
基于改进可微分域转换的双域锥束计算机断层扫描重建网络用于锥角伪影校正
2024-11-03 00:00:00彭声旺王永波边兆英马建华黄静
南方医科大学学报 2024年6期
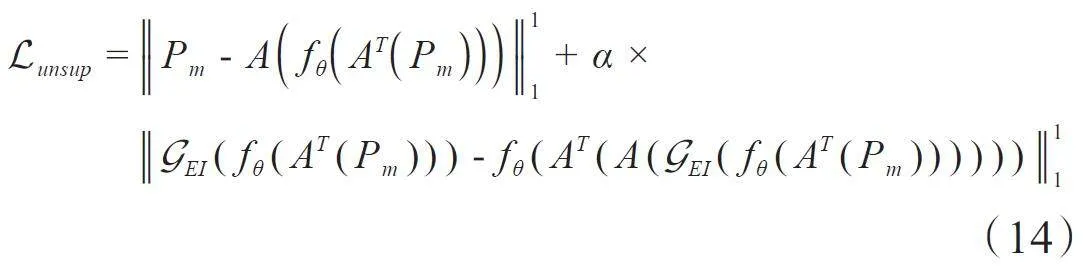

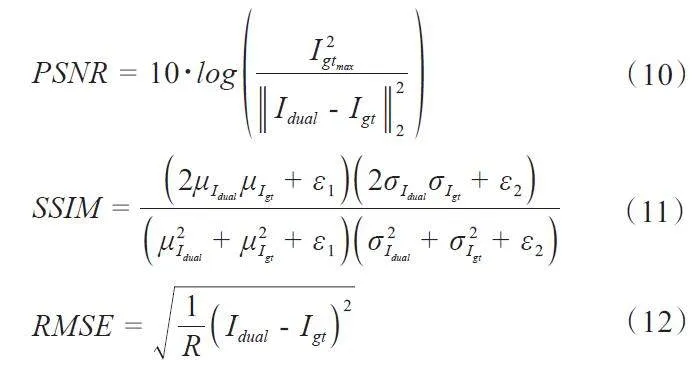
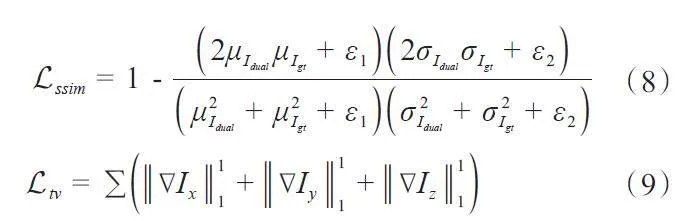
摘要:目的 提出一种基于改进可微分域转换的双域锥束计算机断层扫描(CBCT)重建框架DualCBR-Net用于锥角伪影校正。方法 所提出的双域CBCT重建框架DualCBR-Net包含3个模块:投影域预处理、可微分域转换和图像后处理。投影域预处理模块首先对投影数据进行排方向扩充,使被扫描物体能够被X射线完全覆盖。可微分域转换模块引入重建和前投影算子去完成双域网络的前向和梯度回传过程,其中几何参数对应扩大的数据维度,扩大几何在网络前向过程中提供了重要先验信息,在反向过程中保证了回传梯度的精度,使得锥角区域的数据学习更为精准。图像域后处理模块对域转换后的图像进一步微调以去除残留伪影和噪声。结果 在Mayo公开的胸部数据集上进行的验证实验结果显示,本研究提出的DualCBR-Net在伪影去除和结构细节保持方面均优于其他竞争方法;定量上,这种DualCBR-Net 方法在PSNR和SSIM上相对于最新方法分别提高了0.6479和0.0074。结论 本研究提出的基于改进可微分域转换的双域CBCT重建框架DualCBR-Net用于锥角伪影校正方法使有效联合训练CBCT双域网络成为可能,尤其是对于大锥角区域。。
关键词:CBCT;锥角伪影;可微分域转换
平板探测器的技术进步使锥束计算机断层扫描(CBCT)系统能够在单台旋转中实现大体积覆盖,可以满足各种诊断成像任务,如图像引导放射治疗[1],心脏成像[2]和牙科成像[3]。在CBCT中,FDK算法[4]是最主流的重建算法。而随着锥角的增加,重建图像纵向距离也随之增加,FDK重建算法产生的锥角伪影也随之加剧。受平板探测器尺寸的限制,扫描物体一般无法被X射线完全覆盖,导致获得的投影数据欠采样,其有效重建体素主要集中在360度全扫描区域,扫描不足360度的区域无法被准确重建。位于离圆源轨迹中心平面较远的切片通常表现为强度下降,受到锥角伪影的严重影响。锥角过大给CBCT系统带来的问题主要是由于不满足Tuy数据充分性条件[5]而在高衰减物质周围产生条状锥角伪影,以及由于探测器排方向欠采样导致纵向有效重建体素不足,两端图像反投影值累加不足而引起的阴影状锥角伪影。
既往研究提出各种方法来解决锥角伪影问题,包括解析重建方法[6-9]、估计缺失数据方法[10, 11]和迭代估计方法[12, 13],但均都无法在影去除效果和节省内存开销之间保持平衡。近年来,深度学习技术在医学成像方面应用广泛,其中包括锥角伪影校正技术。然而,现有的用于锥角伪影校正的深度学习方法大多是基于图像后处理[14, 15],没有考虑投影数据到图像数据的重建过程,导致很难兼顾伪影去除和图像细节结构保持,尤其是对于重建过程中丢失的信息。因此必须考虑双域重建网络,同时处理投影域和图像域数据,以去除锥角伪影。
在设计双域重建网络时,投影域和图像域之间的梯度回传精度是个需要重点考虑的问题。主流的CT域转换策略可以分为两类[16]:一类是学习型域转换[17, 18],通过学习双域之间端到端的映射参数,能够保证梯度回传的准确度,但当适配到CBCT重建问题时,学习型域转换需要学习的参数量非常庞大,因此难以应用于CBCT的域转换场景;另一类策略是依赖物理成像过程指导的传统型域转换[19-21],它固定双域间的映射参数,引入重建算子和前投影算子来分别实时计算前向和反向过程,从而构建一种可微分的域转换模块。传统型域转换策略不需要学习双域之间的映射参数,需要更新的参数集中在双域子网络中,因此适用于CBCT的域转换问题。但由于探测器尺寸的限制,在扫描过程中锥束X射线无法完全覆盖目标区域,这将导致使用传统型域转换方式时双域网络参数学习会产生较大误差,从而降低了模型的鲁棒性,限制了其进一步应用。
