
面向生产制造的大数据分析功能模块设计与实现
2024-11-02 00:00:00赵鹏张青胡刚师玉玲胡宁
科技创新与应用 2024年31期



摘 要:该文探究一种面向生产制造的大数据分析平台的设计要点及其功能实现方式。该平台可以与分析数据库、企业数据库之间实现数据共享,通过收集、分析企业数据,在产品质量监督和生产工艺改进等方面发挥重要作用。在数据导入模块应用SQOOP技术,提高数据导入导出速率;数据分析模块应用KNN分布式并行算法,通过批量化计算提高数据处理效率;基于Spark功能栈开发大数据集群功能模块,基于Spring框架和MCV技术构建平台可视化模块。通过数据快速分析和结果可视化呈现,为用户加强生成制造管理提供帮助。
关键词:大数据分析;可视化;SQOOP技术;大数据集群;生产工艺
中图分类号:TP311.13 文献标志码:A 文章编号:2095-2945(2024)31-0130-04
Abstract: This paper explores the design points and functional implementation methods of a big data analysis platform for manufacturing. The platform can realize data sharing with analytical databases and enterprise databases. By collecting and analyzing enterprise data, it plays an important role in product quality supervision and production process improvement. SQOOP technology is applied to the data import module to improve the data import and export rate; the data analysis module applies the KNN distributed parallel algorithm to improve data processing efqbTdgrkw8EYxkWvQSmVsXl4D8iFTnT5690H090AWhLY=ficiency through batch calculation; the big data cluster functional module is developed based on the Spark function stack, and the platform visualization module is built based on the Spring framework and MCV technology. Through rapid data analysis and visual presentation of results, users are helped to strengthen production manufacturing management.
Keywords: big data analysis; visualization; SQOOP technology; big data cluster; production process
在智能制造背景下,企业迫切需要加强生产制造管理,通过减少材料浪费、提高产品质量、优化资源配置等方式,实现自身效益的最大化。大数据分析技术不仅支持对海量数据的批量化、高效化处理,而且还能通过数据的挖掘、整合等方式,发挥数据利用价值,辅助生产制造管理。在这一背景下,设计面向生产制造的大数据分析平台,以企业日常运营中产生的海量数据作为分析对象,将分析结果在Web界面上实时、直观呈现,最终达到提高产品质量、保证决策科学、优化生产调度等目的。
1 面向生产制造的大数据分析平台架构
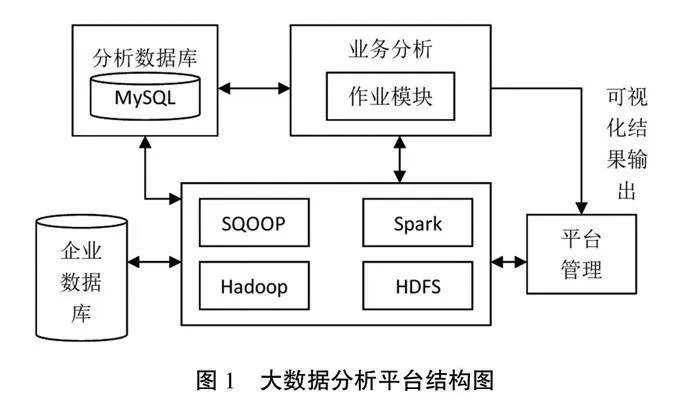
