
基于用户行为序列分析的需求智能挖掘研究与应用
2024-10-29 00:00:00付兵兰寇晨辉刘春林彭伟军陈国
中国新通信 2024年18期
摘 要:本论文提出了一种基于行为序列对比的需求智能挖掘方法,主要应用于RPA、人工智能和界面自动化领域。该方法包括数据采集、数据处理和数据输出三个模块,能够实现对用户操作行为的自动记录、对行为序列的切分和聚类,以及对公共序列的提取,从而生成需求定义文档和RPA流程。本方法具有较高的自动化程度和鲁棒性,可有效提高需求分析和流程设计的效率。
关键词:需求智能挖掘;行为序列对比;需求分析;RPA流程设计
一、引言
随着科技的发展,RPA技术已经在企业中得到了广泛应用,它可以模拟最终用户在软件系统中的操作,实现用户操作的自动化。
企业使用RPA技术,可将工作中重复性高、业务逻辑明确的活动提取为RPA流程,从而实现操作的自动化。RPA高准确率、7*24小时运行的特点,可助力企业实现IT换人、降本增效的目的。目前,其已经成为大多数企业有效推进数字化转型的有效支撑。
然而,在设计RPA流程前,需要对用户的工作内容进行人工需求分析,从工作中筛选出重复度高且可自动化的RPA流程,随后根据其工作内容从零开始设计RPA流程,这是一个复杂且耗时的过程。与RPA降本增效的目的相违背,因此,需要考虑一种自动实现需求分析并辅助流程设计的需求挖掘功能,从用户工作中自动解析、提取具备自动化潜力的流程。
该需求挖掘功能,其应该包含数据采集、数据分析及数据输出三个模块。数据采集模块,收集用户在计算机上的操作日志。用户通过计算机进行的每一步操作,如敲击键盘和点击鼠标,均会产生一条操作日志。每一条日志均代表一个d4afd3610ab0e0a0b8ead8a9f805ac13393a4dceeb4177c977756f5b7ba2089e行为;数据分析模块,针对操作日志进行切分,将用户操作日志切分为多条由多个行为组成的行为序列。基于人工智能/机器学习实现行为序列中的行为相似度对比以及公共序列提取;数据输出模块:根据公共序列输出需求定义文档以及RPA流程。
现有的需求挖掘技术或多或少都存在自动化程度低、行为相似度检测功能鲁棒性低、行为序列提取功能鲁棒性低等问题。
