
基于多目标优化加权软投票集成算法的信用债违约预警研究
2024-09-20 00:00:00郑怡昕王重仁
现代电子技术 2024年8期

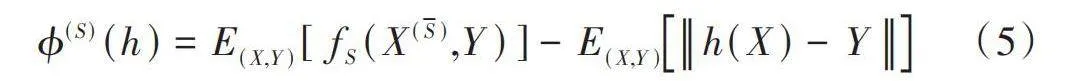




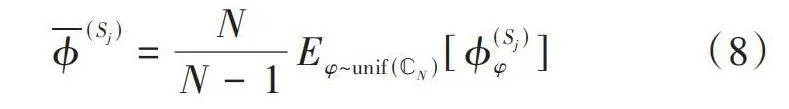






摘" 要: 为了提高信用债违约预测的准确性和稳定性,便于金融风险管理,以2014年1月1日—2021年12月31日的信用债为研究对象,提出一种基于多目标优化的加权软投票集成算法。该算法通过计算每个基分类器的模糊密度来量化其识别能力,并使用多目标粒子群算法来求解基分类器的权重。将所提算法与其他单一分类器如支持向量机、逻辑回归、高斯贝叶斯、MLP,以及其他集成算法如投票类集成算法(voting)和stacking算法进行比较,采用期望PFI算法进行特征重要度分析。结果表明,加权软投票集成算法在信用债违约预测中表现出色,不仅提升了单一算法的性能,且相对于其他集成算法,具有更高的准确性、精确度和AUC值。违约前主体评级、交易所、违约前债项评级、总资产周转率、货币资金、净资产增长率、经营活动现金流量占营收比、GDP、PPI、注册地、短期国债利率、宏观经济景气指数(先行指数)、债券类型和所属行业的特征重要度较高,在信用债违约中值得关注。该研究可为金融风险预测提供一种有效方法,对于投资者和金融机构的风险预警具有重要参考意义。
关键词: 金融风险管理; 信用债违约预警; 加权软投票集成算法; 多目标优化; 模糊密度; 期望PFI算法
中图分类号: TN911.1⁃34; TP18" " " " " " " " " "文献标识码: A" " " " " " " " " " "文章编号: 1004⁃373X(2024)08⁃0043⁃06
Research on credit bond default warning based on multi objective optimization weighted soft voting integration algorithm
ZHENG Yixin, WANG Chongren
(Shandong University of Finance and Economics, Jinan 250002, China)
Abstract: In order to enhance the accuracy and stability of credit bond default prediction for the purpose of financial risk management, a multi⁃objective optimized weighted soft voting ensemble algorithm is proposed by taking the credit bonds (January 1, 2014, to December 31, 2021) as the object of study. In this algorithm, the recognition capability of each base classifier is quantified by calculating their fuzzy densities, and the multi⁃objective particle swarm optimization algorithm is used to slove the weights of the base classifiers. In comparison with other individual classifiers such as support vector machine, logistic regression, Gaussian naive bayes, multi⁃layer perceptron (MLP), as well as other ensemble algorithms like voting and stacking, feature importance analysis is conducted by means of the expected permutation feature importance (PFI) algorithm. The results indicate that the weighted soft voting ensemble algorithm exhibits outstanding performance in credit bond default prediction. It not only enhances the performance of individual algorithms but also demonstrates higher accuracy, precision, and AUC values compared to other ensemble algorithms. Features with higher importance in credit bond default prediction include the issuer's credit rating, exchange, bond rating prior to default, total asset turnover ratio, monetary funds, net asset growth rate, operating cash flow as a percentage of revenue, GDP, PPI, registered location, short⁃term government bond interest rates, leading economic indicators, bond type, and industry sector. This research can provide an effective approach for financial risk prediction, offering valuable insights for investors and financial institutions in the risk warning.