本文设计的大数据分析平台主要包含HDFS分布式文件系统、Spark高级分布式计算框架、Hadoop分布式系统基础架构和SQOOP数据导入导出工具等,该平台可以与分析数据库、企业数据库以及业务分析模块、平台管理模块实现信息共享,整体架构如图1所示。
在大数据分析平台中,HDFS可以为该平台提供相对安全的数据保存环境,用于存储企业待分析数据和数据分析结果;Spark可基于MLlib机器学习算法对数据库中的海量数据进行分布式计算,完成数据分析;Hadoop提供了多种功能模块,如提高系统资源利用率的Yarn模块、用于数据处理的MapReduce模块等,满足大数据分析、集群等需要;SQOOP实现了数据库与HDFS之间的数据共享,提高了数据导入导出的速度。
2 大数据分析功能模块设计与实现
2.1 数据获取与存储模块
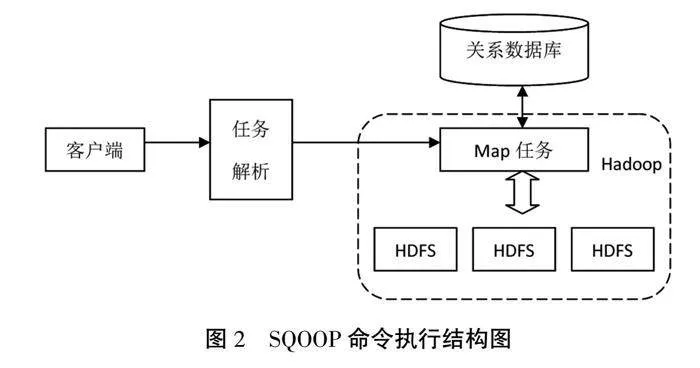
生产制造企业日常运营中产生海量数据,常规的导入导出方式具有效率低、安全性差等弊端,因此在设计中应用了SQOOP技术,其可以通过并行模式实现数据的批量化处理,从而极大地提高了数据导入效率。SQOOP的命令执行流程如图2所示。
由图2可知,SQOOP工具启动运行后进入低功耗的待机状态,等待接收来自客户端的指令。当用户从客户端上编辑并发送shell命令后,该命令经过任务解析器转换成SQOOP可识别的MapReduce任务,在SQL数据库与Hadoop之间实现数据的相互传递,实现数据的导入导出。基于SQOOP的并行数据导入原理如下:用户选择需要导入的数据文件,如果数据量较大可以按时间划分,分成多个Map任务,保证每次导入的数据量相对一致,达到提高导入速率、降低系统能耗的效果。选择Map任务、设定并行数量后,SQOOP工具自动加载大数据平台的配置信息,并将Map任务提交到大数据平台,开始进行数据的导入,在全部Map任务导入后任务结束[1]。
2.2 大数据分析模块
2.2.1 数据分析流程设计
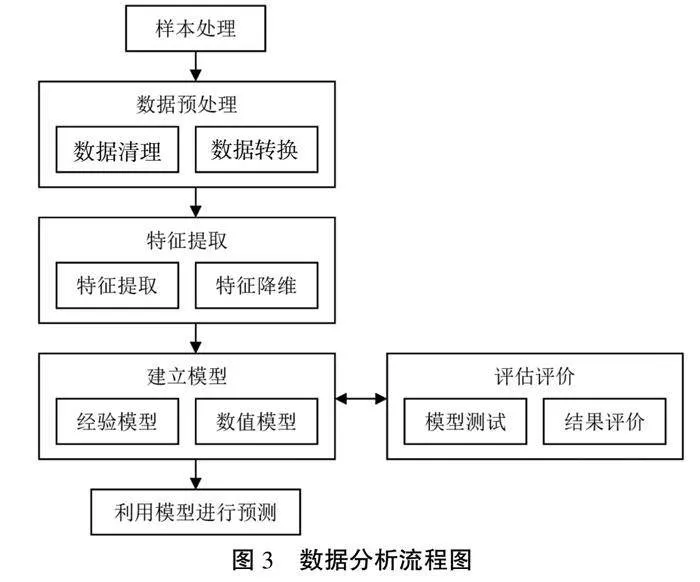
该模块是大数据分析平台的关键组成,根据分析结果帮助企业管理者直观掌握产品质量以及提供产品供应商或产品生产人员信息等。理论上来说,不同类型产品的数据也存在差异,需要根据产品的具体信息选择相应的数据分析算法。本文只探究基于大数据分析平台的数据分析实现方法,不考虑具体算法。数据分析流程如图3所示。
由图3可知,选择待分析的样本数据进行预处理,具体又分为2种操作,即数据清理和数据转换。数据清理的目的是识别出样本数据中的错误数据、异常数据并将其删除,是提升数据质量的一种常用方法。完成数据清理后,噪声减少、格式标准,为下一步的特征提取创造了便利。数据转换的目的是提高不同系统的兼容性,保证样本数据从原始系统转换到大数据分析平台后可以被正常地解释和使用。利用特征提取模块从预处理后的数据中提取特征,判断是否存在特征冗余。如果特征较少,可以直接进行建模环节。如果特征较多、存在冗余,还需要增加一个特征降维步骤,达到缩小特征矩阵、减少模型训练时长的目的。常用的特征降维方法有PCA主成分分析法、LDA线性判别分析法等,本文在设计中选择了PCA降维。根据提取到的特征值建立模型,建模方法有基于专家生产经验的经验模型,基于特征计算的数值模型等。对模型展开测试,根据测试表现作出评估评价。一方面可以验证模型的正确性,另一方面也能发现模型存在问题并进行优化。
2.2.2 数据分析功能的实现
本文设计的大数据分析模块可满足以下功能需求:①准确判断产品质量状态;②提供生产设备、生产人员以及产品供应商等相关信息;③筛选最优原料供应商,确定最优原料供应商搭配;④评估生产人员的业务能力和生产设备的应用性能;⑤发现生产设备潜在故障。这里以产品质量评价为例,介绍该功能的实现情况。产品评价功能模块基于Spark平台实现,主要包含算法库、RDD(Resilient Distributed Dataset)运算、模型库三部分[2]。算法库中提供了可用于产品评价的数据清洗、特征提取等算法,如TruthFinder真值发现算法、多趟近邻排序算法等。考虑到企业生产制造的产品类型较多、数据处理量较大,本文选用了K近邻分类(KNN)算法,该算法属于分布式并行算法,可对输入的多个样本数据进行并行处理,从而提高了数据分析效率。基于KNN算法的产品质量评价程序如图4所示。
