
未爆子弹药图像数据集构建方法及其关键技术研究
2024-09-25 00:00:00闫小伟陈栋
航空兵器 2024年4期
















摘 要:随着计算机技术和机器视觉技术的迅速发展与应用, 探索基于“人工智能+”模型的未爆子弹药搜寻技术受到了广泛关注。 但是, 由于未爆子弹药具有一定的危险性和受军事应用的特殊性影响, 数据集构建是目前亟待解决的瓶颈问题。 本文由此出发, 分别论述了真实实物图像数据集和利用实物图片进行三维重建数据集的构建方法及流程, 重点分析了两种数据集构建过程中的相关关键技术及其优缺点, 并给出了一种利用多目相机采集目标图像和地理坐标信息, 然后利用深度学习算法进行目标特征提取、 生成三维点云和融合三维图像。 试验结果表明, 采用该方法构建的三维数据集可以有效解决未爆子弹药现有数据集数据量不足的问题, 最后展望了数据集构建方法的未来发展方向。
关键词:未爆子弹药; 图像数据集; 深度学习; 三维重建; 图像处理
中图分类号:TJ760
文献标识码: A
文章编号:1673-5048(2024)04-0021-12
DOI: 10.12132/ISSN.1673-5048.2023.0233
0 引 言
从世界上近几场局部冲突中, 可以发现子母弹已经被各军事强国研发并使用, 由此必将产生大量的未爆子弹药。 地表未爆子弹药是未爆弹药的一种, 由于其在下降过程中的稳定性且有降落伞、 飘带等装置进行增阻、 减旋, 使其在战斗部飞越过弹道顶点后缓慢降落, 落在地面上未发生爆炸且暴露在地球表面。 如果这些未爆子弹药未及时被发现和处理, 将对该地域内的人员安全造成极大的威胁。
随着人工智能技术迅猛发展, 深度学习网络在各个领域的应用日益广泛, 尤其在机器视觉领域, 已经取得了显著的进展。 在检测未爆炸物方面, 采用基于深度学习网络的无人机载平台对地面目标图像进行识别的方法是当前研究的热点。 胡聪等[1]利用基于Faster R-CNN网络结构的计算机视觉算法与无人车结合, 提出了排爆无人车自主检测未爆弹的预想。 单成之等[2]提出了一种基于关键点的未爆弹图像目标检测算法与机器人相结合的解决方案, 该方案对未爆弹图像进行初步特征提取, 尔后再利用特定网络进行特征增强, 最后采用头部预测模型对热力图、 中心点及尺寸大小分别进行预测, 检测结果较好。 曾俊等[3]设计了一种融合了无人机自主导航、 深度学习和YOLOv5目标检测算法的空基智能排爆系统, 提高了区域范围内整体的检测速度。 采取“无人+智能”的方法无需操作人员与未爆子弹药接触, 因此被认为是目前最安全、 最有效的检测方法。 然而图像识别的过程必然需要构建含有多种类型未爆子弹药在不同环境条件下的数据集, 为深度学习网络提供数据支撑。 图像数据集的来源主要包括基于真实实物的图像采集数据集、 基于实物图片的三维重建数据集和基于虚拟仿真的虚拟数据集, 由于虚拟数据集必然存在域偏移问题[4], 因此在构建数据集时通常优先考虑采集大量真实实物图片或者利用少量实物图片进行三维重建, 图像数据集构建流程如图1所示。
1 真实实物数据集的构建方法及关键技术
由于真实实物能够全面反映目标的形状、 颜色、 结构等外观状态, 使用真实实物数据集进行预测或者目标识别效果较好, 也一直广受学者的青睐。 而由于自然环
境的影响, 对真实实物进行图像采集或者从开源数据中进行挖掘, 图像中必然会掺杂一些背景噪声或其他影响因素, 并且很多时候难以穷尽目标可能处在的环境或状态, 因此在构建真实实物数据集的过程中往往会使用一些图像处理的相关技术。 如图2所示, 真实实物数据集构建的一般过程主要包括图像数据采集、 图像数据清洗、 图像数据预处理、 图像数据标注和图像数据划分等, 其中图像数据清洗和图像数据预处理是完成数据集构建的关键技术。 1.1 图像数据清洗技术
从广阔的互联网上抓取数据[5]或者在真实实物图像采集的过程中由于录入错误、 背景变化、 物体遮挡等原因将使得初始数据集中存在同一事物的图像多次出现、 同一事物的图像被标注为不同的名称、 不同事物图像不完整等问题, 影响数据可靠性。 简而言之, 数据清洗就是采用人工或技术手段将数据集中的“脏数据”清洗为“干净数据”的过程[6]。
1.1.1 重复数据清洗
数据清洗的关键环节是对重复数据进行清洗, 其主要采取“排序-合并”的思想, 常用的方法有排序邻居方法、 优先权队列方法和哈希清洗方法[7]。
(1) 排序邻居方法(Sorted Neighborhood Method, SNM)是一种常用的重复数据清洗算法[8], 首先采用近邻排序算法, 根据选择的属性作为关键字进行全排序; 其次, 使用固定大小的滑动窗口进行聚类以识别相似或重复的数据。 该方法在时间复杂度上进行了优化, 经过实验表明, 改进的排序邻居方法在相同召回率的情况下, 其时间复杂度优于传统的算法, 且清洗后的数据更符合实际情况, 能够提高数据集的准确性和可靠性, 还能节省时间和资源; 但是该方法对参数较为敏感, 不同的参数可能会导致不同的清洗结果, 由于是基于局部信息进行判断, 可能会误删某些非重复数据, 并且该方法不适合处理数据量较大的数据集。
(2) 优先权队列方法(Priority Queue Strategy, PQS)是Monge等[9]提出的一种基于Union-Find数据结构的重复数据清洗算法, 其基本思想主要是基于优先级队列的数据结构, 优先队列是一种特殊的队列, 每个元素都有一个优先权, 其不同于先进先出队列, 每次从队列中取出的是具有最高优先权的元素。 其清洗过程主要有三步: 第一步, 初始化一个空的优先队列; 第二步, 遍历数据集的所有数据, 将每个数据元素添加到优先队列中; 第三步, 依次从优先队列中取出元素, 即完成了数据的清洗。 该方法时间复杂度较小, 排序比较稳定, 其算法思想比较简单易于编写, 并且能够有效降低作业的平均等待时间, 从而可以提高系统的吞吐量; 但是该方法也存在对长作业不利, 可能会导致长作业的等待时间过长, 其需要对所有数据进行遍历, 未考虑作业的紧迫程度, 可能导致某些紧迫作业延迟。
