
基于转导长短时记忆网络的语义解析框架
2024-11-03 00:00:00陈士超
赤峰学院学报·自然科学版 2024年9期



摘 要:语义解析(SP)技术能够帮助用户将自然语言语句转化为结构化的语义表达,从而可以在结构化和半结构化的知识库中进行高效的数据检索。本文提出了一种基于空间注意力的转导长短期记忆网络模型(TLSTM),并将其用于语义解析。这个模型在检测时间序列数据中的微妙时间变化方面表现出优越的能力,超过了传统的LSTM模型。在Wiki SQL数据集上进行测试时,实验数据表明,该模型的表现优于同类模型。
关键词:语义解析;长短时记忆网络;空间注意力;BERT
中图分类号:TP391.1 文献标识码:A 文章编号:1673-260X(2024)09-0012-04
在当今这个数据丰富的环境中,大量的信息被存储在结构化和半结构化的知识库中。对这些信息的查询和利用,往往需要使用诸如SQL之类的形式化查询语言。然而对于普通用户而言,很难在短时间内掌握这类专业的查询语言,这就造成了某种程度的“数字鸿沟”。语义解析[1,2]能够将自然语言语句转化为结构化的语义表达,为这一问题的解决提供了一种现实可能。然而由于人类语言的复杂性,语义解析在实现上遇到了重重困难。
近年来,深度学习技术取得了飞速发展,并应用到语义解析领域,大大提升了语义解析的准确性[3,4],在Wiki SQL[5]等基准测试上的准确率已经超过了80%。在深度学习领域,长短时记忆(LSTM)网络擅长处理序列数据[6],这使得它们特别适合像语义解析[7]这样的时间序列分析任务。LSTM的架构独特,通过“门”调节信息流向和流出记忆单元的流量,具有选择性地保留或忽略时间信息的独特能力,这种设计使它们能够有效地解开序列数据中的长期依赖性,同时保持对较长序列的计算效率,这也是语义解析[8]所需的关键特性。
尽管LSTM在各种序列学习任务中已被证明有效,但标准的LSTM模型通常使用所有可用的训练数据开发全局模型,这可能会忽视特征空间内的特定区域特性。相比之下,TLSTM采用归纳学习方法来解决这个限制。这种新颖的方法根据测试数据的接近程度调整权重,提高了模型在新数据点或以前未见过的数据点周围的性能。将归纳学习与LSTM的优势相结合,转导长短时记忆网络(TLSTM)为时间序列预测提供了更细致、更具上下文敏感性的方法。它巧妙地结合全局和局部的见解,应对复杂的时间序列预测挑战,其中理解局部模式和时间依赖性至关重要[9]。TLSTM网络的有效性在很大程度上取决于大量数据集的可用性。然而,获取如此大规模的数据集往往涉及大量的成本和时间,对TLSTM网络的广泛应用构成挑战。
为解决上述问题,本研究整合了一个基于空间注意力的TLSTM模型,设计了一个语义解析框架,并使用BERT模型进行模型预训练,以捕获更广泛的语言细节。最后基于Wiki SQL数据集与其他同类方法进行比较,以评估其性能。
1 基于转导长短时记忆网络的语义解析框架
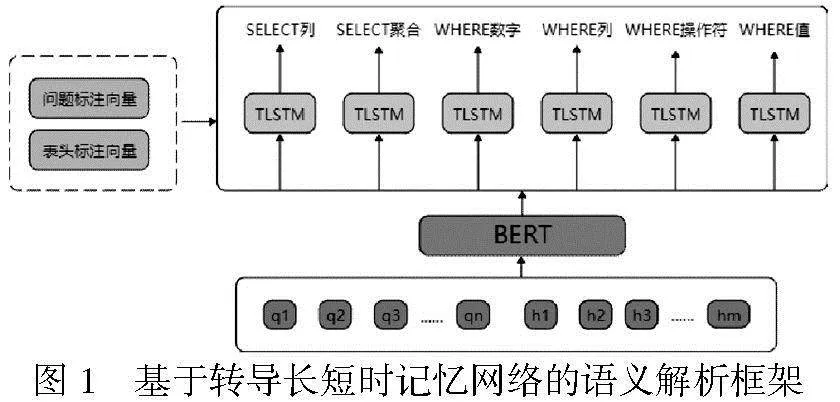
本文提出了一种基于TLSTM的语义解析框架,如图1所示。该框架通过辅助特征向量编码来描述数据,应用增强的TLSTM模型进行语义解析,能对包括SELECT、AGG和WHERE子句在内的SQL语句不同片段进行预测,其中关键组件包括用于精确预测列名称的SELECT列、用于准确确定聚合(agg)槽的SELECT聚合、用于定位Where子句中具体数字或情况的WHERE数字确定、与Where条件关联的列的WHERE列、试图推断在Where子句中使用的操作符的WHERE操作符和重点预测与Where条件对应或交互的值的WHERE值,如图1所示。
2.1 辅助特征向量编码算法
负责数据描述的辅助特征向量编码包括问题标志向量与表头标志向量,这两种向量的具体创建算法为算法1和算法2。
(1)算法1:创建问题的标志向量。
①首先设置一个指示器向量vq,其长度等于问题,所有元素最初都设置为0。
②遍历数据表中的每一列col:检查问题是否包含来自col的文本。
③如果是,找到index,这是问题中首次出现来自col的文本的位置。
④将值2分配给从index开始并扩展到col长度的vq段。
⑤将vp中位于index的元素设置为1。
⑥将值3分配给位于位置index+length的col中的元素的vp。