2.3 大数据集群功能模块
生产制造企业的数据虽然在源源不断地产生,但是数据分析却是一个阶段性需求,即每隔一定阶段开展一次数据分析。为了节约系统能耗、减少资源浪费,当不需要数据分析时大数据分析平台要进入低功耗待机状态,等到有新的数据分析需求时再重新唤醒[3]。为了实现上述功能,设计了大数据集群功能模块。在功能设计中,选择了Spark中的Spark SQL工具,该工具提供了一种抽象数据模型DataFrame,支持用户使用SQL语句完成常规的数据分析,并提供了多样化的分析方法,如csv、json及jdbc等。这里以jbdc为例,大数据集群功能实现代码如图5所示。
为了提高对Spark、Hadoop等集群任务的处理效率,设计了大数据集群服务控制器。该控制器可接收Web处理器发送的参数,完成不同类型的任务。例如当发送参数为“train”时,大数据分析平台提供模型训练服务,将完成清洗与特征提取后的数据输入到模型中,实现模型训练;当发送参数为“predict”时,大数据分析平台提供预测服务,根据用户设定的条件从数据库中调用符合用户要求的产品模型,利用该模型完成数据的预处理和特征提取,最后使用该模型进行数据评价。除此之外,还有import、deletedata、prepare等面向不同服务的参数。
2.4 平台可视化模块
2.4.1 可视化模块处理流程设计
为了让数据分析结果可视化呈现,在设计大数据分析平台时加入了可视化模块,该模块采用Spring框架,在软件开发时只需要保证业务逻辑能顺利实现即可,不受底层程序的限制,从而缩短了开发周期。在设计模式上,采用与Web应用程序有较高兼容度的MVC(Model View Controller)设计模式。可视化模块的处理流程如下:用户通过客户端浏览器编辑并发送HTTP请求,前端控制器接收到来自客户端浏览器的请求后,可以识别浏览器界面的参数信息,并根据该信息选择相应的业务模型,间接地实现了Web处理器与大数据集群的交互。使用业务模型完成数据处理后,再将处理结果反馈给控制器,并利用视图模板对处理结果进行渲染,渲染完毕后即可在Web浏览器的界面上进行呈现[4]。上述处理流程如图6所示。
2.4.2 生成数据分析报告
数据分析结果可以在Web网页上可视化呈现,但是无法保存。用户想要获取同样的数据结果必须要再次调用数据库,操作起来比较麻烦。另外,如果大数据平台处于离线运行模式无法正常加载数据会导致数据分析结果不能呈现。为了避免上述问题,本文提出了一种生成数据分析报告用于保存数据分析结果的方案,具体实现方式如下。
用户通过客户端浏览器发起一个查询相关数据的请求,随后该请求传递给前端控制器。前端控制器根据请求类型和请求内容,把任务分发给对应的数据展示处理器,与数据库对接从中选择相应的数据结果,调用该结果并通过Ajax将其传输到客户端浏览器上进行可视化呈现[5]。
用户从客户端浏览器上选择“生产分析报告”选型,调用Pyhnon搅拌获取浏览器当前界面数据并写入.pdf格式的分析报告中。
将生成的PDF报告以文件形式保存到客户端浏览器中,方便用户随时查看。
3 结束语
面向生产制造的大数据分析平台,在实时获取企业生产数据的基础上运用KNN算法实现数据的分类分析,通过Spring MVC架构将分析结果反馈给Web浏览器进行可视化呈现。同时,引入了Spark服务降低了平台运行能耗,优化了用户操作体验。将该平台应用到企业的生产制造管理中,满足了节约生产成本、提高产品质量的需求。
参考文献:
[1] 周波,李晓科,彭世宇.基于烟草生产大数据平台的数据计算分析服务研究[J].网络安全和信息化,2022(9):67-73.
[2] 刘平峰,陈坤.基于多维工业大数据的制造业服务化价值创造体系构建[J].北京邮电大学学报,2022,24(3):78-89.
[3] 邓盛彪,张宏涛,孙勇.基于大数据的锻造生产过程模型的搭建与分析[J].锻压技术,2019(5):37-39.
[4] 关静.基于大数据技术的机械机床制造数字化平台设计[J].现代信息科技,2023(24):21-24.
[5] 李小宾.智能制造技术与系统可行性分析构架[J].设备管理与维修,2022(16):40-42.