(3) 哈希清洗方法是利用哈希算法的特性来检测和处理数据中的重复项, 该方法将数据集的每个元素都转换为一个唯一的哈希值, 然后将这些哈希值用来检测, 如果两张图像的哈希值相同或在设定的阈值内, 就认为这两张图像为重复图像, 将会被清除掉[10]。 该方法能够将数据运用哈希值高效表达, 可以快速检测和分类数据, 同时其可以将多个不同的数据映射到同一个哈希值上, 从而减少存储空间的占用, 且准确性高; 但是该方法也存在不同数据映射到同一个哈希值会出现冲突问题, 且需要计算哈希值, 从而增加计算时间。
1.1.2 缺失数据填充
因为数据未被记录、 遗漏或丢失, 以及数据采集过程中采集设备故障、 存储介质、 传输媒体故障等因素可能造成数据丢失, 在对缺失数据处理前, 了解数据缺失的机制和形式是十分必要的, 常用的数据填充方法有逻辑回归填充方法、 KNN填充方法和均值填充方法等。
(1) 逻辑回归填充方法。 对缺失数据进行预测, 并利用现有完整数据建立回归算法, 从而确定不同类别的分界线, 并根据该分界填充缺失的数据。 该逻辑回归模型是一种经典的分类模型, 可用于二分类和多分类任务[11]。 该方法计算简单, 且易于实施并行化计算; 但是该方法过于依赖完整数据, 并且只能用于数值填充。
(2) K最近邻方法(K-Nearest Neighbor, KNN)是一种经典的机器学习分类算法[12], KNN是根据“物以类聚”的思想进行分类填充的算法, 其原理是利用样本集中的训练数据对特征空间进行有监督学习的划分, 而后计算预测数据与样本集不同特征值之间的距离, 距离越小, 代表他们之间的差别越小, 属于同一簇类的概率越大, 选择距离缺失元最近的同簇数据对其进行填充[13]。 常用的距离量度方式有闵可夫斯基距离、 欧式距离、 曼哈顿距离等。 该方法简单直观, 无需估计参数, 训练时间较短, 其次, 其既可以处理分类问题, 也可以处理回归问题, 甚至适合对稀有事件进行分类; 但是该方法计算量大, 尤其是对于特征数非常多的数据, 再者当样本不平衡的时候, 对稀有类别的预测准确率较低。
(3) 均值填充方法[14]是一种比较常用的缺失数据填充方法, 其基本原理是用数据集的列或行的均值来填充该列或行中的空值。 例如, 如果某一列中存在空值, 那么可以用该列所有非空值的平均值来填充这些空值。 该方法不但实现简单、 计算高效和容易理解, 而且其不仅可以用于填充数值型数据, 还可以用于填充非数值型数据, 但其缺点也比较突出, 首先, 其对异常值比较敏感, 如果数据集中存在极端值或离群点, 使用均值填充可能会引入偏差, 其次, 其可能会改变原始数据的分布和信息, 最后, 其可能会导致估计出的平均值偏离真实值, 从而影响后续的数据分析和建模。 如图3~5所示, 采用均值填充法对地表未爆子弹药图像进行降噪、 去雾和填充处理, 效果较好。
1.1.3 基于深度学习网络的图像数据清洗
图像数据清洗中常用的深度学习网络主要有AlexNet网络和GoogLeNet网络两种。
(1) 基于AlexNet的图像数据清洗[15]。 AlexNet是由Hinton教授及其团队在2012年的ImageNet大规模图像
识别挑战赛(ILSVRC)上提出的一种卷积神经网络结构, 在图像分类任务中一骑绝尘, 以超过第二名非深度学习方法10%+的成绩震惊了整个业界。 其清洗步骤是: 第一步, 获取目标标签的至少一个标准图像; 第二步, 确定所述至少一个标准图像的聚类中心; 第三步, 提取多个待清洗图像中每一个待清洗图像的特征; 第四步, 在提取了特征之后, 根据这些特征和聚类中心, 确定每一个待清洗图像与所述至少一个标准图像的相似度值; 第五步, 基于所确定的相似度值, 从所述多个待清洗图像中选取若干个待清洗图像以形成所述目标标签的图像集。 在AlexNet模型中, 共有5个卷积层和3个全连接, 选择ReLU作为激活函数, 可以加速网络收敛, 有助于在大型数据集上训练大型模型, 综合采用重叠的池化和dropout的方法将随机神经元置零, 可以一定程度上减少了过拟合的发生。
(2) 基于GoogLeNet的图像数据清洗。 GoogLeNet[16]是谷歌团队为了参加2014年ILSVRC比赛而精心准备的卷积神经网络结构, 也是该挑战赛冠军。 其主要思想是通过构建密集的块结构来近似最优的稀疏结构, 从而达到提高性能而又不大量增加计算量的目的, 其进行图像清洗的步骤与AlexNet相同。 在GoogLeNet模型中, 共有22 层, 但没有全连接层, 其参数个数可以达到6 000万个, 是AlexNet模型的12倍, 且采用Inception模块的创新结构, 可以有效地减少参数数量, 降低过拟合的风险, 同时也能保持网络的深度和宽度。
1.1.4 小 结
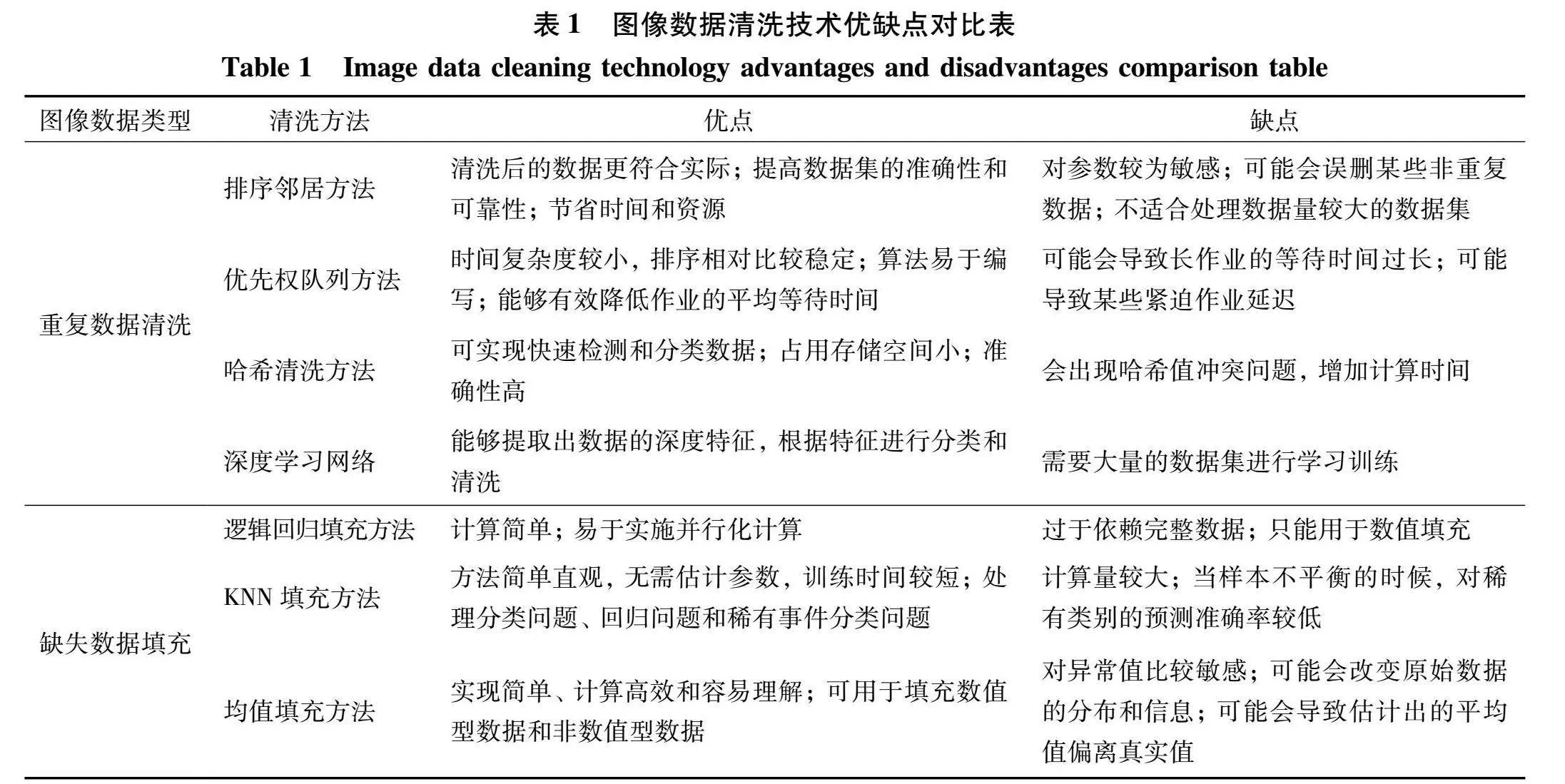
数据清洗要根据数据形式及其类型(各种清洗方法及其优缺点如表1所示), 综合分析后选择一种或多种数据清洗方法对数据集中的缺陷数据进行处理使其变成规范的干净数据, 从而消除缺陷的过程, 其目的主要是为了提高数据质量, 使其更适合做挖掘、 展示、 分析等后续工作。
1.2 图像数据预处理
图像数据清洗后得到的数据集相较于原始图像数据更加规整有序, 但是仍会存在图像分辨率有大有小、 图像格式不统一、 图像变形等问题, 此时还需对数据集中的数据进行预处理, 使其质量进一步提高。
1.2.1 数据标准化
