
考虑自动驾驶仪延迟的非线性最优末制导方法
2024-09-25 00:00:00刘俊彤陈征张泽
航空兵器 2024年4期









摘 要:针对过载受限和自动驾驶仪延迟等条件下的非线性最优末制导指令在线生成方法进行研究。 首先, 基于庞特里亚金极大值原理, 建立了目标静止的非线性最优末制导问题的最优性条件, 并利用饱和函数将过载约束嵌入最优性条件。 其次, 应用参数化方法使得通过数值积分即可快速生成满足最优性条件的飞行轨迹数据集。 然后, 利用该数据集训练神经网络, 使其拟合弹-目相对运动状态到最优制导指令的映射关系, 实现过载约束下制导指令的毫秒量级在线生成。 针对自动驾驶仪的延迟响应, 通过微分补偿法估计神经网络下一时刻输出的制导指令以实现快速跟踪。 最后, 仿真结果表明, 本文所提出方法针对静止目标与小机动目标都能够在线生成最优制导指令。
关键词:过载约束; 自动驾驶仪延迟; 非线性最优末制导; 参数化方法; 神经网络
中图分类号: TJ765; V448.2
文献标识码: A
文章编号:1673-5048(2024)04-0064-08
DOI: 10.12132/ISSN.1673-5048.2023.0250
0 引 言
在精确制导打击中, 零脱靶量不再是评估制导律性能的唯一指标[1]。 新型作战任务对导弹提出了更高的要求, 如满足过载约束、 满足落角约束、 考虑自动驾驶仪延迟、 优化能量消耗等。 然而, 传统的基于线性化方法推导的制导律[2]在一定程度上会破坏约束或损失最优性[3], 影响导弹充分发挥打击能力。 因此, 研究如何在满足各种约束条件下在线求解非线性最优制导问题(Nonlinear Optimal Guidance, NOG)具有重要意义。
目前, 在求解NOG问题时, 通常采用半解析法、 直接法和间接法等。 半解析法的主要思路是通过各种近似或假设将问题进行简化处理, 从而得到解析解或半解析解。 文献[4]基于线性二次最优控制理论, 针对具有时变加速度和高阶自动驾驶仪动力学约束的导弹, 设计了满足落角约束的次优制导律。 文献[5]对打击静止目标的NOG问题进行参数化处理, 将问题简化为求实值函数零点的问题。 由于设计了实值函数的半解析形式, 并限制了其零点的区间, 因此使用暴力搜索便可找到所有零点, 从而快速得到非线性最优制导律。 文献[6]基于小角度假设建立了线性化的弹-目相对运动学方程, 应用Schwarz不等式, 针对带落角约束的一般加权函数形式的最优制导律进行研究, 得到最优制导律的一般表达式。
虽然将问题简化处理有可能得到解析/半解析形式的制导指令, 满足在线生成制导指令的需求, 但这种处理方式只适用于一些特殊场景, 且非线性特征的缺失会损失一定的最优性。 比较而言, 直接法[7-8]和间接法[9-10]直接对NOG相关的最优控制问题进行求解, 得到最优制导指令。 但是, 在高度非线性条件下, 直接法和间接法存在收敛时间长, 甚至不收敛的问题, 难以满足在线生成制导指令的需求[11]。
为解决上述问题, Chen[12]提出一种哈密尔顿轨迹参数化方法, 通过对最优控制问题的解空间进行参数化表征, 将最优性条件嵌入一组微分方程, 使得利用简单数值积分即可生成满足最优性条件的飞行轨迹。 Wang等[13]利用文献[12]中的参数化方法, 研究了具有攻击时间约束的NOG问题, 实现了时间约束下非线性最优制导指令毫秒量级在线生成。 文献[14]进一步围绕过载、 攻击时间等约束条件下的非线性最优制导指令在线生成问题进行研究。 文献[15]直接利用文献[13]中提出的参数化方法研究了纵向平面内考虑落角约束的NOG问题。
上述文献在使用参数化方法解决NOG问题时, 均未考虑自动驾驶仪延迟。 导弹的制导控制系统如图1所示。 实际上, 在导弹执行机构工作过程中, 制导系统与控制系统之间存在响应延迟, 该延迟特性会影响导弹性能。 文献[16]利用H∞控制理论, 设计了考虑导弹自动驾驶仪动态特性的H∞鲁棒制导律。 文献[17-18]在分析导弹自动驾驶仪动态特性的基础上, 将其近似为一阶惯性环节, 设计了自适应滑模制导律。 文献[19]将导弹自动驾驶仪动态特性视为一阶惯性环节, 并将目标加速度视为外界干扰, 基于自抗扰理论设计了自抗扰制导律。 文献[20-21]基于观测器和滑模控制理论, 设计了考虑导弹一阶动态延迟特性的制导律, 同时能够以期望的角度攻击目标。 文献[22-23]在考虑角度约束和通讯延迟等情况下, 设计了饱和制导律和控制器。
