
基于集成学习与深度学习的洪水径流预报研究
2024-09-27 00:00:00许月萍周欣磊王若桐刘莉顾海挺
人民长江 2024年9期









摘要:深度学习模型凭借其对水文因素间复杂作用的优秀处理能力,在水文预报领域得到了一定的应用,然而,针对集成学习与深度学习耦合模型的研究仍有所缺失。通过融合集成学习AdaBoost算法与深度学习Informer模型,提出了一种组合模型,称为AdaBoost-Informer模型,以提高洪水径流预报的精度。该模型以历史雨量和径流数据作为数据输入,将具备长时序依赖捕获能力的Informer作为集成学习的弱预测器,使用网格搜索法进行超参数调优,使用AdaBoost集成学习算法对弱预测器进行加权组合得到强预测器。在浙江省椒江流域的应用分析表明:对比Random Forest、AdaBoost、Transformer、Informer等模型,AdaBoost-Informer模型表现最佳,RMSE为62.08 m3/s,MAE为23.83 m3/s,NSE为0.980,预报合格率为100%。所提模型可有效提高洪水预报精度,为防汛抢险和防洪系统调度提供决策依据。
关 键 词:洪水径流预报; 集成学习; 深度学习; 组合模型; Informer算法; 椒江流域
中图法分类号: TP18;P338
文献标志码: A
DOI:10.16232/j.cnki.1001-4179.2024.09.003
0 引 言
在气候变化背景下,全球极端降水强度和频率不断增加,洪水已成为对人类生命财产安全造成威胁的主要自然灾害之一[1-3]。受自然气象条件、流域特征和人类活动的影响,径流序列常呈现出非线性、随机性等特征[4]。洪水径流预报一直是水文领域重要的研究课题,寻找更精确的径流预报方法是学者们高度关注的重点问题[5]。
当前应用广泛的洪水径流预报模型主要包括过程驱动模型和数据驱动模型[6-7]。过程驱动模型通过建立复杂的数学模型和求解高维偏微分方程来模拟和预测径流过程,常用的过程驱动模型包括ARNO模型、新安江模型、TOPMODEL模型等[8-10]。过程驱动模型的模型参数通常有严格的物理解释,但模型参数选取复杂与计算成本过高的缺点限制了其在径流预报中的应用[11]。数据驱动模型通常只关注输入输出关系,而没有明确参数间的因果关系。随着数据驱动模型的不断发展,其可以进一步分为统计模型、机器学习模型和深度学习模型。统计模型使用统计学相关方法根据历史径流观测数据预测未来径流,如自回归移动平均模型(ARMA)[12]和自回归综合移动平均模型(ARIMA)[13-14]。统计模型的优点是可以精准捕捉历史数据与未来数据的线性关系,但其无法准确描述径流序列中复杂的非线性关系。机器学习模型如人工神经网络(ANN)、支持向量回归(SVR)和AdaBoost可以从多个输入中提取非线性特征[15-17],解决了非线性序列的拟合问题,在实际生产中得到了广泛应用,但其深层信息提取能力有限,预测性能仍有待提升。