Keywords: financial risk management; credit bond default warning; weighted soft voting ensemble algorithm; multi objective optimization; fuzzy density; expected PFI algorithm
0" 引" 言
信用债作为我国企业直接融资的重要工具,在维持实体经济的健康发展,解决企业融资难、融资贵等方面发挥着重要作用。自2014年“11超日债”首支信用债违约以来,信用债违约预警一直是学术界共同关注的研究热点。郑煜和吴世农使用Fisher模型与Logistic模型,基于财务信息和非财务信息预测信用债违约,发现Logistic模型整体判别效果优于Fisher模型[1];周荣喜等通过Xgboost算法构建信用债违约预警模型,可较好地识别我国信用债风险[2];Jiang等在U⁃MIDAS logistic回归框架中加入群组LASSO惩罚项,得到的U⁃MIDAS⁃Logit⁃GL模型成功地预测了中国大陆上市公司的违约情况[3];A. Nazemi等使用逆高斯回归、随机森林、稀疏幂期望传播和支持向量回归,可预测违约公司债券的追偿率的时间点[4]。另外,还有很多研究通过选择集成模型来提升整体预测性能。O. V. Chukwudi等以朴素贝叶斯和支持向量机来构建加权投票集成分类模型[5],该模型的性能精度优于原始模型;B. C. Kim构建了包含6个众所周知的卷积神经网络模型的软投票集成分类器,在测试集的分类表现出98.13%的准确率[6]。刘晓等以随机森林算法、梯度提升决策树算法与贝叶斯算法作为基分类器进行stacking融合,并和其他单层集成算法如随机森林、GBDT进行比较[7],得出双重集成stacking相对底层的单次集成总体精确度提升了1%~8%。stacking集成算法还可以从多模型集成的角度提高预测性能[8],如丁岚等采用Logistic回归、决策树和支持向量机作为基分类器,以支持向量机作为次级学习器,构建一个stacking集成框架用于违约风险评估模型,其预测性能优于单一学习器[9]。
stacking和voting可用于异质集成算法,然而在信用债违约预测中,更多文献偏向选择stacking进行模型集成。为了探索voting集成在信用债违约领域的应用,本文建立一种软投票(soft⁃voting)集成算法,在各个分类器模糊密度的基础上确定各个分类器的权重,建立一种基于多目标优化的加权软投票集成算法来预测中国信用债违约,并对该模型进行特征重要性分析。
1" 相关理论
1.1" 加权软投票集成算法
假定一个空间S存在有M个不同类别的样本x,即[S=C1⋃C2⋃…⋃CM],其中[Cm]表示第m类,[1≤m≤M];且有K个基分类器[e1,e2,…,eK],基分类器[ek]对样本x分类类别为m的后验概率为[pkm(x),1≤k≤K,1≤m≤M]。[ωk]为分类器[ek]的权重,在加权软投票集成算法中,样本x被预测为类别m的概率[Pm(x)]公式如下:
[Pm(x)=k=1Kωkpkm(x)]" " " " " " " (1)
每个样本选择具有最高加权投票概率的类别作为最终分类决策,公式如下:
[E(x)=maxjPj(x)," 1≤j≤M] (2)
1.2" 权重的确定