除了响应延迟外, 导弹还存在过载受限的问题。 若只是简单地通过控制器对过载指令进行限幅, 必然会损失一定的最优性, 甚至还可能导致系统不稳定[24]。 所以, 在研究制导方法时, 加入过载约束才能够更好地发挥导弹的性能。 目前, 针对过载约束下的制导律进行了广泛研究。 Rusnak等[25-27]针对线性、 时不变的导弹模型, 以零脱靶量和控制能量最优为性能指标, 在加速度受限条件下推导了最优制导律的显式解。 文献[28]以弹-目相对距离和视线角速率为主要状态变量, 采用指令滤波 backstepping 方法设计了一种过载约束下的导引律。 Hexner等[29]在考虑导弹加速度约束和制导增益最大值约束等情况下, 使用线性二次随机高斯最优控制理论和随机输入描述函数(Random-Input Describing Function, RIDF)得到最优制导律。
虽然上述文献考虑了过载约束和自动驾驶仪延迟等问题, 但基本上是采用线性化或者简化的处理方法。 本文在同时考虑过载约束与自动驾驶仪延迟的情况下, 完全基于非线性模型研究了最优末制导指令在线生成方法。 首先, 基于目标静止的导弹非线性模型, 利用庞特里亚金极大值原理(Pontryagin’s Maximum Principle, PMP)建立了NOG问题的最优性条件, 并利用饱和函数将过载约束嵌入最优性条件。 其次, 通过参数化方法[12]生成满足最优性条件的飞行轨迹簇, 构建弹-目相对运动状态到最优制导指令映射关系的数据集。 然后, 利用该数据集训练神经网络, 使其拟合上述映射关系, 保证神经网络能够毫秒量级在线生成最优制导指令。 最后, 针对自动驾驶仪延迟问题, 通过微分补偿方法对神经网络下一时刻输出的最优制导指令进行估计, 从而实现快速跟踪。 值得注意的是, 本文所提方法能够实时更新状态信息, 并将弹-目相对运动状态作为神经网络的输入在线生成制导指令。 因此, 该方法同样适用于拦截小机动目标的场景, 并且无需事先得到目标的加速度信息。 针对静止目标和小机动目标, 分别采用本文所提方法与线性化方法进行仿真对比, 验证了所提方法的有效性。
1 数学模型
1.1 导弹的运动模型
在二维平面内, 弹-目相对运动的几何关系如图2所示。 其中, OXY为惯性坐标系。 为便于分析且不失一般性, 将目标位置作为坐标系原点。 M表示导弹; V, a, θ分别表示导弹的速度、 法向加速度、 速度方向角; λ∈[0, 2π]表示弹-目视线角; σ∈[-π, π]表示前置角; r表示弹-目相对距离。
用(x, y)表示导弹在惯性坐标系中的位置, 根据图2有如下关系式:
r=x2+y2
λ=arctanyx
σ=λ-θ(1)
假设导弹在末制导过程中常速运动, 其非线性运动学模型可以表示为
x·(t)=Vcosθ(t)
y·(t)=Vsinθ(t)
θ·(t)=a(t)V(2)
式中: t为时间; 上标“·”表示关于时间的导数。
过载n与法向加速度a之间满足:
n=ag(3)
式中: g为重力加速度常数。 假设过载上限为nmax, 则法向加速度上限amax=g·nmax。 因此, 法向加速度约束为
a≤amax(4)
针对自动驾驶仪跟踪制导指令时存在响应延迟的问题, 采用一阶惯性环节来近似自动驾驶仪的动力学模型:
a·(t)=u(t)-a(t)τ(5)
式中: τ为导弹自动驾驶仪动态延迟的时间常数; u为制导环节输出的加速度指令, 如图1所示。
1.2 最优制导问题描述
根据文献[5], 自由时间下控制效率最优的制导律无解。 因此, 选择将控制效率与攻击时间的权重相加作为性能指标, 即
J=∫tft0κ+12(1-κ)a2dt(6)
式中: t0为初始时刻; tf为自由的终端时刻; κ∈[0, 1]为权重常数。
导弹的初始条件可以表示为
x(t0)=x0
y(t0)=y0
θ(t0)=θ0(7)
为满足零脱靶量要求, 导弹最终应到达目标所在位置, 即
x(tf)=xT
y(tf)=yT(8)
在定义坐标系时, 将目标位置作为坐标系原点, 因此有(xT, yT)=(0, 0)。
综上, 当前的NOG问题可以描述为, 在满足状态约束式(2)、 法向加速度约束式(4)及边界条件式(7)~(8)下, 求解使得性能指标J最小的法向加速度a。
2 最优性条件
将法向加速度a作为控制量, 上述最优控制问题的Hamiltonian函数可以表示为
H=pxVcosθ+pyVsinθ+pθaV-κ+12(1-κ)a2(9)
式中: p=[px, py, pθ]T为z=[x, y, θ]T对应的伴随状态。 根据PMP, 有
z·=Hp
p·=-Hz(10)
其中, p·=-Hz可展开为
p·x=-Hx=0
p·y=-Hy=0
p·θ=-Hθ=pxVsinθ-pyVcosθ(11)
由于θ(tf)是自由的, 有如下横截条件:
pθ(tf)=0(12)
通过式(11)中前两个等式可知, px和py为常数。 考虑终端约束式(8)及横截条件式(12), 对式(11)中第3个等式积分可得
pθ(t)=pxy(t)-pyx(t)(13)
由于终端时间tf自由, 且Hamiltonian函数不显含t, 有
H≡0(14)
根据PMP, 当不考虑输入约束时, 存在最优控制a(t)满足Ha=0, 即
a(t)=pθ(t)V(1-κ)(15)
然而, 由于存在过载约束, 考虑法向加速度上限的最优控制a(t)为
a(t)=satpθ(t)V(1-κ), amax, -amax(16)
式中: sat(·)表示饱和函数, 定义为
sat(i, α, β)=α i>αi α≤i≤ββ i<β (17)
式中: i为饱和函数的输入; α为输入的上限; β为输入的下限。 式(17)可改写为如下形式:
sat(i, α, β)=12(i-β)2-(i-α)2+α+β(18)
式(18)与式(17)的分段函数完全相同。 为解决其在i=α和i=β处不可导的问题, 根据文献[30], 采用如下公式进行修正:
sat(i, α, β, δ)=12((i-α)2+δ-
(i-β)2+δ+α+β)(19)
式中: δ为保证饱和函数在i=α和i=β处可导的参数。 参数δ的取值不同, 修正后的饱和函数式(19)对式(18)的近似精度不同[31]。
利用饱和函数将过载约束嵌入最优性条件后, 最优制导指令可以表示为
a(t, δ)=satpθ(t)V(1-κ), amax, -amax, δ(20)
式中: δ>0越小, 式(20)越逼近式(16)。
得到上述一阶必要条件后, 仍然无法保证轨迹的最优性[32], 还需要建立附加的最优性条件。 根据文献[13], 对于任意一条满足一阶必要条件的轨迹, 若在某一时刻t-, 速度方向与弹-目视线共线, 则其不再满足最优性。 因此, 飞行轨迹必须满足以下附加最优性条件:
x(t-)cosθ(t-)+y(t-)sinθ(t-)
x(t-)2+y(t-)2≠1(21)
本文将满足一阶必要条件及附加最优性条件的轨迹称为最优轨迹。
3 最优末制导指令在线生成方法
基于上述最优性条件, 先利用参数化方法离线生成飞行状态到最优制导指令映射关系的数据集, 然后利用该数据集训练神经网络拟合上述映射关系, 最终通过神经网络实现最优制导指令的在线生成。
为便于后续分析, 参考文献[13]定义如下参数化微分方程组:
X·(t)=-VcosΘ(t)
Y·(t)=-VsinΘ(t)
Θ·(t)=-A(t)V(22)
式中: (X, Y)∈R2, Θ∈[0, 2π]。 最优制导指令A(t)表示为
A(t)=satpxY(t)-pyX(t)V(1-κ), amax, -amax, δ
令X(t)和Y(t)的初值为
X(0)=0
Y(0)=0(23)
令Θ(t)的初值满足如下方程:
pxVcosΘ(0)+pyVsinΘ(0)-κ=0(24)
定义参数向量q为
q=[px, py](25)
根据式(23)~(25)可知, 式(22)的解由参数[t, q]确定。 为了便于分析, 将(X(t, q), Y(t, q), Θ(t, q))表示为参数化微分方程组(22)的解, 且初始条件满足式(23)~(24)。
根据文献[13]可知, 对于任意参数向量q, 参数化轨迹(X(t, q), Y(t, q), Θ(t, q))满足第2节中的所有必要性条件和终端条件。 因此, 在式(23)~(24)定义的初始条件下对式(22)进行数值积分, 同时考虑式(21)的附加最优性条件, 即可得到一条最优轨迹。 通过在二维空间内遍历参数q, 可以获得大量最优轨迹。 将每条轨迹进行离散处理, 能够得到包含飞行状态到最优制导指令映射关系的数据集。
值得注意的是, 上文是基于惯性坐标系中导弹攻击静止目标的运动学模型得到的最优制导指令, 为了使本文提出的制导策略能够更灵活准确地应用于拦截机动目标的任务场景中, 可以将惯性坐标系下的导弹运动参数转换为弹-目相对运动参数。 根据弹-目相对运动参数生成最优制导指令, 从而实现对机动目标的精准拦截。
弹-目相对运动参数也可以用参数化形式表征, 定义如下参数化微分方程组:
R·(t, q)=VcosΩ(t, q)
Λ·(t, q)=-VsinΩ(t, q)R(t, q)
Θ·(t, q)=-A(t, q)V(26)
式中: R(t, q), Ω(t, q), Θ(t, q)分别为参数化形式的弹-目相对运动距离、 前置角以及速度方向角。 具体表达式如下:
R(t, q)=X2(t, q)+Y2(t, q)Ω(t, q)=Λ(t, q)-Θ(t, q)(27)