近年来,计算机技术与人工智能高速发展,为了推动洪水径流预报方法的改进和提升,深度学习模型被引入水文预报领域。Chen等[18]开发了具备自注意力机制的长短时记忆神经网络(SA-LSTM)。Zhang等[19]建立了不同输入变量的LSTM模型与门控循环单元(GRU)模型进行径流预测,结果表明,具有多个气象输入数据的模型相较于单独的降雨数据有更高的预测精度。郭玉雪等[20]基于3种递归神经网络(RNN)建立了不同预报因子组合和预见期的径流预报模型,探讨了RNN模型在海岛地区短期水文预报中的适用性。熊怡等[21]提出了一种基于自适应变分模态分解和LSTM的分解-预测-集成月径流预测混合模型,进一步提升了金沙江上游石鼓水文站月径流预报精度。吴鑫俊等[22]将CNN模型应用于洪水演进的预测计算,提高了洪水演进的计算效率。苑希民等[23]提出了一种基于自编码器(AE)和残差卷积神经网络(RCNN)的洪水分级智能预报方法,可有效提取水文数据特征,提高洪水预报精度。
然而,现有的深度学习预测模型研究主要集中在模型结构调整和输入特征选择上,耦合集成学习算法与深度学习算法的研究较少。本文基于AdaBoost集成学习模型与Informer深度学习模型,提出了一种新的组合模型——AdaBoost-Informer模型,以椒江流域的降雨径流数据为模型输入,对Random Forest、AdaBoost、Transformer、Informer和AdaBoost-Informer模型进行性能比较,验证所提模型的准确性与有效性。
1 研究区域
椒江流域(图1)地处浙江省东南沿海,是浙江省的第三大河,流域面积约为 6 600 km2。上游主要分为两大支流,南部正流称永安溪,发源于括苍山脉西部;北部支流称始丰溪,发源于大磐山。椒江流域受台风暴雨影响大,洪涝季节性强、频率高。上游主要的两条支流都发源于山地,山溪性显著,大洪水发生可能性小。本次研究的沙段水文站位于椒灵江上游支流始丰溪,集水面积 1 482 km2,占始丰溪全流域面积约92%。
本次研究收集了椒江流域内1985~2019年间,部分年份受台风影响的7个测站的降雨量数据与对应时期的沙段水文站流量数据。采用泰森多边形法获得面平均降雨量。结合面平均降雨量与沙段水文站数据得到32场台风洪水的逐时降雨径流数据。
2 研究方法
2.1 AdaBoost集成学习模型
集成学习是一种通过构建多个弱学习器,以不同策略组合,提高模型预测精度与鲁棒性的机器学习方法。常见的集成学习方法包括堆叠(Stacking)法、聚合(Bagging)法与提升(Boosting)法。Stacking法先应用多个方法生成训练集,使用弱学习器进行学习,再将学习器的学习结果作为集成学习的训练集,最终获得集成学习模型。Bagging法的弱学习器间不存在强依赖关系,可以并行生成一系列弱学习器,对放回采样后的若干数据集进行学习,最终使用如加权集成的学习策略形成一个强学习器。Boosting法的弱学习器间存在强依赖关系,弱学习器间需要串行生成,后一个弱学习器的构建需依赖前一个弱学习器的学习结果,在多次的迭代过程中使得弱学习器的学习能力变得越来越强,最后把所有弱学习器组成为一个最终的强学习器。AdaBoost算法是Freund[24]在Boosting算法上改进的、拥有自适应增强能力的集成学习算法。AdaBoost不仅对样本赋予了权重,在迭代过程中将重点放在不易预测正确的样本上,对学习器也赋予了权重,预测精度越高的学习器被分配的权重越高,最后依据加权方法,将多个弱学习器进行组合,形成具有相对优良性能的强学习器。AdaBoost能够有效地缓解过拟合问题,因此可作为一种集成算法框架,用于改进其他算法的性能。