自动化程度低,是指采集用户操作数据时,往往需要用户在每次任务的开始及结束时手动通知数据采集器,以此实现行为序列切分,未实现操作序列的自动化切分;本方案基于时间间隔实现行为序列自动切分,无需人工介入操作,自动化程度高。
关于行为相似度检测功能鲁棒性低,是指现有技术仅通过NLP结果作为行为相似度评判依据,面对不同窗口中的相似元素、同一操作中的不同键值输入情况的处理能力差、误判率高。本方案通过事件信息、窗口信息以及操作目标元素XPath三个维度评判用户行为的相似度,可适应多种情况下的行为相似度对比操作。
关于行为序列提取功能鲁棒性低,是指现有技术需通过滑动窗口功能实现公共序列提取,该方法要求用户在进行重复活动时操作完全一致,对冗余操作适应能力差,对用户操作规范性要求高。本方案基于聚类实现公共序列获取,对冗余操作适应能力强,对用户操作规范性要求低。
在解决以上问题的基础上,本论文提出了一种基于行为序列对比的需求智能挖掘方法,可以自动分析用户操作行为,提取具有高度自动化潜力的重复性工作,从而生成需求定义文档和RPA流程。
二、需求智能挖掘的构建
(一)多模块协同的功能架构设计
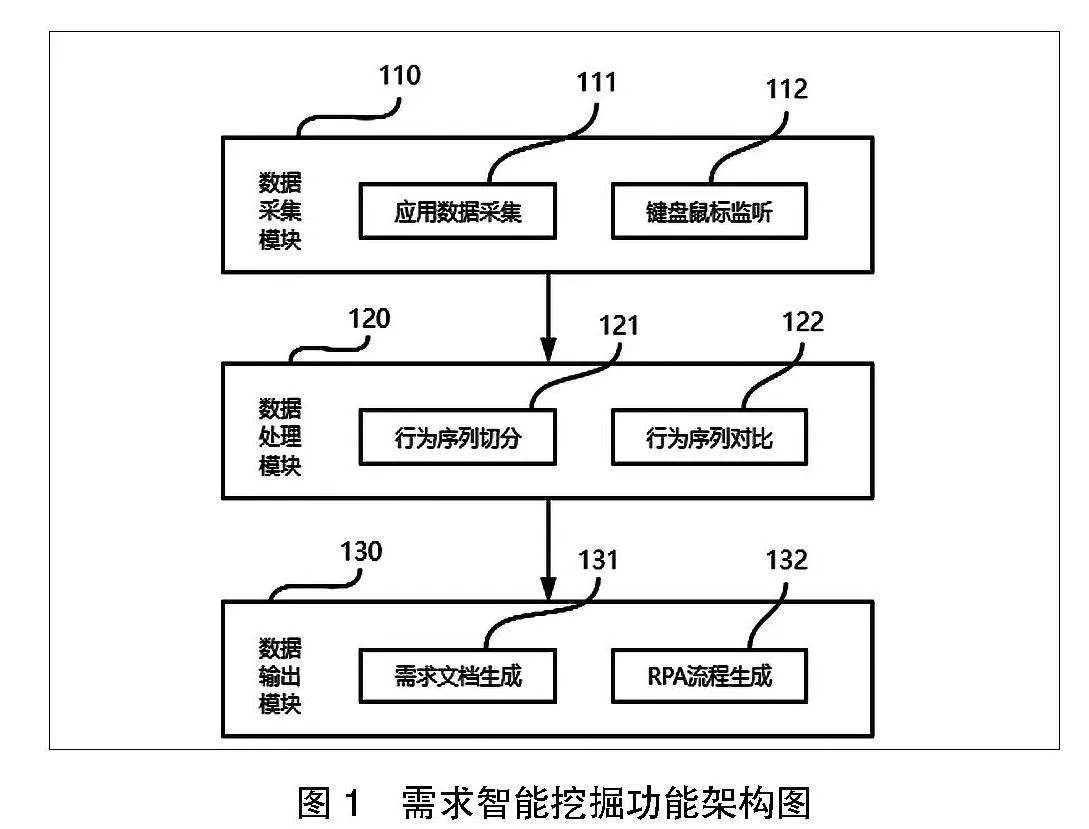
需求智能挖掘可划分为数据采集、数据处理、数据输出三个模块,其功能架构见图1。
110数据采集模块:采集用户操作数据,基于111应用数据采集模块及112键盘鼠标监听模块,获取用户在计算机上的各项操作信息。通过111应用数据采集模块获取操作目标应用中窗口信息及元素信息,112键盘鼠标监听模块监听键盘鼠标事件。
120数据处理模块:接收用户操作数据,经由121行为序列切分模块,基于时间间隔对用户操作数据进行切分,以输出多项行为序列,再由122行为序列对比模块通过聚类将行为序列进行分类,随后通过行为相似度对比提取公共序列。
130数据输出模块:基于公共序列输出需求定义文档及RPA流程。
(二)自上而下的需求智能挖掘
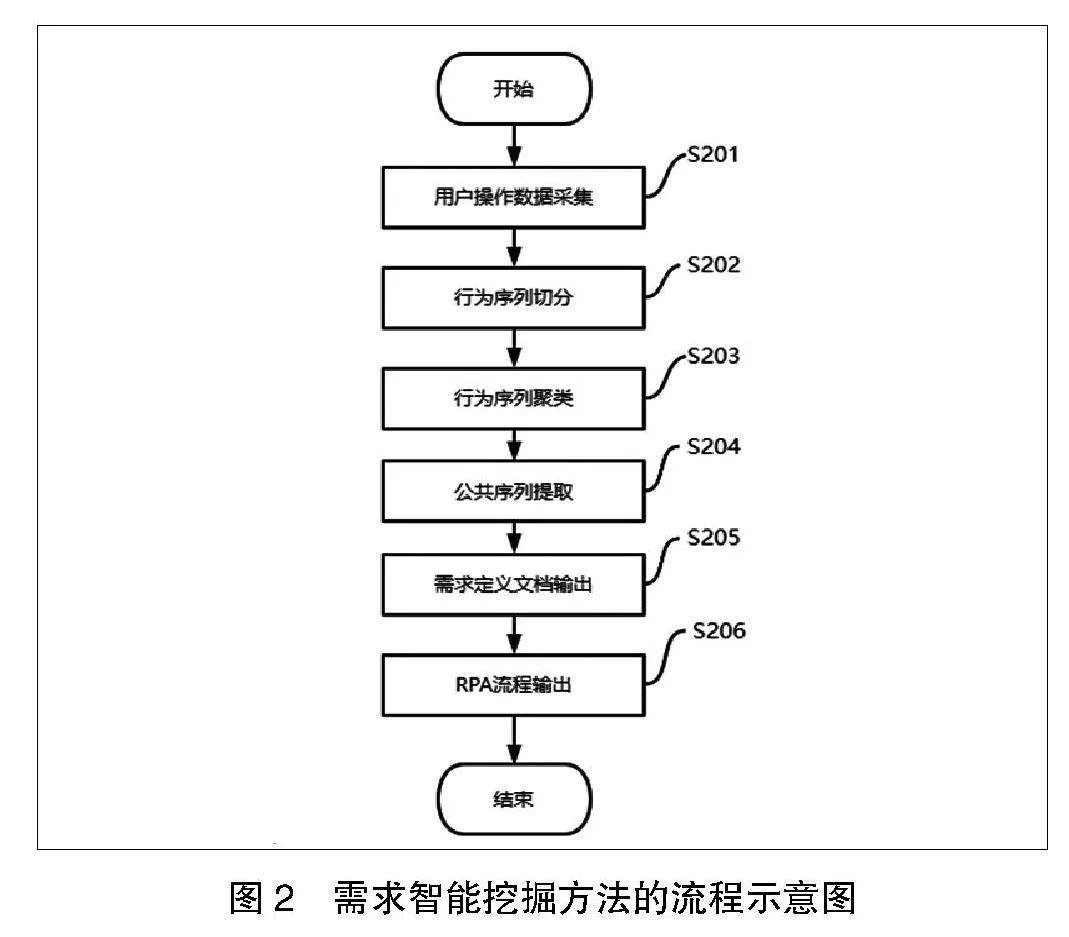
图2是基于AI的需求智能挖掘方法的流程示意图。
1.用户操作数据采集
在步骤S201中,数据采集模块将持续采集用户与计算机的交互操作数据并生成操作日志。
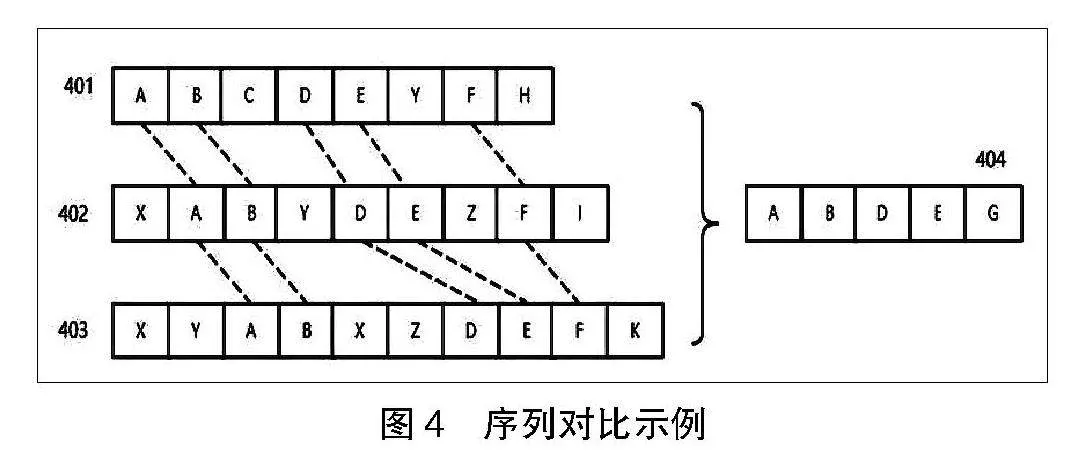
数据采集模块示意图如图3所示。