图像数据标准化是指为了获取的图像数据能够满足实际应用需求, 对不同程度差异的图像数据进行灰度校正、 滤波去噪、 格式转换和几何变换等, 以提高图像数据的质量, 得到符合规定要求的图像数据[17]。 通过互联网开源数据爬虫抓取到的图像数据格式多种多样, 图像像素大小也五花八门, 而通过实物成像采集到的数据往往是.JPG格式, 同一成像设备采集的图像像素相对固定, 为了便于数据集的处理, 首先要将数据集中的数据进行标准化处理, 其主要由三步来完成:
第一步: 通过裁剪或填充技术, 将像素大小不同的图像数据统一为同一像素大小的数据。
第二步: 使用格式转换工具, 将格式不一样的图像数据转换为同一格式类型的数据。 数据格式的选取要根据用户实际需求确定, 传统的图像数据格式有JPG、 GIF、 PNG和HLM等, 一般获取到的数据都是这些格式, 但是这些图像数据格式的数据占用的内存非常大, 且无法存储影像信息, 极大地延长了下步图像处理的时间。 而一些专业图像格式却有很好的表现, 例如HDF(Hierarchical Data Format)图像数据格式, 其是由美国的NCSA研发的一种高效的存储和分发科学数据的新型数据格式[18], 相较于传统的图像存储格式, HDF优点有: 能够存储不同类型的图像与影像信息, 不同的机器之间可以相互传输, 共享资源, 拥有统一处理 HDF 文件格式的函数库, HDF 的特性主要包含: 自述性, 通用性, 灵活性, 扩展性和跨平台性等[19]。 如图6所示, 对采集的图像进行尺寸和格式批量处理。
第三步: 采用min-max标准化或z-score标准化模式对图像数据进行缩放, 使其数值落在某个区间内或按某种规律分布, 为后续进行模型学习时, 加快收敛, 提高模型精度[20]。
1.2.2 图像仿射变换
采用无人机载平台采集到的地表未爆子弹药实物图像通常是从上向下垂直视角拍摄的, 难以获得不同方位、 俯仰角下的未爆子弹药的图像数据, 此时需要对已采集的图像数据进行仿射变换, 将垂直视角下的图像扩展为不同视角下的图像, 以丰富数据集的数量, 提高检测的准确率。 仿射变换是线性变换的一种, 通过一系列的平移变换、 尺度缩放变换和旋转变换获得, 并且能够保持二维图像的平直度和平行度[21]。 如图7所示, 对地表未爆子弹药区域图像进行仿射变换处理。
平移变换的公式为
x′y′z′=10tx01ty001xyz(1)
式中: tx, ty为平移距离。
尺度缩放变换的公式为
x′y′1=sx000sy0001xy1(2)
式中: sx, sy为缩放尺度。
旋转变换的公式为
x′y′1=cosθ-sinθ0sinθcosθ0001xy1(3)
式中: θ为旋转角度。
1.2.3 图像数据分割
图像分割方法是根据图像的基本特征(纹理、 颜色、 形状等)之间的差异将其划分为多个互不连通的区域, 从而实现分割。 常见图像分割方法主要有边缘法、 阈值法和区域法等。
(1) 基于边缘检测的图像分割算法是通过检测目标边缘的方式来解决分割问题[22]。 不同区域之间边缘像素变化较大, 若使用傅里叶变换, 将图片从空域转换到频域, 则在空域中表现为边缘的部分被变换为高频。 常见的边缘检测算法有Sobel边缘检测、 Canny边缘检测、 Prewitt边缘检测等[23]。 虽然通过检测目标边缘的方式来实现分割目的速度快、 边缘定位准确; 但是边缘的连通性无法保证, 细节部分存在大量碎边缘。
(2) 基于阈值的图像分割算法[24], 是一项实现简单、 效率高的传统分割技术。 其实现原理是基于设定的阈值, 将像素点的像素值和阈值进行一一比较, 把图像中所有像素点划分到不同的类别, 从而实现医疗图像像素级分类, 即分割。 因此分割阈值的选择直接影响着分割结果的好坏。 其中比较具有代表性的阈值分割算法是大津算法(OTSU), 又称最大类间方差法。 其根据灰度级将图像灰度值分成两个区域, 使得区域之间差异最大, 区域内差异最小, 然后计算前景、 背景两类间方差, 找到一个使类间方差最大化的灰阶, 将此灰阶设置为分割阈值, 从而实现医疗图像分割; 然而, 基于阈值的医疗图像分割算法, 分割效果取决于阈值的设定, 仅考虑了像素值, 忽视了图像的空间特征, 对噪声敏感, 分割鲁棒性不高。
(3) 基于区域的图像分割算法[25]基本原理是通过寻找图像区域, 进而实现图像分割, 一般分为区域生长法、 区域分裂和合并。 区域生长法原理是: 首先设置代表不同生长区域的随机像素种子, 然后计算相邻生长区域像素之间的相似度, 并将像素合并到对应的区域, 最后计算新的种子像素, 开始新一轮的合并, 不停的迭代轮次一直到所有像素点被合并[26]。 算法的关键在于种子像素的选择、 区域合并的相似度准则、 区域生长停止的条件。 区域生长法适用于分割区域连通、 特征分布均匀的图像; 然而其对噪声较为敏感, 且需要人为设定种子像素, 加入主观因素的干扰, 因此该方法普适性不高。
基于以上分析, 针对边缘性比较明显的未爆子弹药通常采用边缘分割方法, 采用Sobel算子的边缘分割法对未爆子弹药图像进行边缘分割获得的图像结果如图8所示。
1.2.4 小 结
图像数据预处理的目的主要是消除图像中无关的信息, 恢复有用的真实信息, 增强有关信息的可检测性、 最大限度地简化数据, 以提高数据分析和建模的准确性、 可靠性和效率。 经过预处理后获得的部分未爆子弹药图像数据如图9所示。 在进行图像数据预处理时, 并非把所有的数据都进行标准化、 仿射变换和分割, 也不是把所有数据按照上述步骤走一遍就足够了, 而是要根据数据集中数据的情况合理选择方法和步骤, 有些还可能用到均值滤波、 高斯滤波或中值滤波等方法进行去噪和平滑处理。
2 三维重建数据集的构建方法及关键技术
地表未爆子弹药往往出现在交战地域或进行实弹射击后的落弹区内, 获得未爆子弹药的数据一般比较困难。 因此从互联网开源数据中得到的未爆子弹药的图像数据只有很少的一部分, 而采用实物成像获得的图像又会耗费大量的人力物力和时间, 并且动用武器弹药存在一定的安全风险, 因此使用未爆子弹药的真实实物采集大量的图片数据非常不明智。 此时为了保证数据集的稳定性和鲁棒性, 还要保证作业人员的安全, 一些学者把目光锁定在了利用少量实物图片进行三维重建还原成实物, 再利用还原的三维图像转化为二维图片, 从而可以得到大量的接近真实实物的图片数据实现构建数据集, 其流程如图10所示。 这个过程中最为关键的一步就是把二维图片恢复成三维的实物模型。