2.2 Informer深度学习模型
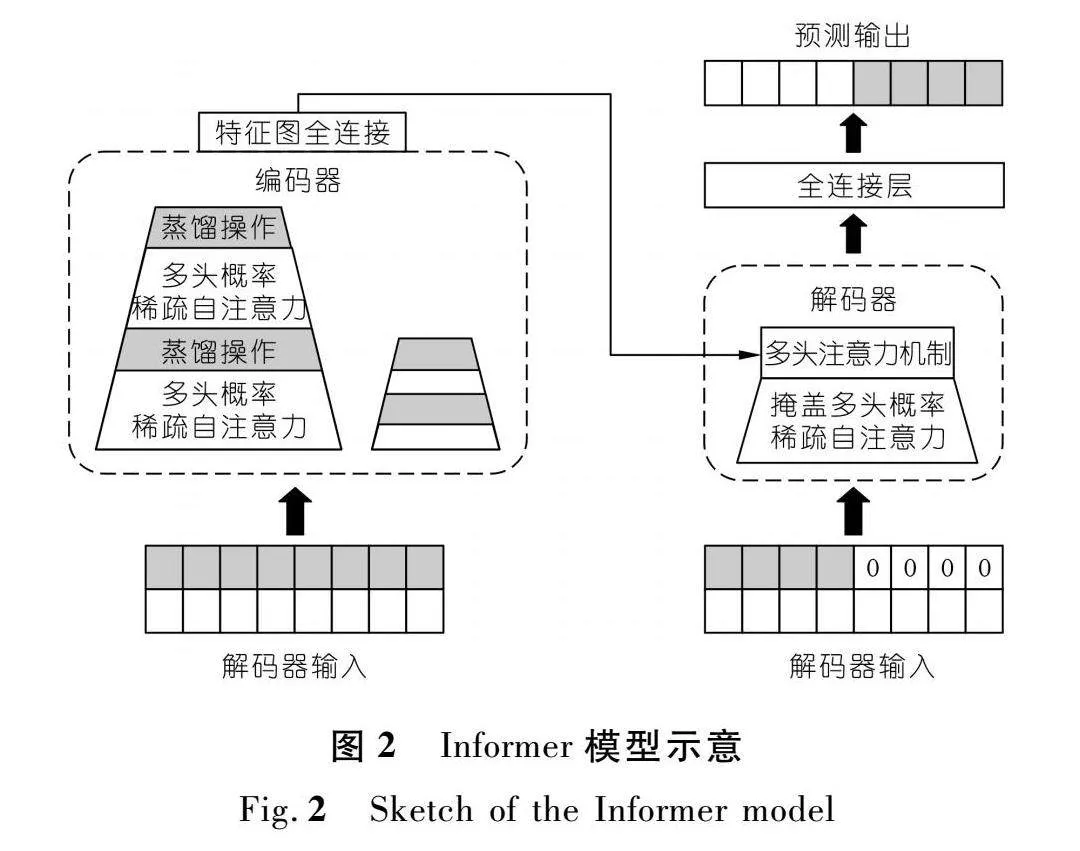
Informer模型是Zhou等[25]在Transformer编码器-解码器结构[26]的基础上改进的、适用于长序列时间预测的深度学习模型。Informer在编码器阶段使用了多头概率稀疏自注意力机制,取代了传统的Transfor-mer模型的自注意力机制,同时采用自注意力蒸馏方法显著减少了网络的深度,并且提高了层堆叠部分的鲁棒性;在解码器部分采用生成式译码方法,只需要一个前向步骤就可一次性生成全部预测序列,有效避免了误差的累积,极大地提高了解码的效率,Informer模型示意如图2所示。
相比被广泛应用于时序预测问题的深度学习模型(如LSTM模型),Informer模型采用的多头概率稀疏自注意力机制能够更好地捕捉长距离依赖关系,解决了梯度消失或梯度爆炸的问题,适合处理长时序预测问题,并且Informer模型内的自注意力机制可以并行运算,能够更有效地利用计算资源,加快训练速度。
2.3 AdaBoost-Informer模型
基于集成学习AdaBoost算法改进的Informer方法(以下简称AdaBoost-Informer)采用AdaBoost集成学习算法顺序串联训练多个Informer弱预测器,并在每一轮迭代后更新样本与弱预测器权重,对预测正确的样本减少关注,对预测错误的样本加大关注,最后采用加权组合的方式将多个弱预测器合成强预测器,输出最终的预测结果。AdaBoost-Informer充分融合了AdaBoost自适应优化提升模型整体性能与Informer处理长时间序列预测问题的优势,从而有效解决了Informer模型超参数选择复杂性与AdaBoost对异常样本的敏感性问题。
基于集成学习AdaBoost算法改进的Informer方法(以下简称AdaBoost-Informer)旨在以集成学习的方式增强Informer模型的预测准确性与鲁棒性。该方法采用AdaBoost集成学习算法,串行训练多个Informer弱预测器,并在训练过程中动态调整样本与弱预测器权重,进而将弱预测器进行加权组合生成强预测器,输出最终的预测结果。AdaBoost-Informer充分融合了AdaBoost深度挖掘算法的潜力与Informer处理长时间序列预测问题的优势,从而解决了Informer模型超参数选择复杂性的问题,且改善了AdaBoost对异常值的敏感性。
AdaBoost-Informer的建模过程如下:
(1) 每个样本都被分配同等重要的权重。
Dn=1M,n=1,2,…,M
(1)
式中:Dn表示第n个样本数据的权重;M表示样本数据的总数量。
(2) 设定神经网络的超参数,并确定Informer弱预测器的总数量为Nn,然后使用Informer模型对样本进行训练。
(3) 对于第n个Informer弱预测器,在训练集上计算其最大误差,记为
En=maxyi-Gn(xi)
(2)
式中:En表示弱预测器在训练集上的最大误差;yi表示弱预测器在训练集上第i个样本数据的预测值;Gn(xi)表示训练集上第i个样本数据的实际观测值。
(4) 计算每个样本的相对误差。
eni=(yi-Gn(xi))2E2n
(3)