针对上述问题,本研究提出一种基于改进可微分域转换的双域CBCT重建框架DualCBR-Net,旨在解决由于投影数据在探测器排方向欠采样导致的锥角伪影问题,从而扩大图像在纵向的重建体素范围,有效提高剂量利用率。本研究为该领域内首次提出用于CBCT的双域联合学习框架,未来可在此框架的基础上开展对CBCT成像的其他相关研究,现报道如下。
1 材料和方法
1.1 总体框架
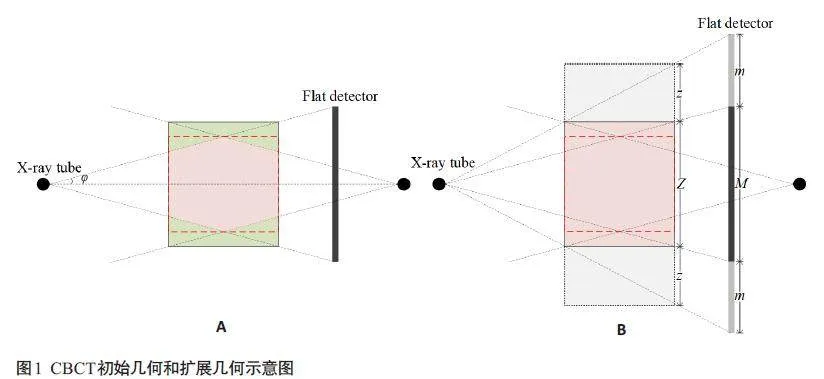
由于实际应用中CBCT探测器排数的限制,一般被扫描物体不能完全被X射线所覆盖,探测器因此采集得到欠采样的投影数据,导致使用FDK重建算法得到的图像中远离中心平面的图层因反投影值累加不足而形成锥角伪影。在锥束扫描过程中,粉红色区域中的每个像素始终在360°范围内被照射,这也是可以被FDK算法重建且无图像强度下降的区域,而绿色区域中的像素被照射范围不足360°,不满足数据完备性的要求,无法被准确重建,导致对应两端图像出现锥角伪影(图1)。针对锥角伪影问题,本文提出了一种基于改进可微分域转换的双域CBCT重建框架DualCBR-Net。该双域CBCT重建框架DualCBR-Net 的结构由投影域前处理模块、可微分域转换模块和图像域后处理模块组成(图2)。
1.1.1 投影域前处理模块
投影域前处理模块包含2个子网络,分别是投影外扩网络(PENet)和投影恢复网络(PRNet)。给定投影数据P ∈ RM × C × A,其中M是初始投影数据的排数,C是探测器通道数,A 是扫描角度数,PENet旨在插值出投影排方向两端的m排像素,从而得到外扩后的投影数据P† ∈ R(M + 2m) × C × A。对于PENet,本研究采用文献[22]中的WGAN-VGG生成对抗网络模型,其中生成器的目标是学习原始排数的2D 投影图像P2D ∈ RM × C到多排2D投影图像P2D + ∈ R(M + 2m) × C的生成过程,判别器的任务是用来评估生成器所生成图像的质量和逼真度,以指导生成器达到更好的外扩图像预测性能。通过整合所有角度下生成的2D 投影图像{ P12D +,P22D +,…,PA2D +},最终得到完整的3D外扩投影图像P†。通过投影外扩,CBCT成像几何在数据层面上进行了扩展(图1A~B)。PENet的目标函数是最小化预测的多排投影数据和真值多排投影数据之间的误差损失,其中损失函数和超参数设置与原始工作保持一致。对于PENet,本研究使用了预训练策略,在整体框架DualCBR-Net训练过程中冻结其网络参数。
本研究在PENet之后还设计了一个投影恢复网络PRNet,其以2.5D UNet[23]作为骨干网络,以提高外扩投影的预测精度,提升模型的去伪影性能。由于锥束几何形状的特殊性,为了完成后续的重建,在批处理时需要保留CBCT投影数据的原始尺寸。本研究在PRNet中分别引入了空间注意模块和通道注意模块[24]。空间注意模块通过学习空间权值来关注CBCT投影数据中的重要区域。通道关注模块通过学习通道间的权值,使网络自动选择并关注最有价值的通道信息来进行图像恢复任务,减少冗余信息的处理,提高网络的学习效率,从而提高模型的性能。
经过PENet外扩后的投影数据P†输入PRNet得到进一步恢复,得到恢复后的外扩投影数据P‡。本研究将投影域前处理模块表示为fproj,fproj的目标是学习原始投影数据到多排投影数据之间的映射,该过程可表示为:
P‡ = fproj (P) (1)
1.1.2 可微分域转换模块
本研究设计了一种改进的可微分域转换模块来完成投影域到图像域的转换。对于锥束几何,常见的重建算法是FDK算法,该算法通过假设目标物体在z方向上有不变性,扩展了二维扇形束滤波反投影算法。FDK算法可以表示为:
I * = AT∙C∙Wcos (P‡ ) (2)
其中Wcos表示投影数据P‡根据当前射线与主射线之间夹角的二维余弦加权函数,C表示滤波算子,AT为具有距离加权函数的三维反投影算子,该三维反投影算子的转置就是前投影算子A。重建算子和前投影算子可以完全表示为离散线性代数,重建算子映射到域转换模块即对应模型的前向过程,利用前投影算子计算对输入的导数,完成梯度回传过程,从而使得双域网络模型在深度学习框架中能够通过标准的反向传播算法直接优化双域子网络的参数。本研究将来自图像域的梯度表示为Gradout,回传到投影域的梯度表示为Gradin,二者之间的转换过程可以表示为:
Gradin = A∙Gradout (3)
通过设计可微分域转换模块,一个完全端到端可训练的CBCT双域网络得以实现,且无需存储大量可学习参数。该可微分域转换模块中使用的几何参数对应于外扩后的数据维度,这保证了目标区域对应的梯度在反向传播时的准确性。得益于外扩后的投影数据中重要的先验知识,网络可以在前向过程中重建出质量更好的图像(图1B)。在反向过程中,因有足够的锥束几何数据,回传梯度的精度大大提高,特别是对于大锥角区域。基于改进的可微分域转换模块,所提出的DualCBR-Net可以准确地更新双域子网络中的参数,这对CBCT锥角伪影校正问题至关重要。
1.1.3 图像域后处理模块
对于重建的CBCT图像I *,希望通过将I *输入到图像域后处理模块,进一步去除残留的噪声和伪影,本研究在图像域后处理模块中设计了一个基于2.5D UNet 骨干网络的图像恢复网络(IRNet),在批处理过程中,未将所有的CBCT图像轴向切片都输入到IRNet中,而是在每次迭代中随机选择一部分连续的2D切片来输入,通过不停地迭代训练,网络能够间接地接触到整个3D图像数据的特征,这里只考虑扫描至少180°范围的区域,即理论上能够被恢复的区域(图1B红色虚线框范围)。将图像后处理模块表示为fimg,fimg 的目标是学习重建图像I * 到参考高质量CBCT图像Igt之间的函数映射,得到模型去伪影后的图像Idual。该过程可以表示为:
Idual = fimg(I * ) (4)
1.1.4 损失函数
DualCBR-Net的整体框架可以用公式表示为:
Idual = fimg( fIDT( fproj (P) )) (5)
其中,fIDT 表示改进的可微分域转换模块。DualCBRNet框架中需要学习的网络参数集中在fproj和fimg中。像素级的均方差损失Limg,图像结构相似度损失Lssim和3D图像总变分正则化项Ltv 构成DualCBR-Net 的联合损失函数:
Ltotal = Limg + α × Lssim + β × Ltv (6)
其中Limg和Lssim在模型输出的去伪影的图像Idual和干净无伪影的图像Igt之间进行计算,Ltv是在Idual上计算的正则化项,具体地:
Limg = || I "dual - Igt||11(7)
其中μ表示均值,σ表示方差,∇Ii表示图像在第i个维度上的梯度,ε1和ε2为超参数,这里我们分别设置为10-4和4×10-4。Lssim是基于一个11×11的窗进行计算的。超参数α和β用来平衡不同损失函数之间的权重,经过扩充验证实验,设置α=0.5,β=0.1。
1.2 实验设计
1.2.1 数据集
本研究使用了来自Mayo 公开数据集Low Dose CT Image and Projection[25]中的胸部数据来进行实验,该数据是使用西门子医疗公司的SomatomDefinition AS+CT 系统在120 kVp 和200 mAs 下扫描获得的。与文献[14]的数据仿真策略类似,本研究使用胸部数据的全剂量图像作为真值图像进行锥束仿真,每个患者的图像尺寸为512×512×300,图像像素为0.75 mm×0.75 mm,层厚为1.5 mm,层数为300。探测器阵列规格为400×512,每个探测器单元大小为1.5 mm×1.5 mm,排数为400,通道数为512。曝光角度设置为360度,射线源到中心的距离为768 mm,射线源到探测器的距离为1280 mm。上述的几何参数在本工作中对应于扩大后的几何,原始几何中的探测器排数为240,重建图像层数为180。另外,仿真所用的真值图像层数为300,最终目标重建层数为180,这对应于前文的Z(图1B),剩余的120层不参与网络训练,只在可微分域转换模块中起过渡作用。本研究共选取了50套患者数据,其中40套作为训练集,10套作为测试集。
1.2.2 实验配套