根据接收设备接收到的信号源不同, 可将三维重建技术分为基于主动视觉的三维图像重建技术、 基于被动视觉的三维重建技术和基于深度学习的三维重建技术。
2.1 基于主动视觉的三维图像重建技术
主动视觉就是利用特殊的光学仪器向视觉场景中投射特殊的结构光, 然后通过检测这些投射光在目标表面的图像, 或者计算回收反射信号的时间来进行深度信息获取的三维重建技术, 当前常见的主动视觉三维重建方法主要有结构光法、 激光扫描法、 飞行时间法和阴影法。
2.1.1 结构光法
结构光法是根据三角测量原理, 投影仪向目标物体投射特定的结构光照明图案, 由相机摄取被目标调制后的图案, 再通过图像处理和视觉模型求出目标物体的三维信息[27]。 结构光是一种可进行编码的光束, 包括各种特定的点、 线、 面等样式。 该方法常用的结构形式有单投影仪-单相机、 单投影仪-双相机[28]、 多投影仪-单相机[29]、 多投影仪-多相机[30]等。 该方法简单方便, 且精度高; 但是由于易受自然光照影响, 只适合在黑暗的室内场所使用, 而且随着检测距离的增加, 重建精度也会变差。
2.1.2 激光扫描法
激光扫描法, 也被称为实景复制技术, 是一种高速、 大面积、 高分辨率的三维信息获取方法。 其主要是利用激光测距的原理, 具体过程是利用激光测距仪向物体表面发射激光束, 经反射后, 激光接收设备可以接收到从物体表面各点反射回来的激光束, 通过记录激光发射和接收之间的时间差, 可以计算出目标物体表面大量密集点的深度信息, 再根据各设备之间的相对位置, 可以计算出物体各点在垂直平面的相对位置, 综合后可以得到物体的三维点云, 从多个角度进行扫描可以得到不同角度的三维点云, 再根据图像中的特征点配准技术, 从而可以重建出物体的三维结构[31]。 该方法能够重建各种表面不规则的物体, 且具有较高的重建精度; 但是由于需要处理大量的点云数据, 需要较大的计算资源和存储空间, 且重建速度较慢, 同时激光发射和接收设备成本较高。
2.1.3 飞行时间法
飞行时间法是一种用于精确测量目标距离的方法, 其主要是通过向目标发送一定频率的光脉冲, 然后用传感器接收从物体表面反射回来的光脉冲, 通过记录这些发射和接收光脉冲的飞行时间来计算与目标的距离, 其原理如图11所示。 根据光源发射器调制光脉冲方法的不同可以分为脉冲调制法和连续波调制法[32]。 该方法可以实时地测量物体的距离, 从而可以快速地进行三维重建。 其次, 其具有强大的抗干扰能力, 不仅能够在无光照的环境中使用, 而且还能在低光照、 多光谱和复杂背景环境下使用, 具有较高的稳定性; 但是由于对光线传播路径的依赖性, 如果光线被遮挡或者发生反射, 可能会影响精度, 测量的结果误差相对较大。
2.1.4 阴影法
阴影法[34]是一种用于重建三维模型的简单、 可靠且低功耗的方法。 其是一种基于弱结构光的方法, 与传统的结构光相比, 这种方法的要求比较低, 只需将一台相机面向被灯光照射的物体, 通过移动光源前面的物体来捕获移动的阴影, 再观察阴影的空间位置, 从而重建出物体的三维结构。 该方法设备需求相对简单, 操作直观, 且由于其能够获取到模型相对于空气高速运动时周围激波和尾流中旋涡的清晰图像, 该方法在空气动力学、 爆炸冲击动力学等方面有广泛的应用价值; 但是由于光线与被测对象表面不垂直, 可能会导致测量结果误差较大。
2.1.5 小 结
以上基于主动视觉的三维重建技术普遍具有高精度、 高分辨率以及强大的抗干扰能力, 均可以进行非接触式测量, 且适用于各种光照环境条件。 但是, 由于其采用主动光照射目标, 无论是结构光还是光脉冲对光线传播路径的依赖性较强, 可能会影响其精度。
2.2 基于被动视觉的三维图像重建技术
被动视觉是指不需要额外的设备发射可见光、 电磁波或声波等形式的波能量, 而是直接利用视觉传感器从客观外界获取物体反射的自然能量信息, 通过信息处理算法计算出目标的三维坐标信息。 由于其不需要其他能量设备的辅助, 因此其更轻巧, 成本也低很多。 当前常用被动视觉三维重建主要有单目视觉重建技术、 双目视觉重建技术和多目视觉重建技术等三类。
2.2.1 单目视觉重建技术
单目视觉重建技术是指只使用一个视觉传感器采集目标的图像信息, 可以使用单张图像进行重建, 也可以使用多张序列图像组合进行重建, 主要是通过提取图像中的灰度、 纹理、 轮廓及特征点等信息, 计算出图像的深度信息, 其原理如图12所示。 一般使用的单目视觉重建技术主要有纹理恢复形状法、 明暗恢复形状法和运动恢复形状法等。
(1) 纹理恢复形状法[31]是由于物体表面一般会具有各种各样的纹理结构, 这些表面结构由纹理元组成, 通过纹理元的变化可以确定表面结构的方向, 从而得到三维的表面结构。 其基本原理是表面布满纹理元的三维物体被投射到平面上时, 其表面的纹理元会发生弯曲变化, 通过观察和分析这些因透视等变形后产生的图像上的纹理变化, 通过逆向计算出深度数据, 从而恢复出物体的三维表面。 该方法能够根据单张二维图像重建出物体的三维形状, 其重建精度高、 速度快, 并且原二维图像的光照和噪声对重建效果没有影响; 但是其实用性不高, 仅能用于重建具有表面纹理特征的物体。
(2) 明暗恢复形状法是利用单目图像中的图像强度信息进行重建的方法, 该方法主要是利用单目图像中物体表面的明暗变化来恢复其表面各点的相对高度或表面法方向等参数值, 以此对目标表面三维信息进行估计, 从而得到图像的深度信息。 该方法是1970年由Minsky提出的, 经过发展演化, 现在有最小化方法、 演化方法、 局部分析法和线性化方法等分支方法[36]。 该方法也仅需一张二维图像即可进行, 其适用范围比较广泛, 且计算复杂度较低; 但是由于其主要利用图像的亮度值进行计算, 对自然光照和噪声干扰非常敏感, 且不适合在室外进行重建技术。
