
基于视频时空特征提取分类的动作分析评估模型
2024-09-20 00:00:00陈迪李焱芳毕卫云李朗蒲珊珊
现代电子技术 2024年8期
















摘" 要: 为拓展机器视觉技术在医工结合场景下的应用,文中基于改进的时空Transformer模型,提出一种动作规范识别模型。该模型由数据嵌入层、时空Transformer层、决策融合层组成。数据嵌入层利用Openpose模型从sRGB图像中提取人体骨骼数据,降低环境部署成本;时空Transformer层使用时空模块和块间模型对图像数据特征进行训练和分类,提升原模型的分类精度;决策融合层实现对应用场景的规范性判别。实验测试结果表明:所提算法的TOP1和TOP5精度指标在所有对比算法中均为最优;在以心肺复苏术为例进行的实际应用测试中,该算法的综合性能较为理想,能够满足工程需要。
关键词: 计算机视觉; 时空Transformer模型; 骨骼模型; 决策融合; 动作识别; 多头注意力机制
中图分类号: TN919⁃34; TP391" " " " " " " " " "文献标识码: A" " " " " " " nbsp; " " " 文章编号: 1004⁃373X(2024)08⁃0160⁃05
An action analysis and evaluation model based on video spatiotemporal feature
extraction and classification
CHEN Di1, LI Yanfang2, BI Weiyun2, LI Lang2, PU Shanshan2
(1. School of Basic Medical Sciences, Air Force Medical University, Xi’an 710032, China; 2. The First Affiliated Hospital of AFMU, Xi’an 710032, China)
Abstract: In order to expand the application of machine vision technology in medical and industrial integration scenarios, an action specification recognition model based on an improved spatiotemporal Transformer model is proposed. The model is composed of data embedding layer, spatiotemporal Transformer layer, and decision fusion layer. In the data embedding layer, the Openpose model is used to extract human bone data from sRGB images, so as to reduce environmental deployment costs. In the spatiotemporal Transformer layer, the spatiotemporal modules and inter block models are used to train and classify image data features, so as to improve the classification accuracy of the original model. The decision fusion layer is used to realize the normative discrimination for application scenarios. The experimental testing results show that the TOP1 and TOP5 accuracy indicators of the proposed algorithm are the best among all comparative algorithms. In practical application testing using cardiopulmonary resuscitation as an example, the comprehensive performance of the algorithm is relatively ideal and can meet engineering needs.