本实验是在配备有2.10 GHz InterXeon E5-2683 CPU和1块48 GB显存的NVIDIA GPURTX A6000 显卡上进行的。Python 版本为3.8.15,CUDA 版本为12.0,基于1.13.0 版本的Pytorch 框架。其他依赖包均在以上环境下进行安装配置。
本研究中的PRNet在批处理时需要处理全角度的多排投影数据,以便在接下来的域转换模块中完成锥束图像重建。为减轻显存压力以及防止信息丢失,本研究将整体3D投影数据重组为几个图像块并同时输入到网络,在批处理过程中,1 例胸部投影数据的尺寸为1×360×512×400,随后将其重组为尺寸为10×36×512×400的图像块,其中10和36分别对应网络中的batch size和通道。可微分域转换模块中的重建算子和前投影算子分别对应网络的前向过程和梯度反向传播过程,本研究使用ASTRA-Toolbox[26]来实施这两个算子。在IRNet中,采用随机选取连续层的策略,设置每次迭代选取的连续层数为8。采用Adam[27]优化器来执行优化过程,其中动量设置为0.9。总训练轮数为500,batch size 设置为1,即1例病人的投影-图像配对数据。初始学习率设置为2×10-4,每50 个epoch 下降为原来的一半,当下降到1×10-6时不再变化。
1.2.3 对比方法与评估指标
本研究选取WCF方法[11]和WCF-PRNet方法进行对比。WCF为线性插值方法,利用水柱形状,将缺失的投影排方向数据进行插值拟合;WCF-PRNet 方法以WCF 方法插值的数据作为初值,以实现与目标外扩数据在空间维度上的对齐,再利用本文中PRNet的网络结构来实现外扩。
本研究选取经典方法FDK[4]、CWFDK[8]、WCF[11]以及基于深度学习的锥角伪影校正方法FDK-Net[28]、DBP-Net[14]、GADR-Net[15]进行对比,以评估所提出的DualCBR-Net 方法在成像上的性能。CWFDK算法考虑扫描角度和锥束几何之间的关系,利用Parker加权短扫描重建拼接策略[29]获得完整图像,本研究选取的短扫描角度为20°。WCF方法直接利用FDK算法对插值后的投影进行重建。FDK-Net是一个端到端的去伪影模型,利用FDK算法重建的图像与真值图像进行配对训练。DBP-Net在差分反投影域上解决问题,以执行与希尔伯特变换相关的不适定反卷积问题的数据驱动反演,并使用冠状面和矢状面图像进行训练,最终利用光谱混合技术整合冠状面和矢状面的结果以获得重建图像。GADR-Net利用锥角分布和旋转几何之间的关系,并使用从CBCT径向采样的图像切片来训练网络。上述基于深度学习的对比方法均参照原文中的参数设置进行训练和测试。
本研究选取峰值信噪比(PSNR)、结构相似度指数(SSIM)和均方根误差(RMSE)3 个指标对所提出方法的性能进行定量评估。PSNR用来对被测量图像进行噪声评估,SSIM用来评估被测试图像与真值图像之间的纹理相似度,RMSE用来评估被测试图像与真值图像之间的误差。上述3个指标的计算公式为:
其中,Igtmax表示Igt中的最大值,R为图像中的总像素数,SSIM中的定义与公式(8)类似。
2 结果
2.1 不同方法投影外扩的结果
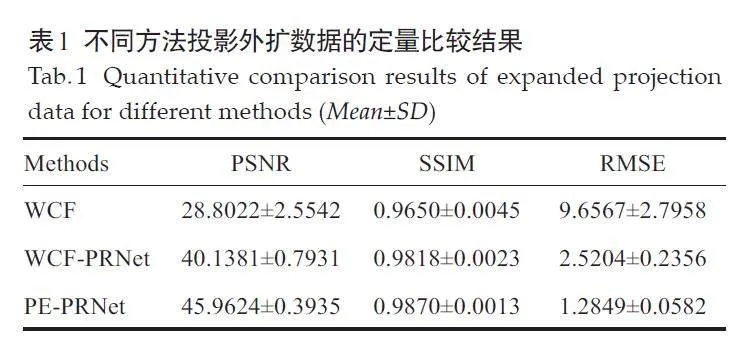
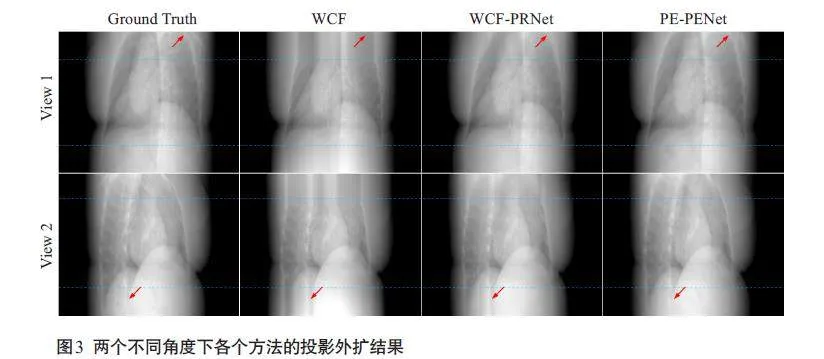
WCF 方法得到的结果与真实数据存在明显偏差(图3)。WCF-PRNet方法得到的结果与真实投影数据的相似度有所提高,但是存在过模糊等现象。本研究提出的PE-PRNet方法的外扩数据结果获得了与真实投影数据最接近的分布,尤其是在细节纹理和整体真实感上。各个方法在投影外扩结果与真实数据之间的定量指标显示,本研究的方法在PSNR、SSIM和RMSE上均为最优(表1)。
2.2 重建结果分析
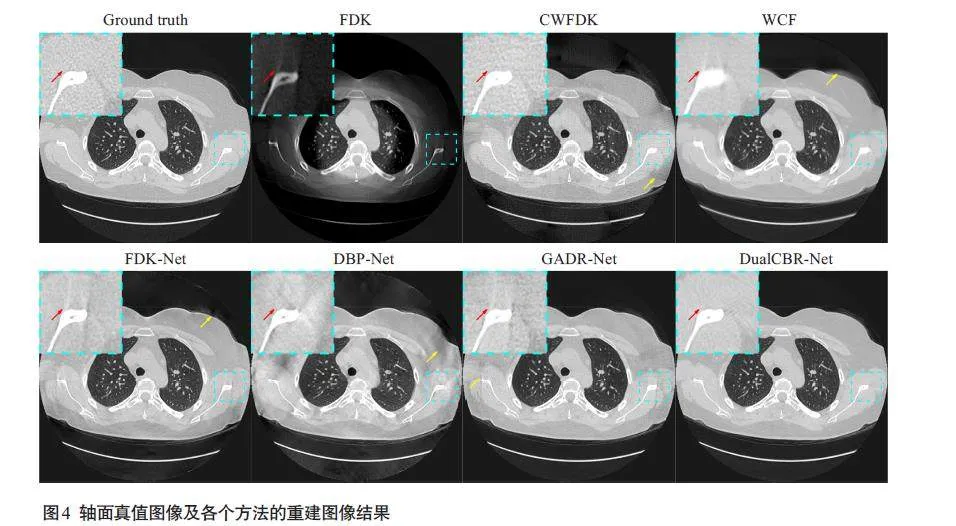
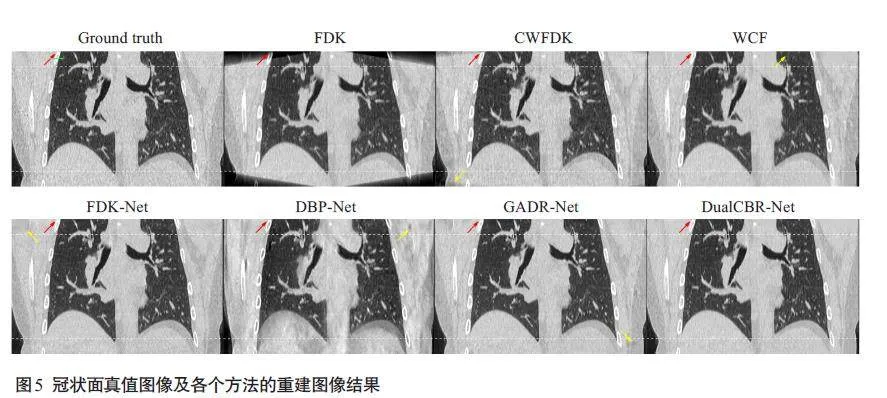
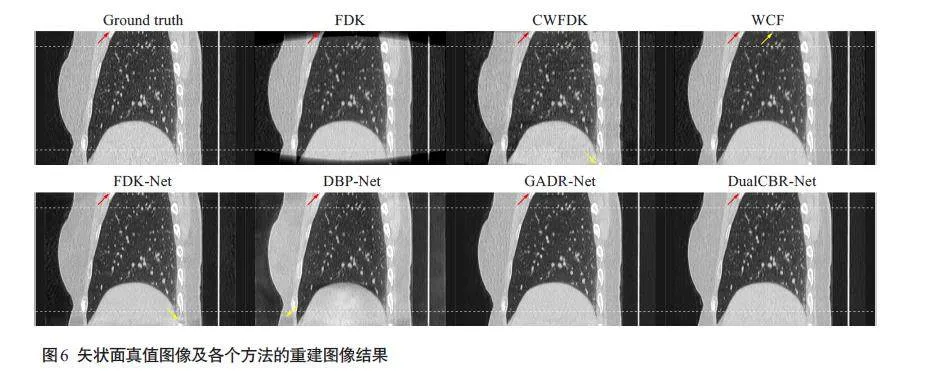