在预测样本x时,基分类器[ek]的混淆矩阵公式为:
[CMk=nk11nk12…nk1Mnk21nk22…nk2M⋮⋮⋱⋮nkM1nkM2…nkMM]" " " " " "(3)
式中:[nkij(1≤i≤M,1≤j≤M)]表示基分类器[ek]把类别i预测为类别j的样本数量。
由K个不同的基分类器可得K个混淆矩阵[CM1],[CM2],[…],[CMK]。为了综合评估不同分类器在不同类别上识别的准确性以及不同类别之间的关联性,Ren等引入模糊密度,使用模糊积分理论计算基分类器[ek]的模糊密度[10],公式如下:
[gkm=1M-1n=1,n≠mM1-nknml=1Mnknlnkmml=1Mnkml] (4)
式中:[nkmml=1Mnkml]表示类别m被基分类器[ek]正确识别的比例;[nknml=1Mnknl]表示类别m被基分类器[ek]错误识别的比例。[nkmml=1Mnkml]越大则[nknml=1Mnknl]越小;[gkm]数值越大,表明基分类器[ek]的识别能力越强。
基分类器[ek]识别M个类别的模糊密度向量为:[Gk=(gk1,gk2,…,gkM)],其平均值为:[μk=1Mm=1Mgkm],方差为:[S2k=1M-1m=1M(gkm-μk)2],而以基分类器加权软投票集成的平均值为:[μ=k=1Kωkμk],又因各个基分类器对同一数据集进行拟合,因此方差为[S2=k=1Kω2kS2k+k=1Kωk(μk-μ)2]。[μ]越大,说明该算法的模糊密度均值越大,模型的识别能力越强;[S2]越小,说明该算法的模糊密度越平稳,模型的识别能力越稳定。
因此,在对样本进行预测时,构建以权重和为1的约束条件,具有加权软投票集成算法的模糊密度均值最大化和方差最小化的多目标优化模型,并选择多目标粒子群优化算法(MOPSO)对最优权重进行求解。
1.3" 权重的求解
本文使用多目标粒子群优化算法获得最优基分类器权重,具体步骤如下:
1) 初始化:每个粒子代表基分类器一个可能的权重组合,每个粒子都有一个位置(权重向量)、速度、个体最优位置及其对应的目标函数值,归档用于存储迭代过程中找到的非支配解。
2) 评估:构建适应度函数,计算每个粒子的[μ]和[S2]数值。
3) 非支配排序:通过非支配排序方法将归档中的解和当前的粒子群合并在一起,然后根据粒子之间的支配关系将它们划分为不同的前沿。在这个过程中,根据粒子之间的支配关系将粒子分为多个等级,每个等级对应一个前沿,且其中的粒子不会被其他前沿中的粒子支配。
4) 更新归档:基于非支配排序的结果,更新归档以包括当前的非支配解,如果归档的大小超过粒子的数量,将其修剪至粒子数量。
5) 更新速度和位置:每个粒子的速度和位置都是根据其个体最优位置和从归档中随机选择的一个位置(作为全局最优位置)来更新的,此更新确保权重向量的总和为1,这是通过归一化位置向量来实现的。
6) 迭代:重复步骤2)~步骤5),直至达到预定的最大迭代次数。
7) 输出:归档中的解被认为是问题的Pareto前沿。
1.4" 特征重要性分析