该模块由数据采集器及元素识别模块组成。301数据采集器通过监听用户键鼠操作信息触发行为记录用户动作,通过元素识别模块调用302浏览器插件、303MSHTML组件及304应用识别器对操作目标进行识别。
将操作目标划分为305浏览器及306桌面应用程序,在用户进行键鼠操作时,首先获取操作窗口信息,判断目标窗口类型。若为目标窗口浏览器,则可以浏览器通信并获取操作目标元素信息,此处以Chrome/FireFox浏览器插件、MSHTML方式为例实现通信功能,实际应用过程中可以拓展至其他浏览器通信方式。通过与浏览器通信获取操作目标元素的XPath、JSPath等信息,以此作为目标元素标识。若为桌面应用程序,则可通过应用元素识别获取程序窗口中的目标元素信息。
数据采集模块接收到用户键鼠操作时,记录本次事件类型及事件值,事件类型为键盘/鼠标,事件值为本次操作击键值,例如鼠标事件-左击、键盘事件-a等。在实际操作活动中,用户键盘操作有单次按键、组合按键及连续按键等行为,为提高后期序列提取的准确率,此处需对键盘事件进行处理,包括但不限于记录并整合用户的组合键、连续键盘输入事件。
通过以上步骤获取事件时间、事件类型、目标窗口信息以及目标元素信息,将其作为一个行为日志进行存储。
2.行为序列切分
在步骤S202中,数据处理模块从数据采集模块获取用户操作数据后,分析各条用户操作时间,根据其时间间隔将用户操作数据的多条行为组合为用户操作行为序列,以此将操作数据切分为多个行为序列,每个行为序列即为一项工作的操作流程。
3.行为序列聚类
在步骤S203中,基于步骤S202输出的行为序列集合进行聚类,同类中的行为序列即为相同内容的工作任务。可聚类的工作任务即为具有高度自动化潜力的重复性工作。
聚类作为一种重要的无监督学习方法,在处理大规模无标记数据时被广泛应用。它通过算法将数据分成多个簇,其中同一簇中的数据具有很高的相似性,而不同簇中的数据则尽可能地不同,从而更有效地提取数据信息。本论文基于聚类将用户操作行为序列划分为若干个序列类,各序列类分别为一项重复性工作的行为序列集合。基于该步骤方法的行为序列聚类实现步骤如下:
(1) 冗余行为处理
用户进行计算机操作过程中会不可避免地出现冗余操作,该冗余操作与实际工作内容虽无关联,却会干扰聚类效果,降低RPA流程挖掘效率,因此,行为序列聚类的第一步,是去除行为序列中的冗余行为。