⑦结束对列的循环。
⑧如果在列中找不到匹配项,则继续检查表头中的每个item。
⑨如果问题包含item,则找到问题中首次出现item的位置index。
⑩更新位于index处的vq为4。
(2)算法2:创建表头的标记向量。
①首先创建一个与查询长度匹配的指标向量vh,将所有元素初始化为0。
②设置一个计数器index为0。
③遍历表头的每个“项目”。
④如果item在查询中找到,将vh中相应的位置(由index指示)设置为1。
⑤每次迭代后,将index增加1。
⑥接下来,遍历表中的每一列col。
⑦如果查询包含col,确定tmp,它表示col在表中的位置。
⑧在vh中将tmp位置标记为2的值。
在算法1中,初始、中间和最终标签分别用值1、2和3表示。从表头和查询得到的向量标记为HV和QV。
2.2 TLSTM
LSTM在语义解析领域引起了相当大的关注,主要是因为它们擅长捕获和利用时间序列数据中固有的时间相关性。与传统的统计方法不同,LSTM独立地学习和适应数据中的复杂模式和相关性,从而提高它们在语义解析任务中的有效性。LSTM网络的一个显著优点是它们能够熟练处理长期依赖性。在语义解析领域,这相当于它们具备识别长时间跨度内的微妙关系和趋势的能力。
LSTM设计了输入门、输出门和遗忘门,用于信息处理。考虑it、ft、ot、ct和ht作为给定时间t的输入、遗忘、输出门、记忆单元和隐藏状态的指示器,xt表示该系统在该时间的输入,LSTM单元的架构可以有如下描述[10]:
it=σ(Wxixt+Whiht-1+Wcict-1+bi)(1)
ft=σ(Wxfxt+Whfht-1+Wcfct-1+bf)(2)
ct=ftct-1+ittanh(Wxcxt+Whcht-1+bc)(3)
ot=σ(Wxoxt+Whoht-1+Wcoct+bo)(4)
ht=ottanh(ct)(5)
在这里σ(.)代表sigmoid函数,作为激活机制。逻辑sigmoid和双曲正切函数都在元素级别上应用。对于k∈{i,f,o,c},综合权重矩阵表示为Wxk对应各种门和记忆单元中xt的输入权重。对于k∈{i,f,o},Wck矩阵配置为对角矩阵,建立记忆单元和不同门之间的连接。需要注意的是,所有门中的神经元数量是预先确定的,并且式(1)到(5)在每个神经元上独立运行。假设n表示神经元的数量,{it,ft,ct,ot,ht}是集合Rn×1的一部分。为了清晰起见,LSTM的权重和偏差被称为列向量wlstm和blstm。LSTM方程可以表示为:
引入TLSTM,假设z(η)是一个未观察到的序列,因此TLSTM的状态空间公式表达如下:
式(7)中概述的架构与式(6)有明显的区别。在式(6)中,模型参数无论评估点如何都保持不变,而在式(7)中,这些参数可以受到特定评估实例对应的特征向量的影响。下标η强调了模型参数对新数据点z(η)的可变性。需要注意的是,评估点的身份是未知的。在训练阶段,评估点的主要功能是根据训练点的特征向量与评估点的相似性来判断每个训练数据点的相关性。
在TLSTM框架内,空间注意力是一种使模型能够在不同的时间有选择地关注输入数据的某些部分的机制,而不是均匀处理整个数据集。这个特点特别有用,因为它允许模型强调数据中最相关的变量和属性,同时忽略无关的噪声或细节。在TLSTM网络内部引入空间注意力模块,将其定位为输入和TLSTM层之间的一个独立的层。该模块执行输入数据的加权求和,权重在训练期间根据每个输入特征对于头任务的相对重要性进行分配。通常,输入到空间注意力模块的数据由矩阵X表示,其维度为N×D,其中N是时间步数,D是输入特征的数量。空间注意力模块通过分析输入数据和一组学习到的参数(用W和b表示)来计算每个输入特征的一组权重,记作a。计算这些权重的过程如下:
a=softmax(XW+b)(8)
softmax函数将输入值转换为对输入特征的概率分布,下一步是计算加权后的输入数据:
X′=Xa(9)
这个加权后的数据是对输入数据的聚焦表示,引导模型将注意力转向最关键的特征。最后,这个加权输入以典型方式通过TLSTM层,隐藏状态根据前述公式进行调整。
2.3 模型预训练
基于BERT对模型进行预训练,从BERT得到的查询和标题向量输入到一个TLSTM网络中,然后通过该网络预测SELECT、AGG和WHERE段的可能性。