式中:eni表示第n个弱预测器的第i个样本数据的相对误差。
(5) 计算第n个Informer弱预测器的误差率。
en=Mi=1wnieni
(4)
式中:en表示第n个弱预测器的误差率;wni表示第n个弱预测器的第i个样本数据的权重。
(6) 计算第n个Informer弱预测器的权重系数。
αn=en1-en
(5)
式中:αn为第n个弱预测器的权重系数。
(7) 对第n+1个弱预测器进行权重更新,更新公式如下:
ωn+1,i=ωniZnα1-enin
(6)
其中规范化因子定义为
Zn=Mi=1ωniα1-enin
(7)
(8) 将多个弱预测器采用取中位数的结合方法融合为强预测器。
f(x)=Nni=1ln1αng(x)
(8)
式中:g(x)为αnGn(x)的中位数。
2.4 模型评价指标
按照GB/T 22482-2008《水文情报预报规范》(以下简称“预报规范”)要求[27],洪水预报评估选择的指标为洪峰流量预报许可误差、峰现时间预报许可误差、预报合格率以及纳什效率系数(NSE);模型性能评估选择均方根误差RMSE,平均绝对误差MAE和纳什效率系数NSE作为代表性指标,其具体原理如下:
(1) 洪峰流量预报许可误差。洪水预报以实测洪峰流量的20%作为许可误差;当流量许可误差小于实测值的5%时,取流量实测值的5%。
(2) 峰现时间预报许可误差。根据预测的洪水峰值时间与实际观测到的洪水峰值时间之间的时差,以30%的差异作为误差的允许范围。当误差小于3 h或一个计算时段长度时,则将误差设置为3 h或一个计算时段长度。
(3) 预报合格率。一次洪水预报的误差小于许可误差即为合格预报。合格预报次数与总预报之比定义为预报合格率,计算公式为
QR=n/m×100%
(9)
式中:n、m分别为合格预报场次数、总预报场次数。
洪水预报精度等级如表1所列。
根据预报规范对精度的规定,当一个预报方案包含多个预报项目时,预报方案的合格率为各预报项目的算数平均值。预报方案精度达到甲、乙两个等级者,可用于正式预报;预报方案精度达到丙等级者只可用于参考性预报。
(4) 纳什效率系数。
NSE=1-(Qp,i-Qt,i)2(Qp,i-Q0)2
(10)
(5) 均方根误差。
RMSE=1M×Mi=1(Qp,i-Qt,i)2
(11)
(6) 平均绝对误差。
MAE=1M×Mi=1Qp,i-Qt,i
(12)
式中:M代表总时间步长数;Qp,i表示i时刻的流量预测数据;Qt,i表示i时刻的流量观测数据;Q0-表示流量预测数据的平均值。NSE的取值范围为(-∞,1],当NSE=1时,表示方法结果完美拟合实测值;RMSE和MAE的取值范围为[0,+∞),RMSE和MAE的数值越大,表示预测值与观测值的偏差越大,当RMSE和MAE等于0时,方法的拟合效果最佳。
2.5 模型输入及参数选择方法
采用自相关系数法、偏自相关系数法和网格搜索法来确认数据输入格式与模型参数。自相关系数与偏自相关系数的计算公式如下:
acf(k)=ρk=1Nd-k Ndt=k+1(xt-x)(xt-k-x)1NdNdt=1(xt-x)2
(13)
pacf(k)=DkD
(14)
D=1ρ1…ρk-1
ρ11…ρk-2
ρk-1ρk-2…1
(15)
Dk=
1ρ1…ρk-1
ρ11…ρk-2
ρk-1ρk-2…ρk
(16)