令本文的特征空间为X,是否违约的目标空间为y,[h:X→y]是一组模型,从一组观测到的数据点[z=(x,y)∈X×y]中学习得出。[D={1,2,…,d}]为特征索引的集合,样本x表示为:[x=(x(i):i∈D)∈X],设一组特征集合为S,[Sj]表示特征j的集合,其补集为[Sj],其中[j∈D]。假设从未知随机变量[(X,Y)]的联合分布中抽取N个观测值,[PS]表示S中特征的边际分布,令[zn=(xn,yn)],[Zn=(Xn,Yn)~i.i.dP(X,Y)],[zn]来自[Zn],[x(S)n]来自[X(S)n~i.i.dPS],样本[n=1,2,…,N]。特征重要性是指一组特征S对于模型h的相关性。为了量化特征重要性,PFI(Permutation Feature Importance)算法的关键思想是比较模型仅使用[S]中的特征与使用[D=S⋃S]中的所有特征时的性能,即移除重要特征会大幅降低模型的性能。模型的性能或风险是基于欧氏范数度量,即[E(X,Y)h(X)-Y],对于特征集合S和模型h,常见方法是将被边缘化的风险与模型固有风险[11]进行比较,公式如下:
[ϕ(S)(h)=E(X,Y)[fS(X(S),Y)]-E(X,Y)h(X)-Y] (5)
在边际分布[PS]被边缘化的风险中,[fS(X(S),Y)=EX~~PSh(x(S),X)-y]。在给定观测值[(x1,y1),(x2y2),…,(xN,yN)]中,[ϕ(S)(h)]的经验估计表示如下:
[ϕ(S)φ=1Nn=1Nλ(S)(xn,xφ(n),yn)]" "(6)
式中:[φ]表示采样策略的实现,[φ∈ℂN]。该策略决定每个观察值都应该用于近似[X(S)],并且[λ(S)(xn,xm,yn)=h(x(S)n,x(S)m)-yn-h(xn)-yn]。
PFI算法尝试用排列来测试特征j的重要性,即[ϕ(S)φ]的估计值[12]如下:
[ϕ(Sj)=NN-11Mm=1MϕSjφm≈NN-1Eφ[ϕSjφ]] (7)
式中:[φ1,φ2,…,φm~i.i.dunif(ℂN)]。但PFI算法依赖随机排列的采样进行平均来估计特征重要性,筛选出的特征依赖排列[13]。本文为了减少随机性的影响,引入期望PFI,通过对所有排列的采样进行平均来估计特征重要性并筛选出重要特征,公式为:
[ϕ(Sj)=NN-1Eφ~unif(ℂN)[ϕ(Sj)φ]]" " " " "(8)
2" 研究设计
2.1" 数据准备
数据来源是wind终端。选择从2014年1月1日—2021年12月31日的违约信用债作为违约样本,对于同一主体发行的不同信用债认定为不同样本,共计1 067支
信用债。其中,60.12%的信用债主体评级在B级及以下,62.71%的信用债债项评级在B级及以下,69.61%违约信用债由民营企业发行,44.75%的违约信用债的交易所是在银行间,34.05%的交易所是在上海交易所,18.86%的交易所是在深圳交易所,违约信用债种类主要是私募债(255支)、一般公司债(249支)和一般中期票据(246支)。为确保所选信用债在观察周期(2014年1月1日—2021年12月31日)内不会发生违约,在2021年12月31日之前到期的信用债之间进行选择,并依据所属行业和资产规模,按照1∶2的配对比例为违约信用债选择匹配样本作为对照组。部分信用债主体信息不完整,需要从样本中剔除,最终确定违约信用债769支,对照组987支信用债用于本文研究。
2.2" 指标选择
从宏观指标、债项指标和财务指标三个方面筛选构建信用债违约风险的指标体系。宏观指标参考文献[14]中的选择;债项指标和财务指标除了考虑现金流质量、短期偿债能力、长期偿债能力、营运能力、盈利能力和发展分析等6个方面,还将根据指标的属性分为定量指标和类别指标[15⁃16]。类别指标按照标签编码方案,将每个类别映射到数值。
