,也须要关注数据流冗余消除技术的安全性和隐私保护问题,确保数据流在传输和处理过程中的安全性和隐私性。
参考文献
[1]余锦河,刘虎,张才俊.基于人工神经网络算法的用电信息传输冗余量消除仿真[J].电子设计工程,2023(23):54-57,62.
[2]张淑清.基于哈希计算的大数据冗余消除算法设计[J].微型电脑应用,2021(12):68-70.
[3]张莉,丁毛毛,李玮,等.基于决策树算法的客服终端冗余数据迭代消除方法[J].计算技术与自动化,2022(4):118-122.
[4]张翼英,王德龙,渠慧颖,等.面向不平衡数据和特征冗余的网络入侵检测[J].天津科技大学学报,2023(5):57-63.
[5]郭勤,曾辉,李慧玲.基于数据驱动的光纤网络冗余节点状态调度方法[J].激光杂志,2023(10):162-166.
[6]谢绒娜,范晓楠,李苏浙,等.基于标签的数据流转控制策略冗余与冲突检测方法[J].网络与信息安全学报,2023(5):21-32.
[7]张霖,张媛媛,刘星.一种最小化网络能耗的冗余消除路由策略[J].首都师范大学学报(自然科学版),2023(5):37-40.
[8]陈润星,刘杰,李龙杰,等.基于HWD32F429的主从冗余数据记录系统的设计[J].电脑知识与技术,2024(2):43-46.
[9]高文昀,戴胜,涂丽萍,等.基于冗余数据消除的不平衡样本加权支持向量机方法研究[J].长江信息通信,2022(1):46-50.
[10]俞立平,舒光美.一种期刊评价指标数据冗余消除法:独立信息测度[J].现代情报,2023(5):114-122,167.
(编辑 王永超)
Electronic communication network based on decision tree algorithm
SONG Jian
(Fuzhou Polytechnic, Fuzhou 350108, China)
Abstract: The existing elimination methods have a low spatial reduction ratio when eliminating redundant data in data streams, resulting in unsatisfactory elimination effects. In response to this issue, the author introduces the decision tree algorithm and designs a new method for eliminating data stream redundancy in electronic communication networks. After integrating and processing electronic communication network data, the author uses decision tree algorithm to classify the electronic communication network data flow. Then, based on the similarity calculation results of data in the same category, the author iteratively eliminates redundant data in the data stream. The experiment shows that after applying the new method, the reduction ratio of data flow space in electronic communication networks is significantly improved, indicating that the elimination effect of the new method is more ideal.
Key words: decision tree algorithm; redundancy elimination; data flow; electronic communication