因此, 式(26)可以表示为
R·(t, q)=VcosΩ(t, q)
Ω·(t, q)=-VsinΩ(t, q)R(t, q)+A(t, q)V(28)
对于R(t, q)>0, 式(28)与式(22)等价。 因此, 最优制导指令A(t, q)既可以由惯性坐标系下的导弹运动参数X(t, q), Y(t, q), Θ(t, q)决定, 也可以由弹-目相对运动参数R(t, q), Ω(t, q)决定。
定义飞行状态R(t, q), Ω(t, q)到最优制导指令A(t, q)的映射关系为
f:(R, Ω)→A(29)
根据通用近似性原理[33], 可以利用上述数据集训练神经网络, 使其拟合映射关系f, 最终通过神经网络实现最优制导指令的毫秒量级在线生成。
4 考虑自动驾驶仪延迟的最优制导律
在导弹执行机构工作过程中, 制导回路生成的加速度指令是通过自动驾驶仪跟踪的。 因此, 相比于加速度指令, 实际加速度总是会存在一定的响应延迟。 常采用一阶惯性环节来近似自动驾驶仪的动态特性, 如式(5)所示。
第3节在建立飞行状态到最优制导指令映射关系时, 未考虑自动驾驶仪的响应延迟。 因此, 若将神经网络得到的法向加速度直接作为指令u代入式(5), 会导致实际加速度无法快速跟踪制导回路给出的最优加速度, 从而降低制导性能。 为解决该问题, 本文提出了一种微分补偿方法, 将式(5)改进为
a·=(uτ-a)/τ(30)
式中: uτ为考虑了自动驾驶仪延迟的指令加速度。
关于uτ的具体描述如下:
假设由于存在响应时间τ, tk时刻的实际加速度ak与当前状态下的最优加速度uk不等, 且差值为εk, 即
ak=uk+εk(31)
为实现快速跟踪, 在tk+1时刻, 期望实际加速度ak+1等于最优加速度uk+1, 即
ak+1=uk+1(32)
根据欧拉积分公式, ak+1与uk+1可以表示为
ak+1=ak+ha·k=ak+huτk-akτ(33)
uk+1=uk+hu·k(34)
式中: h为积分步长。 将式(33)~(34)代入式(32)可得
uτk=ak+τu·k-τh(ak-uk)(35)
式中: u·k为当前时刻的最优加速度uk的导数, 可以通过对神经网络生成的指令进行差分得到。 显然, 指令加速度uτk不仅与uk相关, 也与u·k相关。 正因为u·k的存在, 能够提前对uk+1进行预测, 从而使实际加速度能够快速跟踪最优加速度, 提高制导性能。
5 数值仿真与分析
分别针对静止目标与机动目标进行数值仿真, 从而验证本文提出的NOG方法在过载受限和自动驾驶仪响应延迟条件下的有效性。
5.1 不同制导方法攻击静止目标的仿真对比
20 世纪60年代, Rishel[34]从最优控制角度证明, 针对非机动目标, 比例导引律 (Proportional Navigation Guidance, PNG) 是理想系统下的最优制导律。 Lu等[35]进一步证明, 当不存在落角约束时, 导引系数N=3的PNG近似等效于横向加速度下二次性能指标最小的最优制导律。 因此, 分别采用导引系数N=3的PNG和本文提出的NOG方法在不同的初始前置角下攻击静止目标。
假设静止目标位于原点, 即xT(0)=0 m, yT(0)=0 m。 导弹在初始时刻的位置为x(0)=-3 000 m, y(0)=-4 000 m, 速度V=300 m/s, 法向加速度上限amax=5g。
图3(a)为导弹在不同初始前置角下的飞行轨迹。 可以看出, 当初始前置角的绝对值较小时, 采用两种方法得到的飞行轨迹相近。 但是随着初始前置角绝对值的增大, 两种方法生成的轨迹差异越来越明显。 因此, 分别给出初始前置角为-87°和-107°的加速度指令、 前置角以及弹-目相对距离变化曲线, 如图3(b)~(d)所示。
观察图3(a)中导弹的飞行轨迹可以看出, 在不同的初始前置角下, 两种制导方法都能够成功打击静止目标, 满足终端脱靶量要求。 然而, 如图3(b)所示, 当导弹的初始前置角较大时, PNG在初始阶段的加速度指令会达到上限, 需要对其进行限幅处理, 这将在一定程度上损失最优性。 相比较而言, 由于加入了过载约束, NOG的加速度指令不会达到饱和, 变化曲线更加平滑。
导弹在飞行过程中, 所消耗的控制能量通常表示为
J=∫tf012u(t)2dt
根据仿真计算可得, 当σ(0)=-87°时, PNG和NOG的控制能量消耗分别为1.36×104 m2/s3和1.28×104 m2/s3; 当σ(0)=-107°时, PNG和NOG的控制能量消耗分别为1.71×104 m2/s3和1.60×104 m2/s3。 显然, 当初始前置角较大时, 相比于传统的PNG方法, NOG通过引入过载约束, 可以在满足脱靶量要求的同时, 实现更小的能量消耗, 性能更优。