为了消除不同单位和方差对结果的影响,进行归一化处理,并进行上下1%的缩尾处理剔除异常值,通过显著性、相关性和多重共线性检验,最终筛选出33个指标,其中定量指标27个,定性指标6个,具体如表1所示。
2.3" 实验描述
选择预测性能较好的单一算法逻辑回归、支持向量机、高斯贝叶斯和MLP作为基分类器,每个算法的参数取值如表2所示。
以我国信用债为研究对象,基于信用债违约风险预警指标体系构建模型,比较异质集成算法的stacking算法、voting(soft)和voting(hard)算法的预测性能,并采用期望PFI算法对效果最好的算法进行可解释分析。使用多目标粒子群优化算法求解基分类器权重的参数设置参考Cura[17]的处理:设粒子数为24,最大迭代数为260。为了避免陷入局部最优,在迭代后期降低惯性权重和学习因子,使算法在接近Pareto最优前沿时更稳定地收敛;然后,根据粒子所处环境调整学习因子和惯性权重[18⁃19],其中,惯性权重的取值在0.4~0.9之间,学习因子的取值在1.4~2之间。实验所用主机CPU型号为Intel[Ⓡ] CoreTM i5⁃8250U CPU,主频为1.6 GHz,内存为8 GB,主要使用的库为sklearn。
3" 实验结果与分析
3.1" 评价标准
因为本文违约样本和非违约样本在数量上存在不平衡,所以模型的预测分类评价指标选择accuracy、precision、recall、F1和AUC,以降低数据分布不均的影响,更有效地反映模型预测性能。各指标公式如下:
[accuracy=TP+TNTP+FP+TN+FN] (9)
[precision=TPTP+FP]" (10)
[recall=TPTP+FN]" (11)
[F1=TPTP+FN+FP2]" (12)
[AUC=01TPTP+FNdFPFP+TN] (13)
式中参数的混淆矩阵定义如表3所示。
3.2" 实验结果及分析
不同算法在信用债数据集上的预测结果比较如表4所示。
由表4可知,在单一算法中,逻辑回归的表现最佳,其accuracy、recall、F1和AUC数值都在0.8~0.9之间。高斯贝叶斯、MLP和支持向量机在处理不平衡信用债数据集时,有明显缺陷。高斯贝叶斯算法虽然recall数值高达0.915 4,但是剩下指标的取值均小于0.7;MLP的各个指标取值均在0.5~0.75之间;支持向量机只有recall超过0.7,其他指标均低于0.7。总体来说,逻辑回归相对平衡,MLP表现不稳定,支持向量机和高斯贝叶斯偏向于高召回率。在以4个单一算法为基分类器的异质集成算法中,投票集成算法给单一算法带来预测性能上的提升大于stacking集成算法,其中性能最好的是加权软投票集成算法,其次是硬投票集成算法。
与投票类集成算法相比,虽然stacking常用于异质集成且性能强大,但存在以下问题:
1) stacking包括多个模型的级联,其较高的精确度和较低的召回率可能表明模型存在过拟合的风险,但投票类集成算法通常不会引入额外的复杂性,可以减少过拟合的风险。