DualCBR-Net 得到的轴向、冠状和矢状平面切片的重建结果显示,FDK方法的重建图像在纵向两端区域的质量因锥角影响而严重受损,细节结构丢失。CWFDK方法可以恢复部分图像强度,但在短扫描重建拼接处引入了二次伪影。WCF方法的重建图像中细节结构不真实,引入了本不存在的纹理信息。FDK-Net方法的重建图像仍然存在残留伪影,且丢失了部分细节结构和纹理信息。DBP-Net方法的重建图像较为模糊,细节结构丢失较严重。GADR-Net方法取得了较好的重建效果,但在保留图像结构和纹理方面仍然不够出色。与上述方法相比,本研究所提出的DualCBR-Net 方法在去除伪影的同时,还能有效保留图像中的细节结果和纹理信息(图4~6)。
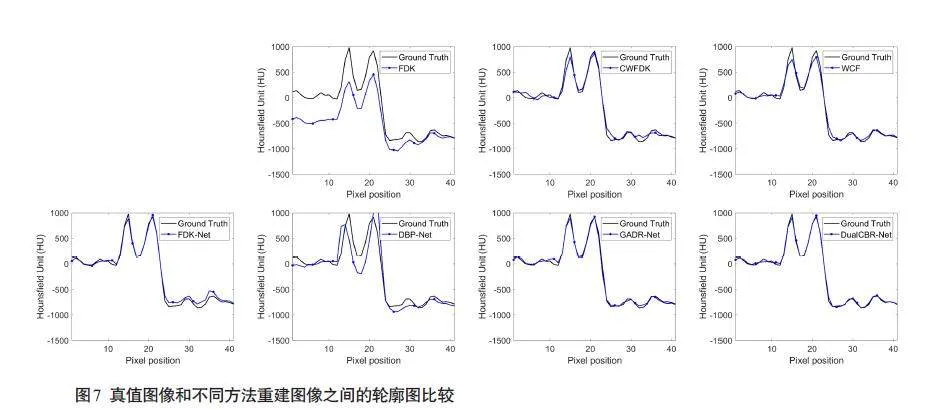
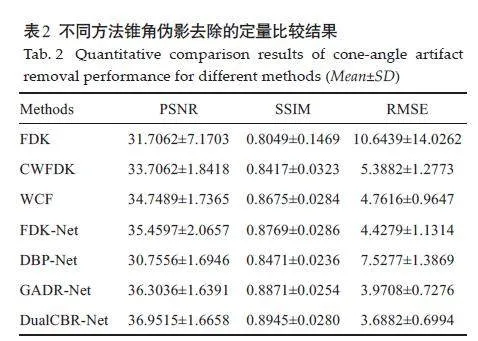
重建结果(图5)中绿色直线标记位置的水平剖面线显示,与对比方法相比,本研究所提出的 DualCBRNet方法的重建结果更接近真值图像(图7)。定量评价结果显示所提出的DualCBR-Net方法取得了最高的 PSNR指标(36.9515±1.6658)、最高的SSIM 指标(0.8945±0.0280)和最低的 RMSE指标(3.6882±0.6994,表2)。
2.3 消融实验结果
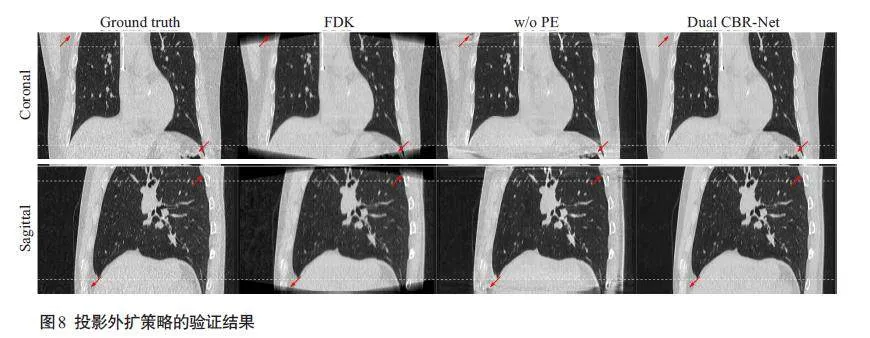
2.3.1 投影外扩策略验证
在没有使用投影外扩策略的重建结果中,无论是冠状面还是矢状面,都有残留的锥角伪影,且图像细节丢失严重(图8)。通过引入投影外扩策略,目标区域的图像得到了很好的恢复,在锥角伪影去除的同时还保留了细节结构信息。
2.3.2 模型组件消融学习
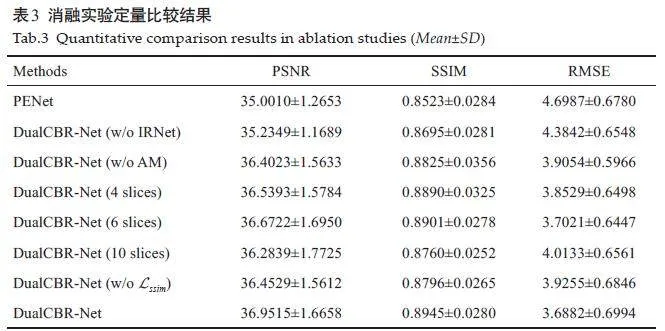
DualCBR-Net中的模型组件消融实验定量比较结果显示,所提出的DualCBR-Net总是取得了比其他消融模块更好的结果(表3)。
3 讨论
针对CBCT探测器尺寸限制而导致的图像纵向有效重建体素不足,轴向两端出现锥角伪影的问题,本研究提出了一种基于改进可微分域转换的双域 CBCT 重建框架DualCBR-Net,来进行锥角伪影校正。DualCBR-Net 由3 个模块组成:投影域预处理、可微分域转换和图像域后处理。投影域预处理模块由投影外扩网络PENet和投影恢复网络PRNet组成,它将原始投影数据在探测器排方向上进行外扩,使扫描物体能够完全被X射线覆盖。然后,可微分域转换模块引入FDK重建和前向投影算子来完成前向过程和梯度反向传播,其中使用的几何参数对应于扩大的数据维度,扩大几何在网络前向过程中提供了重要先验信息,在反向过程中保证了回传梯度的精度,使得锥角区域的数据学习更为精准。图像后处理模块包含一个图像恢复网络IRNet,以进一步微调域转换后的图像以去除残留伪影和噪声。像素级的均方差损失,图像结构相似度损失和3D图像总变分正则化项构成DualCBR-Net 的联合损失函数,使得模型在去除锥角伪影的同时能够保留图像细节结构信息,从而重建出无锥角伪影的高质量CBCT图像。
本研究在Mayo 公开的胸部数据集上验证和评估了所提出的DualCBR-Net方法,从重建结果来看,加权解析重建方法CWFDK无法平衡计算成本与重建效果,且容易导致图像中出现二次伪影;此外,该方法还因需要多次短扫描重建操作而受到进一步限制。参考简单水柱形状作为先验知识来扩充投影数据的WCF方法无法准确获得真实的投影结构分布信息,会在重建图像中引入本不存在的结构。FDK-Net重建结果出现过模糊,且出现残留伪影,这是因为仅使用像素级均方差损失是很难学习从解析重建结果到真实图像间的映射的。DBP-Net重建结果与原文差异较大,其原因可能是由于锥角过大导致差分反投影域中存在过多缺失数据所致,在训练网络时下降的图像强度对模型学习产生了负面影响。GADR-Net可以去除大部分伪影,但是在细节结构保持方面仍然不够出色。与上述方法相比,无论是定性还是定量方面,所提出的 DualCBR-Net 方法在伪影去除和结构细节保留方面均要更为优异。