式中:Nd为总时序长度;k为延迟小时数;xt为第t小时的流量;x为流量的平均值。式(13)表示流量序列与其本身经过某些阶数滞后形成的序列之间存在某种程度的相关性。式(14)表示在剔除中间k-1个变量的干扰后,xt-k与xt存在某种程度的相关性。
网格搜索法是参数值的一种穷举搜索法,即在指定的参数范围内,按步长逐个调整参数,并利用调整后的参数来训练学习器。然后,在验证集上评估各种参数组合的性能,找到能够取得最高精度的参数组合。
3 结果分析
3.1 模型构建
本研究基于配置为 Intel(R) Core(TM) i9-12900H,NVIDIA GeForce RTX 3060 Laptop GPU和16 GB内存的计算机进行洪水径流预报。Informer算法的参数设置如下:迭代次数为30,注意力多头数量为8,编码层层数为2,解码层层数为2,前馈神经网络中间层的维度为2 048,Dropout层的丢弃率为0.1,数据批量batch size为32,初始学习率为0.001,学习率衰减方式为阶梯式衰减,激活函数为gelu函数,注意力机制为多头概率稀疏自注意力机制。选取2.4节介绍的RMSE、MAE、NSE作为算法精度评价指标。
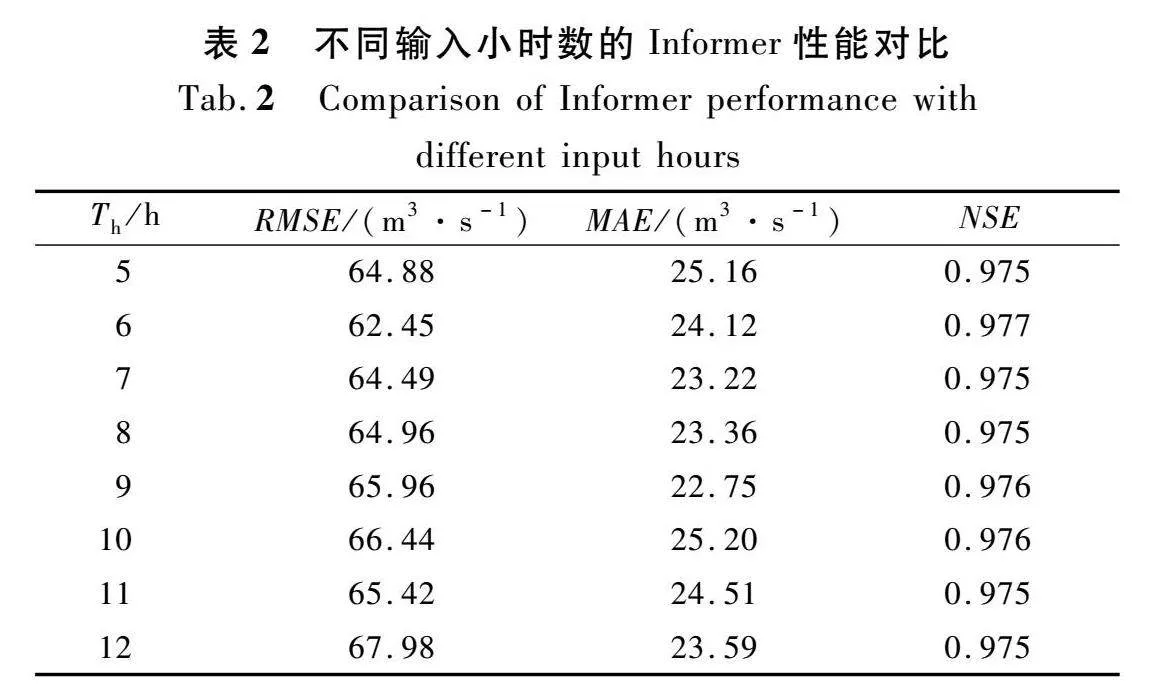
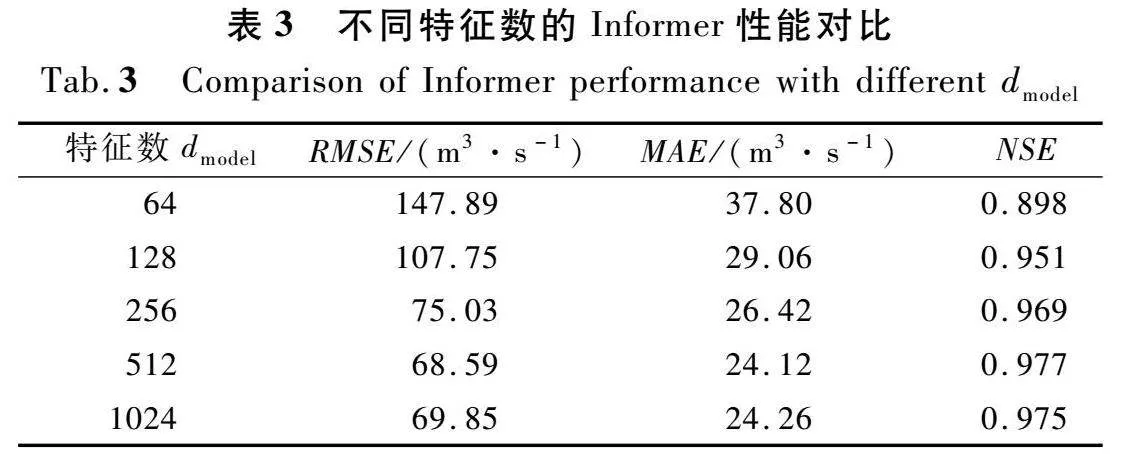
图3为流量序列延迟40 h的自相关系数与偏自相关系数图。图3(a)显示自相关系数是一个逐渐趋于0的拖尾,图3(b)显示在延迟15 h后偏自相关系数为0,因此延迟小时数不超过15 h,数据间的相关性较强,结合网格搜索法继续探究合适的输入天数。本研究以步长为1 h在5~12 h范围内选择合适的时长,结果如表2所列。当输入时长Th为6 h 时,Informer获得最好的性能,NSE最大值为0.977,因此本研究确定输入小时数为6 h。如表3所列,选取编码器/解码器输入中注意力机制的不同维度dmodel对洪水流量进行预测,得出当dmodel设置为512时预测精度最高,因此本研究确定dmodel为512。
AdaBoost-Informer模型中弱预测器采用Informer模型,参数设置参考上文Informer算法。AdaBoost算法须设置的参数主要为用于构建强预测器的Informer算法个数。使用网格搜索法对弱预测器个数Nw在[2,10]范围内的方法性能进行评估。为了减少深度学习模型训练中的随机性误差,对AdaBoost-Informer进行了5次运行,然后计算这5次运行的NSE平均值,选择最佳弱预测器个数。根据不同的弱预测器个数,预测方法的平均NSE值如表4所列,最终确定本方法选用的最佳弱预测器个数为9。
为了验证AdaBoost-Informer模型洪水流量的预测精度,选取Random Forest(RF)、AdaBoost、Transfor-mer、Informer模型进行对比评估。RF、AdaBoost、Transformer的输入均为6 h的流量、面雨量数据,输出为1 h的流量。RF的参数设置如下:决策树个数Nt为10个,决策树最大深度为3。AdaBoost的基学习器数量为10个,决策树最大深度为3。为便于比较,Transformer模型参数设置参考Informer模型:迭代次数为30,编码器/解码器输入中注意力机制的维度dmodel为512,注意力多头数量为8,编码层层数为2,解码层层数为2,前馈神经网络中间层的维度为2 048,Dropout层的丢弃率为0.1,数据批量batch size为32,初始学习率为0.001,学习率衰减方式为阶梯式衰减,激活函数为gelu函数,注意力机制为全局自注意力机制。