去除冗余行为的具体方法是,将各行为序列进行比对,获取各行为的出现频率,将出现频率低于阈值的行为视作冗余操作,将其从行为序列中删除。由此可见,阈值的设定决定了系统对冗余操作的容忍程度,且阈值的判定条件既可为频率,也可为频数,该项的设定参数可由实际应用场景决定,例如,将频数阈值设置为1时,则将仅在单个序列中出现的行为删除。
(2)行为信息分词预处理
行为序列聚类时需对各行为信息进行预处理,其中,对行为窗口信息、元素信息等内容需进行分词处理。
分词是自然语言处理中的关键预处理步骤,它将文本划分为更小的语义单元,即词语,从而便于后续的分析和应用。与英文单词之间由空格自然分隔不同,中文文本中的词语之间没有显式的分隔,这使得中文分词的难度更大。
主流的中文分词算法可以分为两大类:
一是基于词典的字符串匹配算法,这种方法依赖于建立一个全面的词典库,通过词典中的词条来匹配文本字符串。分词的结果完全取决于词典的内容。该方法根据匹配的方向和优先级不同,可以分为正向最大匹配法、逆向最大匹配法和双向匹配法。利用优化的存储数据结构和查找算法(如哈希表和索引树),这类方法可以实现高效的线性时间复杂度。然而,这种方法对词典之外的新词和歧义词的处理效果不佳。
二是基于统计机器学习的分词,这类方法包括生成式模型(如隐马尔可夫模型 HMM)和判别式模型(如条件随机场模型 CRF)。与词典匹配不同,这些方法不直接依赖词为单位,而是对每个字进行标注,考虑上下文的关系,通过对标注序列 Y 的联合概率(HMM)或条件概率(CRF)建模,预测观测序列 X 在标注序列 Y 后的出现概率,从而构成词语。这些方法不依赖于词典,能够较好地处理新词和歧义词的问题。
这里的行为信息分词可基于以上任意一种方法或二者结合,以实现精确模式的分词处理。
(3)基于停用词的降噪处理
在语言中,一些词语虽然出现频率极高,但实际上没有具体意义,这类词语被称为停用词(stopwords)。为了避免这些词语干扰后续的行为文本特征提取,可以利用停用词表来剔除分词结果中的停用词,可自定义停用词表,也可使用现有停用词表,包括但不限于哈工大停用词表、百度停用词表等。
(4)基于自定义词典的高准确率分词
不管是标准分词器、NLP分词器还是索引分词器,都不可能每次都能准确实现目标结果的分词。当前互联网下常出现自定义名词,例如:“证券”“信托”“需求智能挖掘”等,分词功能对长语句处理准确率较低。为弥补该缺陷,需利用用户自定义词典,以记录常用词,从而帮助分词器基于词典实现高准确率分词。