2) stacking的性能可能对基分类器的选择和配置非常敏感,不同的基分类器组合可能导致不同的性能结果,这使得stacking更加不稳定;而投票类集成算法通常不会依赖于单个模型的性能,而是综合利用多个模型的输出,这样不太容易受到单个模型选择和配置的影响,因此对模型的选择和配置不太敏感。
3) 本文的信用债数据集为不平衡数据集,违约类别的样本数量少于非违约类别的样本数量,stacking的recall数值为0.316 9,说明stacking在处理不平衡数据集时,容易对违约类别的正样本预测能力不足,但投票类集成方法直接对多个基分类器的预测结果进行投票,通常不需要在元分类器层面上进行复杂的决策,所以在处理不平衡数据时表现更好。
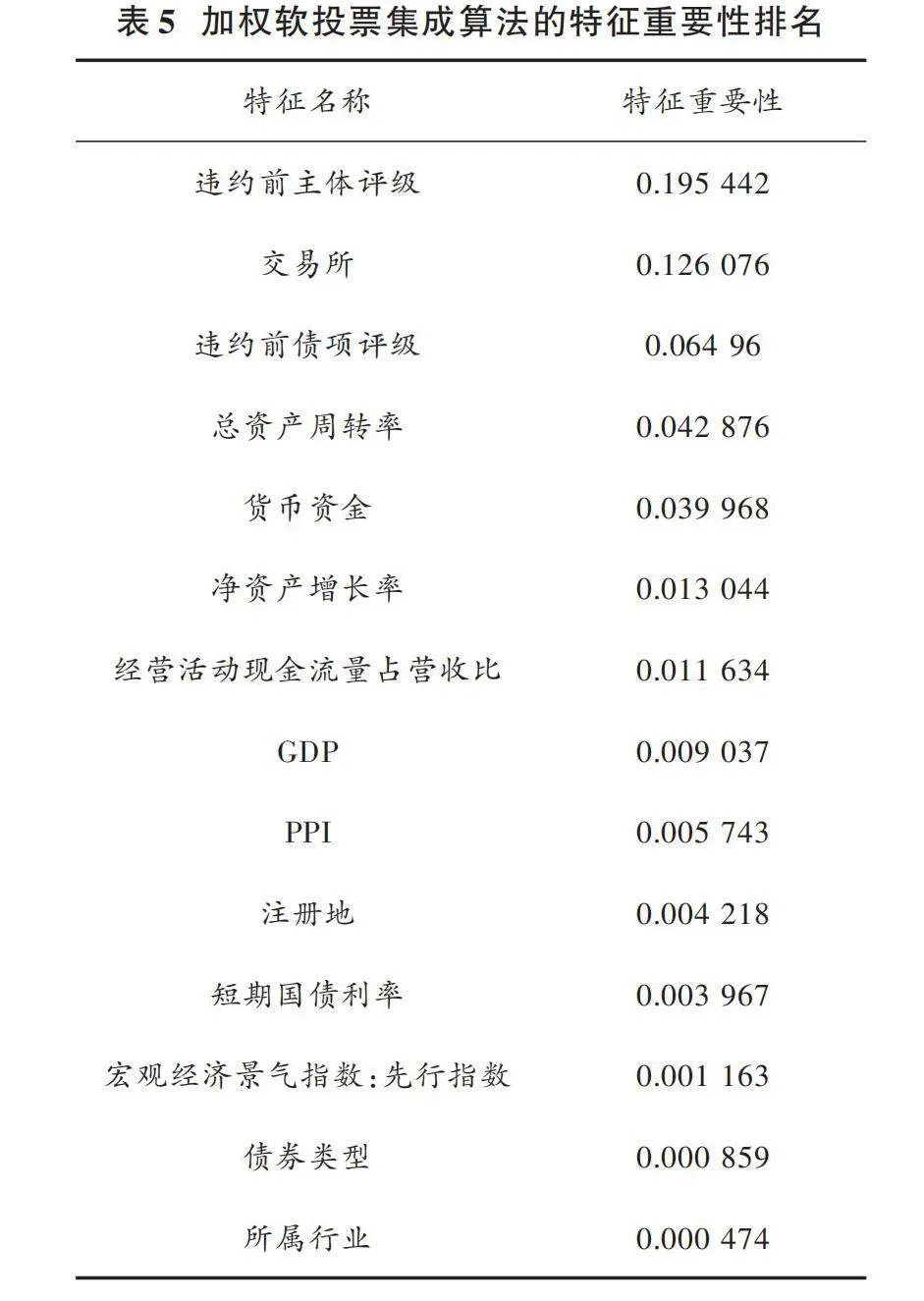
为了增强模型的可解释性,引入期望PFI算法对加权软投票集成算法进行特征重要性分析,以识别可能对信用风险产生较大影响的特征。期望PFI筛选出的重要指标及其重要性如表5所示,在信用债违约中值得关注。
4" 结" 语
本文以2014年1月1日—2021年12月31日的信用债为研究对象,设计一种基于多目标优化的加权软投票集成算法来预测信用债违约,旨在提高信用债违约预测的准确性和稳定性。通过在软投票集成算法中引入权重并很好地利用各个基分类器的优势,在模糊密度均值最大化和方差最小化的多目标优化框架下获得性能更好的预测模型。实验结果表明,加权软投票集成算法在信用债违约预测中表现出色,相对于传统的单一分类器和其他集成算法,取得了更高的准确率、精确度和AUC。这表明该算法对于解决信用债违约预测中的不平衡分布问题具有显著优势,不仅在正确区别违约和非违约样本方面表现出色,还在正类别预测方面有显著提高,并且通过期望PFI算法筛选出值得关注的指标,这对于金融领域的风险管理具有重要意义。
尽管本文提出的加权软投票集成算法在信用债预测中相较于其他算法性能上有很大提升,但仍有需要改进的地方:首先本文在确定权重时使用的是多目标粒子群算法,还可以研究其他权重学习策略,例如基于梯度的方法或进化算法,以进一步提高模型的性能;其次,本文算法依赖样本的模糊密度来分配权重,这可能对数据分布的小变化非常敏感,故需要研究如何提高算法的鲁棒性,以适应不同类型的数据;最后,本文所选择的信用债数据是时变的,可以考虑构建动态更新的集成模型,以适应新的数据模式和趋势。综上所述,本研究为信用债违约预测提供了一种有效的集成算法,并为金融风险管理提供了科学依据。希望在今后的研究中,可以进一步探索集成算法尤其是软投票集成算法的性能,以提高信用债违约预测的准确性,给金融违约风险预警提供更可靠的参考。
注:本文通讯作者为王重仁。
参考文献
[1] 郑煜,吴世农.基于财务信息和非财务信息的债券违约预警模型研究:Fisher模型与Logistic模型的实证分析与应用[J].财会月刊,2023,44(12):22⁃29.
[2] 周荣喜,彭航,李欣宇,等.基于XGBoost算法的信用债违约预测模型[J].债券,2019(10):61⁃68.
[3] JIANG C X, XIONG W, XU Q F. Predicting default of listed companies in mainland China via U⁃MIDAS Logit model with group lasso penalty [J]. Finance research letters, 2020(12): 101487.