在消融实验结果中,没有投影外扩策略意味着,域转换模块中使用的前反投影算子都是基于原始几何,因此在前反投影过程中都存在着欠采样数据导致域转换精度下降的问题。在验证结果中可以观察发现,没有使用该策略的结果中都都有残留的伪影,且图像细节丢失严重,通过引入投影外扩策略,网络的前向过程可以基于外扩的投影数据更好地重建图像,反向过程由于使用了扩大几何,目标区域对应的回传梯度更为精准,因此双域网络在目标函数的约束下能够更好地学习,模型的去伪影性能也会更好,这证明了所提出的投影外扩策略对于模型的前向和反向过程都是有益的。模型组件消融实验定量结果中,所提出的方法总是取得比其他模块更好的指标,因此模型各个组成部分及其参数设置都是合理且最优的。
对于CBCT锥角伪影问题,现有的基于深度学习的解决方法大多是图像后处理[14,15],这主要受限于3D成像几何的复杂性带来的高昂的计算成本。与仅在图像域做图像恢复的方法相比,双域网络方法可以充分利用投影域的信息,并发挥图像域先验知识的作用,在恢复细微结构和减少伪影方面相较于单域处理展现了更卓越的性能[30,31],因此更适合CBCT锥角伪影校正问题。有学者曾提出适用于CBCT的双域成像模型DualCNN,该模型分别在投影域进行插值以及在图像域进行恢复,域转换使用了FDK算法,但是该设计中域转换是不可微的,投影域和图像域的数据分离处理,通过级联方式构成了双域网络,因而在深度学习框架中无法通过标准的反向传播算法直接优化双域子网络的参数,构建成一种“伪”双域网络[32]。考虑到复杂度与计算成本问题,本研究引入了传统型域转换方式,使得CBCT双域网络联合训练,同步更新参数成为可能,而针对CBCT传统型双域转换梯度回传不准确的问题,本研究提出了一种基于改进可微域变换的双域CBCT 重建框架DualCBRNet,有效提高了双域网络的学习精度,为关于CBCT双域网络的其他研究提供了思路。DualCBR-Net中关键的一点是投影外扩操作,通过在投影排方向插值处理,使得目标重建区域在数据维度上能够被X射线完全覆盖,这对于依赖物理成像模型的传统型域转换方法是至关重要的。
本研究的优势在于:提出了适用于CBCT的双域重建框架DualCBR-Net,该框架使用了传统型域转换,其中改进的可微分域转换策略能够有效克服因为成像系统限制导致的域转换精度下降问题,使得CBCT双域网络的联合训练和参数的同步更新成为可能;研究领域内首次进行投影数据排方向外扩任务,这在先验知识有限的条件下具有一定的价值,为域转换模块提供了重要信息;引入像素级的均方差损失,图像结构相似度损失和3D图像总变分正则化项构成DualCBR-Net的联合损失函数,其中图像结构相似度损失能够更好地指导纵向两端强度下降的图像进行伪影恢复。
本研究在未来的工作可从以下方面开展:首先,受限于硬件条件,DualCBR-Net中的投影外扩网络PENet是离线预训练的,即在单角度2D投影数据上逐个进行,这必然会导致投影外扩网络的学习精度降低,因为难以利用相邻角度投影数据之间的结构信息。因此,需要设计一种更加轻量级、高效、能够支持在线训练的投影外扩模块。其次,DualCBR-Net为监督学习方法,非常依赖于高质量的投影图像配对数据,而在真实的临床场景中,获得高质量的CBCT图像数据是非常困难的,其一方面出于成像系统技术难度,另一方面也受伦理道德的约束。在这种情况下,需要探索无监督或半监督学习方法,来克服标签图像的约束。近年来,等变成像(EI)方法[33, 34]已广泛应用于未知真值图像的医学成像问题,可以用于解决标签数据不足的问题,这恰好为未知真值标签的CBCT成像问题提供了思路。EI假设在成像逆问题中,测量数据对应的待重建的原始信号普遍存在低维模型,这些低维模型具有群不变性,从而使得由重建算子和前投影算子构成的整个成像系统具有等变性,因此可以利用这些成像系统中的等变性,来直接从测量数据中学习成像模型中的重建函数。对应到本文中的CBCT成像任务中,即利用等变特性来构建自监督约束,来代替监督学习目标函数中的保真项以及正则化项。这里给出一般监督学习CT成像框架下的目标函数:
Lsup = ||"I "dual - Igt||11+ α × Lregularization (13)