Keywords: computer vision; spatiotemporal Transformer model; bone model; decision fusion; action recognition; multi head attention mechanism
0" 引" 言
随着计算机视觉的发展,国内外众多学者使用深度学习的框架实现了人体的动作识别与预测,还能够提取人体的骨架特征,但计算机视觉在医师规培领域的应用目前较少。由于临床操作的实施与医师的职业技能有着直接关系,若动作不规范,则会导致诊疗水平下降,甚至会对患者造成不可逆转的次生伤害。因此,对医师操作过程中动作的规范性评价成为了研究热点[1⁃3]。
目前,临床操作的培训以及动作规范判断大多依靠具有反馈装置的假人训练模型,这种方式成本较高、效率低、单次规培人数少,同时反馈装置只能对医师的动作力度进行评判,无法识别动作是否规范。在医工结合的背景下,本文基于计算机视觉技术,提出一种动作规范性识别模型,进而提升培训、操作的效率与质量。
1" 动作规范性识别算法
1.1" 算法结构设计
本文的动作规范性识别算法结构设计如图1所示。该算法由数据嵌入层、时空Transformer层、决策融合层组成。视频嵌入层主要负责从视频中提取骨骼数据,并处理数据格式;时空Transformer层负责对数据进行处理,同时还可以捕获数据的时空相关性;最后进行决策层融合,得到动作识别判定结果。
1.2" 骨骼数据嵌入提取模型
常用的骨骼数据提取方法大多依赖于深度图像,需要由专业的深度相机拍摄,环境部署成本较高。本次使用Openpose模型提取骨骼数据[4⁃6],其可以直接对sRGB图像帧数据进行训练与识别,进而增强模型的适用性。
Openpose模型由卷积姿态机和局部亲和度组成。卷积姿态机是一种序列形式的全卷积网络,由多个Stage构成,网络的输入数据为sRGB图像序列。本文使用的卷积姿态机共有4个Stage,具体结构如图2所示。
在训练过程中,每个阶段结束之后均要将损失函数的输出值作为中间值进行替换,从而避免梯度爆炸或梯度消失等问题。模型使用到的损失函数公式如下:
[Losstotal =t=1Tp=1Pj∈Jbpt(j)-bp*(j)2] (1)
式中:t为阶段数;p表示图像中像素点的序号;j代表人体骨骼关节序号;b表示实时热力图分布。
模型还使用了局部亲和度对图像像素点的亲和度进行标注与计算,进而将像素点的关键位置连接构成带有方向的向量,从而记录人体骨骼运动的方向及位置信息。向量合成关系如图3所示。
图3中,xj1,k和xj2,k为第k个人肢体的关节起始位置,p代表像素点,v、vt分别表示水平和垂直方向的肢体移动速度。设L为亲和度,公式如下:
[Lc,k(p)=v,p∈c0,p∉c] (2)
[v=xj1,k-xj2,kxj1,k-xj2,k2] (3)
基于该亲和度信息,可以自上而下地进行单人检测,得到肢体的位置和方向信息,进而确定关节点之间的联通区域。
1.3" 基于编码的骨骼数据嵌入模块
为了将骨骼数据送入时空Transformer模块中进行分析,还需要对数据进行编码并将其嵌入到模型中。本文使用的编码方案如图4所示。
可将图4中的骨骼数据看作张量,故得:
[XC=[x1,x2,…,xT], xi∈Rn×V×C] (4)
式中:n为帧数;T为时空块;V是关节个数;C表示关节数据维度。公式(4)将数据XC分割为多个不重叠的时空块数据,同时通过特征映射层将高维特征嵌入到后续模型中。
1.4" 动作特征提取模型
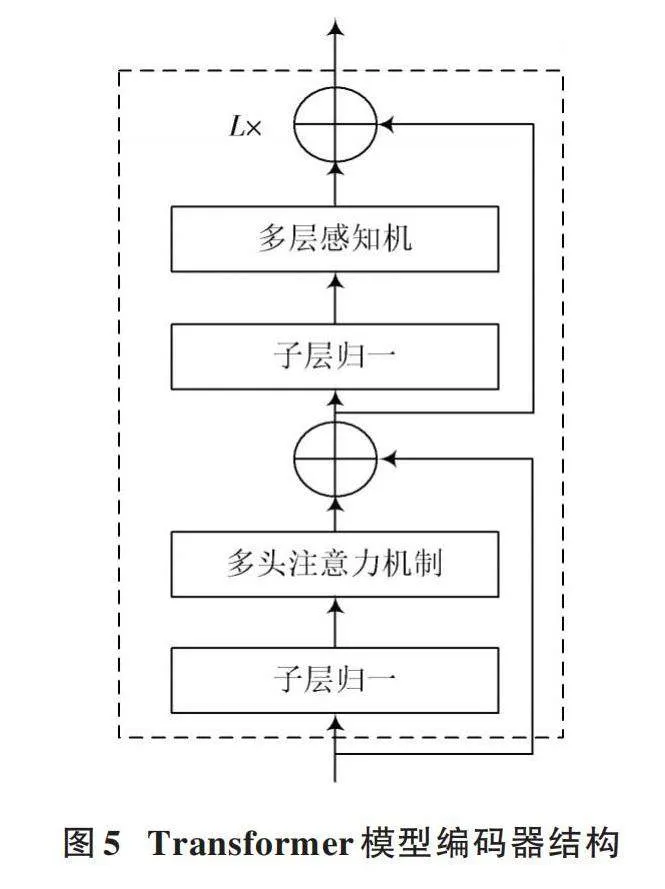
Transformer模型[7⁃11]由编码器和解码器组成,最早被应用于自然语言处理等领域。编码器被用于提取输入数据特征,同时还能够提取同等维度的感知数据特征。Transformer模型的编码器结构如图5所示。
在图5中,编码器的单个子层由多层感知机和多头注意力机制构成,编码器由多个子层结构组成。同时,在连接部分加入了残差网络(Residual Network)和LN层,则第n个编码器子层结构的数据处理过程如下:
[Z′n=MSALNZn-1+Zn-1] (5)
[Zn=MLPLNZ′n+Z′n] (6)
式中:[Zn-1]和[Zn]分别表示第n个子层的输入与输出特征。该特征具有相同的维度,通过残差的连接方式也避免了网络训练过程出现的过拟合。多头注意力机制的结构如图6所示。