5.2 不同制导方法拦截机动目标的仿真对比
一般来说, 当针对机动目标时, PNG不再具有最优性。 而增强型比例导引(Augmented PNG, APNG)是一种针对机动目标的扩展型比例导引律, 其中增加了考虑机动目标的额外项。 APNG被证明可以在最小化能量消耗的同时, 消除目标机动对终端脱靶量的影响[36]。 文献[37]利用Schwartz不等式, 证明了基于垂直于弹-目视线的目标加速度保持不变这一假设条件, APNG为线性化运动模型下最小化控制能量消耗的最优解。
根据第3节可知, 本文提出的NOG方法能够将实时更新的弹-目相对运动状态输入到神经网络, 从而在线生成制导指令。 因此针对小机动目标时, NOG方法仍然适用。 下面分别采用APNG与NOG方法在相同的初始条件下拦截机动目标。 其中, APNG的制导指令表达式参考文献[38]中式(48)。
假设导弹的初始位置为x(0)=-4 000 m, y(0)=-3 000 m, 速度V=500 m/s, 初始速度方向角θ(0)=120°。 目标的初始位置为xT(0)=0 m, yT(0)=0 m, 速度VT=60 m/s, 初始速度方向角θT(0)=0°。 此时导弹的初始前置角σ(0)=-83°。 假设目标作正弦机动, 加速度为aT=-15sinπ12t+π12; 导弹的法向加速度上限amax=15g; 自动驾驶仪的响应时间τ=0.4 s。
图4(a)~(d)分别为导弹和目标的飞行轨迹、 导弹的加速度指令、 前置角以及弹-目相对距离的变化曲线。
由图4(a)可以看出, 导弹采用两种方法都能够成功拦截机动目标。 然而, 在初始阶段导弹的前置角较大时, APNG的加速度指令会达到上限。 正如5.1节所述, 对其
进行限幅处理必然会损失一定的最优性。 此外, 当导弹接近机动目标时, 弹-目相对运动状态变化迅速, APNG未考虑自动驾驶仪延迟, 因此在拦截末段的加速度指令迅速达到饱和。 相较而言, 由于NOG中考虑了自动驾驶仪延迟, 其在接近机动目标时, 加速度指令明显较小。
根据仿真结果可知, 当前场景下采用APNG的能量消耗为7.14×104 m2/s3, 采用NOG的能量消耗为6.63×104 m2/s3。 显然, 在拦截过程中, NOG可以实现更小的能量消耗, 性能更优。
值得注意的是, 根据文献[38]中关于APNG的描述可知, APNG要求已知目标的加速度信息, 但这通常难以直接获得。 相较而言, 本文提出的NOG方法只需要得到弹-目相对运动信息, 即可在线生成制导指令。 此外, 若在某一时刻t~, 导弹的速度方向垂直于弹-目视线, 即|σ(t~)|=90°, APNG可能无解。 换言之, 若导弹的初始前置角|σ(0)|>90°, APNG可能无法拦截机动目标。 为验证本文提出的NOG方法在|σ(0)|>90°时的有效性, 在两组不同的初始条件下进行仿真。
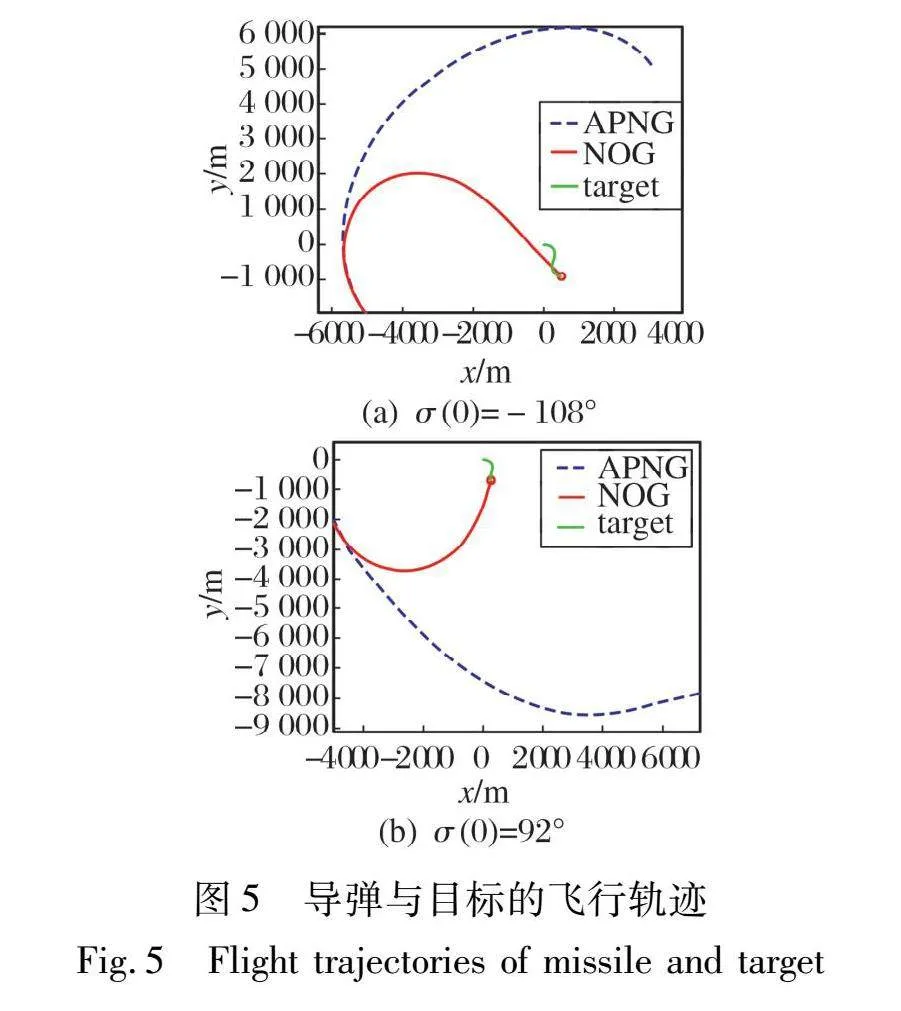
假设目标的运动状态与上文相同。 导弹的初始位置为x(0)=-5 000 m, y(0)=-2 000 m, 速度V=500 m/s。 假设场景一中导弹的初始速度方向角为θ(0)=120°, 初始前置角σ(0)=-108°; 场景二中导弹的初始速度方向角θ(0)=-70°, 初始前置角σ(0)=92°。 图5分别为导弹和目标在场景一和场景二下的飞行轨迹。
由图5可以看出, 当导弹的初始前置角|σ(0)|>90°时, APNG的轨迹逐渐偏离目标, 无法实现拦截, 而NOG仍然有效。 显然, 相比于APNG, NOG能够显著增加拦截半径, 扩大作战范围。
综上, 根据拦截小机动目标的仿真结果可以得出:
(1) 当导弹的初始前置角较大时, NOG通过引入过载约束, 可以有效避免加速度指令达到饱和。
(2) NOG考虑了自动驾驶仪延迟, 因此能够显著改善导弹接近目标时需用过载较大的问题, 同时降低了能量消耗。
(3) NOG方法无需得到目标的加速度信息即可在线生成制导指令。
(4) 当导弹的初始前置角|σ(0)|>90°时, APNG不再适用, 但应用NOG方法仍然能够实现精准拦截, 有效扩大了作战范围。
6 结 论