当本论文方法应用于企业自动化流程挖掘时,可针对企业所处目标领域,选择专业领域知识词典用于支持分词器进行细致分词,例如,收集金融领域特定专用词,构建金融领域词典,以此提高本方法在银行、证券等领域内企业应用时,行为序列类别划分的准确度。
(5)行为文本特征提取
在行为序列中,窗口信息和元素信息中的文本内容不能被计算机直接识别。因此,uHAGzi5rZLnXqqI7A/gVLA==需要在尽可能保留文本特征的情况下,将这些文本进行向量化表示。在自然语言处理中,词是包含特定含义的基本单元,将词映射到实数域的向量中,得到的词向量是最常用的文本特征表示方法。这种映射方式通常分为两种:一种是离散式表示,另一种是分布式表示。
①离散式表示
离散表示中的词特征通常基于词袋模型(Bag of Words,简称BOW)。该模型忽略了文本中的语义、词序和结构等信息,仅将文本看作一系列构成文本的词形成的无序集合。例如:独热编码(one-hot encoding) 和 词频-逆文档频率。
② 分布式表示
词向量的分布式表示也被称为词嵌入,是指词的语义由其上下文决定。语义相近的词通常具有相似的向量表示。例如:谷歌开源的直接获得低维词向量工具 Word2Vec。
基于上述行为文本特征提取方法,将行为序列转化为对应向量,以支持后续的聚类输入。
(6)行为序列聚类
常用的聚类算法主要包括三种方法:密度法(Density-based Method),划分法(Partitioning Method)和层次法(Hierarchical Method)。具体而言,可以采用K-Means聚类算法、分裂层次聚类算法(Divisive Clustering)、凝聚层次聚类算法等。
基于上述方法将行为序列向量集合输入,基于聚类算法将行为序列集合划分为多个行为序列类簇,各类簇分别代表一项具备自动化潜力的重复性工作。
4.公共序列提取
在步骤S204中,将基于S203输出的多个行为序列类提取出各类重复性工作的公共序列。在用户进行计算机操作时会不可避免地出现冗余操作,因此在进行同一项工作任务的过程中必然会存在冗余动作,导致操作步骤存在细微差异。为保证后期输出简洁高效的RPA流程,需要去除冗余操作,获取可实现目标任务的标准流程。