[4] NAZEMI A, BAUMANN F, FABOZZI F J. Intertemporal defaulted bond recoveries prediction via machine learning [J]. European journal of operational research, 2021, 297: 1162⁃1177.
[5] CHUKWUDI V O, FIONA A O. Enhancing the weighted voting ensemble algorithm for tuberculosis predictive diagnosis [J]. Scientific reports, 2021, 11(1): 1⁃10.
[6] KIM B C, KIM H C, HANS H, et al. Inspection of underwater hull surface condition using the soft voting ensemble of the transfer⁃learned models [J]. Sensors, 2022, 22(12): 1⁃17.
[7] 刘晓,周荣喜,李玉茹.基于Stacking算法集成的我国信用债违约预测[J].运筹与管理,2023,32(3):163⁃170.
[8] JIANG M Q, LIU J P, ZHANG L, et al. An improved stacking framework for stock index prediction by leveraging tree⁃based ensemble models and deep learning algorithms [J]. Physica a: statistical mechanics and its applications, 2020, 541: 122272.
[9] 丁岚,骆品亮.基于Stacking集成策略的P2P网贷违约风险预警研究[J].投资研究,2017,36(4):41⁃54.
[10] REN F J, LI Y Q, HU M. Multi⁃classifier ensemble based on dynamic weights [J]. Multimedia tools and applications, 2018, 77(16): 21083⁃21107.
[11] COVERT I C, LUNDBERG S, LEE S I. Understanding global feature contributions with additive importance measures [C]// NIPS'20: Proceedings of the 34th International Conference on Neural Information Processing Systems. [S.l.]: ACM, 2020, 17212⁃17223.
[12] FISHER A, RUDIN C, DOMINICI F. All models are wrong, but many are useful: learning a variable’s importance by studying an entire class of prediction models simultaneously [J]. Journal of machine learning research, 2019, 20(177): 1⁃81.
[13] FUMAGALLI F, MUSCHALIK M, HÜLLERMEIER, E, et al. Incremental permutation feature importance (iPFI): towards online explanations on data streams [EB/OL]. [2023⁃04⁃02]. https://arxiv.org/pdf/2303.09331.pdf.
[14] 王满,张苗苗.考虑高维宏观信息的波动率与股票价格预测[J].统计与决策,2022,38(20):138⁃143.
[15] 庞春潮,罗苑玮.基于投资者视角的信用类债券违约风险预警[J].统计与决策,2023,39(2):152⁃157.
[16] 蒋敏,周炜,史济川,等.基于fsQCA的上市企业债券违约影响因素研究[J].管理学报,2021,18(7):1076⁃1085.
[17] CURA T. Particle swarm optimization approach to portfolio optimization [J]. Nonlinear analysis: real world applications, 2009, 10(1): 2396⁃2406.
[18] 李翼,张本慧,郭宇燕.改进粒子群算法优化下的Lasso⁃Lssvm预测模型[J].统计与决策,2021,37(13):45⁃49.
[19] EBERHART R C, SHI Y H. Particle swarm optimization: developments, applications and resources [C]// Proceedings of the 2001 Congress on Evolutionary Computation. Seoul, South Korea: IEEE, 2001: 81⁃86.
作者简介:郑怡昕(1997—),女,安徽人,硕士研究生,研究方向为违约风险预测、机器学习。
王重仁(1984—),男,山东日照人,博士,副教授,研究方向为机器学习。
猜你喜欢
建筑科学与工程学报(2016年6期)2017-01-18 15:37:05
数学学习与研究(2016年17期)2017-01-17 18:31:20
大经贸(2016年11期)2017-01-06 21:47:05
现代商贸工业(2016年11期)2016-12-26 08:58:06
软件导刊(2016年11期)2016-12-22 21:30:28
求知导刊(2016年26期)2016-10-31 12:11:16
电脑知识与技术(2016年21期)2016-10-18 22:51:02
现代经济信息(2016年18期)2016-08-10 18:04:34
电脑知识与技术(2016年13期)2016-06-29 21:00:53
科教导刊·电子版(2016年10期)2016-06-02 19:22:10