(3) 运动恢复形状法是利用不同视角下采集的图像, 通过提取特征点及特征点匹配, 计算出特征点间对应关系, 根据三角测量原理, 依据采集相机的姿态和特征点间的对应关系计算出各特征点的深度, 从而生成三维点云, 经过多次计算融合得到不同视角下的三维点云, 形成三维图像[37]。 该方法使用不同视角下的多张图像进行相互匹配融合, 重建的三维图像比较精确, 且能够处理动态场景; 但是经过多次计算导致计算量增大, 重建速度较慢。
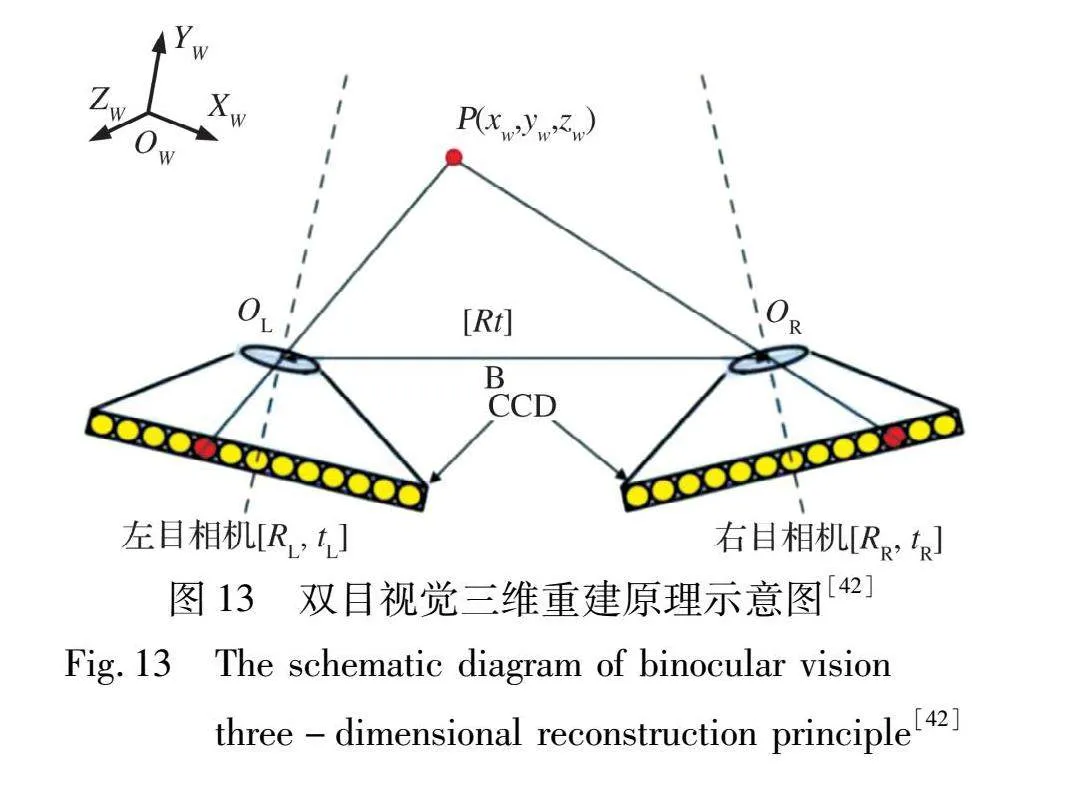
2.2.2 双目视觉重建技术
双目视觉重建技术主要是采用两个相机从不同的视角获取同一目标的两个图像, 通过匹配两张图像中对应点的像素, 计算出匹配像素的位置差, 获得视差图像, 根据三角测量原理计算出各像素点的空间位置, 生成三维点云, 从而得到三维目标信息[38], 其原理如图13所示。 该技术进行三维重建是通过模仿人眼视觉系统对物体进行三维感知, 基本原理是从两个或多个视点观察同一景物, 以获取在不同视角下的感知图像, 通过计算图像像素间的位置偏差来获取景物的三维信息[39], 其计算过程主要有图像获取、 相机标定、 图像校正、 立体匹配和三维重建计算五个步骤[40], 其中图像获取是使用两个相机同时从不同的方向获取被测物体的两幅图像; 相机标定的目的是通过计算两个相机的相对位置信息将二维图像信息转化为三维空间信息; 图像校正的目的是在图像匹配过程中使两幅图像对应的极线位于同一条线上, 只需单向进行匹配计算, 以减少匹配次数; 立体匹配的目的是在两幅图像中找到匹配的像素点, 通过计算匹配像素点的位置差得到像素点的深度值; 三维重建计算的目的是根据三角测量原理计算出各像素点的空间位置。 该方法具有设备简单, 重建效率高等优势; 但也存在人工参与监督, 经过多次计算会将误差逐级放大, 影响重建的准确度等不足[41]。
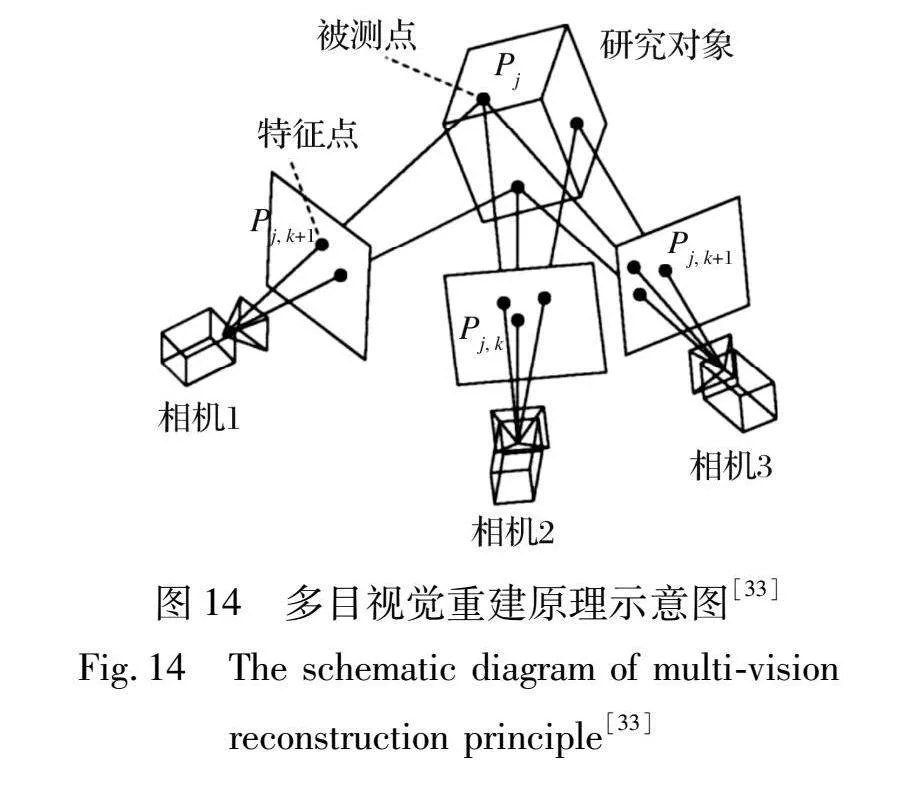
2.2.3 多目视觉重建技术
多目视觉重建技术源于双目视觉重建技术, 其是采用三个或者更多的相机同时从不同方向采集目标图像, 获取更丰富的深度信息, 实现对实际物体或场景的准确重建和建模, 其原理如图14所示。 多视图的三维重建技术, 类似人的双目定位, 相对比较容易, 其方法是先对多个视角的二维图像进行匹配, 然后通过三角测量等方法计算出每个像素点的深度信息, 最后得到目标的三维点云数据。 该方法大大地减少了测量盲区, 可以获取更多的细节信息, 并能减小双目视觉重建技术中误匹配的影响; 但同时也会使计算量大大增加, 消耗更长的时间。
2.2.4 小 结
单目视觉、 双目视觉和多目视觉都是三维重建技术的常用方法, 其在处理图像以恢复深度信息时有各自的优势和挑战。 单目视觉的本质是二维的, 其主要根据相机的成像模型和物体的真实大小来获取距离信息, 依赖于对物体的实际大小的预先知识, 可能会受到光照条件的影响; 双目视觉通过比较两个摄像机所拍摄的图像来计算视差, 从而得到深度信息, 其难点在于光照敏感以及三维点云精准匹配问题; 多目视觉类似于人的双目定位, 其通过利用多个摄像机采集到的图像来重建出三维信息, 可以提供更丰富的视角和更精确的深度信息, 但同时也需要处理更多的数据和更复杂的计算。
2.3 基于深度学习的三维重建技术
基于深度学习的三维重建技术是将深度学习方法引入传统的三维重建算法中进行改进, 或者将深度学习重建算法和传统三维重建算法进行融合。 这种技术利用大量数据建立先验知识, 将三维重建转变为编码与解码问题, 从而对物体进行三维重建。 在深度学习背景下, 图像三维重建方法能够在无需复杂的相机校准的情况下从单张或多张二维图像中重建物体的三维模型。 常用的深度学习算法主要有PointNet算法、 PointCNN算法、 DGCNN算法和VGAE算法等。
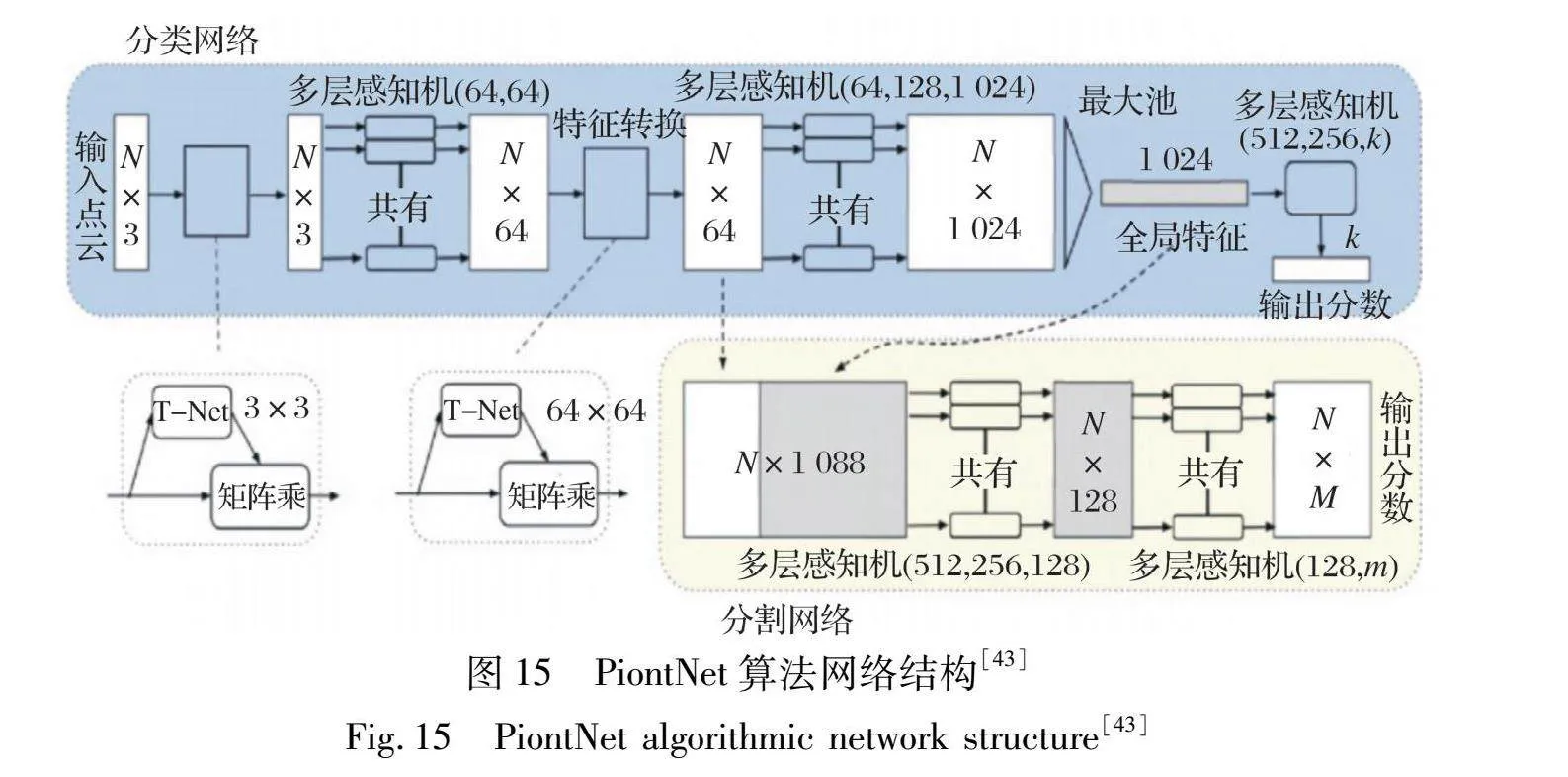
2.3.1 PointNet算法
PointNet算法[43]由斯坦福大学于2016年提出, 主要用于处理点云数据的分类和分割, 其能够直接输入三维点云数据并输出分割结果, 开创了直接将点云作为输入的算法模型, 结构如图15所示。 其原理与传统的点云处理算法相比, PointNet能够处理点云中的无序点集, 不受点的排列顺序影响, 能通过使用最大池化操作, 捕捉点云数据中的局部和全局特征信息; 能够处理不同数量和不同分布的点云数据, 具有较强的泛化能力; 但该算法对于点云数据的局部特征提取能力不足。 后来提出的PointNet++算法是一种分层次的结构, 采用下采样和区域划分的方法, 在局部区域内可以进行特征提取[44], 但其仍然是独立进行的, 忽略了点对的关联关系。
2.3.2 PointCNN算法
PointCNN算法[45]仍是对点云数据进行处理, 并不是将点云数据转化为其他形式的数据, 而是直接对无序点云进行一个X操作, 将其转化为规则的数据集。 其主要包括特征提取和X矩阵训练。 在特征提取阶段, 利用空间-局部关联的方式, 通过X-Conv操作符对输入点和特征进行加权和置换, 将输入点转换为规范的顺序。 然后在X矩阵训练阶段, 该网络利用K近邻的方法实现结构化, 并在X操作后处理整个数据集。 此外, 该算法还采用了分层卷积和X卷积算子来提高模型的性能, 可以在保留点云数据的局部信息的同时, 有效地减少了模型的参数数量, 从而可以提高模型的训练效率和泛化能力; 但是该方法在处理数据时可能会丢失位置信息, 其排列后的点云顺序存在误差。
2.3.3 DGCNN算法