本文研究了自由时间下过载受限且存在自动驾驶仪延迟的非线性最优末制导指令在线生成方法。 首先, 基于参数化方法建立了最优轨迹的参数化微分方程组, 使得通过数值积分即可得到包含状态到最优制导指令映射关系的飞行轨迹数据集。 其次, 训练神经网络拟合上述映射关系, 保证神经网络能够根据实时更新的弹-目相对运动信息在线生成最优制导指令, 从而使本文提出的制导方法不仅能够用于攻击静止目标, 还可以在目标加速度未知的情况下拦截小机动目标。 针对自动驾驶仪延迟, 提出一种微分补偿法以实现快速响应。 数值仿真结果表明: 不论是针对静止目标还是小机动目标, 当导弹的初始前置角较大时, 由于引入了过载约束, 提出的NOG方法不会使加速度指令达到饱和。 考虑自动驾驶仪延迟后, 实际加速度能够快速跟踪加速度指令, 从而使导弹在接近机动目标时过载较小, 能量消耗降低。 更重要的是, 拦截小机动目标时, 能够在目标加速度未知的情况下, 应用NOG方法在线生成制导指令。 而且, 当导弹的初始前置角|σ(0)|>90°时, NOG方法仍然能够完成精准拦截, 显著扩大了作战范围。
参考文献:
[1] 亢有为, 单家元, 赵新. 一种基于角约束的三维三平面最优真比例导引方法[C]∥ 第三十四届中国控制会议, 2015: 103-108.
Kang Youwei, Shan Jiayuan, Zhao Xin. A 3D Three Planes Optimal True Proportional Navigation with Angle Constraint[C]∥ 34th Chinese Control Conference, 2015: 103-108. (in Chinese)
[2] Kim M, Grider K V. Terminal Guidance for Impact Attitude Angle Constrained Flight Trajectories[J]. IEEE Transactions on Aerospace and Electronic Systems, 1973, AES-9(6): 852-859.
[3] 郭志强, 周绍磊, 于运治, 等. 基于状态相关黎卡提方程的非线性协同制导律[J]. 中国惯性技术学报, 2018, 26(6): 822-829.
Guo Zhiqiang, Zhou Shaolei, Yu Yunzhi, et al. Nonlinear Cooperative Guidance Law Based on State-Dependent Riccati-Equation[J]. Journal of Chinese Inertial Technology, 2018, 26(6): 822-829.(in Chinese)
[4] Taub I, Shima T. Intercept Angle Missile Guidance under Time Varying Acceleration Bounds[J]. Journal of Guidance, Control, and Dynamics, 2013, 36(3): 686-699.
[5] Chen Z, Shima T. Nonlinear Optimal Guidance for Intercepting a Stationary Target[J]. Journal of Guidance, Control, and Dyna-mics, 2019, 42(11): 2418-2431.
[6] 张友安, 黄诘, 孙阳平. 带有落角约束的一般加权最优制导律[J]. 航空学报, 2014, 35(3): 848-856.
Zhang You’an, Huang Jie, Sun Yangping. Generalized Weighted Optimal Guidance Laws with Impact Angle Constraints[J]. Acta Aeronautica et Astronautica Sinica, 2014, 35(3): 848-856.(in Chinese)
[7] Oshagh M K, Shamsi M. Direct Pseudo-Spectral Method for Optimal Control of Obstacle Problem-An Optimal Control Problem Go-verned by Elliptic Variational Inequality[J]. Mathematical Methods in the Applied Sciences, 2017, 40(13): 4993-5004.
[8] 刘平, 胡云卿, 廖俊, 等. 基于两阶段自适应Gauss配点重构伪谱法的电力机车优化操纵[J]. 自动化学报, 2019, 45(12): 2344-2354.