其由保真项和正则化项构成,并由超参数α控制不同损失项的权重。在该监督学习框架下,最重要的是保真项的约束,因此标签图像Igt直接决定了监督成像模型的质量。通过引入等变学习EI方法,可以构建如下的目标函数:
其中,Pm为测量数据(这里可以理解为欠采样的投影数据),fθ为无监督EI成像模型,θ为模型参数,G EI为具有等变性的操作集合,A为前投影算子,AT 为重建算子。通过引入等变学习框架,利用成像系统自身的物理特性和成像过程中的一致性约束,可以克服监督学习方法对高质量标签图像的依赖[35, 36],从而在常见的无医学图像标签数据的情况下发挥作用。后续研究中也将致力于研究等变学习与CBCT成像的结合,探索无监督学习成像新方法。
综上所述,本研究提出了一种基于改进可微分域转换的双域 CBCT 重建框架 DualCBR-Net,来进行锥角伪影校正。该方法采用了一种依赖物理成像过程指导的传统型域转换方式,并聚焦于锥束成像系统限制而导致的域转换精度下降问题,分别在投影域进行插值,在图像域进行恢复,改进可微分域转换模块利用扩展的数据维度,这不仅在网络前向过程中提供了重要的先验信息,也在反向过程中保证了回传梯度的精度,使得锥角区域的数据学习更为精准。实验结果表明所提出的方法在伪影消除和细节保持方面优于其他竞争方法,具有良好临床应用潜力。
参考文献:
[1] Jaffray DA, Siewerdsen JH, Wong JW, et al. Flat-panel cone-beamcomputed tomography for image-guided radiation therapy[J]. Int JRadiat Oncol Biol Phys, 2002, 53(5): 1337-49.
[2] Wang G, Zhao SY, Heuscher D. A knowledge-based cone-beam XrayCT algorithm for dynamic volumetric cardiac imaging[J]. MedPhys, 2002, 29(8): 1807-22.
[3] Pauwels R, Araki K, Siewerdsen JH, et al. Technical aspects ofdental CBCT: state of the art[J]. Dentomaxillofac Radiol, 2015, 44(1): 20140224.
[4] Feldkamp LA, Davis LC, Kress JW. Practical cone-beam algorithm[J]. J Opt Soc Am A, 1984, 1(6): 612.
[5] Tuy HK. An inversion formula for cone-beam reconstruction[J].SIAM J Appl Math, 1983, 43(3): 546-52.
[6] Grass M, Köhler T, Proksa R. Angular weighted hybrid cone-beamCT reconstruction for circular trajectories[J]. Phys Med Biol, 2001,46(6): 1595-610.
[7] Tang X, Hsieh J, Nilsen RA, et al. A three-dimensional-weightedcone beam filtered backprojection (CB-FBP) algorithm for imagereconstruction in volumetric CT-helical scanning[J]. Phys MedBiol, 2006, 51(4): 855-74.
[8] Mori S, Endo M, Komatsu S, et al. A combination-weightedFeldkamp-based reconstruction algorithm for cone-beam CT[J].Phys Med Biol, 2006, 51(16): 3953-65.