DGCNN算法, 全称为Dynamic Graph CNN算法[46], 其主要思想是每一层图结构均是采取距离计算来确定节点的近邻, 从而可以动态建立点云图结构, 以便更好地捕获点云间的几何关系。 其次, 该算法引入了Edge Conv模块, 其融合了局部邻居信息, 通过堆叠或循环使用, 来建立点与点之间的拓扑关系, 从而提取到全局的形状信息, 可以增强表征的能力, 同时该算法可以端到端地处理点云数据, 直接对原始点云数据进行学习, 并能够捕获局部几何特征, 能更深入地理解点云数据的内在特性; 但是该方法也存在计算量大、 占用内存等问题。
2.3.4 VGAE算法
VGAE算法, 即变分图自编码器算法[47], 其是为了解决标准自动编码器无法直接处理低维向量图的问题, 在变分自编码器的基础上改进而来, 主要思想是将图卷积神经网络与变分自编码器相结合, 优势互补, 其模型训练的步骤主要有编码、 变分自编码和解码。 其中编码是将低维向量图中的每个节点和边的特征向量通过多层GCN来传递和聚合信息, 以学习其潜在特征; 变分自编码是将每个节点及其邻边的特征向量映射到潜在空间中, 并在其中进行采样, 以获取节点和边的嵌入特征; 解码是将每个节点和边的嵌入向量通过多层GCN进行信息传递和聚合, 从而生成重构的图像。 该算法可以通过调整超参数以适应不同类型的图像重建, 且在不完整的数据集上进行训练仍具有较好的鲁棒性; 但是该方法也存在模型相对较为复杂, 需要更多的计算资源和时间进行训练, 同时对具有复杂拓扑结构的图像处理能力不足。
2.4 基于多目视觉的未爆子弹药智能三维重建技术
通过对主动视觉、 被动视觉和深度学习的三维重建技术进行梳理对比(如表2所示), 发现其在对目标进行三维重建时均存在一定的不足, 为了弥补其不足, 提高三维重建的效率, 本文采取多目视觉与深度学习算法相结合, 通过对五种视角对目标进行成像, 尔后利用深度学习算法对目标进行特征提取, 生成三维图像点云, 最后将点云融合生成三维图像, 其流程如图16~17所示。
基于深度学习的三维重建技术是将深度学习算法与三维重建技术相结合, 充分利用深度学习算法分析提取图像的深层特征, 再利用三维重建技术将图像特征进行聚合, 从而生成完整的图像。 虽然对图像信息提取特征的算法有很多, 也都能直接将图像作为输入, 直接进行计算, 但是在进行图像操作之前仍要根据需求及特点, 结合各种算法使用对象、 运行环境及性能合理选择, 确保所使用的算法能够完成特定任务。
3 结论及展望
数据集是深度学习网络进行训练、 验证、 评估的基础, 网络模型通过对目标数据集的训练可以有效地提取出目标的深层特征, 通过对深层特征的学习来调整模型中各变量之间的权重系数以达到最优组合, 从而实现精确检测与定位目标的目的。 目标数据集的优劣直接关系到深度学习模型检测识别的效率和精度, 由于没有通用的未爆子弹药数据集, 互联网上的相关开源数据也比较少, 因此构建数据充足的、 精确的、 规范的未爆子弹药专用数据集对于进行未爆子弹药快速智能检测与定位具有十分重要的意义。
随着大数据时代的不断发展演进, 数据量将会呈指数级增长, 同时数据的价值和保护也会引起越来越多的重视, 未来对于数据集的构建方法会根据数据量的增长而变得越来越复杂多样。
一是互联网爬虫算法会更加智能高效。 面对互联网上庞大的数据量, 仅靠固定的搜索策略爬虫不但抓取的数据数量较小、 形式单一, 而且会耗费大量的时间, 并且有些爬虫对搜索的关键词比较敏感, 不能从语义的角度灵活改进关键词, 这将使得其查准率和查群率都比较低, 未来将会开发出能够根据语义灵活改进主题关键词且能够兼容抓取各种数据类型的算法, 并且能够根据用户需求直接生成规范化的数据集。
二是三维虚拟数据集将会更加丰富全面。 由于通过真实实物图像采集获得的数据量比较少, 数据及其所处环境比较单一, 且会耗费大量的人力、 物力和时间用于数据采集, 而采用真实实物图片进行三维重建可以获得与真实实物一样包含大量详细特征的数据, 能够保证数据质量的同时不需要构建庞大的采集系统, 还可以根据自身需求进行形状变换和更换数据背景, 数据内容会更加充足精确。
三是虚拟仿真数据集将会更加安全高效。 随着对数据价值的重视越来越高, 数据的安全保密要求也会越来越高, 数据产权的保护也会得到重视, 通用开源数据集虽然仍然可以使用, 但是越来越多的将会是构建专用数据集, 为了能够快速构建所需的数据集, 将会激发学者研究虚拟仿真的方法, 虚拟的数据也将会越来越逼真高效, 数据的质量也将会越来越高。
参考文献:
[1] 胡聪, 何晓晖, 邵发明, 等. 基于Faster R-CNN的未爆弹检测[J]. 机电产品开发与创新, 2021, 34(5): 105-107.
Hu Cong, He Xiaohui, Shao Faming, et al. Unexploded Ordnance Detection Based on Faster R-CNN[J]. Development & Innovation of Machinery & Electrical Products, 2021, 34(5): 105-107. (in Chinese)
[2] 单成之, 张健. 基于关键点的未爆弹图像目标检测算法[J]. 现代计算机, 2023, 29(1): 39-44.
Shan Chengzhi, Zhang Jian. An Algorithm for Object Detection in Unexploded Bombs Images Based on Key Points[J]. Modern Computer, 2023, 29(1): 39-44. (in Chinese)
[3] 曾俊, 卢瑞涛, 杨小冈, 等. 六旋翼无人机空基智能排爆系统设计与实现[J]. 电光与控制, 2023, 30(5): 61-65.