为实现这一目的,则需分析对比同类行为序列并提取出公共序列。该公共序列为可实现目标任务的最短行为序列。此项工作分为行为一致性判定及行为序列对比两部分。
(1)行为一致性判定
行为一致性判定是指基于行为事件、目标窗口及元素信息三个维度,判断两个行为是否一致。
行为事件判断的原则如下:
② 事件类型不一致,则判定行为不一致;
③ 事件类型一致,如同为鼠标事件,但鼠标按键不一致,则判定行为不一致;
④ 事件类型一致,如同为键盘事件,按文本输入组合、特殊键值组合等组合划分键盘键值,若不属同一组合则判定行为不一致。
目标窗口判断条件则直接对操作目标窗口信息进行判别,若操作目标窗口不一致则认为行为不一致。
元素信息判断条件则是通过NLP计算两个行为目标元素的相似度并以此为标准判定用户行为的一致性。
(2)行为序列对比
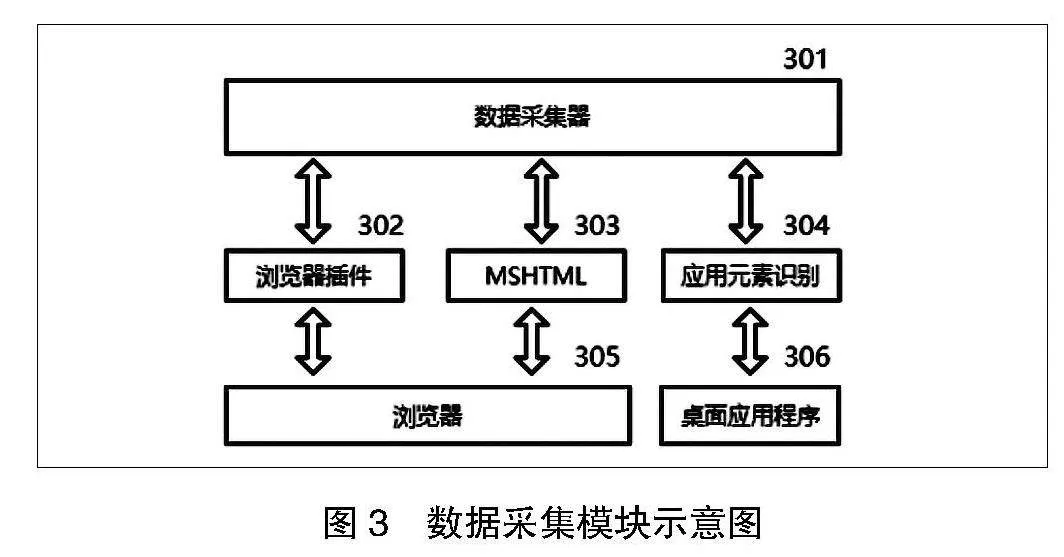
行为序列对比是指基于行为一致性判定规则对比多条行为序列,从中提取公共序列。对比示例图如图4所示,基于行为一致性判定规则,获取401序列、402序列及403序列中的最长公共子序列,其中,子序列在各原序列中可以不连续,由此得到最长子序列为404,其余行为则可视为冗余行为予以舍弃。
此处仅以三序列的0d151c8c3cf7a05b5c165e577b9cacb7对比作为示例,实际应用过程中,可对同类中所有序列进行公共序列提取。
通过行为一致性判定及行为序列对比,可输出同一行为序列类簇中的公共序列,该公共序列可作为此类行为序列的标准流程。对S203聚类输出的各个类簇均采用上述方法提取公共序列,以此分析用户所有的业务工作流程。
5.需求定义文档输出
步骤S205:基于S204输出的公共序列,根据各个行为的事件、操作目标窗口及元素信息生成需求定义文档,文档中写明具有高度自动化潜力的工作具体步骤及人工执行耗时,该文档可作为后续RPA需求分析依据。
三、 应用优势
基于行为序列对比的需求智能挖掘方法,采用基于事件、目标窗口及元素信息的行为一致性校验规则及行为序列提取方法,相比于直接对比事件相似度的方法,本方案对操作不同窗口中相似元素、同一操作中不同键值输入情况具有更高的识别准确率。相较于现有技术中要求操作序列完全一致或开始行为一致的方法,本方案采用最长公共子序列提取方法实现公共序列解析,对用户冗余操作容忍度高,无需指定序列开始行为。基于时间间隔的行为序列自动切分方案,避免现有技术中要求用户手动指定序列开始及结束的缺陷,完全无需人工介入操作,提高了该方案的自动化程度。