3.2 洪水预报结果分析
不同预报模型对测试集中台风编号为1509,名称为Chan-hom的台风洪水模拟效果对比如图4所示。RF模型、AdaBoost模型模拟流量与实测流量的趋势拟合度与其他3种模型相比较低。在部分时间跨度内,流量曲线呈现线性变化的趋势,而在局部时间范围内,模拟流量甚至维持不变,由此造成对峰值的预测效果无法达到令人满意的水平。Transformer模型、Informer模型具有良好的计算精度,能更好地反映流量的时序变化趋势,且对峰值的拟合效果较好,可以有效捕捉流量序列极值点的信息,模拟流量趋势基本与实测流量相符合,但对峰值预测有滞后。AdaBoost-Informer模型对变化趋势与峰值的拟合效果比Informer模型更好,散点图距离标准线也更为紧密。AdaBoost-Informer模型的流量预测性能显著优于其他传统集成学习与深度学习的方法,原因是AdaBoost-Informer模型将Ada-Boost算法对大误差数据的校正学习能力与Informer模型对复杂长序列非线性时序数据的优秀处理能力相结合,对未被预测精确的样本学习能力更强。
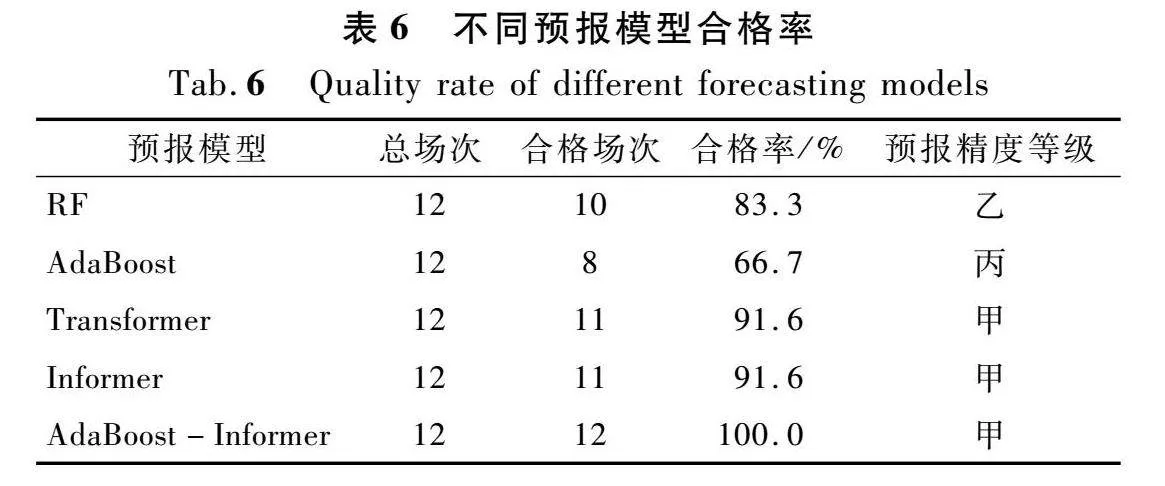
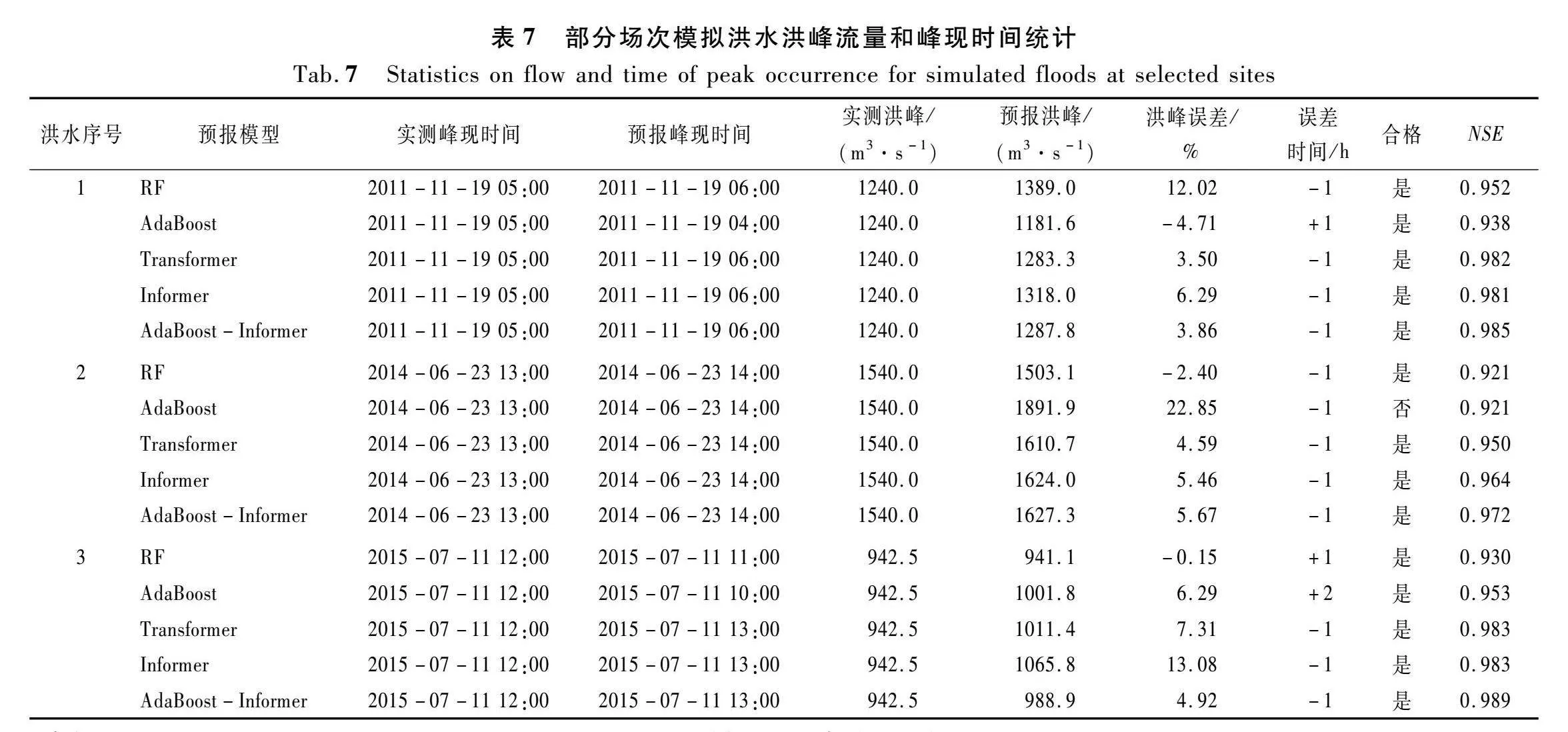
不同预报模型的性能、合格率如表5~6所列,测试集代表洪水预报精度结果如表7所列。由表5可知,在经由AdaBoost集成算法改进后,Informer方法的精度显著提升,RMSE从68.03 m3/s降低至62.08 m3/s,性能提升了8.5%,MAE从24.24 m3/s降至23.83 m3/s,性能提升了1.7%,NSE从0.975提升至0.980,性能提升了05%,验证了AdaBoost-Informer模型的优越性。由表6可知,测试集预报洪水场次共12场,RF、AdaBoost、Transformer、Informer、AdaBoost-Informer模型合格洪水场次分别为10,8,11,11,12场,合格率分别为83.3%,66.7%,91.6%,916%,100.0%,预报精度分别为乙级、丙级、甲级、甲级、甲级。由表7可知,在3场代表洪水中,AdaBoost-Informer模型相比于Informer模型,既提升了NSE,又改善了洪峰流量和峰现时间的预报效果。综上所述,无论是在预测性能方面还是稳定性方面,AdaBoost-Informer模型均优于4种基准对比方法。
4 结 论
本文提出一种新的深度学习洪水预报模型,通过将集成学习算法 AdaBoost 方法与深度学习算法 Informer 方法组合,构建了预测精度更高、拟合效果更佳的 AdaBoost-Informer 模型。并以RF、AdaBoost、Transformer、Informer模型为基准模型,以椒江流域为研究对象,从洪水径流预报性能的方面分析了所提模型的有效性与优越性。结论如下:
(1) 对比AdaBoost-Informer模型和RF、AdaBoost、Transformer、Informer模型,AdaBoost-Informer模型的各项评价指标均为最优,其测试集的RMSE为62.08m3/s,MAE为23.83 m3/s,NSE为0.980。
(2) 与其他模型相比,AdaBoost-Informer模型对流量变化趋势与峰值的拟合效果最好,在整体趋势与局部细节预测上均表现优异。
(3) 与其他模型相比,AdaBoost-Informer模型的预报方案精度等级为最佳,合格率最高,对部分代表洪水有最佳的洪峰流量与峰现时间的预报效果。
后续研究可集中于模型超参数智能优化算法的开发,并可探究深度学习模型在洪水预报应用场景下的损失函数选择,使得洪水预报模型不仅关注全局性能,也可捕捉局部细节。
参考文献:
[1] 蒋云钟,冶运涛,赵红莉,等.水利大数据研究现状与展望[J].水力发电学报,2020,39(10):1-32.
[2] 戴红梅,孙维红.气候变化与人类活动双重驱动下小河流域水沙变化特征研究[J].水利水电快报,2023,44(9):20-28.
[3] 尹家波,郭生练,顾磊,等.中国极端降水对气候变化的热力学响应机理及洪水效应[J].科学通报,2021,66(33):4315-4325.
[4] WANG W C,CHAU K W,CHENG C T,et al.A comparison of performance of several artificial intelligence methods for forecasting monthly discharge time series[J].Journal of Hydrology,2009,374(3/4):294-306.
[5] YUAN X,CHEN C,LEI X,et al.Monthly runoff forecasting based on LSTM-ALO model[J].Stochastic Environmental Research and Risk Assessment,2018,32:2199-2212.
[6] KRATZERT F,KLOTZ D,BRENNER C,et al.Rainfall-runoff modelling using long short-term memory(LSTM) networks[J].Hydrology and Earth System Sciences,2018,22(11):6005-6022.
[7] YOUNG C C,LIU W C.Prediction and modelling of rainfall-runoff during typhoon events using a physically-based and artificial neural network hybrid model[J].Hydrological Sciences Journal,2015,60(12):2102-2116.
[8] TODINI E.The ARNO rainfall-runoff model[J].Journal of Hydrology,1996,175(1-4):339-382.