Liu Ping, Hu Yunqing, Liao Jun, et al. Optimization Operation of Electric Locomotive Based on Two-Stage Adaptive Gauss Re-Collocation Pseudospectral Approach[J]. Acta Automatica Sinica, 2019, 45(12): 2344-2354.(in Chinese)
[9] Garg D, Patterson M, Hager W W, et al. A Unified Framework for the Numerical Solution of Optimal Control Problems Using Pseudospectral Methods[J]. Automatica, 2010, 46(11): 1843-1851.
[10] Yan H, Wu H X. Initial Adjoint-Variable Guess Technique and Its Application in Optimal Orbital Transfer[J]. Journal of Gui-dance, Control, and Dynamics, 1999, 22(3): 490-492.
[11SD/RsIsDP4mJBmDu+8dZEg==] 李惠峰, 李昭莹. 高超声速飞行器上升段最优制导间接法研究[J]. 宇航学报, 2011, 32(2): 297-302.
Li Huifeng, Li Zhaoying. Indirect Method of Optimal Ascent Guidance for Hypersonic Vehicle[J]. Journal of Astronautics, 2011, 32(2): 297-302.(in Chinese)
[12] Chen Z. Second-Order Conditions for Fuel-Optimal Control Problems with Variable Endpoints[J]. Journal of Guidance, Control, and Dynamics, 2022, 45(2): 335-347.
[13] Wang K, Chen Z, Wang H, et al. Nonlinear Optimal Guidance for Intercepting Stationary Targets with Impact-Time Constraints[J]. Journal of Guidance, Control, and Dynamics, 2022, 45(9): 1614-1626.
[14] 王坤, 段欣然, 陈征, 等. 过载和攻击时间约束下的非线性最优制导方法[J]. 系统工程与电子技术, 2024, 46(2): 649-657.
Wang Kun, Duan Xinran, Chen Zheng, et al. Nonlinear Optimal Guidance with Constraints on Overload and Impact Time[J]. Systems Engineering and Electronics, 2024, 46(2): 649-657. (in Chinese)
[15] Cheng L, Wang H, Gong S P, et al. Neural-Network-Based Nonlinear Optimal Terminal Guidance with Impact Angle Constraints[J]. IEEE Transactions on Aerospace and Electronic Systems, 2023: 1-11.
[16] 孟克子, 周荻. 考虑导弹自动驾驶仪动态特性的H∞导引律[J]. 兵工学报, 2016, 37(7): 1194-1202.
Meng Kezi, Zhou Di. H∞ Guidance Law Accounting for Dynamics of Missile Autopilot[J]. Acta Armamentarii, 2016, 37(7): 1194-1202.(in Chinese)
[17] 李炯, 张涛, 雷虎民, 等. 非奇异快速终端二阶滑模有限时间制导律[J]. 系统工程与电子技术, 2018, 40(4): 860-867.
Li Jiong, Zhang Tao, Lei Humin, et al. Nonsingular Fast Terminal Second-Order Sliding Mode Guidance Law with Finite-Time Convergence[J]. Systems Engineering and Electronics, 2018, 40(4): 860-867.(in Chinese)
[18] 佘文学, 周军, 周凤岐. 一种考虑自动驾驶仪动态特性的自适应变结构制导律[J]. 宇航学报, 2003, 24(3): 245-249.
She Wenxue, Zhou Jun, Zhou Fengqi. An Adaptive Variable Structure Guidance Law Considering Missile’s Dynamics of Autopilot[J]. Journal of Astronautics, 2003, 24(3): 245-249.(in Chinese)
[19] 王冬, 马清华, 陈韵, 等. 考虑导引头和驾驶仪动态特性的自抗扰制导律[J]. 弹箭与制导学报, 2018, 38(5): 102-106.
Wang Dong, Ma Qinghua, Chen Yun, et al. ADRC Guidance Law Based on Dynamic Characteristics of Seeker and Autopilot[J]. Journal of Projectiles, Rockets, Missiles and Guidance, 2018, 38(5): 102-106.(in Chinese)
[20] Zhang Z X, Li S H, Luo S. Composite Guidance Laws Based on Sliding Mode Control with Impact Angle Constraint and Autopilot Lag[J]. Transactions of the Institute of Measurement and Control, 2013, 35(6): 764-776.
[21] 周慧波, 宋申民, 宋俊红, 等. 基于扩张状态观测器的有限时间导引律设计[C]∥ 第25届中国控制与决策会议, 2013: 5090-5094.
Zhou Huibo, Song Shenmin, Song Junhong, et al. Design of Guidance Law with Finite Time Convergence Based on Extended State Observer[C]∥ 25th Chinese Control and Decision Conference, 2013: 5090-5094. (in Chinese)
[22] 陈宝文, 孙经广. 考虑通信延迟的多导弹协同分布饱和控制器[J]. 控制工程, 2021, 28(6): 1223-1228.
Chen Baowen, Sun Jingguang. Anti-Saturation Multi-Missile Cooperative Controller with Communication Delay[J]. Control Engineering of China, 2021, 28(6): 1223-1228.(in Chinese)
[23] 孙经广, 孟庆鹏, 李传明. 带有落角约束的反舰导弹自适应饱和制导律设计[J]. 指挥控制与仿真, 2020, 42(3): 118-122.