3 实证评估
3.1 数据集
实验基于WiktionarySQL数据集[11],这是一个人工标注的从文本到SQL任务中最大的数据集,它包含了80 654对问题及其对应的SQL查询。为了保持测试的严谨性和有效性,我们将训练集与测试集进行隔离,确保没有表格重叠。这种隔离对于准确评估模型在实际场景中的性能至关重要。
3.2 评估指标
本研究使用两个指标来评估SQL查询合成的效果。第一个指标是逻辑形式(LF),用于衡量该模型生成的SQL查询的准确性。LF计算精确匹配率,将每个生成的SQL查询与其真实等价物进行比较。这个指标对于理解模型如何复制正确SQL查询的结构和内容至关重要。第二个指标是执行准确性(EX),用于进一步深入评估生成的SQL查询的功能正确性。EX测量不仅与其真实对应项匹配,而且考虑了在执行时产生正确结果的SQL查询的比例。这个指标对于评估生成查询的实际效用至关重要,因为它反映了从数据库中检索正确数据的能力。LF关注的是查询句法的正确性,EX强调的是操作效果。这两个指标共同提供了对模型性能的全面评估。
3.3 参数设置
模型运行的计算机配置64位Windows操作系统、32GB RAM和64GB GPU。批量大小设置为64,以便在每次训练迭代中进行大量的数据处理。模型经历了256个周期,确保了广泛的训练期。学习率固定在0.02,平衡了收敛速度和超过最小损失的风险。此外,保持0.5的丢弃率以防止过度拟合,通过在训练过程中随机禁用一些神经元,从而促进更广泛的学习。经过严格的训练后,模型在完成250个周期后达到了最佳状态,用时90分钟。
3.4 实验结果
基于Wiktionary数据集的实验结果如表1所示,为了说明本文方法的有效性,与其他方法进行了对比。
3.5 结果分析
实验结果表明,本文方法优于同类方法,在LF和EX指标方面,错误率分别超过AE模型的3.10%和5.85%。进一步分析表1可知,不同方法的性能变化非常大。例如,SQLova、SQLNet和Seq2SQL在LF和EX得分的标准偏差表明,它们在Wiktionary数据集中的不同查询上的性能波动很大。这表明这些模型虽然有效,但可能在不同的数据样本上并不总是可靠。另一方面,本文方法不仅获得了更高的平均分数,而且在LF和EX指标上都保持了较低的标准偏差,这意味着在不同查询上的性能更稳定可靠。从表1中还可以看出,随着时间的推移,模型性能逐渐改善。早期模型如SQLova、SQLNet和Seq2SQL的得分相对较低,而新的模型如HydraNet和AE则得分较高。这一趋势反映了在查询理解和SQL生成领域,自然语言处理和机器学习技术的快速进步。
4 结论
本文提出了一种基于转导长短时记忆网络的语义解析框架。转导长短时记忆网络模型表现出了检测时间序列数据中微妙变化的能力,超过了传统的长短时记忆网络模型。基于BERT模型进行预训练,捕获了更广泛的细微语言差别,有助于提高模型的整体效能。在使用Wiktionary数据集进行评估时,该模型的性能优于同类方法。
本文所提出的模型主要关注文本数据,但是大量包括图形、图表和其他类型多媒体数据在内的多模态数据可能存在于各种有组织和半组织的知识库中。整合这些不同形式的数据可以大大丰富模型理解和表示复杂查询的能力,特别是在仅靠文本无法完全表达底层上下文的情况下。例如,在艺术或医学成像等领域的数据库中,用户可能需要使用文本描述和视觉内容的组合进行查询。通过嵌入处理多模态数据的能力,模型可以适应更广泛的查询范围,提供更全面和具有上下文细节的结果。另一个值得进一步研究的方向是,在模型训练阶段还可以整合BERT词嵌入或采用生成对抗网络(GAN)。
参考文献:
〔1〕刘雨蒙,赵怡婧,王碧聪,等.结构化数据库查询语言智能合成技术研究进展[J].计算机科学,2024, 51(07):40-48.
〔2〕刘泽洋.面向汉语数据库问答的数据标注平台和语义解析模型构建[D].苏州:苏州大学,2023.
〔3〕XU X J, LIU C, SONG D. SQLNet: Generating structured queries from natural language without reinforcement learning[EB/OL]. 2017: 1711.04436.http://arxiv.org/abs/1711.04436v1.