[9] JIANG C K,ZHANG S L,XIE Y D.Constrained shuffled complex evolution algorithm and its application in the automatic calibration of Xinanjiang model[J].Frontiers in Earth Science,2023,10:1037173.
[10]BEVEN K J,KIRKBY M J,SCHOFIELD N,et al.Testing a physically-based flood forecasting model(TOPMODEL) for three UK catchments[J].Journal of Hydrology,1984,69(1/4):119-143.
[11]梁忠民,戴荣,李彬权.基于贝叶斯理论的水文不确定性分析研究进展[J].水科学进展,2010,21(2):274-281.
[12]马金凤,杨广.基于自回归滑动平均模型的玛纳斯河洪水预报[J].石河子大学学报(自然科学版),2010,28(2):242-245.
[13]MONTANARI A,ROSSO R,TAQQU M S.Fractionally differenced ARIMA models applied to hydrologic time series:identification,estimation,and simulation[J].Water Resources Research,1997,33(5):1035-1044.
[14]VALIPOUR M.Long-term runoff study using SARIMA and ARIMA models in the United States[J].Meteorological Applications,2015,22(3):592-598.
[15]YU X,ZHANG X,QIN H.A data-driven model based on Fourier transform and support vector regression for monthly reservoir inflow forecasting[J].Journal of Hydro-environment Research,2018,18:12-24.
[16]WU C L,CHAU K W,LI Y S.Predicting monthly streamflow using data-driven models coupled with data-preprocessing techniques[J].Water Resources Research,2009,45(8):W08432.
[17]LIU S,XU J,ZHAO J,et al.Efficiency enhancement of a process-based rainfall-runoff model using a new modified AdaBoost.RT technique[J].Applied Soft Computing,2014,23:521-529.
[18]CHEN X,HUANG J,HAN Z,et al.The importance of short lag-time in the runoff forecasting model based on long short-term memory[J].Journal of Hydrology,2020,589:125359.
[19]ZHANG J,CHEN X,KHAN A,et al.Daily runoff forecasting by deep recursive neural network[J].Journal of Hydrology,2021,596:126067.
[20]郭玉雪,许月萍,陈浩,等.基于多种递归神经网络的海岛水库径流预报[J].水力发电学报,2021,40(9):14-26.
[21]熊怡,周建中,孙娜,等.基于自适应变分模态分解和长短期记忆网络的月径流预报[J].水利学报,2023,54(2):172-183,198.
[22]吴鑫俊,赵晓东,丁茜,等.基于数据驱动的CNN洪水演进预测方法[J].水力发电学报,2021,40(5):79-86.
[23]苑希民,李达,田福昌,等.基于AE-RCNN的洪水分级智能预报方法研究[J].水利学报,2023,54(9):1070-1079.
[24]FREUND Y.Boosting a weak learning algorithm by majority[J].Information and Computation,1995,121(2):256-285.
[25]ZHOU H,ZHANG S,PENG J,et al.Informer:beyond efficient transformer for long sequence time-series forecasting[C]∥Proceedings of the AAAI Conference on Artificial Intelligence,2021,35(12):11106-11115.
[26]VASWANI A,SHAZEER N,PARMAR N,et al.Attention is all you need[C]∥Advances in Neural Information Processing Systems,2017,30:5998-6008.
[27]中华人民共和国国家质量监督检验检疫总局,中国国家标准化管理委员会.水文情报预报规范:GB/T 22482-2008[S].北京:中国标准出版社,2008.
(编辑:郭甜甜)
Research on flood runoff forecasting based on ensemble learning and deep learning
XU Yueping1,ZHOU Xinlei 1,WANG Ruotong2,LIU Li1,GU Haiting1
(1.Institute of Water Science and Engineering,Zhejiang University,Hangzhou 310058,China; 2.College of Civil Engineering,Zhejiang University of Technology,Hangzhou 310023,China)
Abstract:
Deep learning models have demonstrated exceptional capabilities in managing the intricate interactions among hydrological factors,leading to their adoption in hydrological forecasting.Nonetheless,there remains a gap in researches on the integration of ensemble learning with deep learning models.This study introduced a novel combined model,termed AdaBoost-Informer model,which integrates the AdaBoost algorithm with the Informer deep learning model to enhance flood runoff forecasting accuracy.The model utilizes historical precipitation and runoff data as input,with the Informer model,known for its proficiency in capturing long-term dependencies,serving as the weak learner within the ensemble framework.Hyperparameters are optimized using grid search,and AdaBoost is employed to weight and aggregate the weak learners into a robust predictor.Evaluation in the Jiaojiang River Basin in Zhejiang Province revealed that the AdaBoost-Informer model outperforms other models such as Random Forest,AdaBoost,Transformer,and Informer,achieving an RMSE of 62.08 m3/s,an MAE of 23.83 m3/s,an NSE of 0.980,and a forecasting success rate of 100%.This model can significantly enhance the precision of flood forecasts and offer a valuable basis for decision-making in flood prevention and emergency management.
Key words:
flood runoff forecasting; ensemble learning; deep learning; combining model; Informer algorithm; Jiaojiang River Basin