多头注意力机制[12⁃14]由查询向量矩阵Q、键向量矩阵K以及值向量矩阵V组成,可由线性变换计算得到。多头注意力机制的权重矩阵通常是通过点积得到的,公式如下:
[Attention(Q,K,V)=SoftmaxQKTdV] (7)
[MSA(Q,K,V)=Concat(Y1,Y2,…,YH)Wo] (8)
[Yh=Attention(Qh,Kh,Vh)," h∈{1,2,…,H}] (9)
本文基于Transformer结构,提出一种耦合时空因素的Transformer网络算法,其结构如图7所示。
所构建的Transformer网络算法由时空块和块间网络组成,其中,时空块网络主要用来学习多个图像帧之间的关节特征,网络的输入部分为处理过后的骨架数据。输入部分嵌入模块的具体结构如图8所示。
在图8中:输入数据为张量Zin;LP表示线性投影算法,该算法的输入为特征重塑后的张量;定义域设置为B×T1×V1×C1,其中B为块大小,T1是时空块数量,V1为图像中的关节个数,C1表示关节数据维度。
块间的Transformer是在时空块基础结构上改进的,模型可以对高维度的数据进行有效处理,同时能够在时间维度中对数据进行处理,并生成多个空间注意力图。
2" 实验分析
2.1" 实验环境与数据集搭建
首先预设实验环境,本文算法以Pytorch为基础深度学习框架,所使用的硬件配置如表1所示。
使用两个主流人体动作识别数据集作为模型训练数据集,分别为Kinetics⁃400和FineGYM[15⁃16]。Kinetics⁃400是从YouTuBe中采集的人体运动数据集,共有400个人体动作分类,样本数量超过30万条。FineGYM也为人体动作识别数据集,但是其为细粒度数据集,数据来源于体操比赛,共有100个细粒度分类,样本总量约7万条。文中构建的实验数据集分为训练集和验证集,数量比例为8∶2,再将两种数据集按照1∶1的比例随机混合成本文所需数据集。
2.2" 算法测试
为验证算法模型中每个部分对整体性能的贡献,进行消融实验。实验使用5种模型,分别为基本Transformer(模型1)、时空Transformer(模型2)、嵌入层+
Transformer(模型3)、嵌入层+时空Transformer(模型4)、本文模型嵌入层+时空Transformer+块间Transformer(模型5)。模型使用TOP1和TOP5精度作为评价指标,实验测试结果如表2所示。
由表2的实验结果可以看出:将原始模型的线性嵌入模块改进为Openpose嵌入层后,TOP1精度对应提升了5%,TOP5精度也有相应提升,表明改进嵌入模块是有效的策略,也说明了提取骨骼数据特征的重要性;而改进后的时空Transformer模型(模型2)相较原始模型TOP1精度提升了3.3%;本文模型TOP1精度最高,相较原始精度提升了7.6%,这充分说明了改进算法的有效性。
为了对算法性能进行横向评估,本文还使用多种常用算法模型进行精度比较,对比算法为GCN(Graph Convolutional Network)、2D⁃CNN(2D⁃Convolutional Neural Network)、HCN(HyperCube Network)、CNN⁃LSTM(Convolutional Neural Network⁃Long Short⁃Term Memory)以及TP⁃ViT。横向对比测试的实验结果如表3所示。
由表3可以看出,本文算法在所有算法中的精度指标最优,比TP⁃ViT算法的TOP1和TOP5精度分别高0.9%和3.7%,比CNN⁃LSTM算法的TOP1和TOP5精度分别高2.6%与10.6%。综上可得,本文算法表现良好,具有较为理想的性能。
心肺复苏术(Cardio Pulmonary Resuscitation, CPR)是急救领域最基础且常用的手段之一,本文以CPR动作规范性识别为例,进行了应用场景下的实验验证,结果如图9所示。图9表明,模型可识别出sRGB图像的骨架,并能对动作规范性进行识别,验证了算法的工程实用价值。
3" 结" 语
本文充分利用Transformer模型训练效率和识别准确率高的特点,提出了一种可用于医学场景下的动作识别模型。该模型由数据嵌入层、时空Transformer层、决策融合层组成,可以从sRGB图像中提取骨骼数据,并对数据特征进行学习,进而判断动作的规范性。实验测试证明,所提模型的综合性能良好,TOP1和TOP5精度均优于对比算法。
注:本文通讯作者为李焱芳。
参考文献
[1] 莫加良,韦燕运,卢伟光,等.根因分析法在急诊心肺复苏中的应用效果及其对患者预后的影响[J].广西医科大学学报,2023,40(9):1597⁃1602.