Sun Jingguang, Meng Qingpeng, Li Chuanming. Adaptive Saturated Guidance Law Designed for Anti-Ship Missile with Terminal Angular Constraint[J]. Command Control & Simulation, 2020, 42(3): 118-122.(in Chinese)
[24] 张宇献, 刘民, 王建辉. 具有执行器饱和特性的不确定系统预测控制器设计[J]. 控制与决策, 2009, 24(2): 217-220.
Zhang Yuxian, Liu Min, Wang Jianhui. Design of Model Predictive Controller for Uncertain Systems with Actuator Saturation[J]. Control and Decision, 2009, 24(2): 217-220.(in Chinese)
[25] Rusnak I, Meir L. Optimal Guidance for High-Order and Acceleration Constrained Missile[J]. Journal of Guidance, Control, and Dynamics, 1991, 14(3): 589-596.
[26] Rusnak I. Advanced Guidance Laws for Acceleration-Constrained Missile, Randomly Maneuvering Target and Noisy Measurements[J]. IEEE Transactions on Aerospace and Electronic Systems, 1996, 32(1): 456-464.
[27] Rusnak I, Meir L. Optimal Guidance for Acceleration Constrained Missile and Maneuvering Target[J]. IEEE Transactions on Aerospace and Electronic Systems, 1990, 26(4): 618-624.
[28] 孟克子, 周荻. 过载指令约束下的导弹导引律设计[J]. 兵工学报, 2014, 35(9): 1419-1427.
Meng Kezi, Zhou Di. Design of Missile Guidance Law Subject to Acceleration Command Constraint[J]. Acta Armamentarii, 2014, 35(9): 1419-1427.(in Chinese)
[29] Hexner G, Pila A W. Practical Stochastic Optimal Guidance Law for Bounded Acceleration Missiles[J]. Journal of Guidance, Control, and Dynamics, 2011, 34(2): 437-445.
[30] Avvakumov S N, Kiselev Y N. Boundary Value Problem for Ordinary Differential Equations with Applications to Optimal Control[J]. Spectral and Evolution Problems, 2000, 10: 147-155.
[31] Wang Z, Li Y. An Indirect Method for Inequality Constrained Optimal Control Problems[J]. IFAC-Papers On Line, 2017, 50(1): 4070-4075.
[32] Chen Z, Caillau J B, Chitour Y. L1-Minimization for Mechanical Systems[J]. SIAM Journal on Control and Optimization, 2016, 54(3): 1245-1265.
[33] Hornik K, Stinchcombe M, White H. Multilayer Feedforward Networks are Universal Approximators[J]. Neural Networks, 1989, 2(5): 359-366.
[34] Rishel R W. Optimal Terminal Guidance of an Air-to-Surface Missile[J]. Journal of Spacecraft and Rockets, 1968, 5(6): 649-654.
[35] Lu P, Chavez F R. Nonlinear Optimal Guidance[C]∥AIAA Guidance, Navigation, and Control Conference and Exhibit, 20099222067cc6035753c136b808038b8906: 618-628.
[36] 王辉, 林德福, 祁载康, 等. 时变最优的增强型比例导引及其脱靶量解析解[J]. 红外与激光工程, 2013, 42(3): 692-698.
Wang Hui, Lin Defu, Qi Zaikang, et al. Time-Varying Optimal Augmented Proportional Navigation and Miss Distance Closed-Form Solutions[J]. Infrared and Laser Engineering, 2013, 42(3): 692-698.(in Chinese)
[37] Zarchan P. Tactical and Strategic Missile Guidance[M]. 4th ed. Reston: AIAA, 2002: 149-152.
[38] Jeon I S, Cho H, Lee J I. Exact Guidance Solution for Maneuver-ing Target on Relative Virtual Frame Formulation[J]. Journal of Guidance, Control, and Dynamics, 2015, 38(7): 1330-1340.
Nonlinear Optimal Terminal Guidance Considering Autopilot Delay
Liu Juntong1, Chen Zheng1, 2*, Zhang Ze3
(1. School of Aeronautics and Astronautics, Zhejiang University, Hangzhou 310027, China;
2. Huanjiang Laboratory, Zhuji 311800, China;
3. Beijing Institute of Control and Electronic Technology, Beijing 100038, China)
Abstract: The online generation method of nonlinear optimal terminal guidance command with the overload constraint and autopilot delay is studied. Firstly, the optimality conditions of the nonlinear optimal guidance problem with stationary target are established based on the Pontryagin’s maximum principle, and the overload constraint is embedded into the optimality conditions by the saturation function. Secondly, the parametric method is used to generate the flight trajectory data set that satisfies the optimality conditions by numerical integration. Then, the neural network is trained using the data set to fit the mapping relationship between the relative motion state of the missile-target and the optimal guidance command, so as to generate the guidance command under the overload constraint within milliseconds. For the delay response of autopilot, the differential compensation method is used to estimate the optimal guidance command output by the neural network at the next moment to achieve fast tracking. Finally, the simulation results show that the proposed method can generate optimal guidance command online for both stationary targets and small maneuvering targets.
Key words: overload constraint; autopilot delay; nonlinear optimal terminal guidance; parameterized method; neural network