[9] Grimmer R, Oelhafen M, Elstrøm U, et al. Cone-beam CT imagereconstruction with extended z range[J]. Med Phys, 2009, 36(7):3363-70.
[10]Zhu L, Starman J, Fahrig R. An efficient estimation method forreducing the axial intensity drop in circular cone-beam CT[J]. Int JBiomed Imaging, 2008: 242841.
[11]Hsieh J, Chao E, Thibault J, et al. A novel reconstruction algorithmto extend the CT scan field-of-view[J]. Med Phys, 2004, 31(9):2385-91.
[12]Hsieh J. Two-pass algorithm for cone-beam reconstruction[C]. SanDiego: Medical Imaging 2000: Image Processing, 2000: 533-40.
[13]Han C, Baek J. Multi-pass approach to reduce cone-beam artifacts ina circular orbit cone-beam CT system[J]. Opt Express, 2019, 27(7):10108-26.
[14]Han Y, Kim J, Ye JC. Differentiated backprojection domain deeplearning for conebeam artifact removal[J]. IEEE Trans MedImaging, 2020, 39(11): 3571-82.
[15]Minnema J, van Eijnatten M, der Sarkissian H, et al. Efficient highcone-angle artifact reduction in circular cone-beam CT using deeplearning with geometry-aware dimension reduction[J]. Phys MedBiol, 2021, 66(13): 135015.
[16]Xia WJ, Shan HM, Wang G, et al. Physics-/ Model-Based and Data-Driven Methods for Low-Dose Computed Tomography: a survey[J]. IEEE Signal Process Mag, 2023, 40(2): 89-100.
[17]He J, Wang YB, Ma JH. Radon inversion via deep learning[J]. IEEETrans Med Imaging, 2020, 39(6): 2076-87.
[18]He J, Chen SL, Zhang H, et al. Downsampled imaging geometricmodeling for accurate CT reconstruction via deep learning[J]. IEEETrans Med Imaging, 2021, 40(11): 2976-85.
[19]Würfl T, Hoffmann M, Christlein V, et al. Deep learning computedtomography: learning projection-domain weights from imagedomain in limited angle problems[J]. IEEE Trans Med Imag, 2018,37(6): 1454-63.
[20]Hu DL, Liu J, Lv TL, et al. Hybrid-domain neural networkprocessing for sparse-view CT reconstruction[J]. IEEE TransRadiat Plasma Med Sci, 2021, 5(1): 88-98.
[21]Zhang YK, Hu DL, Zhao QL, et al. CLEAR: comprehensivelearning enabled adversarial reconstruction for subtle structureenhanced low-dose CT imaging[J]. IEEE Trans Med Imag, 2021, 40(11): 3089-101.
[22]Yang QS, Yan PK, Zhang YB, et al. Low-dose CT image denoisingusing a generative adversarial network with Wasserstein distanceand perceptual loss[J]. IEEE Trans Med Imaging, 2018, 37(6):1348-57.
[23]Ronneberger O, Fischer P, Brox T. U-net: convolutional networksfor biomedical image segmentation[EB/OL]. [2015-05-18]. https://arxiv.org/abs/1505.04597.
[24]Guo MH, Xu TX, Liu JJ, et al. Attention mechanisms in computervision: a survey[J]. Comput Vis Medium, 2022, 8(3): 331-68.
[25]Moen TR, Chen BY, Holmes DR 3rd, et al. Low-dose CT image andprojection dataset[J]. Med Phys, 2021, 48(2): 902-11.
[26] van Aarle W, Palenstijn WJ, De Beenhouwer J, et al. The ASTRAToolbox: a platform for advanced algorithm development in electrontomography[J]. Ultramicroscopy, 2015, 157: 35-47.
[27]Kingma DP, Ba J. Adam: a method for stochastic optimization[EB/OL]. [2014-12-22]. http://arxiv.org/abs/1412.6980
[28] Jin KH, McCann MT, Froustey E, et al. Deep convolutional neuralnetwork for inverse problems in imaging[J]. IEEE Trans ImageProcess, 2017, 26(9): 4509-22.
[29]Parker DL. Optimal short scan convolution reconstruction forfanbeam CT[J]. Med Phys, 1982, 9(2): 254-7.
[30]Lee D, Choi S, Kim HJ. High quality imaging from sparsely sampledcomputed tomography data with deep learning and wavelettransform in various domains[J]. Med Phys, 2019, 46(1): 104-15.
[31]Zhou B, Chen XC, Zhou SK, et al. DuDoDR-Net: dual-domain dataconsistent recurrent network for simultaneous sparse view and metalartifact reduction in computed tomography[J]. Med Image Anal,2022, 75: 102289.
[32]Chao LY, Wang ZW, Zhang HB, et al. Sparse-view cone beam CTreconstruction using dual CNNs in projection domain and imagedomain[J]. Neurocomputing, 2022, 493(7): 536-47.
[33]Chen DD, Tachella J, Davies ME. Equivariant imaging: learningbeyond the range space[C]. Montreal: 2021 IEEE/CVFInternational Conference on Computer Vision, 2021: 4359-68.
[34]Chen DD, Tachella J, Davies ME. Robust Equivariant Imaging: afully unsupervised framework for learning to image from noisy andpartial measurements[C]. New Orleans, 2022 IEEE/CVFConference on Computer Vision and Pattern Recognition, 2022:5637-46.
[35]Peng SW, Liao JY, Li DY, et al. Noise-conscious explicit weightingnetwork for robust low-dose CT imaging[C]. San Diego: MedicalImaging 2023: Physics of Medical Imaging, 2023: 711-8.
[36]Chen J, Zhang R, Yu T, et al. Label-retrieval-augmented diffusionmodels for learning from noisy labels[J]. Adv Neural Inf ProcessSyst, 2024, 36. doi: 10.48550/arXiv.2305.19518
(编辑:郎 朗)
基金项目:国家自然科学基金(U21A6005)