Zeng Jun, Lu Ruitao, Yang Xiaogang, et al. Design and Implementation of Air-Based Intelligent EOD System Based on Six-Rotor UAV[J]. Electronics Optics & Control, 2023, 30(5): 61-65. (in Chinese)
[4] 彭亚茹. 基于深度学习的零件表面缺陷检测图像增强技术研究[D]. 武汉: 华中科技大学, 2022: 3-6.
Peng Yaru. Research on Image Enhancement Technology of Parts Surface Defect Detection Based on Deep Learning[D]. Wuhan: Huazhong University of Science and Technology, 2022: 3-6. (in Chinese)
[5] 潘晓英, 陈柳, 余慧敏, 等. 主题爬虫技术研究综述[J]. 计算机应用研究, 2020, 37(4): 961-965.
Pan Xiaoying, Chen Liu, Yu Huimin, et al. Survey on Research of Topic Crawling Technique[J]. Application Research of Computers, 2020, 37(4): 961-965. (in Chinese)
[6] Wang H Z, Li M D, Bu Y Y, et al. Cleanix[J]. ACM SIGMOD Record, 2016, 44(4): 35-40.
[7] 刘峰. 智慧校园背景下的数据清洗关键技术研究[D]. 杭州: 杭州电子科技大学, 2022: 13-23.
Liu Feng. Research on Key Technologies of Data Cleaning in the Background of Smart Campus[D]. Hangzhou: Hangzhou Dianzi University, 2022: 13-23. (in Chinese)
[8] 沈沛, 毛海涛, 胡文林, 等. 面向时序的相似重复数据清洗算法优化[J]. 计算机时代, 2022(9): 68-72.
Shen Pei, Mao Haitao, Hu Wenlin, et al. Time-Series-Oriented Duplicate Data Cleaning Algorithm Optimization[J]. Computer Era, 2022(9): 68-72. (in Chinese)
[9] 周世杰, 娄渊胜. 基于字段过滤和伸缩窗口的SNM算法优化[J]. 计算机工程与科学, 2022, 44(4): 699-706.
Zhou Shijie, Lou Yuansheng. SNM Algorithm Optimization Based on Field Filtering and Scaling Window[J]. Computer Engineering & Science, 2022, 44(4): 699-706. (in Chinese)
[10] 罗正东. 大规模食品图像数据集构建及识别方法研究[D]. 北京: 中国科学院大学, 2020: 18-19.
Luo Zhengdong. Research on Large-Scale Food Image Dataset Construction and Recognition[D]. Beijing: University of Chinese Academy of Sciences, 2020: 18-19. (in Chinese)
[11] Midi H, Sarkar S K, Rana S. Collinearity Diagnostics of Binary Logistic Regression Model[J]. Journal of Interdisciplinary Mathematics, 2010, 13(3): 253-267.
[12] Guo G D, Wang H, Bell D, et al. KNN Model-Based Approach in Classification[C]∥OTM Confederated International Conferences “On the Move to Meaningful Internet Systems”, 2003: 986-996.
[13] Song J Y, Yu Q, Bao R Y. The Detection Algorithms for Similar Duplicate Data[C]∥6th International Conference on Systems and Informatics (ICSAI), 2019: 1534-1542.
[14] 熊中敏, 郭怀宇, 吴月欣. 缺失数据处理方法研究综述[J]. 计算机工程与应用, 2021, 57(14): 27-38.
Xiong Zhongmin, Guo Huaiyu, Wu Yuexin. Review of Missing Data Processing Methods[J]. Computer Engineering and Applications, 2021, 57(14): 27-38. (in Chinese)
[15] 余华擎. 基于深度学习的图像数据清洗方法研究[D]. 北京: 北京工业大学, 2018: 8-22.
Yu Huaqing. Research on Cleaning Image Data Based on Deep Learning[D]. Beijing: Beijing University of Technology, 2018: 8-22. (in Chinese)
[16] 梁雪慧, 程云泽, 张瑞杰, 等. 基于卷积神经网络的桥梁裂缝识别和测量方法[J]. 计算机应用, 2020, 40(4): 1056-1061.
Liang Xuehui, Cheng Yunze, Zhang Ruijie, et al. Bridge Crack Classification and Measurement Method Based on Deep Convolutional Neural Network[J]. Journal of Computer Applications, 2020, 40(4): 1056-1061. (in Chinese)
[17]汤国安, 张友顺, 刘咏梅. 遥感数字图像处理[M]. 北京: 科学出版社, 2004: 12-20.
Tong Guoan, Zhang Youshun, Liu Yongmei. Remote Sensing Digi-tal Image Processing[M]. Beijing: Science Press, 2004: 12-20. (in Chinese)
[18] 陈长吉. 适用于深度学习的数据预处理并行算法实现及性能优化[D]. 上海: 上海海洋大学, 2018: 20-21.
Chen Changji. Data Preprocessing Parallel Algorithm Implementation and Performance Optimization for Deep Learning[D]. Shanghai: Shanghai Ocean University, 2018: 20-21. (in Chinese)
[19] 郭经. 国外遥感数据格式标准及启示[J]. 航天标准化, 2011(4): 29-31.
Guo Jing. Foreign Remote Sensing Data Format Standards and Its Enlightenment[J]. Aerospace Standardization, 2011(4): 29-31. (in Chinese)
[20] 吕念祖. 基于深度学习的医学图像分割算法研究[D]. 绵阳: 西南科技大学, 2021: 9.
Lü Nianzu. Research on Medical Image Segmentation Algorithm Based on Deep Learning[D]. Mianyang: Southwest University of Science and Technology, 2021: 9. (in Chinese)
[21] 张玉莲. 光学图像海面舰船目标智能检测与识别方法研究[D]. 长春: 中国科学院大学(中国科学院长春光学精密机械与物理研究所), 2021: 44-47.
Zhang Yulian. Research on Intelligent Detection and Recognition Methods of Ship Targets on the Sea Surface in Optical Images[D]. Changchun: Changchun Institute of Optics, Fine Mechanics and Physics, Chinese Academy of Sciences, 2021: 44-47. (in Chinese)
[22] 黄成, 王红梅. 干扰条件下的红外目标检测方法研究[J]. 航空兵器, 2017(5): 31-36.
Huang Cheng, Wang Hongmei. Research on Infrared Target Detection Method under Jamming Condition[J]. Aero Weaponry, 2017(5): 31-36. (in Chinese)
[23] 胡学龙. 数字图像处理[M]. 4版. 北京: 电子工业出版社, 2020: 5, 23-33.
Hu Xuelong. Digital Image Processing[M]. 4th ed. Beijing: Publishing House of Electronics Industry, 2020: 5, 23-33. (in Chinese)
[24] 卢建宏, 刘海鹏, 王蒙. 改进海鸥算法的多阈值图像分割算法[J]. 光电子·激光, 2022, 33(9): 932-939.
Lu Jianhong, Liu Haipeng, Wang Meng. Multi-Threshold Image Segmentation Based on Improved Seagull Optimization Algorithm[J]. Journal of Optoelectronics·Laser, 2022, 33(9): 932-939. (in Chinese)
[25] 张婷, 秦涵书, 赵若璇. 基于多尺度注意力融合网络的胃癌病理图像分割方法[J]. 电子技术应用, 2023, 46(9): 46-52.
Zhang Ting, Qin Hanshu, Zhao Ruoxuan. Gastric Cancer Pathological Image Segmentation Method Based on Multi-Scale Attention Fusion Network[J]. Application of Electronic Technique, 2023, 46(9): 46-52. (in Chinese)
[26] 汪凌艳, 徐贵力, 王彪, 等. 基于机器视觉的无人机红外合作目标分割方法研究[J]. 航空兵器, 2011(5): 32-35.
Wang Lingyan, Xu Guili, Wang Biao, et al. Research on Segmentation of UAV’s IR Cooperative Target Based on Machine Vision[J]. Aero Weaponry, 2011(5): 32-35. (in Chinese)
[27] 卢荣胜, 史艳琼, 胡海兵. 机器人视觉三维成像技术综述[J]. 激光与光电子学进展, 2020, 57(4): 040001.