〔4〕Shijie Chen, Ziru Chen, Huan Sun, et al. Error Detection for Text-to-SQL Semantic Parsing[J]. arxiv preprint arXiv:2305.13683,2023.
〔5〕ZHONG V, XIONG C M, SOCHER R. Seq2SQL: Generating structured queries from natural language using reinforcement learning[J].arxiv preprint arXiv:1709.00103,2017.
〔6〕SEHOVAC L, GROLINGER K.Deep Learning for Load Forecasting: Sequence to Sequence Recurrent Neural Networks With Attention[J].IEEE ACCESS,2020,8:36411-36426.
〔7〕Yintong Huo, Yuxin Su, Cheryl Lee, et al. SemParser: A Semantic Parser for Log Analysis[J]. arxiv preprint arXiv:2112.12636,2023.
〔8〕Pegah Eslamieh, Mehdi Shajari, Ahmad Nickabadi. User2Vec: A Novel Representation for the Information of the Social Networks for Stock Market Prediction Using Convolutional and Recurrent Neural Networks[J]. Mathematics,2023, 11(13): 2950.
〔9〕胡新辰.基于LSTM的语义关系分类研究[D].哈尔滨:哈尔滨工业大学,2015.
〔10〕梁宏涛,刘硕,杜军威,等.深度学习应用于时序预测研究综述[J].计算机科学与探索,2023,17(06):1285-1300.
〔11〕Tao Yu, Zifan Li, Zilin Zhang, et al. TypeSQL: Knowledge-based Type-Aware Neural Text-to-SQL Generation[J].arxiv preprint arxiv:1804.09769,2018.
〔12〕Wonseok Hwang, Jinyeong Yim, Seunghyun Park, et al. A Comprehensive Exploration on WikiSQL with Table-Aware Word Contextualization[J].arxiv preprint arxiv:1902. 01069, 2019.
〔13〕Li Dong, Mirella Lapata. Coarse-to-Fine Decoding for Neural Semantic Parsing[J]. arxiv preprint arxiv:1805.04793, 2018.
〔14〕Pengcheng He, Yi Mao, Kaushik Chakrabarti, et al. X-SQL: reinforce schema representation with context[J].arxiv preprint arxiv:1908.08113, 2019.
〔15〕Qin Lyu, Kaushik Chakrabarti, Shobhit Hathi, et al. Hybrid Ranking Network for Text-to-SQL[J].arxiv preprint arxiv:2008.04759, 2020.
〔16〕Jianqiang Ma, Zeyu Yan, Shuai Pang, et al. Mention Extraction and Linking for SQL Query Generation[J]. arxiv preprint arxiv:2012. 10074,2020.