四、 结束语
本文提出了一种基于行为序列对比的需求智能挖掘方法,主要应用于RPA、人工智能和界面自动化领域。该方法通过采集用户操作日志,分析并切分行为序列,然后通过聚类和行为相似度对比提取公共序列,最终生成需求定义文档和RPA流程。本方法具有较高的自动化程度和鲁棒性,可以有效提高需求分析和流程设计的效率。在需求分析阶段,传统的人工方式耗时长且效率低,本方法通过自动实现需求分析并辅助流程设计,大大提高了需求分析效率。在流程设计阶段,本方法通过对用户工作的自动解析提取具备自动化潜力的流程,为后续的RPA实施提供了便利。此外,本方法还具有较强的鲁棒性。在行为相似度检测方面,本方法通过事件信息、窗口信息以及操作目标元素XPath三个维度评判行为相似度,可以适应多种情况下的行为相似度对比操作。在行为序列提取方面,本方法基于聚类实现公共序列获取,对冗余操作适应能力强,对用户操作规范性要求低。
总的来说,本文提出的需求智能挖掘方法具有很高的实用价值,不仅可以提高需求分析和流程设计的效率,还可以提高RPA的实施效果。
基于RPA实施效果的提升,本方法将持续为企业自动化转型工作赋能,通过记录并识别员工工作中具有高度自动化潜力的任务,以此为基础输出RPA需求文档及自动化流程,推进后续RPA实施工作,降低需求挖掘及流程设计成本,进一步推动企业自动化及数字化转型。此外,通信、金融及物流等业务流程重复性高的行业具有极高的RPA自动化潜力,RPA产品应用前景广阔。
作者单位:付兵兰 寇晨辉 刘春林 彭伟军 陈国
中移信息技术有限公司
付兵兰(1981.04-),女,汉族,湖南涟源,硕士,研究方向:RPA、云计算;
寇晨辉(1999.07-),男,汉族,陕西咸阳,学士,研究方向:RPA、云计算;
刘春林(1978.09-),男,汉族,湖南衡阳,学士,研究方向:RPA、云计算、人工智能;
彭伟军(1973.10-),男,汉族,广东汕尾,学士,研究方向:RPA、云计算、人工智能;
陈国(1977.11-),男,汉族,山东莱芜,硕士,研究方向:RPA、区块链、云计算、人工智能、算力网络。