Lu Rongsheng, Shi Yanqiong, Hu Haibing. Review of Three-Dimensional Imaging Techniques for Robotic Vision[J]. Laser & Optoelectronics Progress, 2020, 57(4): 040001. (in Chinese)
[28] Zhong K, Li Z W, Zhou X H, et al. Enhanced Phase Measurement Profilometry for Industrial 3D Inspection Automation[J]. The International Journal of Advanced Manufacturing Technology, 2015, 76(9): 1563-1574.
[29] Servin M, Padilla M, Garnica G, et al. Profilometry of Three-Dimensional Discontinuous Solids by Combining Two-Steps Temporal Phase Unwrapping, Co-Phased Profilometry and Phase-Shifting Interferometry[J]. Optics and Lasers in Engineering, 2016, 87: 75-82.
[30] Servin M, Garnica G, Estrada J C, et al. Coherent Digital Demodulation of Single-Camera N-Projections for 3D-Object Shape Measurement: Co-Phased Profilometry[J]. Optics Express, 2013, 21(21): 24873-24878.
[31] 郑太雄, 黄帅, 李永福, 等. 基于视觉的三维重建关键技术研究综述[J]. 自动化学报, 2020, 46(4): 631-652.
Zheng Taixiong, Huang Shuai, Li Yongfu, et al. Key Techniques for Vision Based 3D Reconstruction: A Review[J]. Acta Automatica Sinica, 2020, 46(4): 631-652. (in Chinese)
[32] 段志坚. 基于3D-TOF图像传感器采集系统的设计与实现[D]. 湘潭: 湘潭大学, 2015: 7-10.
Duan Zhijian. The Implementation and Design of Acquisition System Based on 3D-TOF Image Sensor[D]. Xiangtan: Xiangtan University, 2015: 7-10. (in Chinese)
[33] 刘志海, 代振锐, 田绍鲁, 等. 非接触式三维重建技术综述[J]. 科学技术与工程, 2022, 22(23): 9897-9908.
Liu Zhihai, Dai Zhenrui, Tian Shaolu, et al. Review of Non-Contact Three-Dimensional Reconstruction Techniques[J]. Science Technology and Engineering, 2022, 22(23): 9897-9908. (in Chinese)
[34] 沈刘晶, 梅海平, 任益充, 等. 激光阴影法探测大气湍流中二维风矢量的可行性[J]. 中国激光, 2021, 48(13): 1304004.
Shen Liujing, Mei Haiping, Ren Yichong, et al. Feasibility of Laser Shadow Method to Detect Two-Dimensional Wind Vector in Atmospheric Turbulence[J]. Chinese Journal of Lasers, 2021, 48(13): 1304004. (in Chinese)
[35] 徐丽学. 基于机器学习的水下单目视觉感知技术研究[D]. 哈尔滨: 哈尔滨工程大学, 2019: 11-12.
Xu Lixue. Research on Perception of Underwater Monocular Vision Based on Machine Learning[D]. Harbin: Harbin Engineering University, 2019: 11-12. (in Chinese)
[36] Zhang R, Tsai P S, Cryer J E, et al. Shape-from-Shading: A Survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1999, 21(8): 690-706.
[37] 陈辉, 王婷婷, 代作晓, 等. 基于运动恢复结构的无规则植物叶片面积三维测量方法[J]. 农业机械学报, 2021, 52(4): 230-238.
Chen Hui, Wang Tingting, Dai Zuoxiao, et al. 3D Measurement Method for Area of Irregular Plant Leaf Based on Structure from Motion[J]. Transactions of the Chinese Society for Agricultural Machinery, 2021, 52(4): 230-238. (in Chinese)
[38] 刘欢. 基于双目视觉立体匹配算法的研究与应用[D]. 哈尔滨: 哈尔滨工业大学, 2018: 8-10.
Liu Huan. The Research and Application of Stereo-Matching Algorithm Based on Binocular Vision[D]. Harbin: Harbin Institute of Technology, 2018: 8-10. (in Chinese)
[39] 张文明, 刘彬, 李海滨. 基于双目视觉的三维重建中特征点提取及匹配算法的研究[J]. 光学技术, 2008, 34(2): 181-185.
Zhang Wenming, Liu Bin, Li Haibin. Characteristic Point Extracts and the Match Algorithm Based on the Binocular Vision in Three Dimensional Reconstruction[J]. Optical Technique, 2008, 34(2): 181-185. (in Chinese)
[40] 丁苏楠. 基于双目视觉的散乱工件识别与定位技术研究[D]. 无锡: 江南大学, 2020: 26-28.
Ding Sunan. Research on Recognition and Orientation Technology of Scattered Workpieces Based on Binocular Vision[D]. Wuxi: Jiangnan University, 2020: 26-28. (in Chinese)
[41] 李明阳, 陈伟, 王珊珊, 等. 视觉深度学习的三维重建方法综述[J]. 计算机科学与探索, 2023, 17(2): 279-302.
Li Mingyang, Chen Wei, Wang Shanshan, et al. Survey on 3D Reconstruction Methods Based on Visual Deep Learning[J]. Journal of Frontiers of Computer Science and Technology, 2023, 17(2): 279-302. (in Chinese)
[42] 沙欧. 基于双目线结构光的三维重建及其关键技术研究[D]. 长春: 中国科学院大学(中国科学院长春光学精密机械与物理研究所), 2022: 24.
Sha Ou. Research of 3D Reconstruction and Its Key Technologies Based on Binocular and Linear Structured Light[D]. Changchun: Changchun Institute of Optics, Fine Mechanics and Physics, Chinese Academy of Sciences, 2022: 24. (in Chinese)
[43] 王红霄. 基于深度学习的点云场景分割方法研究[D]. 西安: 西安理工大学, 2022: 2-3.
Wang Hongxiao. Research on Point Cloud Scene Segmentation Method Based on Deep Learning[D]. Xi’an: Xi’an University of Technology, 2022: 2-3. (in Chinese)
[44] 杨玺, 雷航, 钱伟中, 等. 基于深度霍夫优化投票的三维时敏单目标跟踪[J]. 航空兵器, 2022, 29(2): 45-51.
Yang Xi, Lei Hang, Qian Weizhong, et al. Time-Sensitive 3D Single Target Tracking Based on Deep Hough Optimized Voting[J]. Aero Weaponry, 2022, 29(2): 45-51. (in Chinese)
[45] 白静, 邵会会, 姬卉, 等. 面向三维点云的端到端细粒度分类网络[J]. 计算机辅助设计与图形学学报, 2023, 35(1): 128-134.
Bai Jing, Shao Huihui, Ji Hui, et al. An End-to-End Fine-Grained Classification Network for 3D Point Clouds[J]. Journal of Computer-Aided Design & Computer Graphics, 2023, 35(1): 128-134. (in Chinese)
[46] Wang Y, Sun Y B, Liu Z W, et al. Dynamic Graph CNN for Learning on Point Clouds[J]. ACM Transactions on Graphics, 2019, 38(5): 146.
[47] 胡坚. 基于图神经网络的虚拟网络嵌入模型与算法研究[D]. 昆明: 云南财经大学, 2023: 20-22.
Hu Jian. Research on Virtual Network Embedding Model and Algorithm Based on Graph Neural Network[D]. Kunming: Yunnan University of Finance and Economics, 2023: 20-22. (in Chinese)
Research on the Construction Method and Key Technologies of
Unexploded Submunition Image Dataset
Yan Xiaowei, Chen Dong*
(Laboratory of Guidance Control and Information Perception Technology of High Overload Projectiles,
PLA Army Academy of Artillery and Air Defense, Hefei 230031, China)
Abstract:
With the rapid development and application of computer technology and machine vision technology, the exploration of unexploded submunition search technology based on “artificial intelligence +” model has received extensive attention. However, due to the danger of unexploded submunitions and the particularity of military applications, data set construction is a bottleneck problem that needs to be solved urgently. Based on this, the paper discusses the construction methods and processes of real physical image data sets and three-dimensional reconstruction data sets using physical images. It focuses on the analysis of the key technologies and their advantages and disadvantages in the construction process of the two data sets. A multi-camera is used to collect the target image and geographic coordinate information, and then the deep learning algorithm is used to extract the target feature, generate the three-dimensional point cloud and fuse the three-dimensional image. The experimental results show that the three-dimensional data set constructed by this method can effectively solve the problem of insufficient data volume of the existing data set of unexploded submunitions. Finally, the future development direction of the data set construction method is prospected.
Key words: unexploded submunitions; image dataset; deep learning; three-dimensional reconstruction; image processing