[2] 冯航测,田江涛,郝美林,等.基于SE⁃Stacking算法的心肺复苏结果预测分析[J].国外电子测量技术,2023,42(9):155⁃161.
[3] 张友坤,陈伟,靳小静,等.基于MW⁃REF算法的心肺复苏影响因素分析[J].科学技术与工程,2023,23(22):9543⁃9549.
[4] 苏波,柴自强,王莉,等.基于姿态估计的八段锦序列动作识别与评估[J].电子科技,2022,35(12):84⁃90.
[5] 张富凯,贺天成.结合轻量Openpose和注意力引导图卷积的动作识别[J].计算机工程与应用,2022,58(18):180⁃187.
[6] 李一凡,袁龙健,王瑞.基于OpenPose改进的轻量化人体动作识别模型[J].电子测量技术,2022,45(1):89⁃95.
[7] 余子丞,凌捷.基于Transformer和多特征融合的DGA域名检测方法[J].计算机工程与科学,2023,45(8):1416⁃1423.
[8] 邓帆,曾渊,刘博文,等.基于Transformer时间特征聚合的步态识别模型[J].计算机应用,2023,43(z1):15⁃18.
[9] 徐丽燕,徐康,黄兴挺,等.基于Transformer的时序数据异常检测方法[J].计算机技术与发展,2023,33(3):152⁃160.
[10] 党晓方,蔡兴雨.基于Transformer的机动目标跟踪技术[J].电子科技,2023,36(9):86⁃92.
[11] 石跃祥,朱茂清.基于骨架动作识别的协作卷积Transformer网络[J].电子与信息学报,2023,45(4):1485⁃1493.
[12] 赵英伏,金福生,李荣华,等.自注意力超图池化网络[J].软件学报,2023,34(10):4463⁃4476.
[13] 常月,侯元波,谭奕舟,等.基于自注意力机制的多模态场景分类[J].复旦学报(自然科学版),2023,62(1):46⁃52.
[14] 李垚,余南南,胡春艾,等.基于自注意力机制的脑血肿分割和出血量测量算法[J].数据采集与处理,2022,37(4):839⁃847.
[15] 屈小春.基于Transformer的双流动作识别方法研究[D].重庆:西南大学,2023.
[16] 蔡思佳.基于注意力机制的细粒度行为识别算法研究[D].南京:东南大学,2022.
作者简介:陈" 迪(1980—),女,辽宁大连人,硕士,讲师,研究方向为生物医学可视化、教育技术。
猜你喜欢
四川党的建设(2022年8期)2022-04-28 21:29:35
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中老年保健(2021年5期)2021-12-02 15:48:21
中老年保健(2021年5期)2021-08-24 07:06:28
小学生学习指导(低年级)(2020年11期)2020-12-14 07:28:10
作文大王·低年级(2018年10期)2018-12-06 06:22:44
小布老虎(2017年1期)2017-07-18 10:57:27
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
小猕猴智力画刊(2016年5期)2016-05-14 09:21:39
